







目录
后缀树简介
字典树(前缀树)的概念
可以参考 https://blog.csdn.net/xushiyu1996818/article/details/89354425
trie树,也就是字典树。trie树有三个性质:
-
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
-
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
-
每个节点的所有子节点包含的字符都不相同。
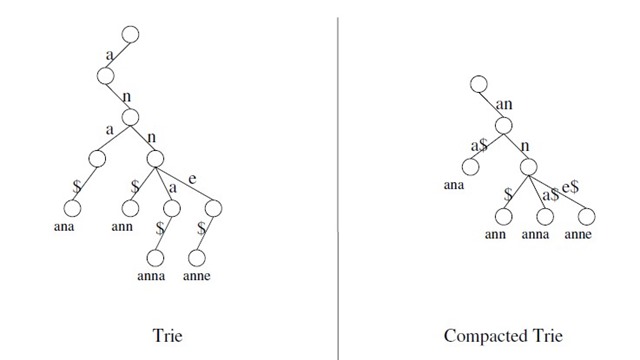
将一系列字符串插入到trie树的过程可以这样来实现:首先,树根不存任何字符;对于每个字符串,从左到右,沿着树从根节点开始往下走直到找不到“路”可以走的时候,“自己开辟一条路”继续往下走。比如往trie树里面存放ana是个字符串的时候(注意一下,$是用来标志字符串末尾),我们会的到这样一棵树:
左图这样存储的时候有点浪费。为了更高效我们把没有分支的路径压缩,于是得到右图。
后缀树的概念
后缀树是一种PAT树,它描述了给定字符串的所有后缀,许多重要的字符串操作都能够在后缀树上快速地实现。
定义
一个长度为n的字符串S,它的后缀树定义为一棵满足如下条件的树:
1. 从根到树叶的路径与S的后缀一一对应。即每条路径惟一代表了S的一个后缀;
2. 每条边都代表一个非空的字符串;
3. 所有内部节点(根节点除外)都有至少两个子节点。
由于并非所有的字符串都存在这样的树,因此S通常使用一个终止符号进行填充(通常使用$)。

优点
1. 匹配快。对于长度为m的模式串,只需花费至多O(m)的时间进行匹配。
2. 空间省。Suffix tree的空间耗费要低于Suffix trie,因为Suffix tree除根节点外不允许其内部节点只含单个子节点,因此它是Suffix trie的压缩表示。

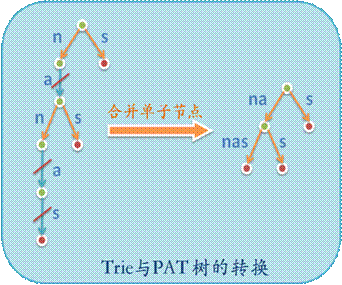
后缀树的生成,Suffix trie ------>> Suffix tree
后缀,顾名思义,甚至通俗点来说,就是所谓后缀就是后面尾巴的意思。比如说给定一长度为n的字符串S=S1S2..Si..Sn,和整数i,1 <= i <= n,子串SiSi+1...Sn便都是字符串S的后缀。
以字符串S=XMADAMYX为例,它的长度为8,所以S[1..8], S[2..8], ... , S[8..8]都算S的后缀,我们一般还把空字串也算成后缀。这样,我们一共有如下后缀。对于后缀S[i..n],我们说这项后缀起始于i。
S[1..8], XMADAMYX, 也就是字符串本身,起始位置为1
S[2..8], MADAMYX,起始位置为2
S[3..8], ADAMYX,起始位置为3
S[4..8], DAMYX,起始位置为4
S[5..8], AMYX,起始位置为5
S[6..8], MYX,起始位置为6
S[7..8], YX,起始位置为7
S[8..8], X,起始位置为8
空字串,记为$。
而后缀树,就是包含一则字符串所有后缀的压缩Trie。把上面的后缀加入Trie后,我们得到下面的结构:
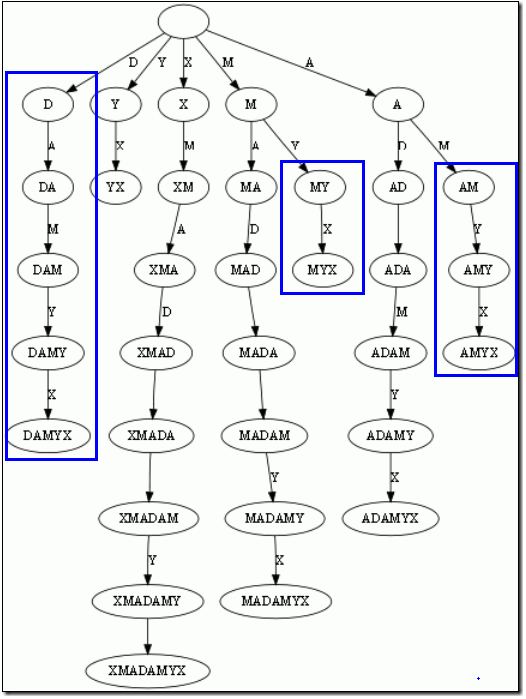
仔细观察上图,我们可以看到不少值得压缩的地方。比如蓝框标注的分支都是独苗,没有必要用单独的节点同边表示。如果我们允许任意一条边里包含多个字 母,就可以把这种没有分叉的路径压缩到一条边。另外每条边已经包含了足够的后缀信息,我们就不用再给节点标注字符串信息了。我们只需要在叶节点上标注上每项后缀的起始位置。于是我们得到下图: 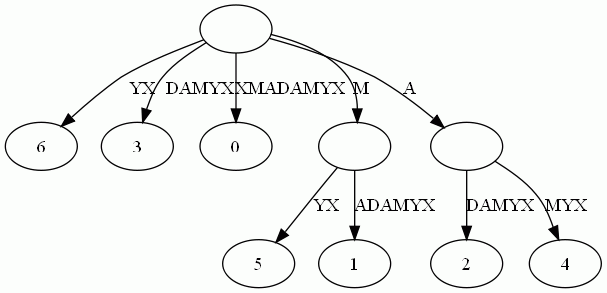
这样的结构丢失了某些后缀。比如后缀X在上图中消失了,因为它正好是字符串XMADAMYX的前缀。为了避免这种情况,我们也规定每项后缀不能是其它后缀的前缀。要解决这个问题其实挺简单,在待处理的子串后加一个空字串就行了。例如我们处理XMADAMYX前,先把XMADAMYX变为 XMADAMYX$,于是就得到suffix tree--后缀树了,如下图所示: 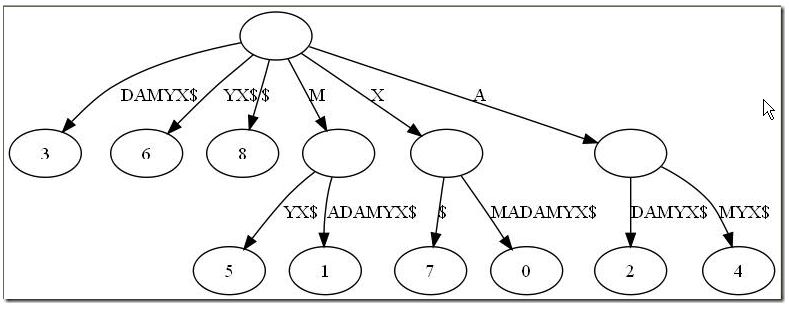
构造后缀树
两种方法在平方时间内构件后缀树
所谓的平方时间是指O(|T|*|T|),|T|是指字符串的长度。
第一种方法非常显然,就是直接按照后缀树的定义来就可以了,将各个后缀依次插入trie树中,再压缩,总的时间复杂度显然是平方级别的。
这里给出的是另外一种方法。对照上面MISSISSIPPI的所有后缀,我们注意到第一种方法就是从左到右扫描完一个后缀再从上到下扫描所有的后缀。那么另外一种思路就是,先安位对齐,然后从上到下扫描完每个位,再从左到右扫描下一位。举个例子吧,第一种方法相当于先扫描完后缀1:MISSISSIPPI ,再往下扫描后缀2:ISSISSIPPI 以此类推;而第二种方法相当于从上到下先插入第一个字符M,然后再从上到下插入第二个字符I(有两个),然后再从上到下插入字符S(有三个)以此类推,参见下图。

但是具体怎么操作呢?因为显然每次操作不能是简简单单的插入字符而已!
我们再后头来看看上述过程,形式化一点,我们将原先的字符串表示为
T = t1t2 … tn$,其中ti表示第i个字符
Pi = t1t2 … ti , i:th prefix of T
构造p1到pn的后缀树
那么,我们每次插入字符ti,相当于完成一个从Trie(Pi-1)到Trie(Pi)的过程,当所有字符插入完毕的时候我们整个后缀树也就构建出来了。
其实就相当于构造abaab的后缀树
先对第一个a,构造
第二个ab ,产生ab,b两个后缀
第三个aba,产生aba,ba,a三个后缀。。。
参见下图ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2926
2926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









