







下面我就简单介绍下这个算法实现,首先我们先确定一个事先准备好的矩阵,这个可能是事先聚类出来的或者通过专家估计出来的值。
为了这个分类矩阵和标签写一个函数,这里我们把它称为createDataSe:
下面给出这个函数的代码:
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
看这篇博客的同时最好配有《机器学习实战》这本书,这本书的译者其中一个是目前项目的一个人参与者,在书中我们可以看到这样的图片:
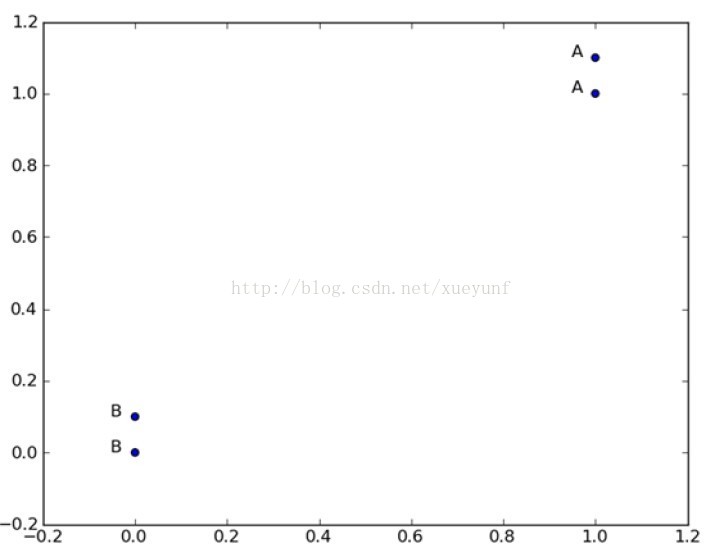
这样很明确的我们可以看到这4个点 和其对应的标签。
所谓KNN即我们新来一个测试点和以前我们做好标记的点计算距离,然后采用距离最近的标签作为该测试点的标签,当然你可能觉得原来是这么简单的东西,是的这个朴素的思想,在当今的各种推荐系统,以及广告系统中,依然有所使用。
然后我们继续讲解下一段简单的代码,有了参考点,下一段当然是来测试点了,
下面我就先贴上代码:
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1))-dataSet
print(diffMat, '\n')
sqDiffMat = diffMat**2
print(sqDiffMat)
sqDistances = sqDiffMat.sum(axis=1)
print(sqDistances)
distance = sqDistances**0.5
sortedDistIndices = distance.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndices[i]]
classCount[voteIlabel]= classCount.get(voteIlabel, 0)+1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]当然这个有书而且很细心的童鞋会发现我多了几行打印代码,第一行是得到先验数据的列数,然后第二行是产生一个与该矩阵一样大小的矩阵并和原矩阵相减,然后得到测试点与4个标记点的坐标差,下一行是打印,接下来就是我们将这个矩阵进行平方,然后将所有数据相加,合为一个数据,然后将其开平方,接距离进行排序,产生一个排名。
这样所有点到测试点的距离排名就都有了。
下一段for循环开始是选择前k个最近距离对该测试点进行投票,最后再次将投票结果进行排序,输出得票率最高的一个点作为最后的结果。这就是最终的标签结果。
不得不感叹一句这么短的代码完成了这多功能!
最后我再说点关于这一句的用法,这个是为了不返回异常如果没有,则增加一项,有了就增加1,这当然是最简单的KNN算法思想的阐述,但是与实际应用差了十万八千里。
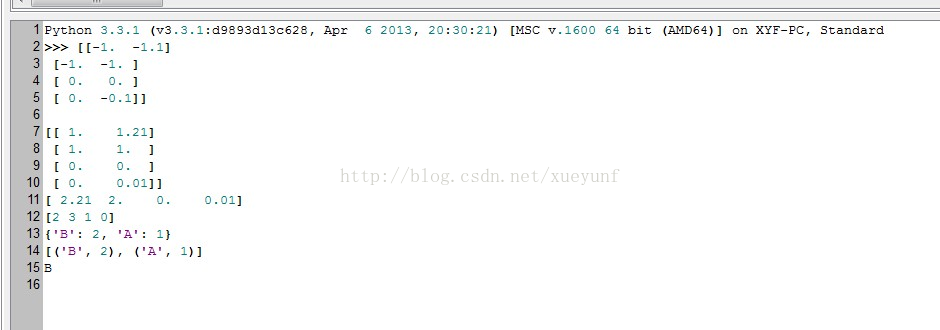
classCount.get(voteIlabel, 0)附上测试调用的代码,该代码完成了(0,0)点的分类:
group, labels = createDataSet()
print(classify([0, 0], group, labels, 3))对了还得给出程序运行的截图:















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









