









一.dfs是什么
深度优先搜索算法(Depth First Search,简称DFS):一种用于遍历或搜索树或图的算法。 沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过或者在搜寻时结点不满足条件,搜索将回溯到发现节点v的那条边的起始节点。整个进程反复进行直到所有节点都被访问为止。属于盲目搜索,最糟糕的情况算法时间复杂度为O(!n)
二.基本思路
1.无论此时的路线是不是通向这题的解,都要向前探索。
2.遇到错误选择就会往回走,在随机选一个方向探索。
3.这样反复操作,直到遍历完还没找到或找到了解。
三.操作步骤
1.假设一个数组a[5][5],零代表墙,一代表路,初始点是a[1][1],要到达a[n][n]。
假如数组为:

dfs方式如下:

四.代码模板
c++模板:
void dfs(int node, const vector<vector<int>>& adj) {
stack<int> s;
vector<bool> visited(adj.size(), false);
s.push(node);
visited[node] = true;
while (!s.empty()) {
int curr = s.top();
s.pop();
// 处理节点 curr
for (int neighbor : adj[curr]) {
if (!visited[neighbor]) {
s.push(neighbor);
visited[neighbor] = true;
}
}
}
}python模板:
def dfs(node, adj):
stack = [node]
visited = [False] * len(adj)
while stack:
curr = stack.pop()
if not visited[curr]:
visited[curr] = True
# 处理节点 curr
for neighbor in reversed(adj[curr]):
if not visited[neighbor]:
stack.append(neighbor)
# 调用示例
def main():
n = 5 # 图的节点数
adj = [[] for _ in range(n)] # 邻接表表示图
# 构建邻接表
# ...
# 从节点 0 开始 DFS
dfs(0, adj)
if __name__ == "__main__":
main()c模板:
#define MAX_NODES 100
// 定义栈结构
typedef struct {
int nodes[MAX_NODES]; // 栈中存储的节点
int top; // 栈顶指针
} Stack;
// 向栈中压入一个节点
void push(Stack *s, int node) {
s->nodes[s->top++] = node;
}
// 从栈中弹出一个节点
int pop(Stack *s) {
return s->nodes[--(s->top)];
}
// 检查栈是否为空
int isEmpty(Stack *s) {
return s->top == 0;
}
// 迭代 DFS 函数
void dfs_iterative(int start_node, const int adj[][MAX_NODES], int n) {
Stack s;
s.top = 0; // 初始化栈
int visited[MAX_NODES] = {0}; // 初始化访问标记数组
push(&s, start_node); // 将起始节点压入栈
visited[start_node] = 1; // 标记起始节点已访问
while (!isEmpty(&s)) { // 当栈不为空时循环
int curr = pop(&s); // 弹出栈顶节点
printf("Visited %d\n", curr); // 输出访问的节点
// 遍历当前节点的所有邻接节点
for (int i = 0; i < n; i++) {
if (adj[curr][i] && !visited[i]) { // 如果邻接节点未被访问过
push(&s, i); // 将邻接节点压入栈
visited[i] = 1; // 标记邻接节点已访问
}
}
}
} return 0;
}五.经典例题
1.洛谷p1443:
题目描述
有一个 n \times mn×m 的棋盘,在某个点 (x, y)(x,y) 上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。
输入格式
输入只有一行四个整数,分别为 n, m, x, yn,m,x,y。
输出格式
一个 n \times mn×m 的矩阵,代表马到达某个点最少要走几步(左对齐,宽 55 格,不能到达则输出 -1−1)。
输入输出样例
输入 #1
3 3 1 1
输出 #1
0 3 2
3 -1 1
2 1 4
说明/提示
数据规模与约定
对于全部的测试点,保证 1 \leq x \leq n \leq 4001≤x≤n≤400,1 \leq y \leq m \leq
参考AC代码:
// 包含标准库和快捷工具库
#include<bits/stdc++.h>
// 使用标准命名空间
using namespace std;
// 定义两个队列,用于存储x和y坐标
queue<int>q, q1;
// 定义两个二维数组,用于存储迷宫状态和最短路径
int a[401][401], ans[401][401];
// 定义骑士可移动的8个方向的x坐标变化量
int dx[8]={-2,-2,2,2,1,-1,1,-1};
// 定义骑士可移动的8个方向的y坐标变化量
int dy[8]={-1,1,-1,1,2,-2,-2,2};
// 主函数
int main(){
// 初始化答案数组为-1,表示尚未找到路径
memset(ans,-1,sizeof(ans));
// 读取迷宫的宽度n,高度m,以及起始点的x和y坐标
int n, m, x, y;
cin>>n>>m>>x>>y;
// 将起始点加入队列,并标记为已访问
q.push(x);
q1.push(y);
ans[x][y]=0;
a[x][y]=1;
// 当队列不为空时,继续进行广度优先搜索
while(!q.empty()){
// 遍历骑士可移动的8个方向
for(int i=0;i<8;i++){
// 计算移动后的新坐标
int tx=q.front()+dx[i];
int ty=q1.front()+dy[i];
// 如果新坐标在迷宫范围内且未被访问过
if(tx>0&&tx<=n&&ty>0&&ty<=m&&a[tx][ty]==0){
// 标记新坐标为已访问
a[tx][ty]=1;
// 更新新坐标在最短路径中的步数
ans[tx][ty]=ans[q.front()][q1.front()]+1;
// 将新坐标加入队列
q.push(tx);
q1.push(ty);
}
}
// 移除队列头部元素,表示已完成当前层的搜索
q.pop();
q1.pop();
}
// 输出每个点到起始点的最短路径步数
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
printf("%-5d",ans[i][j]);
}
printf("\n");
}
return 0;
}2.洛谷p1219
题目描述
一个如下的 6×6 的跳棋棋盘,有六个棋子被放置在棋盘上,使得每行、每列有且只有一个,每条对角线(包括两条主对角线的所有平行线)上至多有一个棋子。
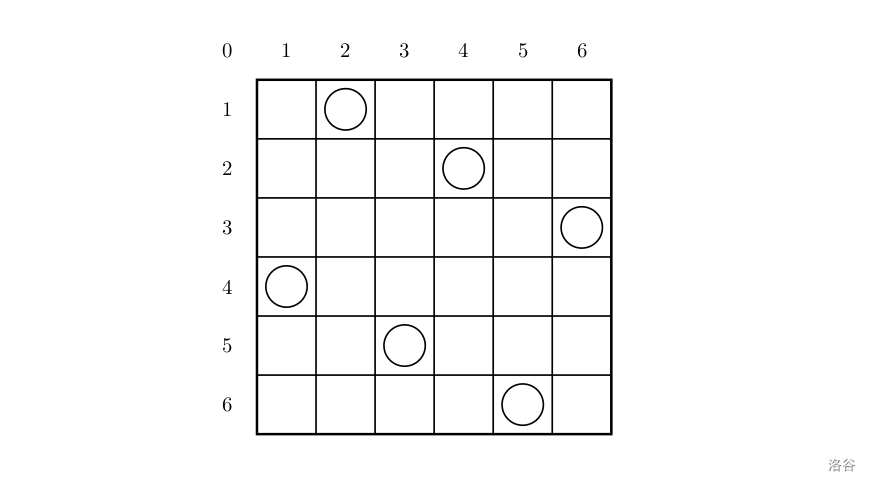
上面的布局可以用序列 2 4 6 1 3 52 4 6 1 3 5 来描述,第 �i 个数字表示在第 �i 行的相应位置有一个棋子,如下:
行号 1 2 3 4 5 61 2 3 4 5 6
列号 2 4 6 1 3 52 4 6 1 3 5
这只是棋子放置的一个解。请编一个程序找出所有棋子放置的解。
并把它们以上面的序列方法输出,解按字典顺序排列。
请输出前 33 个解。最后一行是解的总个数。
输入格式
一行一个正整数 n,表示棋盘是 n×n 大小的。
输出格式
前三行为前三个解,每个解的两个数字之间用一个空格隔开。第四行只有一个数字,表示解的总数。
输入输出样例
输入 #1
6
输出 #1
2 4 6 1 3 5 3 6 2 5 1 4 4 1 5 2 6 3 4
说明/提示
【数据范围】
对于 100%的数据,6≤n≤13。
参考AC代码:
#include <bits/stdc++.h>
using namespace std;
// 定义四个数组,用于记录每一行、列、正对角线、反对角线的放置情况
int a[100], b[100], c[100], d[100];
// 定义变量s,用于记录找到的解的数量
int s;
// 定义变量n,表示N的值,即N皇后问题中的N
int n;
/**
* @brief 输出当前找到的解
*
* 如果找到的解少于或等于2个,就输出当前解的具体放置情况
*/
int ss()
{
if (s <= 2)
{
for (int k = 1; k <= n; k++)
cout << a[k] << " ";
cout << endl;
}
s++;
}
/**
* @brief 深度优先搜索函数
*
* 使用深度优先搜索算法来解决N皇后问题,尝试在棋盘上放置皇后
* @param i 当前正在尝试放置皇后的行号
*/
void dfs(int i)
{
if (i > n)
{
ss();
return;
}
else
{
for (int j = 1; j <= n; j++)
{
if ((!b[j]) && (!c[i + j]) && (!d[i - j + n]))
{
a[i] = j;
b[j] = 1;
c[i + j] = 1;
d[i - j + n] = 1;
dfs(i + 1);
b[j] = 0;
c[i + j] = 0;
d[i - j + n] = 0;
}
}
}
}
int main()
{
cin >> n;
dfs(1);
cout << s;
return 0;
}3.洛谷p5318
题目描述
小 K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小 K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考文献的话就不用再看它了)。
假设洛谷博客里面一共有n(n≤105) 篇文章(编号为 1 到 n)以及 m(m≤106) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 X → Y 表示文章 X 有参考文献 Y。不保证编号为 1 的文章没有被其他文章引用。
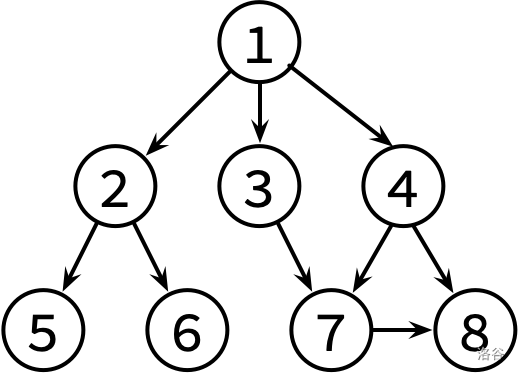
请对这个图分别进行 DFS 和 BFS,并输出遍历结果。如果有很多篇文章可以参阅,请先看编号较小的那篇(因此你可能需要先排序)。
输入格式
共 m+1 行,第 1 行为 2 个数,n 和 m,分别表示一共有 n(n≤105) 篇文章(编号为 1 到 n)以及m(m≤106) 条参考文献引用关系。
接下来 m 行,每行有两个整数 X,Y 表示文章 X 有参考文献 Y。
输出格式
共 2 行。 第一行为 DFS 遍历结果,第二行为 BFS 遍历结果。
输入输出样例
输入 #1复制
8 9 1 2 1 3 1 4 2 5 2 6 3 7 4 7 4 8 7 8
参考AC代码:
#include <bits/stdc++.h>
using namespace std;
// 定义最大节点数量常量
const int MAXN = 100010;
// 使用邻接表存储图的边信息
vector<int> p[MAXN];
int n, m;
// 访问标记数组,用于标记节点是否被访问过
bool vis[MAXN];
// 使用队列实现广度优先搜索
queue<int> q;
/**
* 深度优先搜索函数
* @param x 当前访问的节点
*/
void dfs(int x) {
cout << x << " "; // 输出当前节点
for (int i = 0; i < p[x].size(); i++) // 遍历当前节点的所有邻接节点
if (!vis[p[x][i]]) { // 如果邻接节点未被访问过
vis[p[x][i]] = true; // 标记为已访问
dfs(p[x][i]); // 递归访问邻接节点
}
}
/**
* 广度优先搜索函数
*/
void bfs() {
memset(vis, 0, sizeof(vis)); // 初始化访问标记数组
vis[1] = true; // 从节点1开始,标记为已访问
q.push(1); // 将节点1入队
while (!q.empty()) { // 当队列不为空时循环
int x = q.front(); // 取出队列头部的节点
q.pop(); // 出队
cout << x << " "; // 输出当前节点
for (int i = 0; i < p[x].size(); i++) // 遍历当前节点的所有邻接节点
if (!vis[p[x][i]]) { // 如果邻接节点未被访问过
vis[p[x][i]] = true; // 标记为已访问
q.push(p[x][i]); // 入队邻接节点
}
}
}
int main() {
cin >> n >> m; // 输入节点数量和边数量
for (int i = 1; i <= m; i++) { // 遍历所有边
int u, v;
cin >> u >> v; // 输入边的起点和终点
p[u].push_back(v); // 将终点添加到起点的邻接表中
}
for (int i = 1; i <= n; i++) // 遍历所有节点
sort(p[i].begin(), p[i].end()); // 对邻接表排序,确保搜索顺序一致
vis[1] = true; // 从节点1开始,标记为已访问
dfs(1); // 调用深度优先搜索函数
cout << endl;
bfs(); // 调用广度优先搜索函数
cout << endl;
return 0;
}
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









