







目录
分布式锁与领导选举关键点
1、最多一个获取锁 / 成为Leader
对于分布式锁(这里特指排它锁)而言,任意时刻,最多只有一个进程(对于单进程内的锁而言是单线程)可以获得锁。
对于领导选举而言,任意时间,最多只有一个成功当选为Leader。否则即出现脑裂(Split brain)
2、锁重入 / 确认自己是Leader
对于分布式锁,需要保证获得锁的进程在释放锁之前可再次获得锁,即锁的可重入性。
对于领导选举,Leader需要能够确认自己已经获得领导权,即确认自己是Leader。
3、释放锁 / 放弃领导权
锁的获得者应该能够正确释放已经获得的锁,并且当获得锁的进程宕机时,锁应该自动释放,从而使得其它竞争方可以获得该锁,从而避免出现死锁的状态。
领导应该可以主动放弃领导权,并且当领导所在进程宕机时,领导权应该自动释放,从而使得其它参与者可重新竞争领导而避免进入无主状态。
4、感知锁释放 / 领导权的放弃
当获得锁的一方释放锁时,其它对于锁的竞争方需要能够感知到锁的释放,并再次尝试获取锁。
原来的Leader放弃领导权时,其它参与方应该能够感知该事件,并重新发起选举流程。
非公平领导选举
从上面几个方面可见,分布式锁与领导选举的技术要点非常相似,实际上其实现机制也相近。这里以领导选举为例来说明二者的实现原理,分布式锁的实现原理也几乎一致。
1、选主过程
假设有三个ZooKeeper的客户端,如下图所示,同时竞争Leader。这三个客户端同时向ZooKeeper集群注册Ephemeral且Non-sequence类型的节点,路径都为 /zkroot/leader(工程实践中,路径名可自定义)。
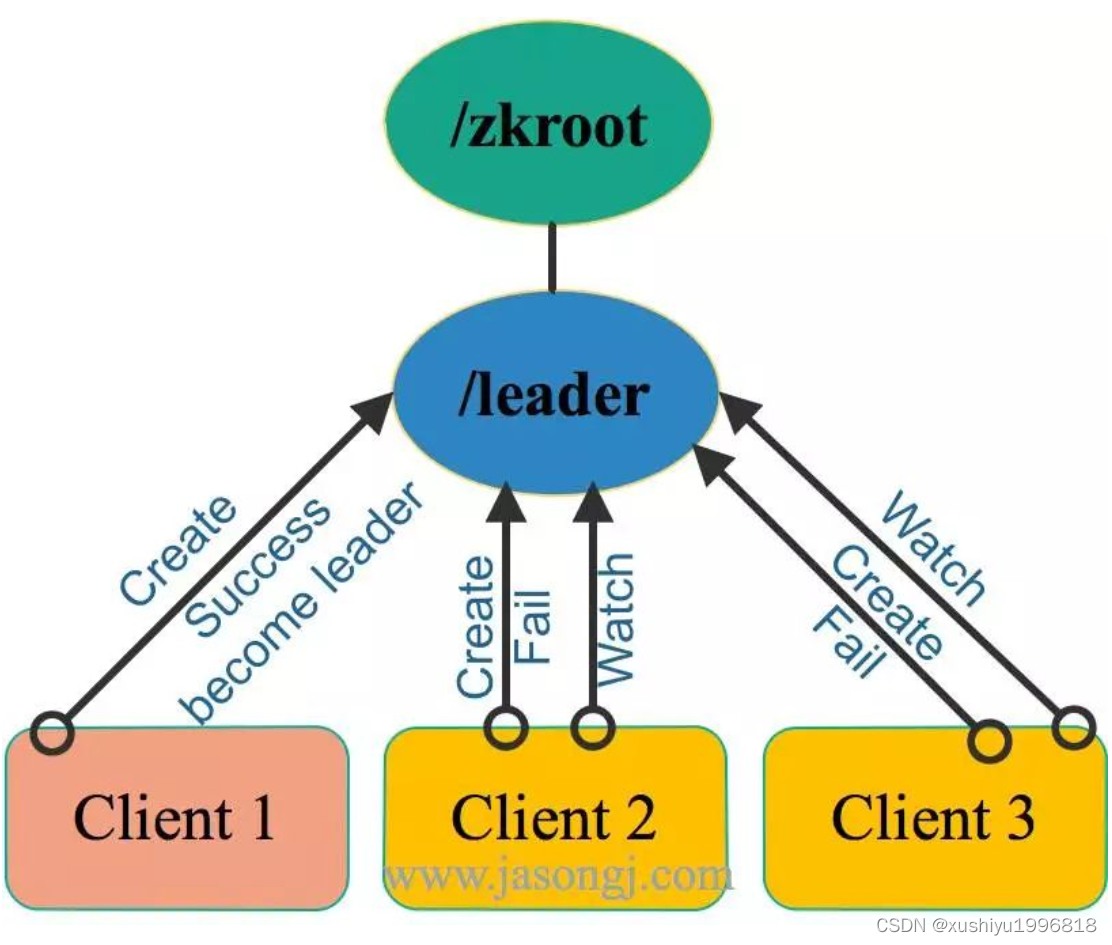
如上图所示,由于是Non-sequence节点,这三个客户端只会有一个创建成功,其它节点均创建失败。此时,创建成功的客户端(即上图中的Client 1)即成功竞选为 Leader 。其它客户端(即上图中的Client 2和Client 3)此时匀为 Follower。
2、放弃领导权
如果 Leader 打算主动放弃领导权,直接删除 /zkroot/leader 节点即可。
如果 Leader 进程意外宕机,其与 ZooKeeper 间的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3163
3163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









