










last modified time:2014-11-9 14:07:00
bullet 是一款开源物理引擎,它提供了碰撞检测、重力模拟等功能,很多3D游戏、3D设计软件(如3D Mark)使用它作为物理引擎。
作为物理引擎,对性能的要求是非常苛刻的;bullet项目之所以能够发展到今天,很大程度取决于它在性能上优异的表现。
翻阅bullet的源码就能看到很多源码级别的优化,本文将介绍的HashMap就是一个典例。
bullet项目首页:http://bulletphysics.org/
注:bullet很多函数定义了Debug版和Release版两个版本,本文仅以Release版为例。
btAlignedAllocator的接口定义
///The btAlignedAllocator is a portable class for aligned memory allocations.
///Default implementations for unaligned and aligned allocations can be overridden by a custom allocator
// using btAlignedAllocSetCustom and btAlignedAllocSetCustomAligned.
template < typename T , unsigned Alignment >
class btAlignedAllocator {
typedef btAlignedAllocator< T , Alignment > self_type;
public:
//just going down a list:
btAlignedAllocator() {}
/*
btAlignedAllocator( const self_type & ) {}
*/
template < typename Other >
btAlignedAllocator( const btAlignedAllocator< Other , Alignment > & ) {}
typedef const T* const_pointer;
typedef const T& const_reference;
typedef T* pointer;
typedef T& reference;
typedef T value_type;
pointer address ( reference ref ) const { return &ref; }
const_pointer address ( const_reference ref ) const { return &ref; }
pointer allocate ( size_type n , const_pointer * hint = 0 ) {
(void)hint;
return reinterpret_cast< pointer >(btAlignedAlloc( sizeof(value_type) * n , Alignment ));
}
void construct ( pointer ptr , const value_type & value ) { new (ptr) value_type( value ); }
void deallocate( pointer ptr ) {
btAlignedFree( reinterpret_cast< void * >( ptr ) );
}
void destroy ( pointer ptr ) { ptr->~value_type(); }
template < typename O > struct rebind {
typedef btAlignedAllocator< O , Alignment > other;
};
template < typename O >
self_type & operator=( const btAlignedAllocator< O , Alignment > & ) { return *this; }
friend bool operator==( const self_type & , const self_type & ) { return true; }
}; void* btAlignedAllocInternal (size_t size, int alignment);
void btAlignedFreeInternal (void* ptr);
#define btAlignedAlloc(size,alignment) btAlignedAllocInternal(size,alignment)
#define btAlignedFree(ptr) btAlignedFreeInternal(ptr)static btAlignedAllocFunc *sAlignedAllocFunc = btAlignedAllocDefault;
static btAlignedFreeFunc *sAlignedFreeFunc = btAlignedFreeDefault;
void btAlignedAllocSetCustomAligned(btAlignedAllocFunc *allocFunc, btAlignedFreeFunc *freeFunc)
{
sAlignedAllocFunc = allocFunc ? allocFunc : btAlignedAllocDefault;
sAlignedFreeFunc = freeFunc ? freeFunc : btAlignedFreeDefault;
}
void* btAlignedAllocInternal (size_t size, int alignment)
{
gNumAlignedAllocs++; // 和gNumAlignedFree结合用来检查内存泄露
void* ptr;
ptr = sAlignedAllocFunc(size, alignment);
// printf("btAlignedAllocInternal %d, %x\n",size,ptr);
return ptr;
}
void btAlignedFreeInternal (void* ptr)
{
if (!ptr)
{
return;
}
gNumAlignedFree++; // 和gNumAlignedAllocs 结合用来检查内存泄露
// printf("btAlignedFreeInternal %x\n",ptr);
sAlignedFreeFunc(ptr);
}
// The developer can let all Bullet memory allocations go through a custom memory allocator, using btAlignedAllocSetCustom
void btAlignedAllocSetCustom(btAllocFunc *allocFunc, btFreeFunc *freeFunc);
// If the developer has already an custom aligned allocator, then btAlignedAllocSetCustomAligned can be used.
// The default aligned allocator pre-allocates extra memory using the non-aligned allocator, and instruments it.
void btAlignedAllocSetCustomAligned(btAlignedAllocFunc *allocFunc, btAlignedFreeFunc *freeFunc);
无论是否定制自己的Alloc/Free(或AllignedAlloc/AlignedFree),bullet内的其他数据结构都使用btAlignedAllocator作为内存分配(回收)的接口。随后将会看到,btAlignedAllocator的定制化设计与std::allocator的不同,文末详细讨论。
btAlignedAllocator的内存对齐
btAlignedAllocator除了定制化与std::allocator不同外,还增加了内存对齐功能(从它的名字也能看得出来)。继续查看btAlignedAllocDefault/btAlignedFreeDefault的定义(btAlignedAllocator.{h|cpp})可以看到:
#if defined (BT_HAS_ALIGNED_ALLOCATOR)
#include <malloc.h>
static void *btAlignedAllocDefault(size_t size, int alignment)
{
return _aligned_malloc(size, (size_t)alignment); // gcc 提供了
}
static void btAlignedFreeDefault(void *ptr)
{
_aligned_free(ptr);
}
#elif defined(__CELLOS_LV2__)
#include <stdlib.h>
static inline void *btAlignedAllocDefault(size_t size, int alignment)
{
return memalign(alignment, size);
}
static inline void btAlignedFreeDefault(void *ptr)
{
free(ptr);
}
#else // 当前编译环境没有 对齐的(aligned)内存分配函数
static inline void *btAlignedAllocDefault(size_t size, int alignment)
{
void *ret;
char *real;
real = (char *)sAllocFunc(size + sizeof(void *) + (alignment-1)); // 1. 多分配一点内存
if (real) {
ret = btAlignPointer(real + sizeof(void *),alignment); // 2. 指针调整
*((void **)(ret)-1) = (void *)(real); // 3. 登记实际地址
} else {
ret = (void *)(real);
}
return (ret);
}
static inline void btAlignedFreeDefault(void *ptr)
{
void* real;
if (ptr) {
real = *((void **)(ptr)-1); // 取出实际内存块 地址
sFreeFunc(real);
}
}
#endifbullet本身也实现了一个对齐的(aligned)内存分配函数,在系统没有对齐的内存分配函数的情况下,也能保证btAlignedAllocator::acllocate返回的地址是按特定字节对齐的。
下面就来分析btAlignedAllocDefault / btAlignedFreeDefault是如何实现aligned allocation / free的。sAllocFunc/sFreeFunc的定义及初始化:
static void *btAllocDefault(size_t size)
{
return malloc(size);
}
static void btFreeDefault(void *ptr)
{
free(ptr);
}
static btAllocFunc *sAllocFunc = btAllocDefault;
static btFreeFunc *sFreeFunc = btFreeDefault;bullet同时提供了,AllocFunc/FreeFunc的定制化:
void btAlignedAllocSetCustom(btAllocFunc *allocFunc, btFreeFunc *freeFunc)
{
sAllocFunc = allocFunc ? allocFunc : btAllocDefault;
sFreeFunc = freeFunc ? freeFunc : btFreeDefault;
}
再来看看bullet是如何实现指针对齐的(btScalar.h):
///align a pointer to the provided alignment, upwards
template <typename T>T* btAlignPointer(T* unalignedPtr, size_t alignment)
{
struct btConvertPointerSizeT
{
union
{
T* ptr;
size_t integer;
};
};
btConvertPointerSizeT converter;
const size_t bit_mask = ~(alignment - 1);
converter.ptr = unalignedPtr;
converter.integer += alignment-1;
converter.integer &= bit_mask;
return converter.ptr;
}接下来分析btAlignPointer是如何调整指针的?
实际调用btAlignPointer时,使用的alignment都是2的指数,如btAlignedObjectArray使用的是16,下面就以16进行分析。
先假设unalignedPtr是alignment(16)的倍数,则converter.integer += alignment-1; 再 converter.integer &= bit_mask之后,unalignedPtr的值不变,还是alignment(16)的倍数。
再假设unalignedPtr不是alignment(16)的倍数,则converter.integer += alignment-1; 再converter.integer &= bit_mask之后,unalignedPtr的值将被上调到alignment(16)的倍数。
所以btAlignPointer能够将unalignedPtr对齐到alignment倍数。】
明白了btAlignPointer的作用,自然能够明白btAlignedAllocDefault中为什么多申请一点内存,申请的大小是size + sizeof(void *) + (alignment-1):
如果sAllocFunc返回的地址已经按照alignment对齐,则sizeof(void*)和sizeof(alignment-1)及btAlignedAllocDefault的返回值关系如下图所示:
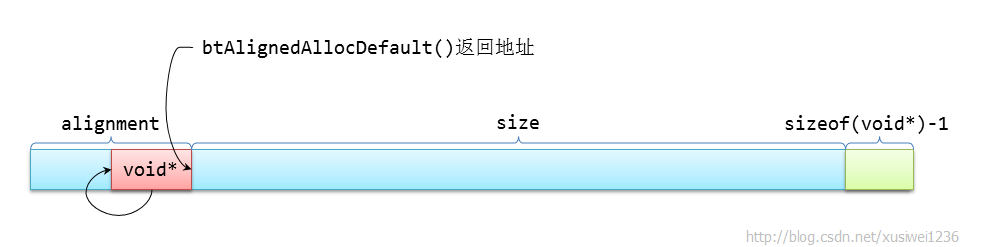
void*前面的alignment-sizeof(void*)字节和尾部的sizeof(size)-1字节的内存会被浪费,不过很小(相对内存条而言)管他呢!
如果sAllocFunc返回的地址没能按alignment对齐,则sizeof(void*)和sizeof(alignment-1)及btAlignedAllocDefault的返回值关系如下图所示:

PS: 顺便一提,为什么需要内存对齐?简单地说,按照机器字长倍数对齐的内存,CPU访问的速度更快;具体来说,则要根据具体CPU和总线控制器的厂商文档来讨论的,那将涉及很多平台、硬件细节,所以本文不对该话题着墨太多。
btAlignedObjectArray——bullet的动态数组
btAlignedObjectArray的作用与STL的vector类似(以下称std::vector),都是动态数组,btAlignedObjectArray的数据成员(data member)声明如下:
template <typename T>
class btAlignedObjectArray
{
btAlignedAllocator<T , 16> m_allocator; // 没有data member,不会增加内存
int m_size;
int m_capacity;
T* m_data;
//PCK: added this line
bool m_ownsMemory;
// ... 省略
};btAlignedObjectArray同时封装了QuickSort,HeapSort,BinarySearch,LinearSearch函数,可用于排序、查找,btAlignedObjectArray的所有成员函数(member function)定义如下:
template <typename T>
//template <class T>
class btAlignedObjectArray
{
btAlignedAllocator<T , 16> m_allocator;
int m_size;
int m_capacity;
T* m_data;
//PCK: added this line
bool m_ownsMemory;
#ifdef BT_ALLOW_ARRAY_COPY_OPERATOR
public:
SIMD_FORCE_INLINE btAlignedObjectArray<T>& operator=(const btAlignedObjectArray<T> &other);
#else//BT_ALLOW_ARRAY_COPY_OPERATOR
private:
SIMD_FORCE_INLINE btAlignedObjectArray<T>& operator=(const btAlignedObjectArray<T> &other);
#endif//BT_ALLOW_ARRAY_COPY_OPERATOR
protected:
SIMD_FORCE_INLINE int allocSize(int size);
SIMD_FORCE_INLINE void copy(int start,int end, T* dest) const;
SIMD_FORCE_INLINE void init();
SIMD_FORCE_INLINE void destroy(int first,int last);
SIMD_FORCE_INLINE void* allocate(int size);
SIMD_FORCE_INLINE void deallocate();
public:
btAlignedObjectArray();
~btAlignedObjectArray();
///Generally it is best to avoid using the copy constructor of an btAlignedObjectArray,
// and use a (const) reference to the array instead.
btAlignedObjectArray(const btAlignedObjectArray& otherArray);
/// return the number of elements in the array
SIMD_FORCE_INLINE int size() const;
SIMD_FORCE_INLINE const T& at(int n) const;
SIMD_FORCE_INLINE T& at(int n);
SIMD_FORCE_INLINE const T& operator[](int n) const;
SIMD_FORCE_INLINE T& operator[](int n);
///clear the array, deallocated memory. Generally it is better to use array.resize(0),
// to reduce performance overhead of run-time memory (de)allocations.
SIMD_FORCE_INLINE void clear();
SIMD_FORCE_INLINE void pop_back();
///resize changes the number of elements in the array. If the new size is larger,
// the new elements will be constructed using the optional second argument.
///when the new number of elements is smaller, the destructor will be called,
// but memory will not be freed, to reduce performance overhead of run-time memory (de)allocations.
SIMD_FORCE_INLINE void resizeNoInitialize(int newsize);
SIMD_FORCE_INLINE void resize(int newsize, const T& fillData=T());
SIMD_FORCE_INLINE T& expandNonInitializing( );
SIMD_FORCE_INLINE T& expand( const T& fillValue=T());
SIMD_FORCE_INLINE void push_back(const T& _Val);
/// return the pre-allocated (reserved) elements, this is at least
// as large as the total number of elements,see size() and reserve()
SIMD_FORCE_INLINE int capacity() const;
SIMD_FORCE_INLINE void reserve(int _Count);
class less
{ public:
bool operator() ( const T& a, const T& b ) { return ( a < b ); }
};
template <typename L>
void quickSortInternal(const L& CompareFunc,int lo, int hi);
template <typename L>
void quickSort(const L& CompareFunc);
///heap sort from http://www.csse.monash.edu.au/~lloyd/tildeAlgDS/Sort/Heap/
template <typename L>
void downHeap(T *pArr, int k, int n, const L& CompareFunc);
void swap(int index0,int index1);
template <typename L>
void heapSort(const L& CompareFunc);
///non-recursive binary search, assumes sorted array
int findBinarySearch(const T& key) const;
int findLinearSearch(const T& key) const;
void remove(const T& key);
//PCK: whole function
void initializeFromBuffer(void *buffer, int size, int capacity);
void copyFromArray(const btAlignedObjectArray& otherArray);
};btAlignedObjectArray和std::vector类似,各成员函数的具体实现这里不再列出。
std::unordered_map的内存布局
btHashMap的内存布局与我们常见的HashMap的内存布局截然不同,为了和btHashMap的内存布局对比,这里先介绍一下std::unordered_map的内存布局。
GCC中std::unordered_map仅是对_Hahstable的简单包装,_Hashtable的数据成员定义如下:
__bucket_type* _M_buckets;
size_type _M_bucket_count;
__before_begin _M_bbegin;
size_type _M_element_count;
_RehashPolicy _M_rehash_policy;继续跟踪_bucket_type,可以看到(_Hashtable):
using __bucket_type = typename __hashtable_base::__bucket_type; using __node_base = __detail::_Hash_node_base;
using __bucket_type = __node_base*;至此,才知道_M_buckets的类型为:_Hash_node_base**
继续追踪,可以看到_Hash_node_base的定义: /**
* struct _Hash_node_base
*
* Nodes, used to wrap elements stored in the hash table. A policy
* template parameter of class template _Hashtable controls whether
* nodes also store a hash code. In some cases (e.g. strings) this
* may be a performance win.
*/
struct _Hash_node_base
{
_Hash_node_base* _M_nxt;
_Hash_node_base() : _M_nxt() { }
_Hash_node_base(_Hash_node_base* __next) : _M_nxt(__next) { }
};从_Hashtable::_M_buckets(二维指针)和_Hash_node_base的_M_nxt的类型(指针),可以猜测Hashtable的内存布局——buckets数组存放hash值相同的node链表的头指针,每个bucket上挂着一个链表。
继续看__before_begin的类型(_Hashtable):
using __before_begin = __detail::_Before_begin<_Node_allocator_type>; /**
* This type is to combine a _Hash_node_base instance with an allocator
* instance through inheritance to benefit from EBO when possible.
*/
template<typename _NodeAlloc>
struct _Before_begin : public _NodeAlloc
{
_Hash_node_base _M_node;
_Before_begin(const _Before_begin&) = default;
_Before_begin(_Before_begin&&) = default;
template<typename _Alloc>
_Before_begin(_Alloc&& __a)
: _NodeAlloc(std::forward<_Alloc>(__a))
{ }
}; iterator
begin() noexcept
{ return iterator(_M_begin()); }
__node_type*
_M_begin() const
{ return static_cast<__node_type*>(_M_before_begin()._M_nxt); }
const __node_base&
_M_before_begin() const
{ return _M_bbegin._M_node; }
实际存放Value的node类型为下面两种的其中一种(按Hash_node_base的注释,Key为string时可能会用第一种,以提升性能):
/**
* Specialization for nodes with caches, struct _Hash_node.
*
* Base class is __detail::_Hash_node_base.
*/
template<typename _Value>
struct _Hash_node<_Value, true> : _Hash_node_base
{
_Value _M_v;
std::size_t _M_hash_code;
template<typename... _Args>
_Hash_node(_Args&&... __args)
: _M_v(std::forward<_Args>(__args)...), _M_hash_code() { }
_Hash_node*
_M_next() const { return static_cast<_Hash_node*>(_M_nxt); }
};
/**
* Specialization for nodes without caches, struct _Hash_node.
*
* Base class is __detail::_Hash_node_base.
*/
template<typename _Value>
struct _Hash_node<_Value, false> : _Hash_node_base
{
_Value _M_v;
template<typename... _Args>
_Hash_node(_Args&&... __args)
: _M_v(std::forward<_Args>(__args)...) { }
_Hash_node*
_M_next() const { return static_cast<_Hash_node*>(_M_nxt); }
};_Hashtable::insert:
template<typename _Pair, typename = _IFconsp<_Pair>>
__ireturn_type
insert(_Pair&& __v)
{
__hashtable& __h = this->_M_conjure_hashtable();
return __h._M_emplace(__unique_keys(), std::forward<_Pair>(__v));
}
_Hashtable::_M_emplace(返回值类型写得太复杂,已删除):
_M_emplace(std::true_type, _Args&&... __args)
{
// First build the node to get access to the hash code
__node_type* __node = _M_allocate_node(std::forward<_Args>(__args)...); // 申请链表节点 __args为 pair<Key, Value> 类型
const key_type& __k = this->_M_extract()(__node->_M_v); // 从节点中抽取 key
__hash_code __code;
__try
{
__code = this->_M_hash_code(__k);
}
__catch(...)
{
_M_deallocate_node(__node);
__throw_exception_again;
}
size_type __bkt = _M_bucket_index(__k, __code); // 寻找buckets上的对应hash code对应的index
if (__node_type* __p = _M_find_node(__bkt, __k, __code)) // 在bucket所指链表上找到实际节点
{
// There is already an equivalent node, no insertion
_M_deallocate_node(__node);
return std::make_pair(iterator(__p), false);
}
// Insert the node
return std::make_pair(_M_insert_unique_node(__bkt, __code, __node),
true);
}_Hashtable::_M_find_node:
__node_type*
_M_find_node(size_type __bkt, const key_type& __key,
__hash_code __c) const
{
__node_base* __before_n = _M_find_before_node(__bkt, __key, __c);
if (__before_n)
return static_cast<__node_type*>(__before_n->_M_nxt);
return nullptr;
}_Hashtable::_M_find_before_node(返回值类型写得太复杂,已删除):
_M_find_before_node(size_type __n, const key_type& __k,
__hash_code __code) const
{
__node_base* __prev_p = _M_buckets[__n]; // 取出头指针
if (!__prev_p)
return nullptr;
__node_type* __p = static_cast<__node_type*>(__prev_p->_M_nxt);
for (;; __p = __p->_M_next()) // 遍历链表
{
if (this->_M_equals(__k, __code, __p)) // key匹配?
return __prev_p;
if (!__p->_M_nxt || _M_bucket_index(__p->_M_next()) != __n)
break;
__prev_p = __p;
}
return nullptr;
}看到_Hashtable::_M_find_before_node的代码,就验证了此前我们对于Hashtable内存布局的猜想:这和SGI hash_map的实现体hashtable的内存布局相同(详情可参考《STL源码剖析》,侯捷先生著)。
(PS:追踪起来并不轻松,可以借助Eclipse等集成开发环境进行)
例如,std::unordered_map<int, int*>背后的Hashtable的一种可能的内存布局如下:
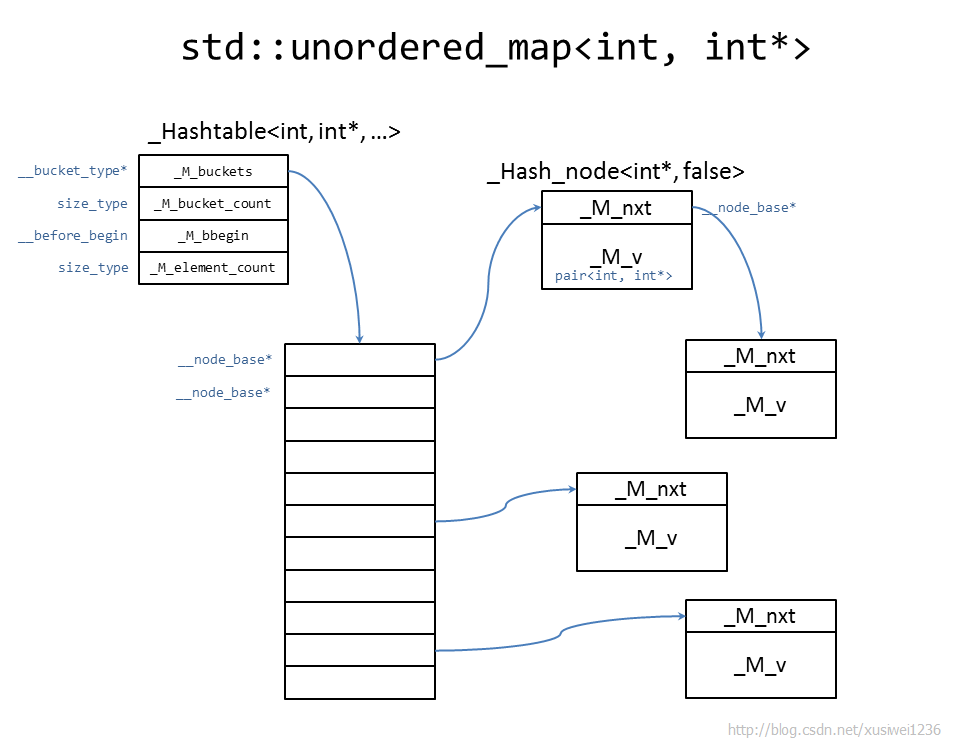
std::unordered_map的内存布局是大多数<数据结构>、<算法>类教材给出的“标准做法”,也是比较常见的实现方法。
btHashMap
btHashMap的内存布局,与“标准做法”截然不同,如下可见btHashMap的数据成员(data member)定义:
template <class Key, class Value>
class btHashMap
{
protected:
btAlignedObjectArray<int> m_hashTable;
btAlignedObjectArray<int> m_next;
btAlignedObjectArray<Value> m_valueArray;
btAlignedObjectArray<Key> m_keyArray;
// ... 省略
};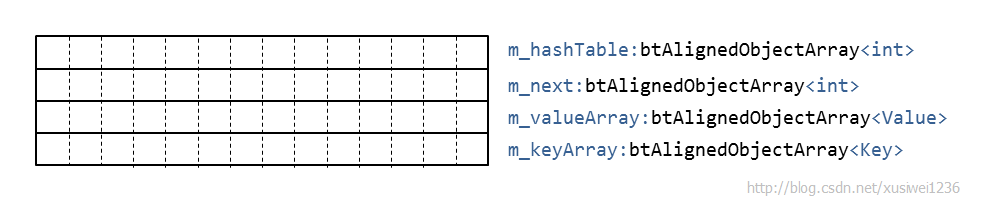
根据命名,可以猜测:
m_keyArray和m_valueArray分别存放key和value;
m_next的作用应该是存放k/v array的index,以此形成链表;
m_hashTable的作用应该和前面_M_bukets所指向的数组类似,作为表头;
下面通过分析btHashMap的几个方法,来对这几个猜测一一验证。
btHashMap::findIndex
下面来看看btHashMap::findIndex的实现:
int findIndex(const Key& key) const
{
unsigned int hash = key.getHash() & (m_valueArray.capacity()-1); // 依赖 Key::getHash()
if (hash >= (unsigned int)m_hashTable.size())
{
return BT_HASH_NULL;
}
int index = m_hashTable[hash]; // index相当于unordered_map的buckets[hash]的链表头指针
while ((index != BT_HASH_NULL) && key.equals(m_keyArray[index]) == false) // 遍历链表,直到匹配,依赖 Key::equals(Key)
{
index = m_next[index];
}
return index;
}btHashMap::findIndex用到了m_hashTable,m_keyArray,m_next,可以看出:
m_hashTable的作用确实类似于unordered_map的buckets数组;
m_keyArray确实是存放了key;
m_next[i]确实类似于unordered_map链表节点的next指针。
btHashMap::insert
接下来看看btHashMap::insert:
void insert(const Key& key, const Value& value) {
int hash = key.getHash() & (m_valueArray.capacity()-1);
//replace value if the key is already there
int index = findIndex(key); // 找到了<Key, Value>节点
if (index != BT_HASH_NULL)
{
m_valueArray[index]=value; // 找到了,更行value
return;
}
int count = m_valueArray.size(); // 当前已填充数目
int oldCapacity = m_valueArray.capacity();
m_valueArray.push_back(value); // value压入m_valueArray的尾部,capacity可能增长
m_keyArray.push_back(key); // key压入m_keyArray的尾部
int newCapacity = m_valueArray.capacity();
if (oldCapacity < newCapacity)
{
growTables(key); // 如果增长,调整其余两个数组的大小,并调整头指针所在位置
//hash with new capacity
hash = key.getHash() & (m_valueArray.capacity()-1);
}
m_next[count] = m_hashTable[hash]; // 连同下一行,将新节点插入 m_hashTable[hash]链表头部
m_hashTable[hash] = count;
}
这里验证了:m_valueArray存放的确实是value。
btHashMap::remove
btHashMap与普通Hash表的区别在于,它可能要自己管理节点内存;比如,中间节点remove掉之后,如何保证下次insert能够复用节点内存?通过btHashMap::remove可以知道bullet是如何实现的:
void remove(const Key& key) {
int hash = key.getHash() & (m_valueArray.capacity()-1);
int pairIndex = findIndex(key); // 找到<Key, Value>的 index
if (pairIndex ==BT_HASH_NULL)
{
return;
}
// Remove the pair from the hash table.
int index = m_hashTable[hash]; // 取出头指针
btAssert(index != BT_HASH_NULL);
int previous = BT_HASH_NULL;
while (index != pairIndex) // 找index的前驱
{
previous = index;
index = m_next[index];
}
if (previous != BT_HASH_NULL) // 将当前节点从链表上删除
{
btAssert(m_next[previous] == pairIndex);
m_next[previous] = m_next[pairIndex]; // 当前节点位于链表中间
}
else
{
m_hashTable[hash] = m_next[pairIndex]; // 当前节点是链表第一个节点
}
// We now move the last pair into spot of the
// pair being removed. We need to fix the hash
// table indices to support the move.
int lastPairIndex = m_valueArray.size() - 1;
// If the removed pair is the last pair, we are done.
if (lastPairIndex == pairIndex) // 如果<Key, Value>已经是array的最后一个元素,则pop_back将减小size(capacity不变)
{
m_valueArray.pop_back();
m_keyArray.pop_back();
return;
}
// Remove the last pair from the hash table. 将最后一个<Key, Value>对从array上移除
int lastHash = m_keyArray[lastPairIndex].getHash() & (m_valueArray.capacity()-1);
index = m_hashTable[lastHash];
btAssert(index != BT_HASH_NULL);
previous = BT_HASH_NULL;
while (index != lastPairIndex)
{
previous = index;
index = m_next[index];
}
if (previous != BT_HASH_NULL)
{
btAssert(m_next[previous] == lastPairIndex);
m_next[previous] = m_next[lastPairIndex];
}
else
{
m_hashTable[lastHash] = m_next[lastPairIndex];
}
// Copy the last pair into the remove pair's spot. 将最后一个<Key, Value>拷贝到移除pair的空当处
m_valueArray[pairIndex] = m_valueArray[lastPairIndex];
m_keyArray[pairIndex] = m_keyArray[lastPairIndex];
// Insert the last pair into the hash table , 将移除节点插入到m_hashTable[lastHash]链表的头部
m_next[pairIndex] = m_hashTable[lastHash];
m_hashTable[lastHash] = pairIndex;
m_valueArray.pop_back();
m_keyArray.pop_back();
}内存紧密(连续)的好处
btHashMap的这种设计,能够保证整个Hash表内存的紧密(连续)性;而这种连续性的好处主要在于:
第一,能与数组(指针)式API兼容,比如很多OpenGL API。因为存在btHashMap内的Value和Key在内存上都是连续的,所以这一点很好理解;
第二,保证了cache命中率(表元素较少时)。由于普通链表的节点内存是在每次需要时才申请的,所以基本上不会连续,通常不在相同内存页。所以,即便是短时间内多次访问链表节点,也可能由于节点内存分散造成不能将所有节点放入cache,从而导致访问速度的下降;而btHashMap的节点内存始终连续,因而保证较高的cache命中率,能带来一定程度的性能提升。
btAlignedAllocator点评
btAlignedAllocator定制化接口与std::allocator完全不同。std::allocator的思路是:首先实现allocator,然后将allocator作为模板参数写入具体数据结构上,如vector<int, allocator<int> >;
这种方法虽然可以实现“定制化”,但存在着一定的问题:
第一,由于所有标准库的allcoator用的都是std::allocator,如果你使用了另外一种allocator,程序中就可能存在不止一种类型的内存管理方法一起工作的局面;特别是当标准库使用的是SGI 当年实现的“程序退出时才归还所有内存的”allocator(具体可参阅《STL源码剖析》)时,内存争用是不可避免的。
第二,这种设计无形中增加了编码和调试的复杂性,相信调试过gcc STL代码的人深有体会。
而btAlignedAllocator则完全不存在这样的问题:
第一,它的allocate/deallocate行为通过全局的函数指针代理实现,不可能存在同时有两个以上的类型底层管理内存的方法。
第二,使用btAlignedAllocator的数据结构,其模板参数相对简单,编码、调试的复杂性自然也降低了。
本人拙见,STL有点过度设计了,虽然Policy Based的设计能够带来灵活性,但代码的可读性下降了很多(或许开发glibc++的那群人没打算让别人看他们的代码☺)。
扩展阅读
文中提到了两本书:
《Modern C++ Design》(中译本名为《C++设计新思维》,侯捷先生译),该书细致描述了Policy Based Design。
《STL源码剖析》(侯捷先生著),该书详细剖析了SGI hashtable的实现。
本文所讨论的源码版本:
bullet 2.81
gcc 4.6.1(MinGW)
欢迎评论或email(xusiwei1236@163.com)交流观点,转载注明出处,勿做商用。
















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











