










oracle 分析函数(window 函数)
本文总结了oracle种常见的分组,rollup,cube,分析函数,行转列的常见用法
1.如何同时查询两种分组?
1.1 传统方法使用union ,无法避免多次扫描表
--scott 用户下
--部门平均工资
SELECT to_char(deptno) deptno,'' job,avg(sal) dep_avg_sal FROM emp GROUP BY DEPTNO
--岗位平均工资
UNION ALL
SELECT '' deptno, job ,avg(sal) job_avg_sal FROM EMP GROUP BY JOB;
在此简要回忆一下 分组查询
group by 要领 出现在select 列表中的字段,要么在group by 中出现,要么在聚合函数之中
正确的例子
SELECT deptno ,job, avg(sal) avg_sal FROM emp GROUP BY DEPTNO ,job ;
错误的例子
SELECT deptno ,job, avg(sal) avg_sal FROM emp GROUP BY DEPTNO ;
修正后
SELECT deptno , min(job), avg(sal) avg_sal FROM emp GROUP BY DEPTNO ;
where 和having 区别 都是数据的过滤
having 是对分组后的数据过滤,且必须有分组函数 having avg(sal) >100
1.2 使用 grouping sets
--同时计算部门平均工资和岗位平均工资
SELECT
deptno
,grouping(deptno) g_deptno --为0 说明按 deptno分组,为1 说明分组的时候忽略
,job
,grouping(job) g_job
,avg(sal) avg_sal
FROM EMP GROUP BY grouping sets(deptno,job)
关于 grouping sets 使用方法,再看一个例子
select
jf.fylbid
,sum(jf.fyje) fyje
,jf.skrid
,jf.skrmc
,jf.zffs
,substr( ry.dwdm,0,6) college
from
bw_xy_bjtxy_jfmx jf
,bw_ry_bjtry ry
where 1=1
and jf.skrid=ry.id
and jf.yxbz='Y'
and jf.qrsj >= to_date('2017-07-01','yyyy-mm-dd')
and jf.qrsj < to_date('2017-07-31','yyyy-mm-dd')+1
and jf.differentiate='1'
AND jf.ZFFS IS NOT null
-- 多字段 group sets
GROUP BY grouping sets(
(substr( ry.dwdm,0,6),jf.skrid,jf.skrmc,jf.FYLBID)
,(substr( ry.dwdm,0,6),jf.skrid,jf.skrmc,jf.ZFFS)
)
2 rollup 和cube
--rollup上卷 比如 rollup(deptno,job) 先按 deptno,job 同时分组,然后从右 到左依次去掉一个 字段然后分组
-- 第一组分组字段 deptno,job
-- 第二组分组字段 deptno
-- 第三组分组字段 无
SELECT
grouping(deptno) g_deptno,
grouping(job) g_job,
deptno
,job
,round( avg(sal),2) avg_sal
FROM emp GROUP BY rollup(deptno,job)
--cube 数据立方体
-- 第一组分组字段 deptno,job
-- 第二组分组字段 job
-- 第三组分组字段 deptno
-- 第三组分组字段 无
--分组数量是 2的 字段个数次方
SELECT
grouping(deptno) g_deptno,
grouping(job) g_job,
deptno
,job
,round( avg(sal),2) avg_sal
FROM emp GROUP BY cube(deptno,job)
3. 分析函数
--按部门汇总 sal
SELECT deptno,sum(sal) demp_sum_sal FROM EMP GROUP BY deptno
--分析函数 应用在每一行上
--查询部门中个人销售额 占 部门销售额的 百分比
SELECT
e.EMPNO
,e.ENAME
,e.DEPTNO
,e.SAL
,sum(e.SAL) OVER (PARTITION BY e.DEPTNO ) dept_sum
FROM EMP e;
--部门内 按员工销售额 排序
SELECT
e.EMPNO
,e.ENAME
,e.DEPTNO
,e.SAL
,row_number () OVER (PARTITION BY e.DEPTNO ORDER BY e.SAL ) dept_rn
FROM EMP e;
--部门内 计算员工累计和
SELECT
e.EMPNO
,e.ENAME
,e.DEPTNO
,e.SAL
,sum(e.SAL) OVER (PARTITION BY e.DEPTNO ORDER BY e.EMPNO ) dept_sum
,sum(e.SAL) OVER (PARTITION BY e.DEPTNO ) dept_sum_all
,sum(e.SAL) OVER () dept_sum_all
FROM EMP e;
--行号,总排序,部门内排序,部门内rank
SELECT
e.EMPNO,e.ENAME,e.SAL,e.DEPTNO
, ROWNUM rn
,row_number() OVER(ORDER BY e.SAL ) rn_all
,row_number() OVER(PARTITION BY e.DEPTNO ORDER BY e.SAL) rn_dep
,rank() OVER(PARTITION BY e.DEPTNO ORDER BY e.SAL) rank_dep
,ntile(3) OVER(ORDER BY e.SAL DESC ) tile_all --获取总排名 前1/3 的人员
FROM EMP e;
SELECT * FROM USER_LOG;
DROP TABLE user_log;
CREATE TABLE user_log
(
ID NUMBER(5,0),
user_id VARCHAR(10),
flag char(1), --1 登录 0 退出
CREATE_TIME DATE
);
TRUNCATE TABLE user_log;
INSERT INTO user_log VALUES(1,'a',1,to_date('2017-01-01','yyyy-mm-dd'));
INSERT INTO user_log VALUES(2,'a',0,to_date('2017-01-03','yyyy-mm-dd'));
INSERT INTO user_log VALUES(3,'a',1,to_date('2017-01-04','yyyy-mm-dd'));
INSERT INTO user_log VALUES(4,'a',0,to_date('2017-01-07','yyyy-mm-dd'));
INSERT INTO user_log VALUES(5,'b',1,to_date('2017-01-02','yyyy-mm-dd'));
INSERT INTO user_log VALUES(6,'b',0,to_date('2017-01-04','yyyy-mm-dd'));
INSERT INTO user_log VALUES(7,'b',1,to_date('2017-01-08','yyyy-mm-dd'));
INSERT INTO user_log VALUES(8,'b',0,to_date('2017-01-10','yyyy-mm-dd'));
INSERT INTO user_log VALUES(9,'b',1,to_date('2017-01-11','yyyy-mm-dd'));
COMMIT;
SELECT * FROM USER_LOG;
--统计用户登录时长
WITH t AS
(
SELECT
u.USER_ID
, u.FLAG
, u.CREATE_TIME
, lead(u.CREATE_TIME) OVER(PARTITION BY u.USER_ID ORDER BY u.CREATE_TIME) after_my
, lag (u.CREATE_TIME) OVER(PARTITION BY u.USER_ID ORDER BY u.CREATE_TIME) before_my
FROM USER_LOG u
)
,t1 AS (
SELECT t.USER_ID,t.CREATE_TIME, nvl( t.AFTER_MY,SYSDATE) AFTER_MY FROM t WHERE t.flag='1'
)
SELECT t1.user_id,sum(t1.AFTER_MY-t1.CREATE_TIME) login_days FROM t1 GROUP BY t1.user_id
--滑动窗口
WITH r1 AS (
SELECT ROWNUM rn
--,TRUNC( dbms_random.value(10,0) ) c
FROM DUAL CONNECT BY LEVEL <=10
)
SELECT rn
,sum(rn) OVER ( ORDER BY rn) rn_sum
,sum(rn) OVER ( ORDER BY rn ROWS BETWEEN unbounded preceding AND CURRENT ROW) rn_sum1
,sum(rn) OVER ( ORDER BY rn ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) rn_sum2
FROM r1
--listagg 函数 11g
select empno,ename,deptno from scott.emp ORDER BY deptno;
SELECT deptno,
LISTAGG(ename, ';') WITHIN GROUP(ORDER BY ename) AS employees
FROM scott.emp
GROUP BY deptno;
--10g
SELECT deptno, WMSYS.WM_CONCAT(ename) AS vals
FROM scott.emp
GROUP BY deptno;
4.行转列
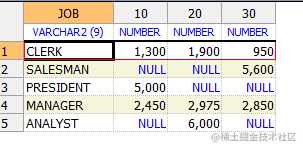
--行转列
WITH pivot_data AS (SELECT deptno, job, sal FROM emp)
SELECT * FROM PIVOT_data
PIVOT
(
--倒写的for 循环
SUM(sal) FOR deptno IN (10, 20, 30) -- 10, 20, 30 是分组字段 deptno
);
结果:
--指定列名
WITH pivot_data AS (SELECT deptno, job, sal FROM emp)
SELECT * FROM PIVOT_data
PIVOT
(
SUM(sal) sal --pivot_clause
FOR deptno --pivot_for_clause
IN (
10 AS dep_10
, 20 AS dep_20
, 30 AS dep_30
)
);
--多列转行
WITH pivot_data AS (SELECT deptno, job, sal FROM emp)
SELECT *
FROM pivot_data
PIVOT
(
SUM(sal) AS SUM,
COUNT(sal) AS cnt
FOR (deptno, job) --多列
IN (
(30, 'SALESMAN' ) AS d30_sls,
(30, 'MANAGER' ) AS d30_mgr,
(30, 'CLERK' ) AS d30_clk
)
);
/*
FOR (deptno, job) IN ( (30, 'SALESMAN' ), (30, 'MANAGER' ) , (30, 'CLERK')){
SUM(sal) AS SUM,
COUNT(sal) AS cnt
}
*/
--unpivot 行转列
WITH pivot_data AS (SELECT deptno, job, sal FROM emp)
,t AS
(
SELECT *
FROM pivot_data
PIVOT (
SUM(sal)
FOR deptno
IN (
10 AS d10_sal,
20 AS d20_sal,
30 AS d30_sal,
40 AS d40_sal)
)
)
SELECT * FROM t
UNPIVOT
(
deptsal --<-- unpivot_clause 代表 d10_sal, d20_sal, d30_sal, d40_sal
FOR saldesc --<-- unpivot_for_clause 给 unpivovit 操作后的结果列一个名称( SALDESC)
IN (d10_sal, d20_sal, d30_sal, d40_sal) --<-- unpivot_in_clause
);
--再来一个例子 多个字段展开成行
WITH a AS (
SELECT 'a' xy,'131' tel1,'132' tel2 ,'133' tel3 FROM DUAL
UNION ALL
SELECT 'b' xy,'181' tel1,'182' tel2 ,'183' tel3 FROM DUAL
)
SELECT * FROM a
UNPIVOT
(
--倒写的 for 循环
tel FOR tel_flag IN (tel1,tel2,tel3) --要转化的列
)
/**
tel_flag 是循环 数组(tel1,tel2,tel3) 的变量
FOR tel_flag IN (tel1,tel2,tel3)
把值转化为 行 并令其别名叫 tel
======> 写成java
for tel_flag IN (tel1,tel2,tel3){
system.out(tel_flag);
}
*/















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









