









图的基本算法(BFS和DFS)
![]() 卡巴拉的树
卡巴拉的树 ![]() 关注
关注
2016.07.29 16:43* 字数 1103 阅读 24659评论 22喜欢 69赞赏 2
图是一种灵活的数据结构,一般作为一种模型用来定义对象之间的关系或联系。对象由顶点(V)表示,而对象之间的关系或者关联则通过图的边(E)来表示。
图可以分为有向图和无向图,一般用G=(V,E)来表示图。经常用邻接矩阵或者邻接表来描述一副图。
在图的基本算法中,最初需要接触的就是图的遍历算法,根据访问节点的顺序,可分为广度优先搜索(BFS)和深度优先搜索(DFS)。
广度优先搜索(BFS)
广度优先搜索在进一步遍历图中顶点之前,先访问当前顶点的所有邻接结点。
a .首先选择一个顶点作为起始结点,并将其染成灰色,其余结点为白色。
b. 将起始结点放入队列中。
c. 从队列首部选出一个顶点,并找出所有与之邻接的结点,将找到的邻接结点放入队列尾部,将已访问过结点涂成黑色,没访问过的结点是白色。如果顶点的颜色是灰色,表示已经发现并且放入了队列,如果顶点的颜色是白色,表示还没有发现
d. 按照同样的方法处理队列中的下一个结点。
基本就是出队的顶点变成黑色,在队列里的是灰色,还没入队的是白色。
用一副图来表达这个流程如下:
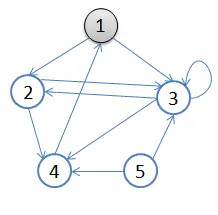
1.初始状态,从顶点1开始,队列={1}
2.访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}
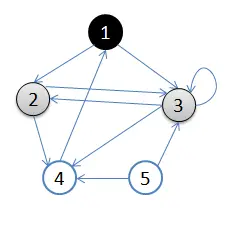
3.访问2的邻接结点,2出队,4入队,队列={3,4}
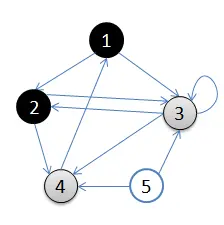
4.访问3的邻接结点,3出队,队列={4}
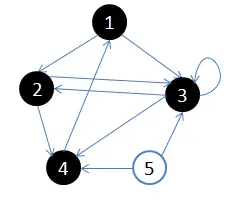
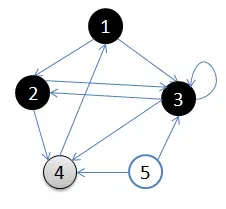
5.访问4的邻接结点,4出队,队列={ 空}
从顶点1开始进行广度优先搜索:
- 初始状态,从顶点1开始,队列={1}
- 访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}
- 访问2的邻接结点,2出队,4入队,队列={3,4}
- 访问3的邻接结点,3出队,队列={4}
- 访问4的邻接结点,4出队,队列={ 空}
结点5对于1来说不可达。
上面的图可以通过如下邻接矩阵表示:
int maze[5][5] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 1, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 0, 0, 0, 0 },
{ 0, 0, 1, 1, 0 }
};
BFS核心代码如下:
#include <iostream>
#include <queue>
#define N 5
using namespace std;
int maze[N][N] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 1, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 0, 0, 0, 0 },
{ 0, 0, 1, 1, 0 }
};
int visited[N + 1] = { 0, };
void BFS(int start)
{
queue<int> Q;
Q.push(start);
visited[start] = 1;
while (!Q.empty())
{
int front = Q.front();
cout << front << " ";
Q.pop();
for (int i = 1; i <= N; i++)
{
if (!visited[i] && maze[front - 1][i - 1] == 1)
{
visited[i] = 1;
Q.push(i);
}
}
}
}
int main()
{
for (int i = 1; i <= N; i++)
{
if (visited[i] == 1)
continue;
BFS(i);
}
return 0;
}
深度优先搜索(DFS)
深度优先搜索在搜索过程中访问某个顶点后,需要递归地访问此顶点的所有未访问过的相邻顶点。
初始条件下所有节点为白色,选择一个作为起始顶点,按照如下步骤遍历:
a. 选择起始顶点涂成灰色,表示还未访问
b. 从该顶点的邻接顶点中选择一个,继续这个过程(即再寻找邻接结点的邻接结点),一直深入下去,直到一个顶点没有邻接结点了,涂黑它,表示访问过了
c. 回溯到这个涂黑顶点的上一层顶点,再找这个上一层顶点的其余邻接结点,继续如上操作,如果所有邻接结点往下都访问过了,就把自己涂黑,再回溯到更上一层。
d. 上一层继续做如上操作,知道所有顶点都访问过。
用图可以更清楚的表达这个过程:

1.初始状态,从顶点1开始

2.依次访问过顶点1,2,3后,终止于顶点3

3.从顶点3回溯到顶点2,继续访问顶点5,并且终止于顶点5

4.从顶点5回溯到顶点2,并且终止于顶点2

5.从顶点2回溯到顶点1,并终止于顶点1

6.从顶点4开始访问,并终止于顶点4
从顶点1开始做深度搜索:
- 初始状态,从顶点1开始
- 依次访问过顶点1,2,3后,终止于顶点3
- 从顶点3回溯到顶点2,继续访问顶点5,并且终止于顶点5
- 从顶点5回溯到顶点2,并且终止于顶点2
- 从顶点2回溯到顶点1,并终止于顶点1
- 从顶点4开始访问,并终止于顶点4
上面的图可以通过如下邻接矩阵表示:
int maze[5][5] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 0, 1 },
{ 0, 0, 1, 0, 0 },
{ 1, 1, 0, 0, 1 },
{ 0, 0, 1, 0, 0 }
};
DFS核心代码如下(递归实现):
#include <iostream>
#define N 5
using namespace std;
int maze[N][N] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 0, 1 },
{ 0, 0, 1, 0, 0 },
{ 1, 1, 0, 0, 1 },
{ 0, 0, 1, 0, 0 }
};
int visited[N + 1] = { 0, };
void DFS(int start)
{
visited[start] = 1;
for (int i = 1; i <= N; i++)
{
if (!visited[i] && maze[start - 1][i - 1] == 1)
DFS(i);
}
cout << start << " ";
}
int main()
{
for (int i = 1; i <= N; i++)
{
if (visited[i] == 1)
continue;
DFS(i);
}
return 0;
}
非递归实现如下,借助一个栈:
#include <iostream>
#include <stack>
#define N 5
using namespace std;
int maze[N][N] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 0, 1 },
{ 0, 0, 1, 0, 0 },
{ 1, 1, 0, 0, 1 },
{ 0, 0, 1, 0, 0 }
};
int visited[N + 1] = { 0, };
void DFS(int start)
{
stack<int> s;
s.push(start);
visited[start] = 1;
bool is_push = false;
while (!s.empty())
{
is_push = false;
int v = s.top();
for (int i = 1; i <= N; i++)
{
if (maze[v - 1][i - 1] == 1 && !visited[i])
{
visited[i] = 1;
s.push(i);
is_push = true;
break;
}
}
if (!is_push)
{
cout << v << " ";
s.pop();
}
}
}
int main()
{
for (int i = 1; i <= N; i++)
{
if (visited[i] == 1)
continue;
DFS(i);
}
return 0;
}
有的DFS是先访问读取到的结点,等回溯时就不再输出该结点,也是可以的。算法和我上面的区别就是输出点的时机不同,思想还是一样的。DFS在环监测和拓扑排序中都有不错的应用。
PS: 图文均为本人原创,画了好几个小时,转载注明出处,尊重知识劳动,谢谢~
小礼物走一走,来简书关注我
赞赏支持

© 著作权归作者所有
 关注卡巴拉的树
关注卡巴拉的树 ![]()
写了 66570 字,被 573 人关注,获得了 1410 个喜欢
程序员专题审稿员 主业程序员,也爱读书,电影,半文艺范。希望与你分享有趣的经验和故事。我的公众号:树说新语(shushuoxinyu6),豆瓣:卡巴拉的树
喜欢 69 更多分享
https://www.jianshu.com/p/70952b51f0c8

WhyWhy
越学越不会系列。
算法录 之 BFS和DFS
说一下BFS和DFS,这是个比较重要的概念,是很多很多算法的基础。
不过在说这个之前需要先说一下图和树,当然这里的图不是自拍的图片了,树也不是能结苹果的树了。这里要说的是图论和数学里面的概念。

以上概念来自百度百科。
数学里面的图就是许多的点和许多的边把这些点连了起来,具体每个点放在那里没啥关系,重点是他们之间的连接关系。
一个图长得就像是下面这样:

这个图有6个点,8条边,其中有一条是自己连接自己的。
然后图的话有有向图,无向图等等,还有很多很多分类,比如二分图等等,可以百度百科或者维基看一下就差不多明白了。
然后树的话其实也是图,但是比较特殊而已,他有N个点,N-1条边,而且这N个点是互相连通的,那么这个图就能画成一颗树一样的样子。

倒过来看就很像一棵树。
然后下面要说的是BFS和DFS,这两个是一个缩写,全称是 BFS:Breadth-First-Search,宽度优先搜索;DFS:Depth-first search,深度优先搜索。
都是一种搜索,只不过搜索的方法不一样而已。
先说说搜索,顾名思义,搜索就是。。。搜索。对于一个图来说,搜索就是从某个点开始,不停的搜索与他相连的所有的点,然后以此接连下去,直到所有的点都被搜索到了。
然后BFS的话就是宽度优先。

比如这个图,如果从1开始进行搜索的话,BFS的步骤就是,先搜索所有和1相连的,也就是2和5被找到了,然后再从2开始搜索和他相连的,也就是3被找到了,然后从5搜,也就是4被找到了,然后从3开始搜索,4被找到了,但是4之前已经被5找到了,所以忽略掉就行。然后3开始搜索,忽略4所以啥都没搜到,然后从4开始,6被找到了。。。
就是这样,这就是BFS。。。
说完DFS比较一下两个的区别可能会比较好理解。
DFS的话从1开始,先找到其中一个相连的,2被找到了,然后直接开始从2开始搜索,3被找到了,然后从3开始搜索,4被找到了,然后从4开始搜索,5被找到了,然后从5开始搜索,忽略已经找到的所以啥都没找到。然后没路可走了,回到前面去再走另一条路,从4开始,6被找到了,然后又没路可走了,然后再回去前面4,然后没路了 ,回去前面3,然后一直这样。。。
DFS 就是像走迷宫一样一条路走到头直到走不通才回到前一个换一条路。。。就是这样。。。
DFS和BFS主要是运用于对于图和树的搜索,但是绝大部分问题模型都是可以建模变成一个图或者树的,所以差不多不少问题都会涉及到这两个。
现在知道了这个东西的实现的步骤了。下面就要说一下怎么用代码来实现他。
先说图吧,对于每个点来说就是标号1,2,3。。。。N就好,表示有N个结点,一般题目也已经标好号了。
然后边的话一般会就是 u,v 这样表示有一条边连接u点和v点。
存储一个图的边有三种方法:
首先说一下存图就是对于每个点u,记录他能到的所有点就行了。。。
邻接矩阵:
直接开一个N×N的二维数组E,然后 E[i][j] 为1的时候表示 i 和 j 之间有一条边,0的时候就没有。
这样很方便简单,但是有几个缺陷,首先是效率问题,超过1000个点一般不管是空间还是时间都不允许了。然后就是如果从 3 到 5 有两条边的话,就没法表示了。。。
所以一般很少用了现在,当然有些算法还是会用到的。
int E[110][110];
E[1][2]=1;
E[5][3]=0;邻接链表:
使用链表的方式保存一个结点的所有边,就是每个点都有一个链表。
当然写个链表很麻烦,所以一般是用vector来替代。就像是下面这样。
vector <int> E[110];
E[3].push_back(6) // 有一条从3到6的边。具体vector怎么用自行学习
前向星:
这个名字实在逼格太高,而且很好用效率也高,所以我一直都用这种方式来存图。
他和链表几乎没什么区别,就是每次添加新的边的时候往开头加,而不是往最后加。
具体就像是下面这样:

struct Edge
{
int to,next;
};
Edge E[1010]; // 总共不超过1000条边。
int head[110],Ecou; // 不超过100个点。
void init() // 初始化。
{
memset(head,-1,sizeof(head));
Ecou=0;
}
void addEdge(int u,int v) // 增加边 u,v。
{
E[Ecou].to=v;
E[Ecou].next=head[u];
head[u]=Ecou++;
}
具体的代码可以慢慢理解,而且刚开始的话用前面两种也可以。
然后说说BFS和DFS怎么写。
首先BFS的话需要一个队列这种数据结构来保存,队列在另一篇有说。
因为每次找到和u相连的之后要一个个找这些点,符合先进先出。
代码如下:(采用第二种存图方式。)
bool vis[110]; // 记录已经走过的点,防止重复访问。
void BFS(int root,int N) // N个点的图,从root点开始搜索。
{
queue <int> que;
memset(vis,0,sizeof(vis)); // 初始化。
vis[root]=1;
que.push(root);
int u,len;
while(!que.empty())
{
u=que.front();
que.pop();
len=E[u].size();
for(int i=0;i<len;++i) // 找到和u相连的所有点,存在一个vector里面。
if(vis[E[u][i]]==0)
{
vis[E[u][i]]=1;
que.push(E[u][i]);
}
}
}
十分建议手算模拟一下这个算法,对于步骤有一个清晰的认识。
然后是DFS:需要一个栈,因为每次都是搜到之后不停的往下搜,符合先进先出。但是一般来说不用栈,而是直接通过函数的递归就行了。
bool vis[110];
int N;
void DFS(int u)
{
int len;
vis[u]=1;
len=E[u].size();
for(int i=0;i<len;++i)
if(vis[E[u][i]]==0)
DFS(E[u][i]);
}
差不多就是这样,也建议好好模拟一下。
至于这两个的用途,其实在一定程度上是可以相互转化的,但是有些需要各自的特性的话就不行了。
DFS主要的特性是深度优先,总是不停的往下找,走到没路才罢休。
BFS则是从root开始扩展,每一层都是精密的搜索完整了才下一个。
分类: (算法录)


+加关注
2
0
« 上一篇:算法录 之 二分和三分
» 下一篇:数据结构录 之 单调队列&单调栈。















 2123
2123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









