










讲师: 刘奇(goroutine)
个人简介:
PingCAP创始人兼CEO。分布式系统专家,擅长分布式数据库,分布式缓存。目前从事NewSQL方向的创业,通过开源方式重建google内部的F1和spanner。目前项目已经开源,https://github.com/pingcap/tidb
大家好, 我是开源项目 分布式 NewSQL 数据库 TiDB 和 分布式缓存 Codis 的 创始人 刘奇, 之前在京东, 豌豆荚做 infrastructure 相关的事情, 现在在创业 (PingCAP), 方向是分布式数据库. 最近如果有朋友关注开源社区或者HackerNews 的话,可能会发现一个叫 TiDB 的数据库项目吸引了一些眼球(https://github.com/pingcap/tidb ) 。 这是我们开源的第一个东西,短短几天得到了过千Star,特别感谢大家的支持和鼓励。
今天主要介绍一下 NewSQL 与 TiDB 的设计实现, 未来的一些 Roadmap 以及 一些做开源项目的心得。
大家可能经常用数据库,但是很少写一个数据库(实在是有点 hardcore),今天我就从一个开发者的角度,来看看如何写一个分布式数据库,因为这个话题实在太大,我试着讲一下,讲的不好请各位海涵 :D
数据库系统架构如何分层
某种程度上看来,数据库作为整个系统的核心,这句话其实并不夸张,数据库的选型关系到上层业务代码实现的方方面面,现在比较流行的架构方案是上层业务逻辑微服务化,并且结合分布式缓存,这套框架已经基本能做到上层业务的弹性扩展,但是最底层的数据存储还是很难去中心化(除非整个技术栈中去除关系型数据库(RDBMS), 全部采用 NoSQL)。所以,经常是 RDBMS 成为整个系统的瓶颈。
在长期的斗争中,大家总结出了很多方式来扩展最底层的关系型数据库:
- 主从,一主多从,双写,通过队列暂存请求… 这些方案其实并没有解决问题,写入仍然是单点,而且对于 DBA 的挑战比较大,今天我们暂时就不讨论了。
通过中间件 Sharding,常见的开源方案有: Cobar, TDDL, Vitess, Kingshard, MyCat 等,这些方案的思路是拦截 SQL 的请求通过 sharding key 和一定规则,将请求转发/广播到不同的 MySQL 实例上,从而实现水平扩展的效果,这个方案基本解决了单点写入的问题,对于业务来说整体的吞吐也上来了,看上去不错,这个方案是大多数业务遇到性能瓶颈的解决方案,但是缺点也是有的:
1)大多中间件都没有解决动态扩容的问题,多采用了静态的路由策略,扩容一般还处于人工 x2 的状态,对 DBA 要求比较高。
2)从一定程度上来说都放弃了事务,这是由于一条语句有可能会涉及到多个数据库实例,实现分布式 事务是一个比较难的事情,我们后面会详细的介绍。
3)对业务不透明,需要指定 sharding key, 心智负担较大
特别是第二点,由于放弃事务,对于上层业务的程序的写法带来很多的影响,有一些中间件支持部分的事务,但是需要使用者保证参与事务的行都会落在一台实例上(例如 sharding key 选为 userid 按照同一个 user_id 下的多行进行事务操作,)对于一些简单的业务来说还比较好,但是一旦对于一致性的要求比较高的业务,就会给开发者带来了比较大的心智负担,比如通过队列绕开(http://blog.jobbole.com/89140/ )等技巧。
因为上述原因,有些业务就抛弃了 RDBMS,直接上 NoSQL,常见的选型方案是:HBase,MongoDB, Cassandra 等,简单介绍一下:
HBase 来自 Google 的 Big Table 的论文,底层存储依赖 HDFS 来实现扩展性,通过对 Key 进行 Range 化、列式存储(多 Region )的管理,使整个集群达到比较高的随机读写性能(吞吐),比较适用于海量小 Key/Value 读写业务,强一致性,支持多版本,支持 Table 和半结构化的数据存储。但是缺点是并不支持复杂查询,同时并没有支持跨行事务。我认为 HBase 是一个 CP 的系统。没有官方的 SQL 支持,有一些第三方的公司做了 SQL on HBase (比如 Phoenix)但是大多都用于 OLAP 领域,面向 OLTP 的不多。
Cassandra 来自 Dynamo 的模型,比较大的特点是,C* 可以根据业务的需求进行决定它是 CP 还是 AP(最终一致性),C* 采用的 WRN 模型,当 W + R > N 的时候是 CP 系统,W+R <= N 时是 AP 系统,但是拥有最终一致性,其中 W 代表写入几个节点算成功,R 表示读几个节点算成功,N 是可写入多少节点。C* 2.0+ 支持了 CAS 算是支持了单行事务。C* 的读写性能略优于 HBase(http://www.planetcassandra.org/nosql-performance-benchmarks/)但是我认为吧,在分布式系统中的单机 benchmark 其实意义不大,因为系统都是可以水平扩展的,能满足需求即可。
MongoDB Cluster 网上吐槽的非常多,个人不太熟悉,就不评论了。
以上 NoSQL 的问题是,接口表达力相比 SQL 而言差了很多,对于很多现有业务来说,从 RDBMS 重构至 NoSQL 基本无异于重写。所以问题就来了,我们能不能既享受 NoSQL 带来的扩展能力,同时又不丢失像单机一样的事务能力,并且还能使用 SQL?
在仔细思考过这个问题后,其实并非不可能,而且实际上,有很多公司都已经尝试过造出了这类称为 NewSQL 的产品,比如 Google 的 Spanner 和 F1 (http://research.google.com/pubs/pub41344.html ),被 Apple 收购的 FoundationDB, 近年出现的 CockroachDB,TiDB 等,都是主打提供 SQL 及分布式事务的数据库产品。
这类数据库的模型都比较统一:即在下层提供一个支持事务的分布式 KV 层,上层构造 SQL Layer,将 SQL 语句翻译成 KV 的事务操作,进而实现在分布式存储上的带事务的 SQL 的支持。实际上单机数据库的模型也在往这个方向上靠,比如 sqlite4, MySQL。
我们接下来从上到下,以 TiDB 为例看看如何实现一个分布式数据库,先上架构图
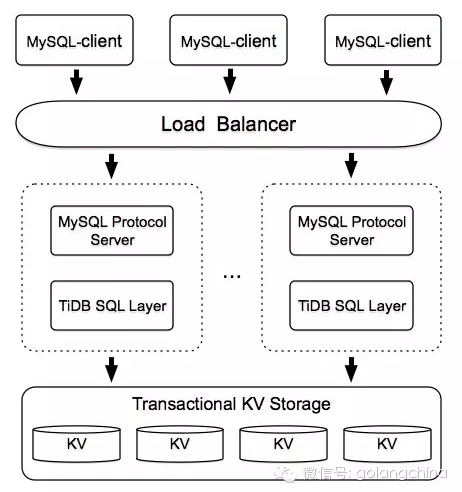
由于篇幅原因,以下主要说说 SQL Layer 和 KV。
SQL Layer
写一个 SQL Layer 第一步考虑的是 Lexer 和 Parser ,做词法和语法解析,生成语法树。值得一提的是,整个 TiDB是用纯 Go 开发的,在 Go 的世界里,官方是推荐使用 yacc 来进行语言应用的开发,Go 官方也提供了 yacc 的工具。至于 yacc 的语法在这里就不提了,我们使用了一个开源的 Parser 生成器, cznic/goyacc 和 cznic/ebnf2y (打个广告: http://github.com/cznic 这个歪国朋友做了很多 go 来开发语言应用的工具,同时还是一个 go 的嵌入式数据库 ql 的作者,目前也在给 TiDB 贡献 Parser 部分的代码) 。其中 ebnf2y 是一个 EBNF to Yacc 的转换工具,可以通过 EBNF(主要是 EBNF 比较好写 :D ) 生成一个 Go 版本的 yacc 文件。然后用这个 yacc 文件通过 goyacc 生成 Paser 的 Go 代码。词法分析器是通过 cznic/golex 工具生成的。详细的例子可以参考 TiDB 根目录下的 parser 文件夹和 Makefile,有完整的实现。
TiDB 是支持大部分常用的 MySQL 语法的(CRUD, JOIN,GROUP BY…)Anyway 虽然比较苦逼,这步算是基本完成了,现在 TiDB 应该拥有 Go 的项目中最完整的 MySQL yacc/lex 文法实现,可以生成语法树。而且相对独立,如果有朋友对类 SQL 的语法感兴趣,想实现一个小数据库的话,可以参考一下 :)
运行时通过 Parser 编译 SQL 语句拿到 AST(抽象语法树)后,下一步是生成查询计划,会根据不同的语句类型,生成执行计划 Plan。值得注意的是,Plan 并不是的一个孤立的东西,多个 Plan 其实是可以叠加执行的。形成一个 Plan Tree。
例如一个最简单的例子: SELECT * FROM t WHERE id > 0;
通过 Parser 会生成一个 SelectStmt 对象,它的 Plan 是 :第一步会从AST 结构的 From 成员中生成一个 TableDefaultPlan(t)(默认扫全表,从头到尾)。然后从 Where 子句中构造出 Plan 的时候会将上一步生成的 TableDefaultPlan 作为参数传入, 然后根据 Where 的表达式来决定到底是不是转换成 IndexPlan(使用索引扫表)或者是直接生成一个 FilterDefaultPlan(在上一个 Plan 的执行过程中上叠加一个 Filter 操作)。简单来说,Plan 就是根据语句的语法元素来决定应该如何对数据集进行扫描,生成结果集的一系列方法。在传统的数据库中,生成好 Plan Tree 以后,会进行执行计划的优化,有很多查询优化的理论就不一一细说了,目前 TiDB 并没有太多的查询优化(但是最基本的索引识别还是有的),目前的理论多是针对单机的数据库的查询优化,但是在分布式系统中如何进行优化,是一个有待探讨的课题,我们未来也会在这方面进行一些尝试。
这里就不细说了,这个话题展开能写一本书。。。实际上我们也确实准备写本书,而且 REPO 也建立了,见 https://github.com/ngaut/builddatabase
到这一步为止还是停留在比较正统的 SQL Layer 的实现阶段,下面我们介绍事务 KV 引擎,这部分是实现整个系统的核心。
分布式事务
当你有一个支持跨行事务的 kv 层时,在上层构建 SQL 引擎就会方便很多。但是就像上文提到的目前的 NoSQL 很少有能支持这个的,但是也不是没法搞,而且基本上就只有一种办法,2PC(二阶段提交),或者性能更差的 3PC, 很多算法都是在 2PC 上进行的优化。简单提一下 2PC,在事务开始的时候,协调者第一阶段会将要修改的内容发给各个事务的参与者,参与者将事务内容写入本地 WAL 后回复OK给协调者,当协调者收到所有的参与者回复后,协调者再次向所有参与者发送 Commit(或者 Abort) 指令,并在事务状态表里标记该事务为成功(失败)。
在 2PC 中我们还是可以看到几个不太协调的东西,一个协调者的选取,另一个是事务状态表的一致性如何保证,还有就是如何实现事务的隔离性。
先说协调者的问题,在传统的 2PC 中,为了实现分布式事务的一致性(先提交的事务的结果,需要被后发起的事务看到),当有多个协调者的时候,如何实现事务的时序呢?单协调者肯定不能忍受,在这点上 Google 有很多尝试,比如在 Percolator 中采用中心授时服务器(不会是单点,应该是一个 Paxos Group),在 Spanner 中使用高度同步的原子钟,就是为了解决标记事务的先后。
事务状态表,这个是用来查询已成功事务的,在第二阶段的 Commit 过程中,理论上协调者是不需要收到所有参与者的返回的,因为收到第一阶段所有参与者的成功返回后(写入 WAL),就可以标记事务成功,如果第二阶段有人挂了,当它恢复的时候,第一步会去事务状态表中询问这个事务是否已经被标记成功,如果成功的话,就写入本地库,如果不成功的话,就丢弃 WAL。这个状态表修改是不需要跨行事务的,所以使用传统的做法,sharding 或者按照 range 存储即可,但是考虑到这个表的读请求可能会比较大(因为新开始事务需要知道当前最新的事务号,以支持 MVCC),可以通过 Paxos 做多副本。
接下来说到事务的隔离性,在我们的系统中,提供 SI 和 SI+ 乐观锁 两个级别,对应到 MySQL 里面SI+ 乐观锁 可以理解为 select for update 语句,但行为略有不同。所以,我们需要实现 MVCC,上一段中我们已经知道每个事务都会对应一个事务编号,而且这个事务编号是全局有序的。
当我开始新事务 y 的时候,我需要得知我当前的最新已提交事务号 x,然后在我的 y 事务中看到的整个数据库的视图都是这个事务 x 完成后的状态(即使在 y 开始后,有其他的事务 x’ 提交,y 是看不到 x’ 的内容的)。
实现这一点并不困难,底层存储引擎支持的话,比如 LevelDB 内部就已经实现了(参考 Snapshot 实现),LMDB 也是一个在 MVCC-BTree 的实现。TiDB 的可插拔的存储引擎设计可以很方便的实现。比较 tricky 的是冲突的解决策略,在实际的场景中,比如刚才 y 事务开始后,x’ 修改了 y 事务中修改的某个行 r,因为有 SI 此时 y 事务是不知道 r 已经被修改拥有更新的版本号,此时比较合理的做法是让 y 事务回滚,然后重试,在 TiDB 中也是这么做的。
TiDB 做了接口的严格分层,将 KV 存储的接口和 SQL Layer 分离得比较彻底,目前本地的存储引擎 (LevelDB, RocksDB, LMDB, BoltDB) 都已经支持,分布式引擎目前第一阶段打算采用了 HBase + Coprocessor 来实现,分布式事务模型采用 Google 的 Percolator 模型,近期将会开源。
下面我们从TIDB的代码层面看看一些更细节的实现。
首先是执行方法:
// 代码去掉错误处理以及和原理无关的代码
func (s *session) Execute(sql string) ([]rset.Recordset, error) {
statements, err := Compile(sql) // 编译 SQL 语句
var rs []rset.Recordset
for _, st := range statements {
r := runStmt(s, st) // 执行语句
rs = append(rs, r)
}
return rs, nil
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
明显可以看到代码分为编译和执行两个步骤,相信很多同学再一次想起大学的编译原理课程了吧 :)
我们再来看看编译过程,也可以看到明确的两个步骤,词法分析和语法分析
// Compile is safe for concurrent use by multiple goroutines.
func Compile(src string) ([]stmt.Statement, error) {
l := parser.NewLexer(src) // 生成一个词法分析器
if parser.YYParse(l) != 0 { // 语法分析,得到语法树
return nil, errors.Trace(l.Errors()[0])
}
return l.Stmts(), nil
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
看看最后生成的语法树长什么样子:
// SelectStmt is a statement to retrieve rows selected from one or more tables.
// See: https://dev.mysql.com/doc/refman/5.7/en/select.html
type SelectStmt struct {
Distinct bool
Fields []*field.Field
From *rsets.JoinRset
GroupBy *rsets.GroupByRset
Having *rsets.HavingRset
Limit *rsets.LimitRset
Offset *rsets.OffsetRset
OrderBy *rsets.OrderByRset
Where *rsets.WhereRset
// select for update
Lock coldef.LockType
Text string
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
接下来我们以查询为例再来看下,select语句构造逻辑大概是这样的:
// The whole phase for select is
// `from -> where -> lock -> group by -> having -> select fields -> distinct -> order by -> limit -> final`
func (s *SelectStmt) Plan(ctx context.Context) (plan.Plan, error) {
var (
r plan.Plan
err error
)
if s.From != nil {
r, err = s.From.Plan(ctx)
}
if w := s.Where; w != nil {
r = rsets.WhereRset{Expr: w.Expr, Src: r}).Plan(ctx)
}
// Get select list for futher field values evaluation.
// select * from table; 将 * 转化为具体的field
selectList, err := plans.ResolveSelectList(s.Fields, r.GetFields())
switch {
case !rsets.HasAggFields(selectList.Fields) && s.GroupBy == nil:
// If no group by and no aggregate functions, we will use SelectFieldsPlan.
r = (&rsets.SelectFieldsRset{Src: r, SelectList: selectList}).Plan(ctx)
default:
r = (&rsets.GroupByRset{By: groupBy, Src: r, SelectList: selectList}).Plan(ctx)
}
if s := s.Having; s != nil {
r = rsets.HavingRset{
Src: r,
Expr: s.Expr}).Plan(ctx)
}
if s.Distinct {
r= rsets.DistinctRset{Src: r,
SelectList: selectList}).Plan(ctx)
}
if s := s.OrderBy; s != nil {
rsets.OrderByRset{By: s.By,
Src: r,
SelectList: selectList}).Plan(ctx)
}
if s := s.Offset; s != nil {
rsets.OffsetRset{Count: s.Count, Src: r}).Plan(ctx)
}
if s := s.Limit; s != nil {
rsets.LimitRset{Count: s.Count, Src: r}).Plan(ctx)
}
rsets.SelectFinalRset{Src: r,
SelectList: selectList}).Plan(ctx)
return r, nil
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
有兴趣的同学可以看下具体的代码,这里我们就先不介绍了,我们继续:)
SQL层如何映射到KV层
最终所有的操作都会映射到 KV 层,我们来看一个简单的例子,假设有一个 user 表:
| RowID (隐藏列) | uid | name | |
|---|---|---|---|
| 1 | xx | bob | bob@gmail.com |
如果支持 select uid, name, email from user; 最终会变成哪些 KV 操作呢? 在 TiDB 里面,所有的表都有一个唯一的ID, 所有的列也都有唯一的ID,假设 user 表的 ID 为1, uid 的 ID 为2,name的 ID 为3, email的 ID 为 4。那么最后存储在 KV 层的大概是这样的:
整个key的逻辑结构:
TableID : RowID : ColumnID
一个具体的例子
Key Value
1 : 1 : 1 nil
1 : 1 : 2 xx
1 : 1 : 3 bob
1 : 1 : 4 bob@email.com
第一个1是表的 ID, 第二个是RowID, 第三个是列的 ID,冒号表示分隔符
上面的SQL语句最终会被映射成指令:
uid := kv.Get( “ 1 : 1 : 2 ” )
name := kv.Get( “ 1 : 1 : 3 ” )
email := kv.Get( “ 1 : 1 : 4 ” )
其它语句类似,会被翻译成相应的 Put 和 Delete 操作,详细的请参考 TiDB 源码。
下面我们聊聊 TiDB 的索引实现
还是以上面的表为例,在name上面建立唯一索引,最后存储的索引KV大概是这样的(idx表示index):
Key Value
1 : Idx : 3 : bob 1
这里的Value就是实际上的RowID
这样如果遇到语句 select email from user where name = ‘bob’; 的时候就会自动通过索引来找到 RowID,然后通过 RowID 做一次 kv.Get 操作就能拿到。
类似的,非唯一索引可以通过添加一个RowID的后缀到 key 后面,假设系统里面有两个 bob, 那么实际存储格式大概是这样的:
Key Value
1 : Idx : 3 : bob : 1 1
1 : Idx : 3 : bob : 2 2
实际的代码做了适当的优化,这里只是为了便于理解。
聊到这里,是不是大家对如何实现多引擎支持都比较好奇呢?我们继续看看这个:)
默认 TiDB 单机模式使用 Goleveldb 和 BoltDB 作为存储引擎和测试引擎,因为这两个都是纯go实现,没有依赖,但性能都不好 :(
我们来看看 Transaction的接口,从这个接口也能看出对底层存储引擎的要求
// Transaction defines the interface for operations inside a Transaction.
type Transaction interface {
// Get gets the value for key k from KV store.
Get(k Key) ([]byte, error)
// Set sets the value for key k as v into KV store.
Set(k Key, v []byte) error
// Seek searches for the entry with key k in KV store.
Seek(k Key, fnKeyCmp func(key Key) bool) (Iterator, error)
// Deletes removes the entry for key k from KV store.
Delete(k Key) error
// Commit commites the transaction operations to KV store.
Commit() error
// Rollback undoes the transaction operations to KV store.
Rollback() error
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
由于需要 seek,所以底层的存储引擎的 KV 必须是有序的,能够 scan。对于一个事务内的所有写操作都是先 buffer 住,最后 commit 时才提交,所以对单机的 KV 引擎来讲,支持 Batch 写入的原子操作即可,即使不支持也可以通过 lock 的方式来搞定。同时由于合理的抽象, TiDB 能够轻松支持多个存储引擎。TiDB 自然也可以作为一个很好的 bench 工具, 大家可以用来bench 各种存储引擎了 :)
为了便于大家理解,或者想给TiDB添加新的引擎支持,我们写了 lmdb 的引擎的例子,只用了大约200行代码,见 https://github.com/pingcap/tidb-lmdb
开源的心得
下面想和大家聊一下怎么做开源,算是这几个月来的小小的感悟吧。
关于如何做开源,在中国鲜有认真做开源项目的商业公司,这和整个浮躁的大环境是分不开的,很多国内的开源项目基本就只是 Push 代码到 Github 上而已,有的甚至就再也不更新了。我个人认为优秀的开源项目是社区和商业公司支持缺一不可的,特别是基础软件领域。
TiDB 的目标是做一个全球性的开源项目,所以我们非常刻意的去营造社区的氛围,比如我们选择一个比较早期的版本的时间点开源,早期一些比较容易修改和上手的 Bug 会可以留下来,吸引社区的爱好者来修改。Github 已经搭建了一个非常好的代码协作平台,我们不管是公司内部的私有项目还是外部的开源项目,都是完全通过 Github 协作的(有机会我可以讲讲我们 PingCAP 的工作流)
btw,提交的 patch 被合并到主干后,我们都会给这个 contributor 邮寄一件我们的 t-shirt :)
另外提交 PR 也需要相应的标准和格式,TiDB 的标准见 https://github.com/pingcap/tidb/blob/master/docs/CONTRIBUTING.md
对于TiDB而言,通过
https://github.com/pingcap/tidb/issues/158
参与项目是最好的切入点,由于MySQL有大量 builtin 的函数,目前TiDB只实现了一部分。
比较值得注意的是,文档,README 和 Issues 及讨论必须需要英文书写,否则很难吸引外国的社区贡献,这个也是大多数国内开源项目通病。
TiDB 的计划是:
1. 继续完善 SQL 层,更完整的兼容 MySQL 语法。
2. 实现异步 Schema 变更,在分布式系统中,DDL 是不容许阻塞的,这个算法比较巧妙,可以参考 Google 的一篇论文(http://research.google.com/pubs/pub41376.html)
3. 继续开发 HBase 的引擎,第一个可以在生产环境中使用的版本应该是搭载 HBase 引擎的
4. 更长期的计划是去掉 HBase,构建自己的 Kv 层,毕竟 HBase 并不是为 SQL 优化的 Kv,而且在依赖太重,我个人不太喜欢 Hadoop,非常难容器化。
5. 多租户
6. 容器化
由于时间关系,我们今天的分享就先到这里了,感谢大家的支持:)
以后有机会,我们再聊聊下面的东西:
HBase的分布式事务实现,以及TiDB如何让HBase拥有SQL能力
MySQL协议支持,更重要的哲学问题是为什么选择支持MySQL协议
如何在KV的引擎上实现行锁
隔离级别的选择,select for update语句的特殊处理
如何用HLC实现去中心化的事务管理
在线异步动态schema变更
Q&A
事务状态表如何解决单点问题
多副本,比如通过Paxos或者Raft等一致性协议TiDB和MySQL的区别是什么?能不能编译到一起Go应用里面
可以把 TiDB 理解成一个无比强大的分布式 MySQL, MySQL 自身主要是单机的。
可以和Go应用编译到一起:)TiDB目前的roadmap是什么?什么时候可以应用于产品中,后期API会不会改变很多?
TiDB 的计划是:- 继续完善 SQL 层,更完整的兼容 MySQL 语法。
- 实现异步 Schema 变更,在分布式系统中,DDL 是不容许阻塞的,这个算法比较巧妙,可以参考 Google 的一篇论文(http://research.google.com/pubs/pub41376.html)
- 继续开发 HBase 的引擎,第一个可以在生产环境中使用的版本应该是搭载 HBase 引擎的
- 更长期的计划是去掉 HBase,构建自己的 Kv 层,毕竟 HBase 并不是为 SQL 优化的 Kv,而且在依赖太重,我个人不太喜欢 Hadoop,非常难容器化。
- 多租户
- 容器化
我们目前主要兼容 MySQL 协议,所以接口比较稳定,直接使用 MySQL 客户端就可以,现在我们已经支持了各种ORM,比如Beego, Xorm等等。
分布式事务目前是否只支持hbase
是的,暂时是的Why choose golang to build a database?
Golang的开发和运行效率都很理想,Go语言官方有很好的规范,统一的风格和标准,我们都很喜欢它:)请问事务更新冲突为什么不采用行级锁?其他被回滚的事务如果在被发现冲突前已经结束怎么处理?
TiDB 采用了行锁,上面也提到,由于时间关系,没有来得及详细讲,后面的问题没看明白,请详细描述下:)分布式kv如何做到任意扩展?
Sharding, split, merge如采用raft之类做事务状态表,对吞吐量有多大影响?
事务状态表也可以分配一个key,让状态合理散落到整个分布式系统里面,不存在性能瓶颈是否对比过如mysql ndb cluster,相对这类实现有哪些优缺点?
MySQL上面的cluster由于局限于MySQL本身,在分布式上面受到的约束很多,类似PG的xc,好多年都很难有突破性的进展,这方面其它的分布式数据库基本都选择了一开始就朝着分布式去做设计,优缺点见上面的 roadmap, 里面很多东西基于MySQL的方案都很难搞定“事务状态表,这个是用来查询已成功事务的,在第二阶段的 Commit 过程中,理论上协调者是不需要收到所有参与者的返回的,因为收到第一阶段所有参与者的成功返回后(写入 WAL),就可以标记事务成功,如果第二阶段有人挂了,当它恢复的时候,第一步会去事务状态表中询问这个事务是否已经被标记成功,如果成功的话,就写入本地库,如果不成功的话,就丢弃 WAL。”——这个能否再说明一下,既然第二阶段有人挂了,为什么去查询第一阶段为成功以后,还是继续写入本地?
由于多副本存在,而且前面已经有了wal,所以其它副本会接替挂了的,继续apply wal就行抽象语法树这块是不是类似web中的路由树的构建?
这个有点像,又不太像,抽象语法树一般用于编译领域比较多NuoDB对比F1 TiDB 如何?
NuoDB不太清楚,也没怎么见到用户使用,TiDB 基本上是朝着F1作为目标去的,F1是Google出品目前全球最好的分布式OLTP数据库















 3127
3127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









