







Python基础5 爬虫入门——了解爬虫Scrapy
一、爬虫概念
一个在网上到处或定向抓取数据的程序。它会把页面的URL加载到抓取队列中,然后进入到新页面后再递归进行操作。
二、Scrapy
Scrapy是一个为了抓取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
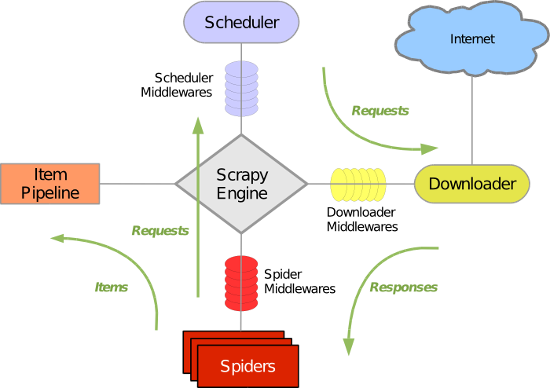
构架图:
1. 安装
环境:ubuntu,
sudo apt-get install python2.7 python2.7-dev
sudo apt-get install build-essential;
#sudo apt-get install python-dev;
sudo apt-get install libxml2-dev;
sudo apt-get install libxslt1-dev;
sudo apt-get install python-setuptools;
sudo apt-get install python-pip
pip install Scrapy
环境:windows
https://pypi.python.org/pypi/pip#downloads
python setup.py install
把python/scripts加到环境变量。
环境: mac
sudo -H pip install Scrapy
2. 说明
- 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
- 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
- 项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
3. 爬取流程
图中绿色是数据走向。首先从初始URL开始,Scheduler会将其交给Downloader进行下载,
下载之后Spider分析结果:
- 需要进一步抓取的链接,如下一页
- 需要保存的数据,送到项目管道,对数据进行后期处理(详细分析、过滤、存储等)
在数据流动的通道里还可以安装各种中间件,进行必要的处理。
4. 数据流
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
三、Scrapy项目基本流程
1. 创建项目
scrapy startproject tutorial
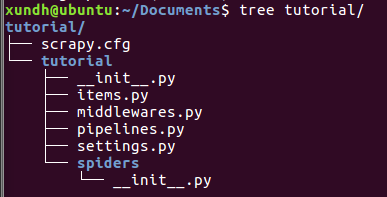
文件说明:
- scrapy.cfg:项目的配置文件
- tutorial/:项目的Python模块,将会从这里引用代码
- tutorial/items.py:项目的items文件
- tutorial/pipelines.py:项目的pipelines文件
- tutorial/settings.py:项目的设置文件
- tutorial/spiders/:存储爬虫的目录
2. 定义要抓取的数据(Item)
修改tutorial目录下的items.py
from scrapy.item import Item,Field
class TutorialItem(Item):
pass
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
3. 使用项目命令genspider创建爬虫Spider
制作爬虫,分为两步:先爬再取。
(1) 爬
Spider是用户自己编写的类,用来从一个域(或域组)中抓取信息。
Spider定义了用于下载的URL列表、跟踪链接的方案、解析网页内容的方式,以此来提取items。
使用scrapy.spider.BaseSpider创建一个子类,并确定三个强制的属性:
- name:爬虫的名字,必须是唯一的,在不同的爬虫中定义不同的名字
- start_urls:爬取的URL列表,爬虫从这里开始。
- parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL
到tutorial/spiders下新建一个爬虫文件:dmoz_spider.py
from scrapy.spider import Spider
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["test.com.cn"] #搜索的域名范围
start_urls = [
"http://test.com.cn/a/b/771.html"
]
def parse(self, response): # 将链接的最后两个地址取出作为文件名进行存储
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
运行测试:
scrapy crawl dmoz
运行结果:
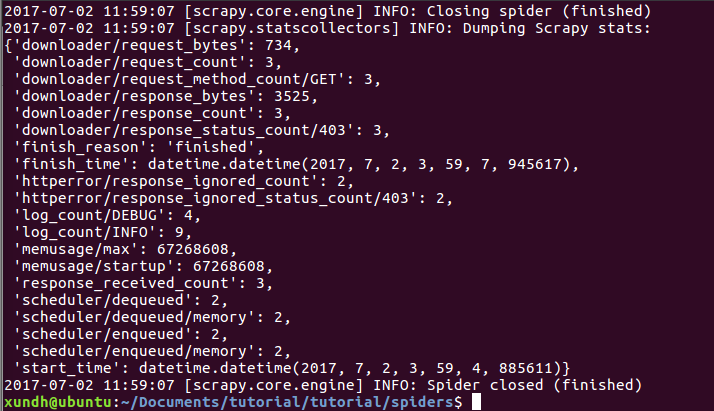
Scrapy为爬虫的 start_urls属性中的每个URL创建了一个 scrapy.http.Request 对象 ,并将爬虫的parse 方法指定为回调函数。
然后,这些 Request被调度并执行,之后通过parse()方法返回scrapy.http.Response对象,并反馈给爬虫。
(2) 取
在Scrapy里,使用XPath selectors 基于XPath。
XPath示例
- /html/head/title: 选择HTML文档元素下面的
标签。 - /html/head/title/text(): 选择前面提到的
元素下面的文本内容 - //td: 选择所有 元素
- //div[@class=“mine”]: 选择所有包含 class=“mine” 属性的div 标签元素
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
W3C XPath教程:http://www.w3school.com.cn/xpath/
Scrapy提供了XPathSelector类:HtmlXPathSelector(HTML数据解析)和XmlXPathSelector(XML数据解析)。
Selectors的基础方法:
- xpath():返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点
- css():返回一系列的selectors,每一个select表示一个css参数表达式选择的节点
- extract():返回一个unicode字符串,为选中的数据
- re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
测试:
scrapy shell http://test.com.cn/a/b/771.html
这时可以用response.body看到本地response变量body的值。
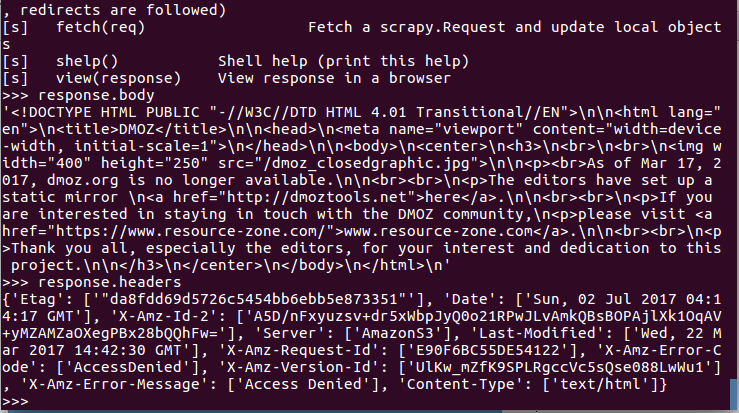
示例:
>>> response.xpath('//title')
[<Selector xpath='//title' data=u'<title>\u3010\u56fe\u3011\u6c49\u5170\u8fbe \u914d\u7f6e_\u6c49\u5170\u8fbe \u53c2\u6570_\u4e30\u7530_\u6c7d\u8f66\u4e4b\u5bb6</title>'>]
>>> response.xpath('//title').extract()
[u'<title>\u3010\u56fe\u3011\u6c49\u5170\u8fbe \u914d\u7f6e_\u6c49\u5170\u8fbe \u53c2\u6570_\u4e30\u7530_\u6c7d\u8f66\u4e4b\u5bb6</title>']
>>> response.xpath('//title/text()')
[<Selector xpath='//title/text()' data=u'\u3010\u56fe\u3011\u6c49\u5170\u8fbe \u914d\u7f6e_\u6c49\u5170\u8fbe \u53c2\u6570_\u4e30\u7530_\u6c7d\u8f66\u4e4b\u5bb6'>]
>>> response.xpath('//title/text()').extract()
[u'\u3010\u56fe\u3011\u6c49\u5170\u8fbe \u914d\u7f6e_\u6c49\u5170\u8fbe \u53c2\u6570_\u4e30\u7530_\u6c7d\u8f66\u4e4b\u5bb6']
原来的sel已经使用response替换。
4. 编写提取item数据的Spider
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["test.com.cn"]
start_urls = [
"http://test.com.cn/a/b/771.html"
]
def parse(self,response):
sel = Selector(response)
sites = sel.xpath('//title')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.xpath('text()').extract()
print item['title']
items.append(item)
return items
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//title')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
desc = site.xpath('text()').extract()
print title
5. 进行爬取
scrapy crawl dmoz
6. 通过选择器提取数据
示例
sites = sel.xpath('//ul[@class="directory-url"]/li')
7. 保存数据
scrapy crawl dmoz -o items.json -t json
-o 文件名
-t 导出类型
本文来源:
http://www.jianshu.com/p/a8aad3bf4dc4
参考资料:
http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/architecture.html
http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/tutorial.html
http://www.zhihu.com/question/20899988
http://www.cnblogs.com/wuxl360/p/5567631.html
问题处理:
ImprtError: No module named win32api
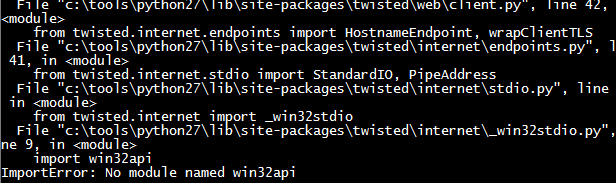
需要到https://sourceforge.net/projects/pywin32/files/pywin32/
下载对应版本安装。
安装的时候可能会出现:
python2.7 is required for this package select installation to use
则执行下面的python
#
# script to register Python 2.0 or later for use with win32all
# and other extensions that require Python registry settings
#
# written by Joakim Loew for Secret Labs AB / PythonWare
#
# source:
# http://www.pythonware.com/products/works/articles/regpy20.htm
#
# modified by Valentine Gogichashvili as described in http://www.mail-archive.com/distutils-sig@python.org/msg10512.html
import sys
from _winreg import *
# tweak as necessary
version = sys.version[:3]
installpath = sys.prefix
regpath = "SOFTWARE\\Python\\Pythoncore\\%s\\" % (version)
installkey = "InstallPath"
pythonkey = "PythonPath"
pythonpath = "%s;%s\\Lib\\;%s\\DLLs\\" % (
installpath, installpath, installpath
)
def RegisterPy():
try:
reg = OpenKey(HKEY_CURRENT_USER, regpath)
except EnvironmentError as e:
try:
reg = CreateKey(HKEY_CURRENT_USER, regpath)
SetValue(reg, installkey, REG_SZ, installpath)
SetValue(reg, pythonkey, REG_SZ, pythonpath)
CloseKey(reg)
except:
print "*** Unable to register!"
return
print "--- Python", version, "is now registered!"
return
if (QueryValue(reg, installkey) == installpath and
QueryValue(reg, pythonkey) == pythonpath):
CloseKey(reg)
print "=== Python", version, "is already registered!"
return
CloseKey(reg)
print "*** Unable to register!"
print "*** You probably have another Python installation!"
if __name__ == "__main__":
RegisterPy()
参考:
http://www.cnblogs.com/min0208/archive/2012/05/24/2515584.html















 55万+
55万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











