







我们先看一个例子:
public class MemoryReorderingExample {
private static int x=0,y=0;
private static int a=0,b=0;
public static void main(String[] args) throws InterruptedException {
int i=0;
while(true){
i++;
x=0;y=0;
a=0;b=0;
Thread t1=new Thread(()->{
a=1;
x=b;
});
Thread t2=new Thread(()->{
b=1;
y=a;
});
t1.start();
t2.start();
t1.join();
t2.join();
String result="第"+i+"次("+x+","+y+")";
if(x==0&&y==0){
System.out.println(result);
break;
}
}
}
}这个代码正常情况下,x和y的值,会根据t1和t2线程的执行情况来决定:
-
如果t1先执行,那么结果是x=0,y=1.
-
如果t2先执行,那么结果是x=1,y=0
-
如果同时执行,那么结果是x=1,y=1
执行的时候我们会发现会在某个时刻出现这样的输出:
第439458次(0,0)如果等待时间够久,这种情况一定会出现,只不过不一定是第第439458次。
这里竟然出现了x=0,y=0的情况。这其实就是指令重排序问题,假设上面的代码通过指令重排序之后,变成下面的结构:
Thread t1=new Thread(()->{
x=b;//重排序
a=1;
});
Thread t2=new Thread(()->{
y=a;//指令重排序
b=1;
});这时候如果t1和t2同时执行,就会得到x=0,y=0的情况。
这就是重排序的一种潜在问题。
CPU在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
-
1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
-
3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上 去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图所示。

上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序可能会导致多线程程序 出现内存可见性问题。例如下面的代码:
a=b+c;
d=a+e;
f=g+h;
i=f+j;前两行有引用关系,因此d=a+e必须在a=b+c之后执行,后面的两行也一样。如果CPU检测到这两组不相关,就可以在一个CPU 上执行,而另外一组在其他CPU上执行。
假设第二个CPU执行的更快,此时就可能出现靠后的代码靠前执行的情况。
那如何解决因为重排序导致的可见性问题呢?
对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排 序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要 求Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel称之为 Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
除此之外,CPU的设计者提供了一个内存屏障指令,开发者可以再合适的位置插入内存屏障指令,相当于告诉CPU之间之间的关系,避免CPU执行时进行重排序。
大多数处理器都会提供内存屏障指令,这个指令主要是读屏障、写屏障和读写屏障。而操作系统必然要利用这些指令封装成特定的接口来供上层代码调用,例如Linux系统的是smp_mb()、smp_rmb()和smp_wmb()。
JVM对其进一步封装成了四个方法。为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM把内存屏障指令分为4类,如表所示。
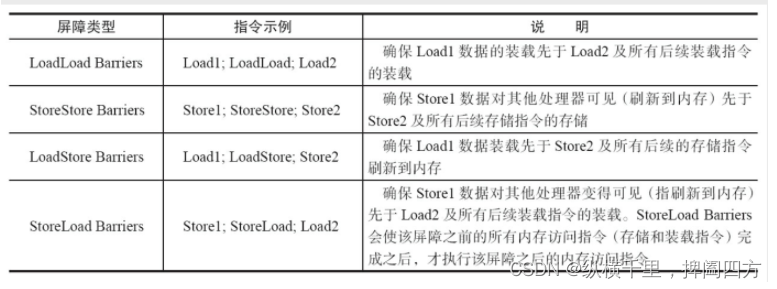
如果想进一步理解内存屏障是怎么工作的,需要从CPU内存系统入手,例如Store Buffers等,比较复杂。后面研究清楚了再写。
















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











