






在我们很多开发场景中可能会需要消息队列的存在,实现消息队列的方式有很多,上篇文章也大概了解了一下Kafka,Rebbitmq等等消息队列,但是如果我们想要特别简单的消息队列,我们可以使用redis来实现
引用:redis之如何实现消息队列_redis实现消息队列_wang0907的博客-CSDN博客
Redis实现消息队列最简单版
我们可以先回顾一下redis是用来干嘛的,redis是非关系型的数据库,他是以key:value形式存在数据库中,redis数据库的常用数据类型有字符串,列表,哈希,集合,有序集合,当我们简单的了解一下redis的列表类型的时候,我们就可以实现一个简单版的消息队列
Redis中列表的插入值有多种方法,但是我们选择其中两个
rpush key value1 value2 value3 表示从右侧插入,每次插入都在上个值的右侧
lpush key vlaue value2 value3 表示从左侧插入,每次插入都在上个值的左侧
Reis的取值方法
lpop key 从列表左侧弹出一个值
rpop key 从列表右侧弹出一个值
那么我们看到了列表的插入以及取值,是不是可以联想到我们的消息队列呢,消息队列其实可以简单的理解为我们生产者在某一个位置放入值,而我们的消费者在同样的位置去拿值,那结合redis的插入值,如我们的lpush,他每次所插入的值都会在上一个值的左侧,所以最右边的值是第一个插入的,再依次向左,那这个时候如果我们用rpop去弹出列表最后面的值,那么就拿的是到消息队列第一个放入的值,那再弹第二个,就是第二个放入的,这样我们可以实现一个简单的消息队列
List用自身的特性保证了有序性,但是有一个问题在出队时消费者需要轮询消息队列,无论消息队列是否有值都需要轮询显然这是对资源的消耗不太合理,所以Redis中可以使用阻塞式读取命令BRPOP当消息队列是空时会阻塞等待,当消息队列有后会重新出队
消息的重复消费
生产者可以创建唯一性ID来标识这个消息,消费者需要存储已经消费的消息ID列表,每处理一个消息需要对比消息ID在已消费列表中是否存在,如果ID已存在那么该消息不会再处理,这也是幂等性的保证
消息的可靠性
消息的可靠性保证可以在消费者出队一个消息后将这个消息保存到未完成的队列中,只有当消费者处理完毕才从未完成的队列中移除,其核心思想就是采用BRPOPLPUSH备份
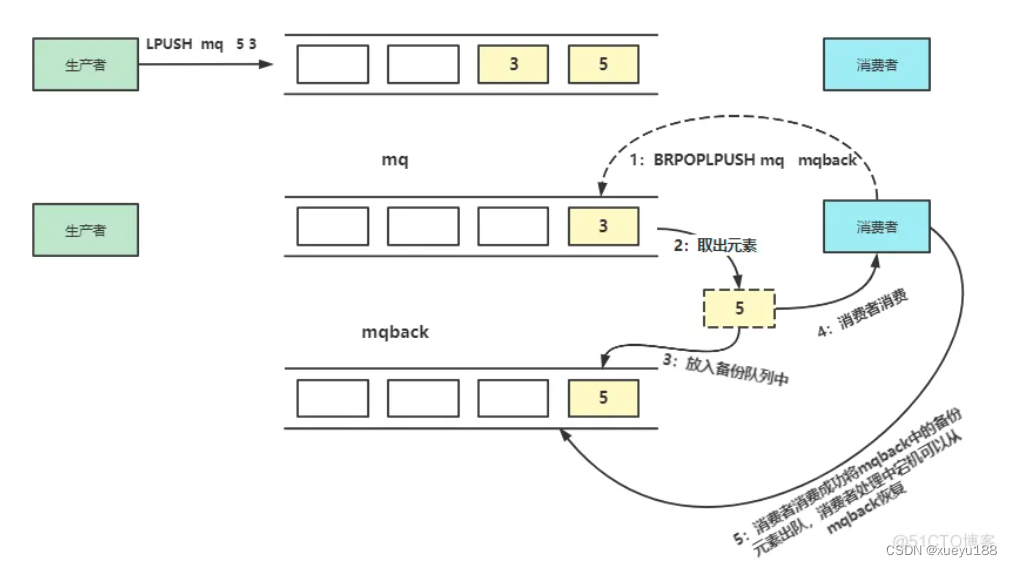
对于List可以简单满足消息队列的需求,但需要注意的是List处理消息队列肯定不能多个消费者一起消费,不然消息的有序性得不到保证,如果生产者的速度过快,而消费者的速度慢就会造成消息堆积,在Redis内存带来巨大的压力,所以在这种场景下需要考虑多个消费者共同分担压力的问题,这就需要依靠5.0 版本开始提供的Stream解决。
Streams
Streams是Redis5.0新增的数据结构,它提供了消息的持久化以及主备复制功能,可以让任何客户端访问任何时刻的数据,它有一个消息链表可以将所有加入的消息串起来,每个消息都存在一个唯一ID,并且这个ID是递增的,是一种redis专门为消息队列定义的一种数据结构,
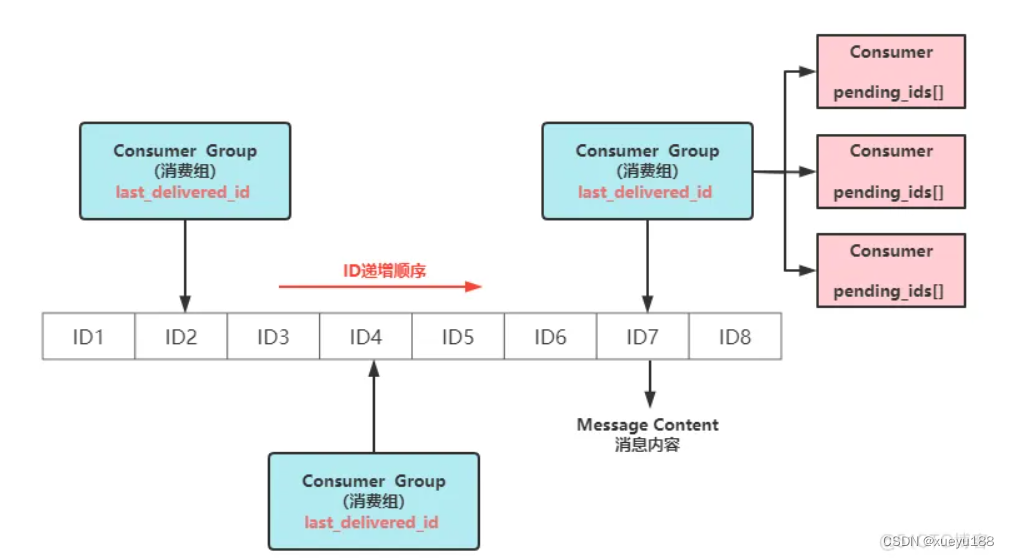
自然的我们是先要看如何定义这种数据结构了,和其它的数据结构一样,我们不需要显式的创建,在执行第一次数据添加的时候自动创建,添加数据的命令是XADD,语法格式是XADD key ID field value [field value ...],参数说明如下:
key:redis的key
ID:消息的唯一标识,可以指定,也可以设置为*,设置为*时id会自动生成,id是递增
field value:消息的字段和值
如下生产(创建)若干条消息:
redis> XADD mystream * name Sara surname OConnor
"1601372323627-0"
redis> XADD mystream * field1 value1 field2 value2 field3 value3
"1601372323627-1"
redis> XLEN mystream
(integer) 2
redis> XRANGE mystream - +
1) 1) "1601372323627-0"
2) 1) "name"
2) "Sara"
3) "surname"
4) "OConnor"
2) 1) "1601372323627-1"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
redis>
其中XLEN用来查看消息的个数,XRANGE用来通过范围查询基于递增ID获取消息,-相当于是负无穷,+相当于是正无穷,即获取所有消息。我们接着再来看下其它一些命令
XDEL :根据ID删除消息
> XADD mystream * a 1
1538561698944-0
> XADD mystream * b 2
1538561700640-0
> XADD mystream * c 3
1538561701744-0
> XDEL mystream 1538561700640-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) 1538561698944-0
2) 1) "a"
2) "1"
2) 1) 1538561701744-0
2) 1) "c"
2) "3"
XLEN:获取消息的数量
redis> XADD mystream * item 1
"1601372563177-0"
redis> XADD mystream * item 2
"1601372563178-0"
redis> XADD mystream * item 3
"1601372563178-1"
redis> XLEN mystream
(integer) 3
redis>
XRANGE:查询指定范围的消息
key :队列名
start :开始值, - 表示最小值
end :结束值, + 表示最大值
count :数量
redis> XADD writers * name Virginia surname Woolf
"1601372577811-0"
redis> XADD writers * name Jane surname Austen
"1601372577811-1"
redis> XADD writers * name Toni surname Morrison
"1601372577811-2"
redis> XADD writers * name Agatha surname Christie
"1601372577812-0"
redis> XADD writers * name Ngozi surname Adichie
"1601372577812-1"
redis> XLEN writers
(integer) 5
redis> XRANGE writers - + COUNT 2
1) 1) "1601372577811-0"
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) "1601372577811-1"
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
redis>
XREVRANGE:从后往前获取消息
语法格式XREVRANGE key end start [COUNT count]
key :队列名
end :结束值, + 表示最大值
start :开始值, - 表示最小值
count :数量
redis> XADD writers * name Virginia surname Woolf
"1601372731458-0"
redis> XADD writers * name Jane surname Austen
"1601372731459-0"
redis> XADD writers * name Toni surname Morrison
"1601372731459-1"
redis> XADD writers * name Agatha surname Christie
"1601372731459-2"
redis> XADD writers * name Ngozi surname Adichie
"1601372731459-3"
redis> XLEN writers
(integer) 5
redis> XREVRANGE writers + - COUNT 1
1) 1) "1601372731459-3"
2) 1) "name"
2) "Ngozi"
3) "surname"
4) "Adichie"
XREAD
以阻塞或者是非阻塞的方式获取消息,即消费消息的命令,语法格式XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...],解释如下:
count :数量
milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
key :队列名
id :消息 ID
# 从 Stream 头部读取两条消息
> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
1) 1) "mystream"
2) 1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
2) 1) 1526999352406-0
2) 1) "duration"
2) "812"
3) "event-id"
4) "9"
5) "user-id"
6) "388234"
2) 1) "writers"
2) 1) 1) 1526985676425-0
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
XGROUP CREATE
创建消费者组,使用消费者可以对消息进行并发的消费,解决消费者消费能力不足的问题,语法格式为XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername],解释如下:
key :队列名称,如果不存在就创建
groupname :组名。
$ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
如下从头开始消费:
XGROUP CREATE mystream consumer-group-name 0-0
如下从尾部开始消费:
XGROUP CREATE mystream consumer-group-name $
在实际的场景中我们可以通过设置多个消费者组的不同开始消费的位置来实现并发消费的效果,此时可能如下图:
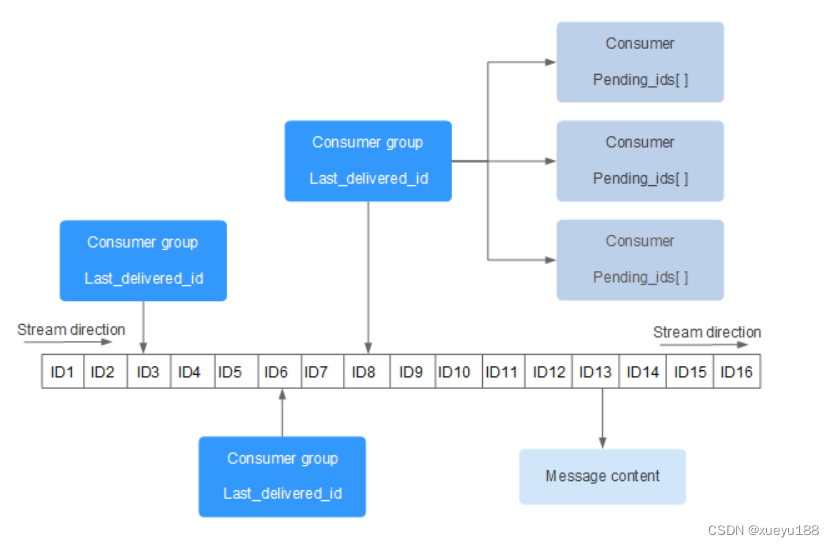
图中主要元素解释如下:
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
XREADGROUP GROUP
读取消费者组中的消息,语法格式如下:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
解释如下:
group :消费组名
consumer :消费者名。
count : 读取数量。
milliseconds : 阻塞毫秒数。
key : 队列名。
ID : 消息 ID。
如下测试:
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >
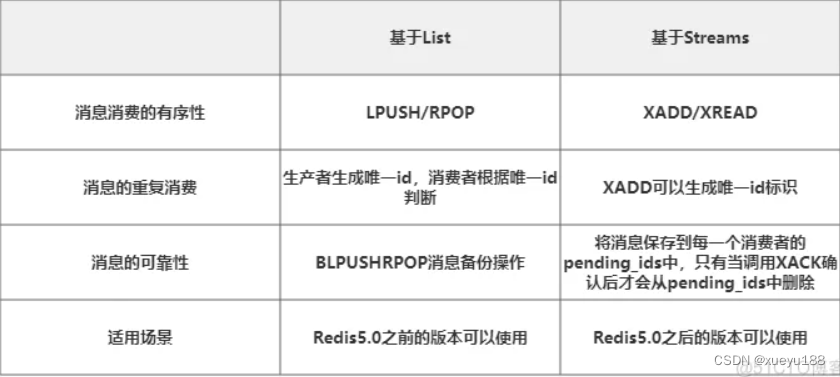
总结
Redis消息队列的实现真正能运用到生产环境的是List和Streams,两者区别如下所示















 8512
8512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









