










https://www.cnblogs.com/mellowsmile/p/4642306.html
HH
终风且暴,顾我则笑,谑浪笑敖,中心是悼。 终风且霾,惠然肯来,莫往莫来,悠悠我思。
随笔 - 48 文章 - 0 评论 - 12
Oracle行转列、列转行的Sql语句总结
多行转字符串
这个比较简单,用||或concat函数可以实现
SQL Code
| 1 |
| select concat(id,username) str from app_user |
字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式
字符串转多行
使用union all函数等方式
wm_concat函数
首先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行,接下来上例子,看看这个神奇的函数如何应用准备测试数据
SQL Code
| 1 |
| create table test(id number,name varchar2(20)); |
效果1 : 行转列 ,默认逗号隔开
SQL Code
| 1 |
| select wm_concat(name) name from test; |
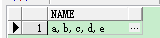
效果2: 把结果里的逗号替换成"|"
SQL Code
| 1 |
| select replace(wm_concat(name),',','|') from test; |
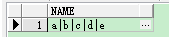
效果3: 按ID分组合并name
SQL Code
| 1 |
| select id,wm_concat(name) name from test group by id; |
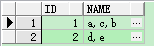
sql语句等同于下面的sql语句:
SQL Code
| 1 |
| -------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE ) |
懒人扩展用法:
案例: 我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 当然有了,看我如果应用wm_concat来让这个需求变简单,假设我的APP_USER表中有(id,username,password,age)4个字段。查询结果如下
SQL Code
| 1 |
| /** 这里的表名默认区分大小写 */ |

利用系统表方式查询
SQL Code
| 1 |
| select * from user_tab_columns |
Oracle 11g 行列互换 pivot 和 unpivot 说明
在Oracle 11g中,Oracle 又增加了2个查询:pivot(行转列) 和unpivot(列转行)
参考:http://blog.csdn.net/tianlesoftware/article/details/7060306、http://www.oracle.com/technetwork/cn/articles/11g-pivot-101924-zhs.html
google 一下,网上有一篇比较详细的文档:http://www.oracle-developer.net/display.php?id=506
pivot 列转行
测试数据 (id,类型名称,销售数量),案例:根据水果的类型查询出一条数据显示出每种类型的销售数量。
SQL Code
| 1 |
| create table demo(id int,name varchar(20),nums int); ---- 创建表 |
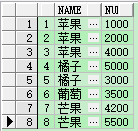
分组查询 (当然这是不符合查询一条数据的要求的)
SQL Code
| 1 |
| select name, sum(nums) nums from demo group by name |
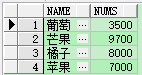
行转列查询
SQL Code
| 1 |
| select * from (select name, nums from demo) pivot (sum(nums) for name in ('苹果' 苹果, '橘子', '葡萄', '芒果')); |

注意: pivot(聚合函数 for 列名 in(类型)) ,其中 in('') 中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers
当然也可以不使用pivot函数,等同于下列语句,只是代码比较长,容易理解
SQL Code
| 1 |
| select * |
unpivot 行转列
顾名思义就是将多列转换成1列中去
案例:现在有一个水果表,记录了4个季度的销售数量,现在要将每种水果的每个季度的销售情况用多行数据展示。
创建表和数据
SQL Code
| 1 |
| create table Fruit(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int); |
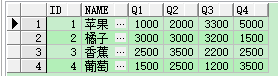
列转行查询
SQL Code
| 1 |
| select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) ) |
注意: unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量
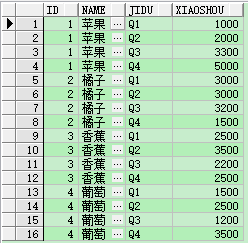
同样不使用unpivot也可以实现同样的效果,只是sql语句会很长,而且执行速度效率也没有前者高
SQL Code
| 1 |
| select id, name ,'Q1' jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit f |
XML类型
上述pivot列转行示例中,你已经知道了需要查询的类型有哪些,用in()的方式包含,假设如果您不知道都有哪些值,您怎么构建查询呢?
pivot 操作中的另一个子句 XML 可用于解决此问题。该子句允许您以 XML 格式创建执行了 pivot 操作的输出,在此输出中,您可以指定一个特殊的子句 ANY 而非文字值
示例如下:
SQL Code
| 1 |
| select * from ( |

如您所见,列 NAME_XML 是 XMLTYPE,其中根元素是 <PivotSet>。每个值以名称-值元素对的形式表示。您可以使用任何 XML 分析器中的输出生成更有用的输出。

对于该xml文件的解析,贴代码如下:
SQL Code
| 1 | create or replace procedure ljz_pivot_xml_sp(pi_table_name varchar2, |
第一个参数为要解析xml文件所属数据表,第二个参数为要解析xml所存字段,第三个参数存放解析后的数据集。
测试:
begin
ljz_pivot_xml_sp('(select * from (select deptno,sal from emp) pivot xml(sum(sal) for deptno in(any)))',
'deptno_xml',
'ljz_pivot_tmp');
end;
初学oracle xml解析,这种方法较为笨拙,一个一个循环列,原型如下:
select extractvalue(name_xml, '/PivotSet/item[1]/column[1]')
from (select * from (select name,nums from demo) pivot xml(sum(nums) for name in(any))) x
where existsnode(name_xml, '/PivotSet/item[1]/column[1]') = 1;
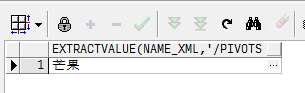
select x.*
from (select *
from (select name, nums from demo)
pivot xml(sum(nums)
for name in(any))) a,
xmltable('/PivotSet' passing a.name_xml columns
芒果 varchar2(30) path 'item[1]/column[2]',
苹果 varchar2(30) path 'item[2]/column[2]') x
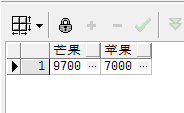
不知是否存在直接进行解析的方法,这种方法还不如直接行列转变,不通过xml转来转去。
select '''' || listagg(substr(name, 1, 30), q'{','}') within group(order by name) || ''''
from (select distinct name from demo);

select *
from (select name, nums from demo)
pivot(sum(nums)
for name in('苹果', '橘子', '葡萄', '芒果'));

这样拼接字符串反而更加方便。
结论
Pivot 为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用 unpivot 操作转换任何交叉表报表,以常规关系表的形式对其进行存储。Pivot 可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域。
分类: Oracle 相关

+加关注
3
1
« 上一篇:Oracle发送邮件,支持HTML,多收件人,多附件
» 下一篇:Oracle用法、函数备忘记录
posted @ 2015-07-13 10:54 mellowsmile 阅读(134290) 评论(7) 编辑 收藏
https://www.cnblogs.com/mellowsmile/p/4642306.html
https://blog.csdn.net/wyqwilliam/article/details/82559023
原
SQL行转列、列转行
2018年09月09日 15:51:14 道法—自然 阅读数:182
SQL行转列、列转行
这个主题还是比较常见的,行转列主要适用于对数据作聚合统计,如统计某类目的商品在某个时间区间的销售情况。列转行问题同样也很常见。
一、整理测试数据
-
create table wyc_test( -
id int(32) not null auto_increment, -
name varchar(80) default null, -
date date default null, -
scount int(32), -
primary key (id) -
); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (1,'小说','2013-09-01',10000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (2,'微信','2013-09-01',20000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (3,'小说','2013-09-02',30000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (4,'微信','2013-09-02',35000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (5,'小说','2013-09-03',31000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (6,'微信','2013-09-03',36000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (7,'小说','2013-09-04',35000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (8,'微信','2013-09-04',38000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (9,'小说','2013-09-01',80000); -
INSERT INTO `wyc_test` (`id`,`name`,`date`,`scount`) VALUES (10,'微信','2013-09-01',70000);
二、行转列
主要思路是分组后使用case进行条件判断处理
-
#行转列 -
select -
a.date, -
sum(case a.name -
when '小说' then a.scount -
else 0 -
end) 'sum_小说', -
max(case a.name -
when '小说' then a.scount -
else 0 -
end) 'max_小说', -
sum(case a.name -
when '微信' then a.scount -
else 0 -
end) '微信', -
max(case a.name -
when '小说' then a.scount -
else 0 -
end) 'max_微信' -
from -
wyc_test a -
group by date;
结果:

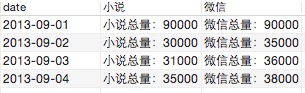
三、列转行
主要思路也是分组后使用case
-
#列转行 -
select -
a.date, -
concat('小说:', -
cast(sum(case a.name -
when '小说' then a.scount -
else 0 -
end) -
as char), -
'微信', -
cast(sum(case a.name -
when '微信' then a.scount -
else 0 -
end) -
as char)) as 'str' -
from -
wyc_test a -
group by a.date; -
#列转行 -
#1.使用mysql提供的函数分组 -
select a.date,group_concat(a.name,'总量:', a.scount) from wyc_test a group by a.date,a.name; -
#2.使用mysql提供的函数分组 -
select a.date,a.name, group_concat(a.name, '总量:', a.scount) from wyc_test a group by a.date,a.name; -
#3.普通group结合字符串拼接 -
SELECT -
a.date, -
concat('小说总量:', -
cast(sum(case a.name -
when '小说' then a.scount -
else 0 -
end) -
as char)) as '小说', -
concat('微信总量:', -
cast(sum(case a.name -
when '微信' then a.scount -
else 0 -
end) -
as char)) as '微信' -
from -
wyc_test a -
group by a.date;
结果:
四、列转行详解
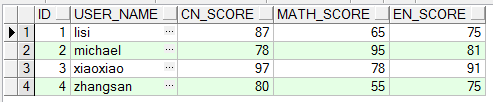
1.1、初始测试数据
表结构:TEST_TB_GRADE2
Sql代码
create table TEST_TB_GRADE2
(
ID NUMBER(10) not null,
USER_NAME VARCHAR2(20 CHAR),
CN_SCORE FLOAT,
MATH_SCORE FLOAT,
EN_SCORE FLOAT
)
初始数据如下图:
1.2、 如果需要实现如下的查询效果图:
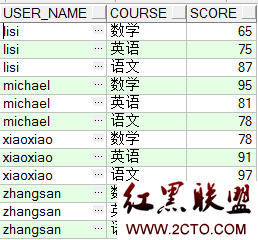
这就是最常见的列转行,主要原理是利用SQL里面的union,具体的sql语句如下:
Sql代码
select user_name, '语文' COURSE , CN_SCORE as SCORE from test_tb_grade2
union select user_name, '数学' COURSE, MATH_SCORE as SCORE from test_tb_grade2
union select user_name, '英语' COURSE, EN_SCORE as SCORE from test_tb_grade2
order by user_name,COURSE
也可以利用【 insert all into ... select 】来实现,首先需要先建一个表TEST_TB_GRADE3:
Sql代码
create table TEST_TB_GRADE3
(
USER_NAME VARCHAR2(20 CHAR),
COURSE VARCHAR2(20 CHAR),
SCORE FLOAT
)
再执行下面的sql:
Sql代码
insert all
into test_tb_grade3(USER_NAME,COURSE,SCORE) values(user_name, '语文', CN_SCORE)
into test_tb_grade3(USER_NAME,COURSE,SCORE) values(user_name, '数学', MATH_SCORE)
into test_tb_grade3(USER_NAME,COURSE,SCORE) values(user_name, '英语', EN_SCORE)
select user_name, CN_SCORE, MATH_SCORE, EN_SCORE from test_tb_grade2;
commit;
别忘记commit操作,然后再查询TEST_TB_GRADE3,发现表中的数据就是列转成行了。
收藏
分享
https://blog.csdn.net/wyqwilliam/article/details/82559023
https://www.cnblogs.com/wayne-ivan/p/6416489.html

wm_concat函数的排序问题
wm_concat在行转列的时候非常有用,但在行转列的过程中的排序问题常常难以控制。
可见下面例子:
准备测试表:
drop table t;
create table t (n number,m number);
insert into t values(1,1);
insert into t values(5,3);
insert into t values(3,3);
insert into t values(6,5);
insert into t values(7,2);
insert into t values(2,2);
insert into t values(0,1);
insert into t values(11,1);
insert into t values(15,3);
insert into t values(13,3);
insert into t values(16,5);
insert into t values(17,2);
insert into t values(12,2);
insert into t values(10,1);
commit;
SQL> select * from t order by 2,1;
N M
———- ———-
0 1
1 1
10 1
11 1
2 2
7 2
12 2
17 2
3 3
5 3
13 3
15 3
6 5
16 5
测试wm_concat后的顺序:
测试1:
SQL> select m,wm_concat(n) from t group by m;
M WM_CONCAT(N)
———- ——————————————————————————–
1 11,0,1,10
2 17,2,7,12
3 15,3,5,13
5 16,6
可见wm_concat后的顺序并没有按大->小,或小->大的顺序。
测试2:
–参考网上一些解决思路
SQL> select m,wm_concat(n)
2 from (select n,m from t order by m,n )
3 group by m;
M WM_CONCAT(N)
———- ——————————————————————————–
1 0,11,10,1
2 2,17,12,7
3 3,15,13,5
5 6,16
可见顺序问题还是没有解决
最终解决思路:
SQL> select m, max(r)
2 from (select m, wm_concat(n) over (partition by m order by n) r from t)
3 group by m ;
M MAX(R)
———- ——————————————————————————–
1 0,1,10,11
2 2,7,12,17
3 3,5,13,15
5 6,16
分类: Oracle
好文要顶 关注我 收藏该文 ![]()


+加关注
0
0
« 上一篇:Oracle树查询及相关函数
» 下一篇:Oracle系统表整理+常用SQL语句收集
posted @ 2017-02-19 18:23 伊凡 阅读(8665) 评论(0) 编辑 收藏
https://www.cnblogs.com/wayne-ivan/p/6416489.html
https://blog.csdn.net/seandba/article/details/72730657
原
Oracle SQL函数pivot、unpivot转置函数实现行转列、列转行
2017年05月25日 16:18:27 Seandba 阅读数:26664
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Seandba/article/details/72730657
函数PIVOT、UNPIVOT转置函数实现行转列、列转行,效果如下图所示:
1.PIVOT为行转列,从图示的左边到右边
2.UNPIVOT为列转行,从图示的右边到左边
3.左边为纵表,结构简单,易扩展
4.右边为横表,展示清晰,方便查询
5.很多时候业务表为纵表,但是统计分析需要的结果如右边的横表,这时候就需要用到转置函数了
示例图表:
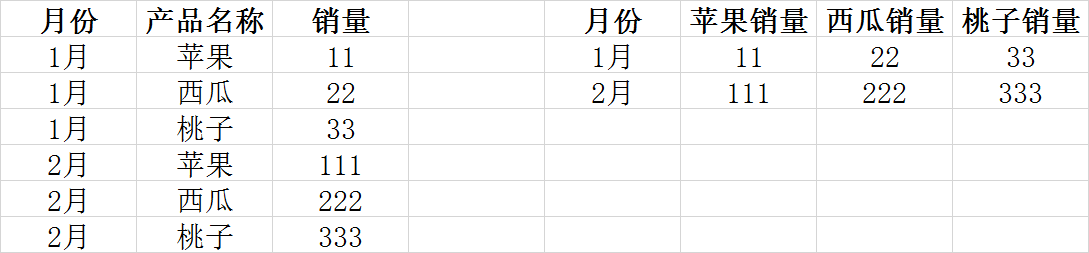
Pivot语法:
-
SELECT .... -
FROM <table-expr> -
PIVOT -
( -
aggregate-function(<column>) -
FOR <pivot-column> IN (<value1>, <value2>,..., <valuen>) -
) AS <alias> -
WHERE .....
注意:
FOR <pivot-column>这个是不支持表达式的,如果需要,请通过子查询或者视图先预处理。
Pivot
例子1:先构造一个子查询,然后根据CHANNEL列进行转置,源表sales_view里面可能有很多列,不需要列先通过子查询过滤掉再进行转置。
另外转置后的列指定了别名,值是对amount_sold列的汇总。
-
SELECT * FROM -
(SELECT product, channel, amount_sold -
FROM sales_view -
) S PIVOT (SUM(amount_sold) -
FOR CHANNEL IN (3 AS DIRECT_SALES, 4 AS INTERNET_SALES, -
5 AS CATALOG_SALES, 9 AS TELESALES)) -
ORDER BY product; -
PRODUCT DIRECT_SALES INTERNET_SALES CATALOG_SALES TELESALES -
---------------------- ------------ -------------- ------------- --------- -
... -
Internal 6X CD-ROM 229512.97 26249.55 -
Internal 8X CD-ROM 286291.49 42809.44 -
Keyboard Wrist Rest 200959.84 38695.36 1522.73 -
...
例子2:基于多列进行转置,下面例子是基于channel、quarter两列进行转置
-
SELECT * -
FROM -
(SELECT product, channel, quarter, quantity_sold -
FROM sales_view -
) PIVOT (SUM(quantity_sold) -
FOR (channel, quarter) IN -
((5, '02') AS CATALOG_Q2, -
(4, '01') AS INTERNET_Q1, -
(4, '04') AS INTERNET_Q4, -
(2, '02') AS PARTNERS_Q2, -
(9, '03') AS TELE_Q3 -
) -
); -
PRODUCT CATALOG_Q2 INTERNET_Q1 INTERNET_Q4 PARTNERS_Q2 TELE_Q3 -
------- ---------- ----------- ----------- ----------- ------- -
... -
Bounce 347 632 954 -
... -
Smash Up Boxing 129 280 560 -
... -
Comic Book Heroes 47 155 275 -
...
例子3:对多列的值进行汇总计算,以下是基于channel例进行转置,然后对amount_sold和quantity_sold两列进行合计运算
-
SELECT * -
FROM -
(SELECT product, channel, amount_sold, quantity_sold -
FROM sales_view -
) PIVOT (SUM(amount_sold) AS sums, -
SUM(quantity_sold) AS sumq -
FOR channel IN (5, 4, 2, 9) -
) -
ORDER BY product; -
PRODUCT 5_SUMS 5_SUMQ 4_SUMS 4_SUMQ 2_SUMS 2_SUMQ 9_SUMS 9_SUMQ -
------------- ------ ------ ------ ------ ------ ------ ------ ------ -
O/S Doc Set English 142780.36 3081 381397.99 8044 6028.66 134 -
O/S Doc Set French 55503.58 1192 132000.77 2782 -
...
Unpivot
unpivot是pivot的相反操作,进行的是列转行
例子1:先看源表结构,for子句指定将(Q1_SUMQ, Q2_SUMQ, Q3_SUMQ, Q4_SUMQ)这4列转置为行,
for子句之前的quantity_sold是4列转置后的列名,
decode还定义了每列转置为行后新标示列的值,这个等下看第2个例子可以看到,也可以在 in 子句后面加 as 指定别名。
UNPIVOT INCLUDE NULLS 指定空值也进行转置,如果是EXCLUDE NULLS 将忽略空值。
-
SELECT * -
FROM pivotedTable -
ORDER BY product; -
PRODUCT Q1_SUMQ Q1_SUMA Q2_SUMQ Q2_SUMA Q3_SUMQ Q3_SUMA Q4_SUMQ Q4_SUMA -
--------------- ------- ------- ------- -------- ------- -------- ------- --------- -
1.44MB External 6098 58301.33 5112 49001.56 6050 56974.3 5848 55341.28 -
128MB Memory 1963 110763.63 2361 132123.12 3069 170710.4 2832 157736.6 -
17" LCD 1492 1812786.94 1387 1672389.06 1591 1859987.66 1540 1844008.11
-
SELECT product, DECODE(quarter, 'Q1_SUMQ', 'Q1', 'Q2_SUMQ', 'Q2', 'Q3_SUMQ', 'Q3', -
'Q4_SUMQ', 'Q4') AS quarter, quantity_sold -
FROM pivotedTable -
UNPIVOT INCLUDE NULLS -
(quantity_sold -
FOR quarter IN (Q1_SUMQ, Q2_SUMQ, Q3_SUMQ, Q4_SUMQ)) -
ORDER BY product, quarter; -
PRODUCT QUARTER QUANTITY_SOLD -
------- -- ------------- -
1.44MB External 3.5" Diskette Q1 6098 -
1.44MB External 3.5" Diskette Q2 5112 -
1.44MB External 3.5" Diskette Q3 6050 -
1.44MB External 3.5" Diskette Q4 5848 -
128MB Memory Card Q1 1963 -
128MB Memory Card Q2 2361 -
128MB Memory Card Q3 3069 -
128MB Memory Card Q4 2832 -
...
例子2:转置多列的情况
-
SELECT product, quarter, quantity_sold, amount_sold -
FROM pivotedTable -
UNPIVOT INCLUDE NULLS -
( -
(quantity_sold, amount_sold) -
FOR quarter IN ((Q1_SUMQ, Q1_SUMA) AS 'Q1', (Q2_SUMQ, Q2_SUMA) AS 'Q2', (Q3_SUMQ, Q3_SUMA) AS 'Q3', (Q4_SUMQ, Q4_SUMA) AS 'Q4')) -
ORDER BY product, quarter; -
PRODUCT QU QUANTITY_SOLD AMOUNT_SOLD -
----------------------------- -- ------------- ------------ -
1.44MB External 3.5" Diskette Q1 6098 58301.33 -
1.44MB External 3.5" Diskette Q2 5112 49001.56 -
1.44MB External 3.5" Diskette Q3 6050 56974.3 -
1.44MB External 3.5" Diskette Q4 5848 55341.28 -
128MB Memory Card Q1 1963 110763.63 -
128MB Memory Card Q2 2361 132123.12 -
128MB Memory Card Q3 3069 170710.4 -
128MB Memory Card Q4 2832 157736.6
总结,基本上按照语法套用即可,注意将源表非相关列先过滤掉,可是是子查询,也可以是视图。
最后试试解决这个问题吧,看你是否真的懂了!
http://blog.csdn.net/seandba/article/details/72629724
以上内容均来自Oracle11g官方文档,我只是搬运工。。。
Oracle® Database Data Warehousing Guide
11g Release 2 (11.2)
E25554-01
阅读更多 收藏
分享
https://blog.csdn.net/seandba/article/details/72730657
https://segmentfault.com/q/1010000009622091?sort=created
Oracle pivot in子查询的疑问
在使用pivot函数进行行转列的时候 in后面接子查询就报错

按照oracle的文档,pivot语句中in后面的列如果不固定,只能使用xml格式的返回结果,如:
http://www.oracle-developer.n...
SQL> SELECT *
2 FROM pivot_data
3 PIVOT XML
4 (SUM(sal) FOR deptno IN (ANY));
JOB DEPTNO_XML
--------- ---------------------------------------------------------------------------
ANALYST <PivotSet><item><column name = "DEPTNO">20</column><column name = "SUM(SAL)
">6600</column></item></PivotSet>
CLERK <PivotSet><item><column name = "DEPTNO">10</column><column name = "SUM(SAL)
">1430</column></item><item><column name = "DEPTNO">20</column><column name
= "SUM(SAL)">2090</column></item><item><column name = "DEPTNO">30</column>
<column name = "SUM(SAL)">1045</column></item></PivotSet>
MANAGER <PivotSet><item><column name = "DEPTNO">10</column><column name = "SUM(SAL)
">2695</column></item><item><column name = "DEPTNO">20</column><column name
= "SUM(SAL)">3272.5</column></item><item><column name = "DEPTNO">30</colum
n><column name = "SUM(SAL)">3135</column></item></PivotSet>如果不想要xml格式的结果,就只能使用把in之间的内容提前计算出来,动态拼接成sql语句,使用execute immediately动态执行。
- 评论 · 2
- 赞赏
- 编辑

邢爱明  4.8k
4.8k
https://segmentfault.com/q/1010000009622091?sort=created
oracle中pivot子查询如何用 50
在oracle中使用pivot函数,看介绍说在in()中可以使用子查询,但是使用子查询执行时报错缺少表达式,请问子查询应该如何使用,是不是pivot不支持子查询,谢谢
 我来答
我来答
分享
举报浏览 6787 次
- 你的回答被采纳后将获得:
- 系统奖励15(财富值+成长值)+难题奖励20(财富值+成长值)+提问者悬赏50(财富值+成长值)
1个回答
 chengccy2010
chengccy2010
来自电脑网络类芝麻团 2015-05-22
xml 类型的时候可以使用any 关键字和子查询,返回的结果是xml结构的;
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (select state_code from preferred_states)
)
order by 1
本回答被网友采纳
7 67
评论
分享
举报














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









