







介绍
最近邻法(k-Nearest neighbor method,或k-NN)是另一种非常流行的分类方法,有时也用于回归问题中。这和决策树一样,是最容易理解的分类方法之一。该方法遵循紧密度假设:如果样本之间的距离测量得足够好,那么相似的样本更有可能属于同一类。
应用场景
- 在实际应用中,k-NN方法在某些情况下可以作为良好的起点(基线);
- 在Kaggle竞赛中,k-NN通常用于构建元特征(即k-NN预测作为其他模型的输入)或用于叠加/混合;
- 最近邻方法扩展到其他任务,如推荐系统。最初的决定可能是一个产品(或服务)的推荐,该产品(或服务)在我们想要为其推荐的人的最近的邻居中很受欢迎;
- 在实践中,在大型数据集上,通常对最近的邻居使用近似的搜索方法。有许多开源库实现了这种算法;
KNN的简单实践
1、分类
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
n_neighbors = 15
# import some data to play with
iris = datasets.load_iris()
# we only take the first two features. We could avoid this ugly
# slicing by using a two-dim dataset
X = iris.data[:, :2]
y = iris.target
h = .02 # step size in the mesh
# Create color maps
cmap_light = ListedColormap(['orange', 'cyan', 'cornflowerblue'])
cmap_bold = ListedColormap(['darkorange', 'c', 'darkblue'])
for weights in ['uniform', 'distance']:
# we create an instance of Neighbours Classifier and fit the data.
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold,
edgecolor='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weights = '%s')"
% (n_neighbors, weights))
plt.savefig("res_{}.jpg".format(weights), dpi=100)
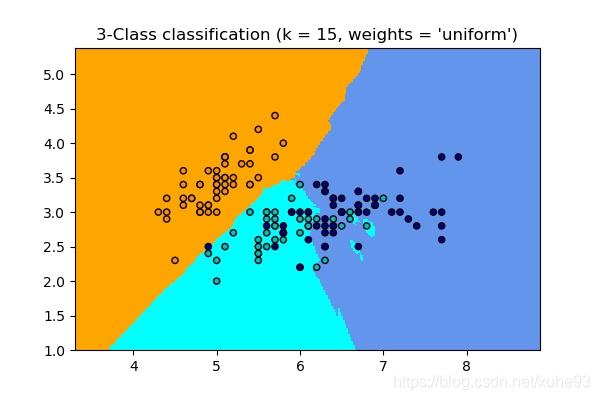
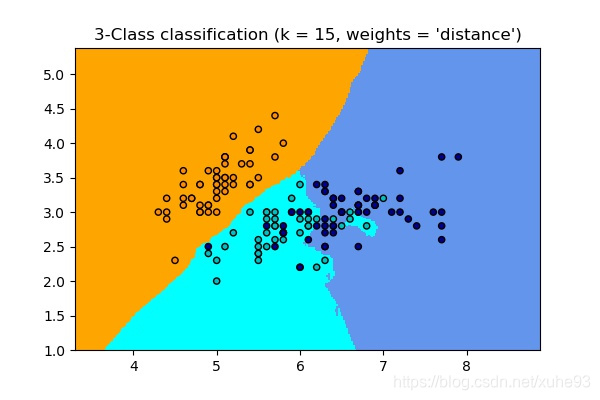
2、回归
# Generate sample data
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
np.random.seed(0)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X).ravel()
# Add noise to targets
y[::5] += 1 * (0.5 - np.random.rand(8))
# Fit regression model
n_neighbors = 5
for i, weights in enumerate(['uniform', 'distance']):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X, y).predict(T)
plt.subplot(2, 1, i + 1)
plt.scatter(X, y, color='darkorange', label='data')
plt.plot(T, y_, color='navy', label='prediction')
plt.axis('tight')
plt.legend()
plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors,
weights))
plt.tight_layout()
plt.savefig("regressor.jpg".format(weights), dpi=100)

理论
1)公式及概念
1、距离度量
k 近邻模型的特征空间一般是η 维实数向量空间
R
n
R^n
Rn 。使用的距离是欧氏距离, 但也可以是其他距离,如更一般的
L
p
L_p
Lp 距离(
L
p
L_p
Lp distance) 或Minkowski距离(Minkowski distance) 。
设特征空间
X
X
X是
n
n
n维实数向量空间
R
n
R^n
Rn,
x
i
,
x
j
∈
X
,
x
i
=
(
x
i
(
1
)
,
x
i
(
2
)
,
⋯
,
x
i
(
n
)
)
T
,
x
j
=
(
x
j
(
1
)
,
x
j
(
2
)
,
⋯
,
x
j
(
n
)
)
T
x_{i}, x_{j} \in \mathcal{X}, x_{i}=\left(x_{i}^{(1)}, x_{i}^{(2)}, \cdots, x_{i}^{(n)}\right)^{\mathrm{T}}, x_{j}=\left(x_{j}^{(1)}, x_{j}^{(2)}, \cdots, x_{j}^{(n)}\right)^{\mathrm{T}}
xi,xj∈X,xi=(xi(1),xi(2),⋯,xi(n))T,xj=(xj(1),xj(2),⋯,xj(n))T,
x
i
,
x
j
x_i, x_j
xi,xj的
L
p
L_p
Lp距离定义为:
L
p
(
x
i
,
x
j
)
=
(
∑
l
=
1
n
∣
x
i
(
l
)
−
x
j
(
l
)
∣
p
)
1
p
L_{p}\left(x_{i}, x_{j}\right)=\left(\sum_{l=1}^{n}\left|x_{i}^{(l)}-x_{j}^{(l)}\right|^{p}\right)^{\frac{1}{p}}
Lp(xi,xj)=(l=1∑n∣∣∣xi(l)−xj(l)∣∣∣p)p1
- 当 p = 1 p=1 p=1时,称为曼哈顿距离(Manhattan distance);
- 当 p = 2 p=2 p=2时,称为欧氏距离(Euclidean distance);
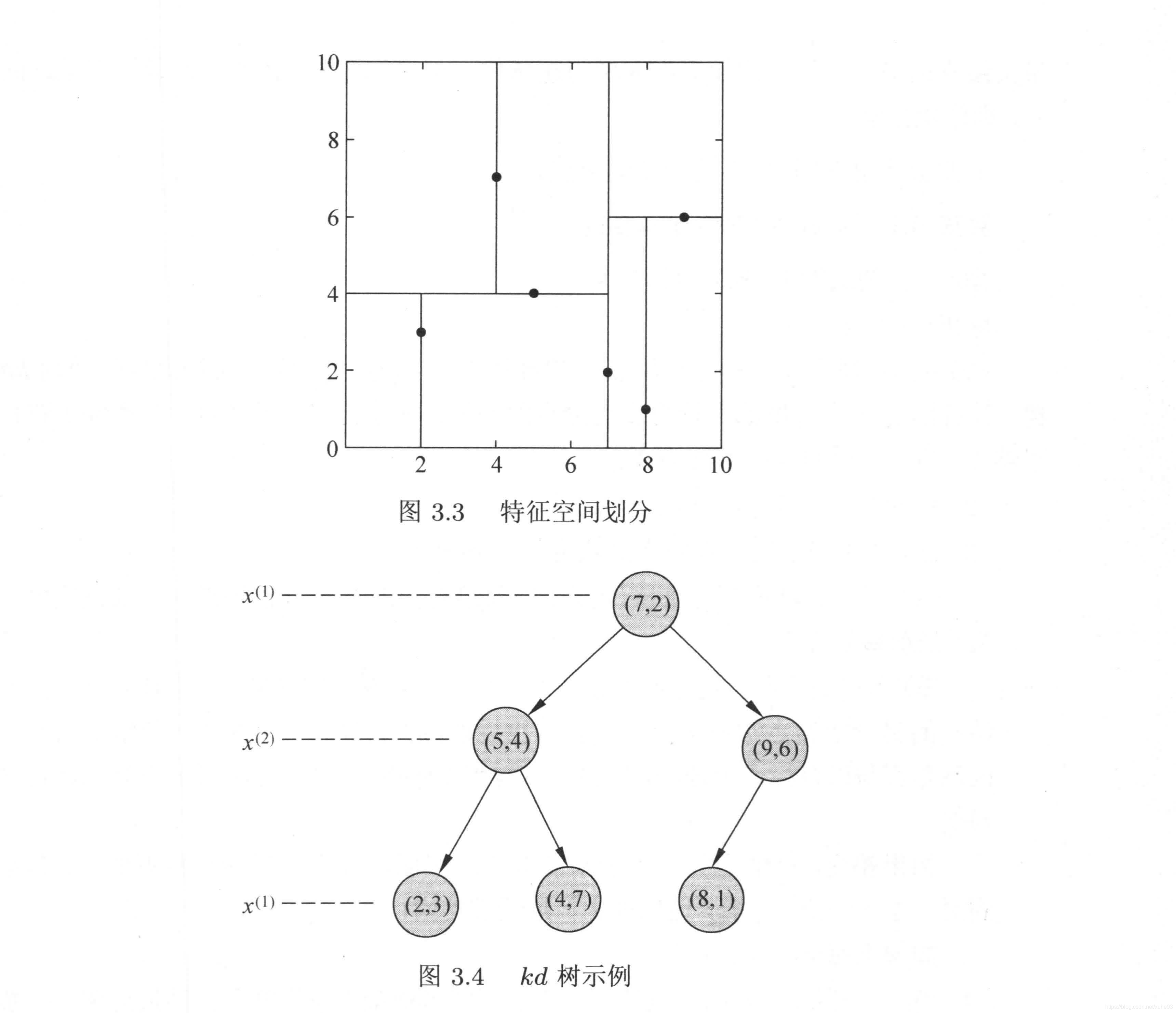
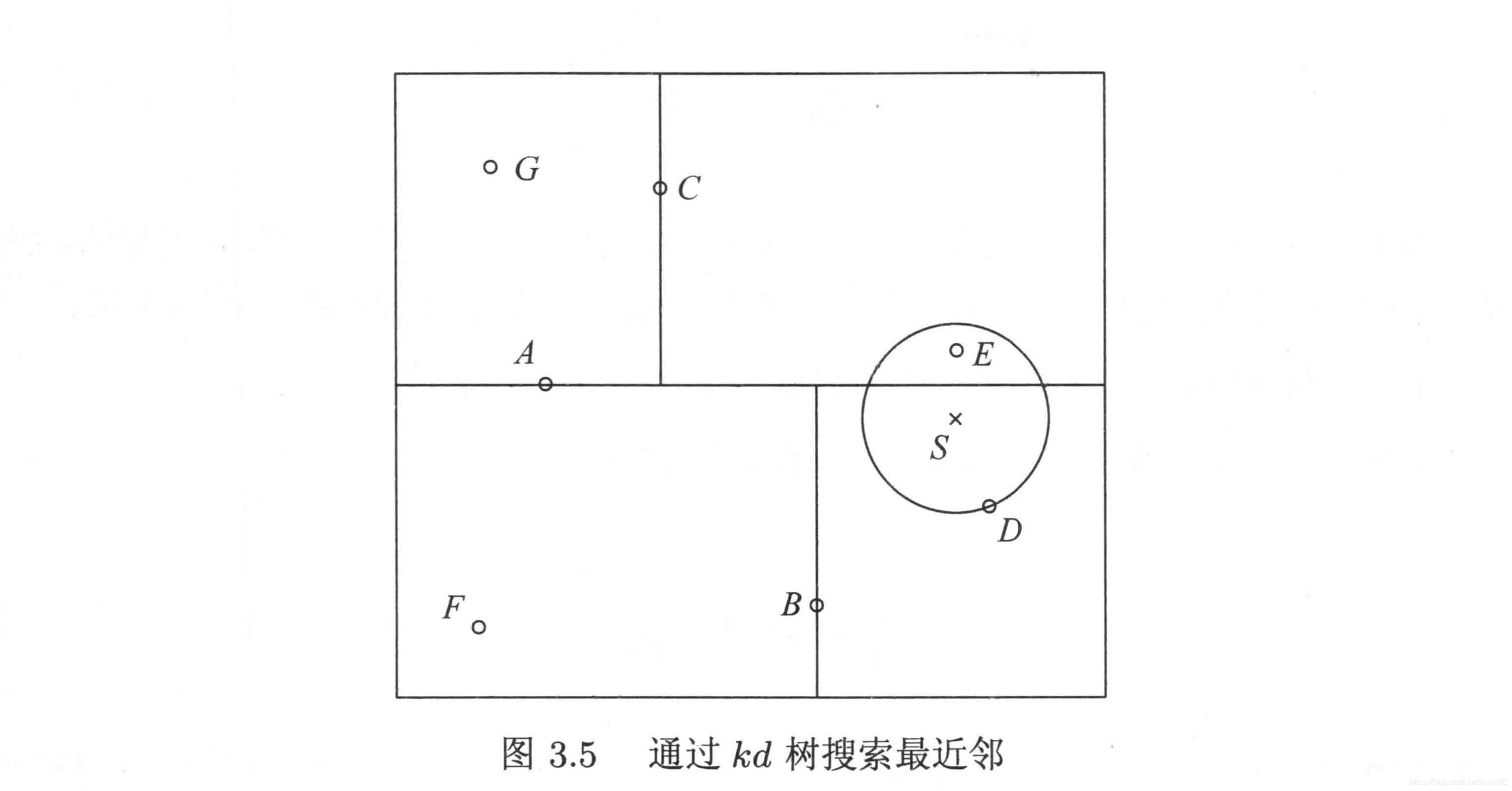
2)k 近邻法的实现: kd 树
- 构造kd 树:

- 搜索kd 树:

3)例子


python实现
# 构建kd树
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点)
self.split = split # 整数(进行分割维度的序号)
self.left = left # 该结点分割超平面左子空间构成的kd-tree
self.right = right # 该结点分割超平面右子空间构成的kd-tree
class KdTree(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set: # 数据集为空
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号
#data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(median, split,
CreateNode(split_next, data_set[:split_pos]), # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print (root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
# 对构建好的kd树进行搜索,寻找与目标点最近的样本点:
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple", "nearest_point nearest_dist nodes_visited")
def find_nearest(tree, point):
k = len(point) # 数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0] * k, float("inf"), 0) # python中用float("inf")和float("-inf")表示正负无穷
nodes_visited = 1
s = kd_node.split # 进行分割的维度
pivot = kd_node.dom_elt # 进行分割的“轴”
if target[s] <= pivot[s]: # 如果目标点第s维小于分割轴的对应值(目标离左子树更近)
nearer_node = kd_node.left # 下一个访问节点为左子树根节点
further_node = kd_node.right # 同时记录下右子树
else: # 目标离右子树更近
nearer_node = kd_node.right # 下一个访问节点为右子树根节点
further_node = kd_node.left
temp1 = travel(nearer_node, target, max_dist) # 进行遍历找到包含目标点的区域
nearest = temp1.nearest_point # 以此叶结点作为“当前最近点”
dist = temp1.nearest_dist # 更新最近距离
nodes_visited += temp1.nodes_visited
if dist < max_dist:
max_dist = dist # 最近点将在以目标点为球心,max_dist为半径的超球体内
temp_dist = abs(pivot[s] - target[s]) # 第s维上目标点与分割超平面的距离
if max_dist < temp_dist: # 判断超球体是否与超平面相交
return result(nearest, dist, nodes_visited) # 不相交则可以直接返回,不用继续判断
#----------------------------------------------------------------------
# 计算目标点与分割点的欧氏距离
temp_dist = sqrt(sum((p1 - p2) ** 2 for p1, p2 in zip(pivot, target)))
if temp_dist < dist: # 如果“更近”
nearest = pivot # 更新最近点
dist = temp_dist # 更新最近距离
max_dist = dist # 更新超球体半径
# 检查另一个子结点对应的区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离
nearest = temp2.nearest_point # 更新最近点
dist = temp2.nearest_dist # 更新最近距离
return result(nearest, dist, nodes_visited)
return travel(tree.root, point, float("inf")) # 从根节点
# 例3.2
data = [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]]
kd = KdTree(data)
preorder(kd.root)
[7, 2]
[5, 4]
[2, 3]
[4, 7]
[9, 6]
[8, 1]
ret = find_nearest(kd, [3,4.5])
print (ret)
Result_tuple(nearest_point=[2, 3], nearest_dist=1.8027756377319946, nodes_visited=4)
在scikit-learn中
sklearn.neighbors 提供了 neighbors-based (基于邻居的) 无监督学习以及监督学习方法的功能。 NearestNeighbors (最近邻)实现了 unsupervised nearest neighbors learning(无监督的最近邻学习)。 它为三种不同的最近邻算法提供统一的接口:BallTree, KDTree, 还有基于 sklearn.metrics.pairwise 的 brute-force 算法。算法的选择可通过关键字 ‘algorithm’ 来控制, 并必须是 [‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’] 其中的一个。当设置为默认值 ‘auto’ 时,算法会尝试从训练数据中确定最佳方法。
scikit-learn 实现了两种不同的最近邻分类器:
- 基于每个查询点的 k 个最近邻实现,其中 k 是用户指定的整数值adiusNeighborsClassifier 基于每个查询点的固定半径 r 内的邻居数量实现, 其中 r 是用户指定的浮点数值。
- k -邻居分类是KNeighborsClassifie的技术中比较常用的一种。 值的最佳选择是高度依赖数据的:通常较大的 k 是会抑制噪声的影响,但是使得分类界限不明显。
scikit-learn 实现了两种不同的最近邻回归:
- KNeighborsRegressor 基于每个查询点的 k 个最近邻实现,其中 k 是用户指定的整数值。
- RadiusNeighborsRegressor 基于每个查询点的固定半径 r 内的邻点数量实现,其中 r 是用户指定的浮点数值
KNeighborsClassifie相关参数:
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier
RadiusNeighborsClassifier 相关参数:
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.RadiusNeighborsClassifier.html#sklearn.neighbors.RadiusNeighborsClassifier
KNeighborsRegressor 相关参数:
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html#sklearn.neighbors.KNeighborsRegressor
RadiusNeighborsRegressor 相关参数:
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.RadiusNeighborsRegressor.html#sklearn.neighbors.RadiusNeighborsRegressor
调优
使用k- nn进行分类/回归的质量取决于几个参数:
- 近邻k的数量。
- 样本之间的距离度量(常见的有Hamming距离、Euclidean距离、余弦距离和Minkowski距离)。请注意,大多数这些指标都需要对数据进行伸缩。
- 邻居的权重(每个邻居可能贡献不同的权重;例如,样本越远,重量越低)。
from sklearn.pipeline import Pipeline
knn_pipe = Pipeline([('scaler', StandardScaler()), ('knn', KNeighborsClassifier(n_jobs=-1))])
knn_params = {'knn__n_neighbors': range(1, 20), 'knn__weights': ['uniform', 'distance']}
knn_grid = GridSearchCV(knn_pipe, knn_params,
cv=5, n_jobs=-1, verbose=True)
knn_grid.fit(X, y)
knn_grid.best_params_, knn_grid.best_score_
Fitting 5 folds for each of 38 candidates, totalling 190 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 2.5s
[Parallel(n_jobs=-1)]: Done 190 out of 190 | elapsed: 6.5s finished
({'knn__n_neighbors': 5, 'knn__weights': 'uniform'}, 0.78)
Reference:
[1] https://sklearn.apachecn.org/docs/master/7.html
[2] 统计学习方法 第二版 李航



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











