







一:日志简介
日志用于记录系统中硬件、软件、系统、进程和应用运行时的信息,同时可以监控系统中发生的各种事件。我们可以通过它来检查错误发生的原因,解决用户投诉的问题,找到攻击者留下的攻击痕迹。日志既可以用来生成监控图,也可以用来发出警报。
按照产生的来源,日志可以分为系统日志、容器日志和应用日志等;
按照应用目标的不同,日志可以分为性能日志、安全日志等;
按照级别的不同,日志可以分为调试日志、信息日志、警告日志和错误 日志等 。
我们在业务系统开发中,一般使用的日志框架有 Commons logging 、 Log4j 、 Slf4j 、 Logback 、 Log4j 2 等,业务日志一般分为trace 、 debug 、 warn、 info 和 error 级别等,线上系统根据其特点进行的相应设置也不同,有的设置为 debug 级别,有的设置为 info 、error 级别在刚上线且不稳定的项目中通常设置为 debug 级别,便于查找问题;在线上系统稳定后使用 error级别即可,这样能够有效地提高效率。
二:JDK Logger介绍及使用
JDK 从 1 .4 版本起,开始自带一套日志系统 JDK Logger ,它的最大优点就是不需要集成任何类库 ,只要有 JVM 的运行环境,就可以直接使用,使用起来比较方便。
JDK Logger 将日志分为 9 个级别 : all 、 finest 、 finer 、 fine 、 config 、 info 、 warning 、 severe 、off,级别依次升高 ,这里我们看到其命名和主流的开源日志框架命名有些不同,例如 : 主流框
架的错误日志使用 error命名,而这里使用 severe 命名,实际上,这些命名让人感觉很奇怪 。
JDK Logger 的使用示例如下 :

如果将日志级别设置为 all,则所有信息都会被输出:如果设置为 off,则所有信息都不会被输出。
如果将级别设置为 info ,则info前面的更低级别的信息将不会被输出,只有info和高于info级别的日志才会被输出。通过这种方法控制日志的输出级别,以达到控制日志输出量的目的。
JDK Logger 默认在控制台输出,并且输出 info 级别和高于 info 级别的信息,我们也可以通过调用 Logger 的 setLevel()方法或者通过配置文件来设置,当然,我们也可以设置多个输出,对每个输出设置不同的级别,然后把输出的日志添加到同一个或者多个日志文件中来集中管理 。
然而,相比其他开源日志框架, JDK 自带的 Logger 日志框架可谓鸡肋,在易用性、功能及扩展性方面都要稍逊一筹,所以很少在线上系统中被使用。 所以这里我们不做过多的细节介绍了。
三:日志门面框架:Apache Commons Logging
在 Java 领域里有许多实现日志功能的框架,最早得到广泛使用的是 Log4j ,许多应用程序的日志记录功能都由 Log4j 来实现。不过,作为应用开发者,我们希望自己的组件不依赖于某个日志工具,毕竟还有很多其他日志工具可用 ,如果存在性能或者其他问题,需要在日志实现框架中进行切换,则使用 Log4j 就直接把程序日志绑定到 Log4j 的实现上了,但切换时会带来大量的修改工作 。 为了解决这个问题 , Apache Commons Logging (简称 Commons Logging,又名 JCL,即 Jakata Commons Loggings ) 只提供了日志接口 ,具体的实现则在运行时根据配置动态查找日志的实现框架 ,它的出现避免了和具体的日志实现框架直接耦合。 在日常开发中 ,开发者可以选择第三方日志组件搭配使用 ,例如 Log4j。
有了 Commons Logging 后 , 开发人员就可以针对 Commons Logging 的 API 进行编程了,而运行时可以根据配置切换不同的日志实现框架,使应用程序打印日志的功能与日志实现解耦。换句话来说, JCL 提供了操作日志的接口 ,而具体的日志实现交给 Log4j 这样的开源日志框架来完成。这样可实现程序的解耦,对于底层日志框架的改变 ,并不会影响上层的业务代码 。
传统的系统基本上使用 Commons Logging 和 Apache Log4j 的组合 , Commons Logging 使用门面设计模式实现,门面后面可以转接 Apache Log4j 等其他日志实现框架 。 后来,Log4j 的作者 Ceki 看到这套实现在一些细节上存在缺陷 ,于是又开发了 Slf4j 和 Logback,但是它们并不属于 Apache 组织 。 Slf4j 用来取代 Commons Logging, Logback 则用来取代 Log4j 。
1. 实现结构
首先 , 我们来分析 Commons Logging 的实现结构,如图
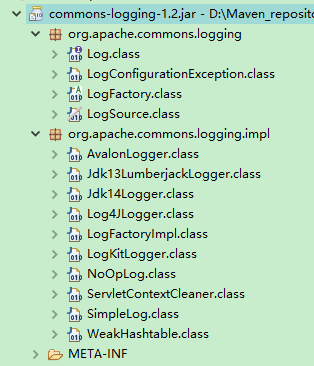
Commons Logging 一共有两个包: org.apache.commons.logging 和 org.apache.commons. logging.impl,前者包含日志 API ,后者包含日志 API 的实现。
实现类的具体职责如下 。
- Log:日志对象接口,封装了操作日志的方法,定义了日志操作的 5 个级别,在级别上trace < debug < info < warn < error。
- LogFactory : 是一个抽象类 , 是用来获取日志对象的工厂类。
- Logfactorylmpl: LogFactory 的实现类,是真正获取日志对象的地方 。
- Log4JLogger:对 Log4j 的日志对象的封装 。
- Jdk14Logger:对 JDKI .4 Logger 的日 志对象的封装。
- SimpleLog:自带的简单的日志记录器。
2. 使用方式
Commons Logging 的使用非常简单。
首先 ,需要在应用的maven 配置文件pom.xml 中添加如下依赖:
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
测试代码:

接下来,在 classpath 下定义配置文件 commons-logging.properties:
#指定日志对象
org.apache.commons.logging.Log=org.apache.commons.logging.impl.Jdk14Logger
#指定日志工厂
org.apache.commons.logging.LogFactory=org.apache.commons.logging.impl.LogFactoryImpl
在项目中如果单纯地依赖 Commons Logging,则默认使用的日志对象是 org.apache.commons.logging.impl.Jdk14Logger, 默认使用的日志工厂是 org.apache.commons.logging.impl.LogFactorylmpl 。
3. 类加载方式
Commons Logging 使用下面的顺序加载底层的日志框架 。
- 寻找 JVM内的 org.apache.cornrnons.logging.LogFactory属性配置,如果找到,则使用配置的日志工厂。
- 使用 JDK 从 1.3 版本开始提供的服务发现机制,扫描类路径下的 META-INF/services/org.apache.commons.logging.LogFactory文件,如果找到,则装载其中的配置,并使用其中的配置来加载日志工厂
- 从类路径中查找配置文件 commons-logging. properties ,如果找到,则根据其中的配置加载具体的日志实现框架。
- 如果前面的配置文件不存在,则使用默认的配置,通过反射 API 判断 Log4j 是否存在于类路径中 :如果不存在,则判断 JDK14Logger 是否存在于类路径中;如果都不存在,则使用内部简单的 SimpleLog 来实现 。
在这个过程中,我们可以看到 Apache Commons Logging 通过配置来动态地找到具体的实现类,如果具体的实现类不在类路径中或者被限制使用,则无法加载,例如在 OSGI 环境下类被分组后,就有可能出现加载不到底层实现类的情况。后续介绍的 Slf4j 框架对类加载的方式进行了改进,解决了在 OSGI 等环境下无法找到底层日志框架类的问题。
四:Apache Log4j介绍及使用
Apache Log4j (简称 Log4j )是一款由 Java 编写的可靠、灵活的日志框架,是 Apache 旗下的一个开源项目,如今, Log4j 己经被移植到了多种语言中 ,服务于更多的开发者 。
通过使用 Log4j ,我们能够更加方便地记录日志信息,它不但能控制日志输出的目的地,还能控制日志输出的内容格式等,通过定义不同的日志级别,可以更加精确地控制日志的生成过程, 从而达到应用对日志记录的需求。这一切都得益于一个简单、灵活的日志配置文件,而不需要我们更改应用层代码 。
1. 实现结构
下面分析 Log4j 的实现结构,如图:
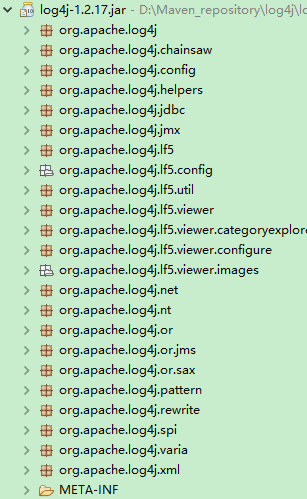
其中, org.apache.log4j 包含 Log4j 主要的实现类: Logger 、 Layout 、 Appender 和 LogManager, 它们的职责如下 。
(1)Logger: 日志对象,负责捕捉日志记录的信息 。
Logger 对象是用来取代 JDK 自带的 System.out 或者 System.error 的日志输出器,负责日志信息的输出:它提供了 trace 、 debug、 info 、 warn 和 error 等 API 供开发者使用。与 Commons Logging 一样, Log4j 也有日志级别的概念。对每个 Logger 对象都会分配一个级别,未被分配级别的 Logger 对象则继承根 Logger 对象的级别,进行日志的输出。日志对象的相应方法为: trace 、 debug 、 info 、 warn 和 error,每个方法对应日志的一个级别,也可以设置一个日志的级别,如果方法对应的级别等于或大于当前 Logger 对象设置的级别,则该调用请求会被处理并记录到输出中,否则该请求被忽略。
Log4j 在 Level 类中定义了 7 个级别,级别关系如下:
Level.all < Level.debug < Level.info < Level.warn < Level.error < Level. fatal< Level.off
每个级别的含义如下:
all:打开所有日志。
debug:适用于代码调试期间打印调试信息 。
info:适用于代码运行期间打印逻辑信息 。
warn:适用于代码有潜在错误事件时打印相关信息 。
error:适用于代码产生错误事件时打印错误信息和环境 。
fatal:适用于代码存在严重错误事件时打印错误信息 。
off:关闭所有日志。
(2)Appender:日志输出目的地,负责把格式化的日志信息输出到指定的地方,可以是控制台、磁盘文件等 。
每个日志对象都有一个对应的 Appender 对象,每个 Appender 对象代表一个日志输出目的地。其中, Log4j 有以下 Appender 对象可供选择。
- ConsoleAppender:把日志输出到控制台 。
- FileAppender:把日志输出到磁盘文件 。
- DailyRollingFileAppender:每天产生一个日志磁盘文件,日志文件按天滚动生成。
- RollingFileAppender:日志磁盘文件的大小达到指定尺寸时会产生一个新的文件,日志文件按照日志大小滚动生成 。
(3)Layout:对日志进行格式化,负责生成不同格式的日志信息。
每个 Appender 对象对应一个 Layout 对象, Appender 对象负责把日志信息输出到指定的文件中, Layout 对象则负责把日志信息按照格式化的要求展示出来 。其中 , Log4j 有以下 Layout
可供选择。
- HTMLLayout:以 HTML 表格形式布局展示。
- PatternLayout:自定义指定的格式展示。
- SimpleLayout:只包含日志信息的级别和信息字符串。
- TTCCLayout:包含日志产生的时间、线程、类别等信息。
2. 使用方式
首先,我们需要在应用的 maven 配置文件pom.xml中添加依赖:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
然后,编写测试代码:

最后,在类路径下声明配置文件 log4j.properties 或者 log4j.xml 。
声明 log4j .properties:

从上面的配置中,我们看到默认的根 Logger 对象使用 error级别打印日志,并且同时打印到控制台和 日志文件中,控制台和日志文件都对应各自的 Layout 对象配置。通过以上步骤, Log4j 就可以正常运行了。
声明 log4j .xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration>
<appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender">
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{yyyy-MM-dd HH:mm:ss:SSS} - %c -%-4r [%t] %-5p %x - %m%n" />
</layout>
<!--限制输出级别 -->
<filter class="org.apache.log4j.varia.LevelRangeFilter">
<param name="LevelMax" value="ERROR" />
<param name="LevelMin" value="TRACE" />
</filter>
</appender>
<appender name="FILE-ERROR" class="org.apache.log4j.DailyRollingFileAppender">
<param name="DatePattern" value="'.'yyyy-MM-dd" />
<param name="Append" value="true" />
<param name="file" value="/export/Logs/error.log" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{yyyy-MM-dd HH:mm:ss:SSS} [%7r] %6p - %30.30c - %m \n" />
</layout>
<filter class="org.apache.log4j.varia.LevelRangeFilter">
<param name="LevelMin" value="ERROR" />
</filter>
</appender>
<appender name="AsyncLog" class="org.apache.log4j.AsyncAppender">
<param name="BufferSize" value="128" />
<appender-ref ref="MLOG" />
</appender>
<root>
<priority value="ERROR" />
<appender-ref ref="CONSOLE" />
<appender-ref ref="FILE-ERROR" />
</root>
</log4j:configuration>3. Log4j 的锁和性能优化
通常来说,打印日志总比不打印日志要好得多 , 产生问题时至少有据可查,但是存在太多的日志会使服务的性能下降 , 尤其是 Log4j 默认的 Appenders 使用同步锁来实现 。 下面是笔者
亲自测试的一个例子:
Netty 作为 HTTP 服务器实现的一个类似回显的服务,使用 Log4j 记录业务日志,压测时发现每秒最多可处理 9000 个请求,关闭日志时发现每秒最多 可处理 28000 个请求。
可见日志对性能的影响还是很大的。为了找到性能的瓶颈,在压测过程中,使用 Jstack 命令发现并发时线程都在等待一个写日志事件的锁 。其中,在多个线程同时使用一个 Logger 时,在 Category 层次上加了同步锁, Hierarchy 类中的相关代码如下:
public void callAppenders(LoggingEvent event) {
int writes = 0;
for(Category c = this; c != null; c = c.parent) {
// Protected against simultaneous call to addAppender,
// removeAppender,...
synchronized(c) {
if(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if(!c.additive) {
break;
}
}
}
if(writes == 0) {
repository.emitNoAppenderWarning(this);
}
}也就是说,对同一个 Category 对象,所有线程需要同步锁来排队打印日志,这是因为在多线程环境下并发写日志时,首先需要保证线程安全,多个线程一起写日志时,需要一个一个地写,保证内容不能出现交叉等情况 。
另外,多个线程使用同一个 Appender 时,即同时向一个日志文件中打印日志时,在 Appender层次上加同步锁, AppenderSkeleton 类中的相关代码如下 :
public synchronized void doAppend(LoggingEvent event) {
if(closed) {
LogLog.error("Attempted to append to closed appender named [" + name + "].");
return;
}
if(!isAsSevereAsThreshold(event.getLevel())) {
return;
}
Filter f = this.headFilter;
FILTER_LOOP : while(f != null) {
switch (f.decide(event)) {
case Filter.DENY :
return;
case Filter.ACCEPT :
break FILTER_LOOP;
case Filter.NEUTRAL :
f = f.getNext();
}
}
this.append(event);
}可以把一个 FileAppender 对象理解成维护了一个打开的日志文件,当多线程井发把日志写入日志文件时,需要对 Appender 进行同步,保证使用同一个 Logger 对象时只有一个线程使用FileAppender 来写文件,避免了多线程情况下写的日志出现交叉 。
上面代码中的两个锁,一个在 Category层次上,另一个在 Appender 层次上,在高并发的情况下对系统的性能影响很大,因为一个时段只能有一个线程在打印日志,会阻塞其他大部分业务线程,而对日志的收集不是核心链路上的功能, 应该作为一个辅助操作,不能影响核心业务功能 。
所以,我们需要对 Log4j 进行一些改进,首先想到的就是把同步操作改为异步操作,将 Log4j对业务线程的影响降到最小 。
例如:可以使用一个缓冲队列,业务线程仅将日志事件放入缓冲队列就返回,然后用单独的消费者线程去消费缓冲队列,异步将缓冲队列的日志内容打印到日志文件。如果把同步变成异步,则需要合理地选择缓冲区的实现,通常可以用基于数组的有界队列使内存可控,这样不会产生 OOM。在高并发下如果队列满了,则可能会阻塞生产者线程,也可以用基于链表的无界队列,用内存空间换取性能。但是,由于无界队列使用的内存不可控,所以在极端情况下,如果消费者的消费速度远远落后于生产者的生产速度,则将会导致队列变得越来越大而产生 OOM。
另外,一些公司实现了异步日志框架,使用的是 ConcurrentLinkedQueue, 业务线程保存日志到 ConcurrentLinkedQueue,异步线程从 ConcurrentLinkedQueue 消费,然后异步打印日志到本地磁盘的日志文件,由于 ConcurrentLinkedQueue 是一个无界队列,所以仍然会出现内存溢出的风险 。
这里还有一个错误的设计,即使用 ConcurrentLinkedQueue 作为缓冲 。为了避免队列无限增长而产生 OOM,我们使用 ConcurrentLinkedQueue 的 size()方法来判断队列的大小,如果超过一定的阀值,则将抛弃日志,或者将其缓存到本地磁盘,实现对内存的保护 。 但是,由于ConcurrentLinkedQueue 的 size()方法的实现并不是常量时间复杂度的 ,而是 O(n)的,即每次调用size()方法都需要实时计算队列的大小,所以会导致 CPU 利用率加大。
我们解决了异步存储日志到缓冲队列的问题,在消费这个缓冲队列时,可以一条一条地顺序消费 ,也可以采用批量消费的模式 。
- 一条一条地顺序消费就是使用 一个无限循环的线程,只要缓冲队列不为空,就从队列中取日志后写入日志文件中 。
- 批量消费模式会定时取批量日志事件然后写入日志文件中。
在高井发系统中,我们会将这两种模式结合。 为了达到较高的性能,我们使用一个无线循环的线程,批量检查日志缓存队列时是否有日志事件,如果有就批量消费和打印日志。
当然,在实际生产中,我们不用自己实现异步打印日志, Log4j 本身也提供了异步打印日志的功能,我们可以使用 AsyncAppender 类来异步打印日志, AsyncAppender 类的代码如下:
public class AsyncAppender extends AppenderSkeleton
implements AppenderAttachable {
/**
* The default buffer size is set to 128 events.
*/
public static final int DEFAULT_BUFFER_SIZE = 128;
/**
* Event buffer, also used as monitor to protect itself and
* discardMap from simulatenous modifications.
*/
private final List buffer = new ArrayList();
/**
* Map of DiscardSummary objects keyed by logger name.
*/
private final Map discardMap = new HashMap();
/**
* Buffer size.
*/
private int bufferSize = DEFAULT_BUFFER_SIZE;
/** Nested appenders. */
AppenderAttachableImpl aai;
/**
* Nested appenders.
*/
private final AppenderAttachableImpl appenders;
/**
* Dispatcher.
*/
private final Thread dispatcher;
/**
* Should location info be included in dispatched messages.
*/
private boolean locationInfo = false;
/**
* Does appender block when buffer is full.
*/
private boolean blocking = true;我们看到, AsyncAppender 使用了 一个数组 List buffer = new ArrayList() 作为日志事件的缓冲区,而且配合了一个阻塞标记 boolean blocking = true , 并结合条件队列操作 wait 和 notify来实现一个简单的阻塞队列 , 实际上,它并没有直接使用 JDK 自带的阻塞队列。如果使用 JDK自带的阻塞有界队列 ArrayBlockingQueue 来实现,则这个类会更加简单、方便。
另外 , AsyncAppender 将异步线程 Thread dispatcher 作为日志的消费者,只要缓冲队列不为空,就唤醒消费者线程 dispatcher。先将 buffer 中的日志事件移动到另外一个数组,然后异步将日
志事件存储到磁盘文件中,这样 buffer 可以继续给生产者使用,类似 CopyOnWrite 模式的原理。
AsyncAppender 的代码版本比较老,可以使用 ArrayBlockingQueue 对其进行改写,减少条件队列的操作 ,这样的实现更加清晰,使用更简单 。也可以进一步优化, 采用无界的 LinkedBlockingQueue 用空间换性能的方式,这样不会阻塞生产者线程,也就不会阻塞业务线程。只有当 LinedBlockingQueue 为空时才会阻塞消费线程,这是合理的,因为消费线程不是业务线程,没有消息可消费的时候,当然要阻塞并等待,这也防止了消费钱程的空转。
使用阻塞队列时 ,由于生产者和消费者在对队列进行修改时需要排队,所以这时只有一个生产者或者消费者在做事,仍然会影响性能,我们可以考虑使用无锁队列,后续在 Log4j2 中提供了无锁的 Disruptor Ring Buffer 来优化缓冲队列的性能方案 。
Disruptor RingBuffer 是一个优秀的无锁队列,也是一个高性能的异步处理框架,或者可以被认为是最快的消息框架,从设计模式上来讲,它是一个观察者模式的实现 。
相对于 Disruptor 的无锁队列,传统队列存在如下问题 。
- 链表 : 节点分散,不利于 Cache 和批量读取,分配节点需要大量 GC. size/head/tail 有大量的竞争,存在 CPU 缓存的伪竞争 问题 。
- 数组: size/head/tail 一样有大量的竞争,传统方法是在所有写操作上做互斥,效率低下,将这几个有大量读写操作的字段申明在一起时, 存在 CPU 缓存的伪共享问题 。
然而, Disruptor RingBuffer 也是一个数组,但是减少了同步的竞争点,如果有多个生产者 ,则写入标识时仍然有竞争,但是使用 CAS 来实现,如果只有一个生产者写操作就不存在竞争 ,而消费者只记录自己的读取标识位,并不断地监听写标识位作为界限 。
Disruptor RingBuffer 解决了伪共享的问题,例如:
在双核心 CPU 中,每个核心有 64 字节的缓存,假如每个核心的缓存各自加载了引用 r1 和 r2 , 一个核心更新 r1 ,另一个核心更新 r2, CPU 会在硬件级别做互斥,而这个互斥操作是没有必要的, r1 和 r2 没有任何关系,只是在物理顺序上相邻,我们把这个场景叫作伪共享。 RingBuffer 通过在 r1 后面填充字节来解决伪互斥问题,也就是读写指针填满 64 字节的 CPU 缓冲区。
读者可参考文章 “伪共享和缓存行” (链接 :http: //www.jianshu.com/p/7f89650367b8 )查看伪共享对性能影响的测试结果。
在 Disruptor RingBuffer 的生产者快于消费者, 或者消费者快于生产者时,也就是填满了Ringbuffer 或者 RingBuffer 为空时,则需要等待,等待策略如下 。
- BlockingWaitStrategy:默认的策略,是最传统和最安全的,但是效率低下,占用 CPU最少。
- SleepingWaitStrategy:占用 CPU 较多,适合异步写日志,处理延迟高,因为要睡眠。
- YieldingWaitStrategy:占用 CPU 较多,适合开启了超线程模式,释放 CPU 并服务其他线程。
- BusySpinWaitStrategy:占用 CPU 较多,适合未开启超线程模式,独占CPU 。
后三者通过占用大量 CPU 来提高整体的吞吐量和效率,其实就是在等待时没有阻塞和挂起,而是不断地轮询, CPU 占用率确实非常高。
LMAX 是一个新型的交易平台,通过 Disruptor RingBuffer 可以获得每秒 600 万订单,用1ms的延迟获得超过 100万/s 的交易吞吐量。
幸运的是 , Log4j2 己经支持 Disruptor RingBuffer 实现的异步 Logger,在高并发情况下,Log4j 2 在极低的延迟下,吞吐量是 Log4j 1.x 的 18 倍以上 。
五:日志门面框架:Slf4j 使用详解
Slf4j ( Simple Logging Facade for Java )与 Apache Commons Logging 一样,都是使用门面模式对外提供统一的日志接口,应用程序可以只依赖于Slf4j 来实现日志打印,具体的日志实现由配置来决定使用 Log4j 还是 Logback 等,在不改变应用代码的前提下切换底层的日志实现 。
1. 实现结构
Slf4j 仍然使用了门面模式,但是相对于 Commons Logging 做了 一些修改和优化,它在编译时确定底层的日志实现框架,而不是通过配置文件动态地装载底层的实现类,因此,只要底层的日志实现 Jar 包和Slf4j 的静态编译转接包在类路径下即可。
下图为 Slf4j 的实现结构,我们看到除了必要的 Logger 和 LoggerFactory 类,里面的LoggerFactoryBinder 是一个接口,用来在编译时连接相关的日志,实现转接器的关键类。
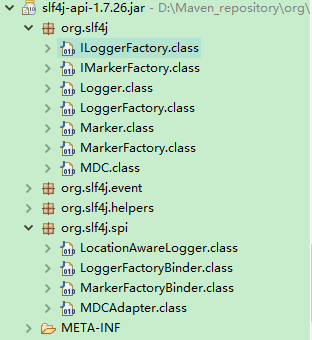
Slf4j 对于每种日志实现框架都提供了一个转接的jar 包 , Jar 包里面包含 LoggerFactoryBinder接口的实现 , 例如,针对 Logback 转接的 Jar 包 logback-classic-1.0.13.jar, 提供了 LoggerFactoryBinder的实现,代码如下:
public class StaticLoggerBinder implements LoggerFactoryBinder {
/**
* The unique instance of this class.
*
*/
private static final StaticLoggerBinder SINGLETON = new StaticLoggerBinder();
/**
* Return the singleton of this class.
*
* @return the StaticLoggerBinder singleton
*/
public static final StaticLoggerBinder getSingleton() {
return SINGLETON;
}
/**
* Declare the version of the SLF4J API this implementation is compiled
* against. The value of this field is usually modified with each release.
*/
// to avoid constant folding by the compiler, this field must *not* be final
public static String REQUESTED_API_VERSION = "1.6.99"; // !final
private static final String loggerFactoryClassStr = Log4jLoggerFactory.class.getName();
/**
* The ILoggerFactory instance returned by the {@link #getLoggerFactory}
* method should always be the same object
*/
private final ILoggerFactory loggerFactory;
private StaticLoggerBinder() {
loggerFactory = new Log4jLoggerFactory();
try {
@SuppressWarnings("unused")
Level level = Level.TRACE;
} catch (NoSuchFieldError nsfe) {
Util.report("This version of SLF4J requires log4j version 1.2.12 or later. See also http://www.slf4j.org/codes.html#log4j_version");
}
}
public ILoggerFactory getLoggerFactory() {
return loggerFactory;
}
public String getLoggerFactoryClassStr() {
return loggerFactoryClassStr;
}
}这样,在使用 Slf4j 的 LoggerFactory 获取 Logger 时,我们就可以直接在类路径上找到 Logger的实际实现类 , 代码如下 :
public static ILoggerFactory getILoggerFactory() {
if (INITIALIZATION_STATE == UNINITIALIZED) {
synchronized (LoggerFactory.class) {
if (INITIALIZATION_STATE == UNINITIALIZED) {
INITIALIZATION_STATE = ONGOING_INITIALIZATION;
performInitialization();
}
}
}
switch (INITIALIZATION_STATE) {
case SUCCESSFUL_INITIALIZATION:
return StaticLoggerBinder.getSingleton().getLoggerFactory();
case NOP_FALLBACK_INITIALIZATION:
return NOP_FALLBACK_FACTORY;
case FAILED_INITIALIZATION:
throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG);
case ONGOING_INITIALIZATION:
// support re-entrant behavior.
// See also http://jira.qos.ch/browse/SLF4J-97
return SUBST_FACTORY;
}
throw new IllegalStateException("Unreachable code");
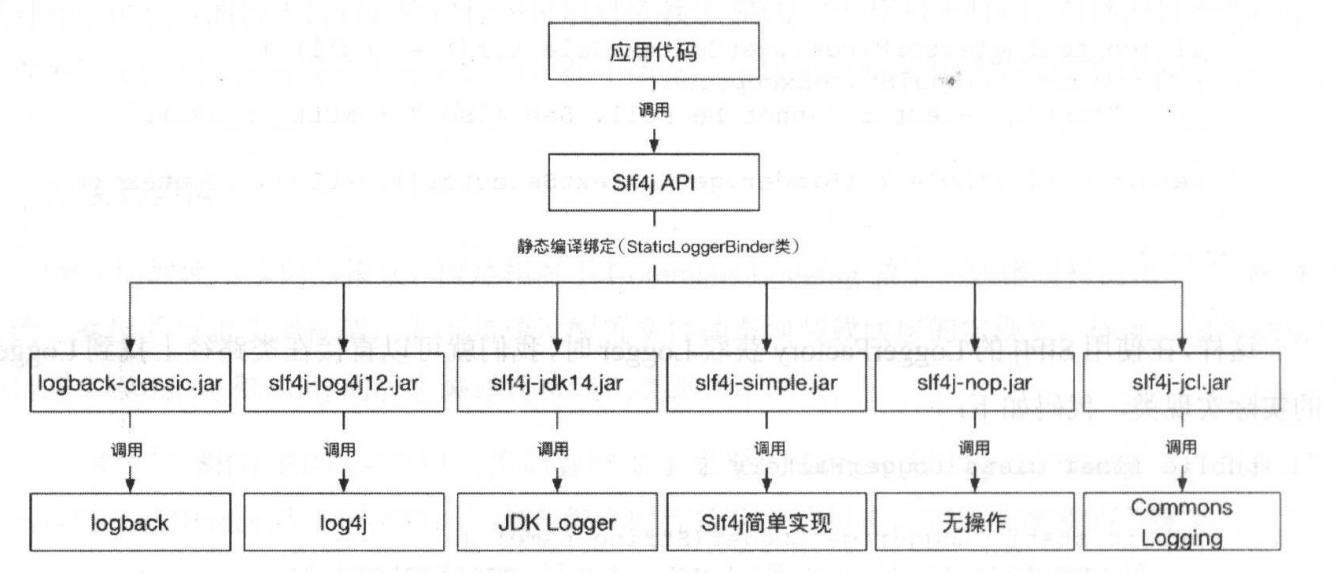
}Slf4j 实现的静态编译绑定架构如下图,应用层程序使用 Slf4j API 打印日志, Slf4j API使用不同的日志实现转接 Jar 包里面的 StaticLoggerBinder 类到不同的日志实现框架中 。
另外,在使用方面的最大改进就是增加了参数化的日志,使我们在打印复杂的日志内容时不再需要判断相应的级别是否己经打开,也就是不再需要下面的代码:
if(logger.isDebugEnabled () ) {... }如下面的代码所示,使用Slf4j 将拼装消息推迟到了它能够确定是不是要显示这条消息时:
logger.debug("The current login user is: {}", logginUser)虽然拼接消息是延迟的 ,并且根据需要才决定是否拼接,但是获取对象的过程还是不可缺少的。
2. 使用方式
前面介绍了 Commons Logging 的使用方式,在使用 Commons Logging 时无须在 maven 的配置文件 pom.xml 中单独引入日志实现框架,便可在运行时直接转接底层的日志实现框架,这是因为 Commons Logging 动态地加载日志实现框架的类。 Slf4j 则不同,它是通过在静态编译时静态绑定相关日志框架的转接器来实现的,在编译时确定使用底层日志框架,因此必须在pom.xml 中单独引入底层日志实现的转接 Jar 包。
这里以 Slf4j 搭配 Log4j 使用为例 。首先,需要在 pom.xml 文件中添加依赖 :
<!--slf4j -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.20</version>
</dependency>
<!--slf4j-log4j -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.12</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>然后 , 编写测试代码:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Slf4jLog4jDemo {
Logger logger = LoggerFactory.getLogger(Slf4jLog4jDemo.class);
public void print() throws IOException {
logger.error("er r or log.. ");
logger.warn("warn log .. ");
logger.info("info log .. ");
logger.debug("debug log.. ");
logger.trace("trace log .. ");
}
}上面的示例通过 Slf4j 的 API 打印日志 , 日志通过 Log4j 最终输出到控制台上。
实际上 , Slf4j 只提供了一个核心模块 slf4j-api.jar, 这个模块下只有日志接口,没有具体的实现,所以在实际开发中需要单独添加底层日志实现的转接包和实现 Jar 包。但是,这些底层日志类实际上和 Slf4j 并没有任何关系 , Slf4j 通过增加日志的中间转接层来转换相应的实现,例如我们在上文中看到的 slf4j-log4j12.jar , 这个设计能有效地避免在特殊的类加载环境下Commons Logging 无法加载具体日志框架实现类的 问题。
六:Logback 介绍及使用
Logback 是由 Log4j 创始人 Ceki 设计的另一个开源日志组件, Logback 并没有在 Apache 开源,而是单独在其主页( https://logback.qos.ch/)开源,如今 Logback 被越来越多地应用在项目中,是目前首选的主流日志记录工具。
1. 实现结构
Logback 分为三个模块: logback-core 、 logback-classic 和 logback-access 。
- logback-core : 是后面两个模块的基础模块,包含日志框架实现的所有基础类 。
- logback-classic : 是 Log4j 的一个改良版本,在性能优化上有较大的提高,并且完整地实现了 Slf4j API,可以很方便地将原日记系统更换成其他日记系统 。
- logback-access : 与 Servlet 容器集成,提供了丰富的 HTTP 访问日志功能。
下图显示了 logback-classic 的项目结构,其中最重要的类就是 Logger,它对外提供了日志记录的 API 。

2. 使用方式
首先,我们需要在应用的 maven 配置文件 pom.xml 中添加依赖:
<!--slf4J -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.20</version>
</dependency>
<!-- logback -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.7</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.1.7</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-access</artifactId>
<version>1.1.7 </version>
</dependency>然后,编写测试代码 :
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Slf4jLogbackDemo {
Logger logger = LoggerFactory.getLogger(Slf4jLogbackDemo.class);
public void test() {
logger.debug("debug log ..");
logger.info("info log ..");
logger.warn("warning log ..");
logger.error("error log ..");
logger.warn("login log ..");
}
}最后,在类路径下声明配置文件 logback.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<!--定义日志文件的存储地址 勿在 LogBack 的配置中使用相对路径-->
<property name="LOG_HOME" value="/home" />
<!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!-- 按照每天生成日志文件 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件输出的文件名-->
<FileNamePattern>${LOG_HOME}/TestWeb.log.%d{yyyy-MM-dd}.log</FileNamePattern>
<!--日志文件保留天数-->
<MaxHistory>30</MaxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
<!--日志文件最大的大小-->
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>10MB</MaxFileSize>
</triggeringPolicy>
</appender>
<!-- 日志输出级别 -->
<root level="INFO">
<appender-ref ref="STDOUT" />
</root>
</configuration>通过以上步骤 , Logback 就可以正常运行了。
3. 性能提升
Logback 相对于 Log4j 的最大提升是效率 , Logback 对 Log4j 的内核进行了重写和优化, 在一些关键执行路径上性能提升了至少 10 倍,初始化内存加载也变得更小了 。
Logback 声称具有极佳的性能, 尤其在某些关键操作上。
- Logback 获取己存的 Logger 只需 94ns,而 Log4j 需要 2234ns 。
- 判定是否记录一条日志语句的操作,其性能得到了显著提高,这个操作在 Logback 中需要 3ns,而在 Log4j 中则需要 30ns
- 在 Log4j 中需要 23ms 创建一个 logger,在 Logback 中只需要 13ms
下面是笔者在自己的笔记本电脑上使用 Logback 进行性能测试的结果 。
- 使用 Logback 的同步记录日志大概可以达到 1.5 万/s 的吞吐量 。
- 使用 Logback 的 AsyncAppender 异步记录日志,内部使用 BlockingQueue 及同步 I/O 实现,大概是 1.7 万/s 的吞吐量,但是波动性较大,性能不稳定。
- 用 Disruptor RingBuffer 的缓冲替换 BlockingQueue 的实现进行定制,记录日志达到 3万/s 的吞吐量。
- 关掉日志可以达到 5 万/s 的吞吐量。
-
七:Apache Log4j 2 介绍及使用
Apache Log4j 2 (简称 Log4j 2 )是 Log4j 的升级版本,相对于 Log4j 1.x,它有很多层面的提高,并且提供了 Logback 的所有高级特性。
Log4j 2 不但提供了高性能,而且提供了对 Log4j 1.2 、 Slf4j 、 Commons Logging 和 Java Logger 的支持,通过 log4j-to-slf4j 的兼容模式,使用 Log4j 2 API 的应用完全可以转接到 Slf4j 支持的任何日志框架上。
与 Logback 一样, Log4j 2 可以动态地加载修改过的配置, 在动态加载的过程中不会丢失日志 。
在 Log4j 2 中,过滤器的实现更加精细化,它可以根据环境数据、标记和正则表达式来过滤日志数据,过滤器可以在 Logger 级别上应用,也可以在 Appender 级别上应用。
1. 实现结构
首先, Log4j 2 实现了 API 模块和实现模块的分离,如图所示,它包含两个 Jar 包, 一个是 log4j-api.jar,另一个是 log4j-core.jar,前者提供 Log4j 对外提供的 API , 主要包含 Logger类和 LogManager 类 ,后者包含实现日志记录功能的核心基础类。
因为 API 与实现分离,所以在 API 对外保持兼容的情况下,开发人员更容易升级内部的实现。
2. 使用方式
首先,我们需要在应用 的 maven 配置文件 pom.xml 中添加依赖:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.5</version>
</dependency>
然后,编写测试代码 :
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Log4j2Demo {
static Logger logger = LogManager.getLogger(Log4j2Demo.class);
public static void main(String[] args) {
logger.trace("trace log ..");
logger.debug("debug log..");
logger.info("info log ..");
logger.warn("warn log .. ");
logger.error("error log ..");
logger.fatal("fatal log.");
}
}最后,在类路径下声明配置文件 log4j2.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!--日志级别以及优先级排序: OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL -->
<!--Configuration后面的status,这个用于设置log4j2自身内部的信息输出,可以不设置,当设置成trace时,你会看到log4j2内部各种详细输出-->
<!--monitorInterval:Log4j能够自动检测修改配置 文件和重新配置本身,设置间隔秒数-->
<configuration status="WARN" monitorInterval="30">
<!--先定义所有的appender-->
<appenders>
<!--这个输出控制台的配置-->
<console name="Console" target="SYSTEM_OUT">
<!--输出日志的格式-->
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
</console>
<!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用-->
<File name="log" fileName="log/test.log" append="false">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File>
<!-- 这个会打印出所有的info及以下级别的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档-->
<RollingFile name="RollingFileInfo" fileName="${sys:user.home}/logs/info.log"
filePattern="${sys:user.home}/logs/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="100 MB"/>
</Policies>
</RollingFile>
<RollingFile name="RollingFileWarn" fileName="${sys:user.home}/logs/warn.log"
filePattern="${sys:user.home}/logs/$${date:yyyy-MM}/warn-%d{yyyy-MM-dd}-%i.log">
<ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="100 MB"/>
</Policies>
<!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件,这里设置了20 -->
<DefaultRolloverStrategy max="20"/>
</RollingFile>
<RollingFile name="RollingFileError" fileName="${sys:user.home}/logs/error.log"
filePattern="${sys:user.home}/logs/$${date:yyyy-MM}/error-%d{yyyy-MM-dd}-%i.log">
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="100 MB"/>
</Policies>
</RollingFile>
</appenders>
<!--然后定义logger,只有定义了logger并引入的appender,appender才会生效-->
<loggers>
<!--过滤掉spring和mybatis的一些无用的DEBUG信息-->
<logger name="org.springframework" level="INFO"></logger>
<logger name="org.mybatis" level="INFO"></logger>
<root level="all">
<appender-ref ref="Console"/>
<appender-ref ref="RollingFileInfo"/>
<appender-ref ref="RollingFileWarn"/>
<appender-ref ref="RollingFileError"/>
</root>
</loggers>
</configuration>3. 性能提升
Log4j 2 的异步记录日志功能通过在一个单独的线程里执行 I/O 操作来提高性能,有两种实现方式:
异步 Appender 和异步 Logger。异步 Appender 与 Log4j 类似,内部通过 ArrayBlockingQueue来实现, 异步的线程从队列里取走日志事件并写入磁盘 , 每次当队列为空时,会对缓冲的批量日志事件进行一次落盘操作.
异步 Logger 是 Log4j 2 新引入的功能,目标是尽可能快地使打印日志的方法调用返回, Logger 分为所有 Logger 全异步,以及同步与异步混合两种类型,异步 Logger使用无锁的 Disruptor RingBuffer 来实现,这样能达到更高的吞吐量和更低的 API 调用延迟 。
所有 Logger 使用异步的配置很简单,只需要配置 JVM 启动参数-DLog4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector,然后把 Disruptor 的 Jar 包放入类路径中即可。
而同步与异步混合 Logger 需要在配置文件中显示指定的<asyncRoot> 或者<asyncLogger>标记即可。
对于性能上的提升,根据 Log4j 2 官方公布的测试数据 ,在 64 线程测试的情况下 , 异步Logger 的吞吐量是异步 Appender 的吞吐量 的 12 倍,是同步 Logger 的吞吐量的 68 倍。
另外,通过对比 Log4j 2 和 Log4j 、 Logback 等,我们发现它们在异步记录日志功能方面的差异。异步 Appender 的性能随着线程数的增加基本保持不变,而 Log4j 2 的异步 Logger 随着线程数的增加其吞吐量也持续增加,在多核 CPU 系统中能够达到更好的性能,如图:
















 1359
1359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









