






一 背景说明
Flink版本1.15.3,Hudi版本0.12.2,进行flink数据入湖,spark和hive都可进行数据读写,实现hudi元数据同步及数据共享.
大数据平台为CDP7.5.1

二 环境配置
1 配置Flink环境变量
#Flink Home
export FLINK_HOME=/opt/apache/flink/flink-1.15.3
export PATH=$PATH:$FLINK_HOME/bin2 Jar包拷贝,拷贝完之后重启对应的服务,确保jar包加载
2.1HudiJar包放到hive目录,
hudi-hadoop-mr-bundle-0.12.2.jar
hudi-hive-sync-bundle-0.12.2.jar
2.2 Hive Jar包放到flink目录,flink同步元数据到Hive
cp ./hive-exec-3.1.3000.7.1.7.0-551.jar /opt/apache/flink/flink-1.15.3/lib/
cp ./libfb303-0.9.3.jar /opt/apache/flink/flink-1.15.3/lib/
3 Flink Jar包下载
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.15.3/flink-connector-hive_2.12-1.15.3.jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.15.3/flink-sql-connector-hive-3.1.2_2.12-1.15.3.jar4 其他jar包
环境不同,需要的Jar包不同,具体任务拉起后。提交任务,看flink jobmanager日志,根据具体报错去hive或hadoop安装目录下把具体安装包拷贝到flin lib目录下即可。
类型错误的问题,一般情况下都能通过上述方法搞定。
三 Flink建表,数据同步
3.1 MERGE_ON_READ 类型表
#创建catalog,断开连接后需要重新创建
CREATE CATALOG hive_catalog WITH (
'type' = 'hudi',
'default-database' = 'default',
'catalog.path' = 'hdfs:///hudi/test',
'hive.conf.dir' = '/opt/cloudera/parcels/CDH/lib/hive/conf'
);
use catalog hive_catalog;
#选择具体database
use hudi;
#创建表,表类型为MERGE_ON_READ
CREATE TABLE test_hudi_flink5 (
id int PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
price int,
ts int,
dt VARCHAR(10)
)
PARTITIONED BY (dt)
WITH (
'connector' = 'hudi',
'path' = 'hdfs:///hudi/test/hudi/test_hudi_flink5',
'table.type' = 'MERGE_ON_READ',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://node20:9083',
'hive_sync.conf.dir'='/opt/cloudera/parcels/CDH/lib/hive/conf',
'hive_sync.db' = 'hudi',
'hive_sync.table' = 'test_hudi_flink5',
'hive_sync.partition_fields' = 'dt',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor'
);
#插入数据
insert into test_hudi_flink5 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'),(3,'hudi',10,100,'2022-10-31'),(4,'hudi',10,100,'2022-10-31'),(5,'hudi',10,100,'2022-10-31'),(6,'hudi',10,100,'2022-10-31');
#查询数据
select * from _hudi_flink5;
在hive中查看,这里存在一个问题,hive中查询不到具体数据,后续再研究

3.2 COPY_ON_WRITE类型表
#创建表,表类型为MERGE_ON_READ
CREATE TABLE test_hudi_flink7 (
id int PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
price int,
ts int,
dt VARCHAR(10)
)
PARTITIONED BY (dt)
WITH (
'connector' = 'hudi',
'path' = 'hdfs:///hudi/test/hudi/test_hudi_flink7',
'table.type' = 'COPY_ON_WRITE',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://node20:9083',
'hive_sync.conf.dir'='/opt/cloudera/parcels/CDH/lib/hive/conf',
'hive_sync.db' = 'hudi',
'hive_sync.table' = 'test_hudi_flink7',
'hive_sync.partition_fields' = 'dt',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor'
);
#插入数据
insert into test_hudi_flink7 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'),(3,'hudi',10,100,'2022-10-31'),(4,'hudi',10,100,'2022-10-31'),(5,'hudi',10,100,'2022-10-31'),(6,'hudi',10,100,'2022-10-31');
#查询数据
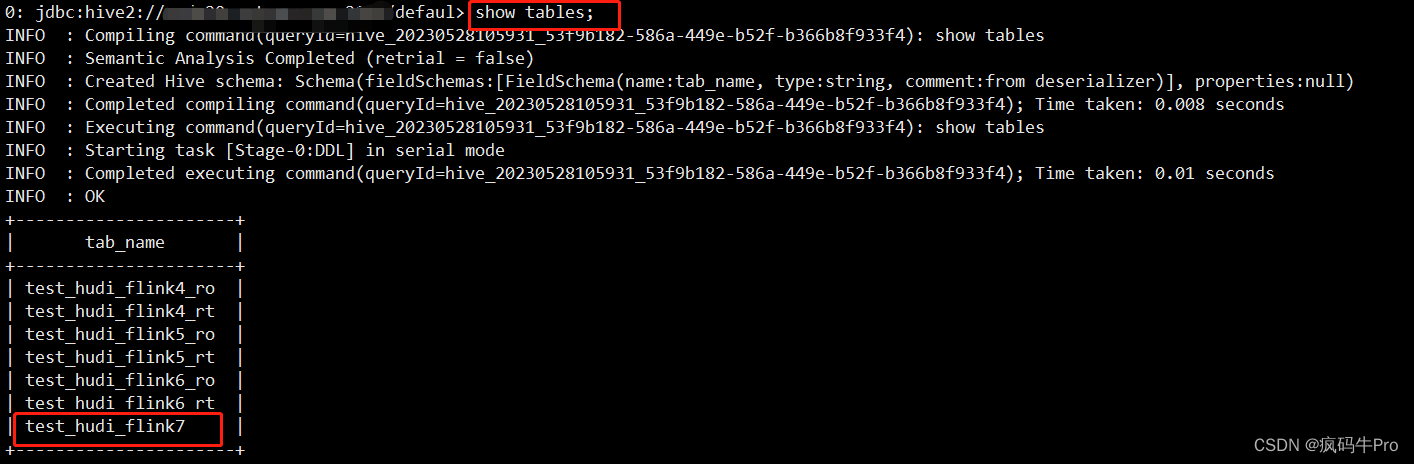
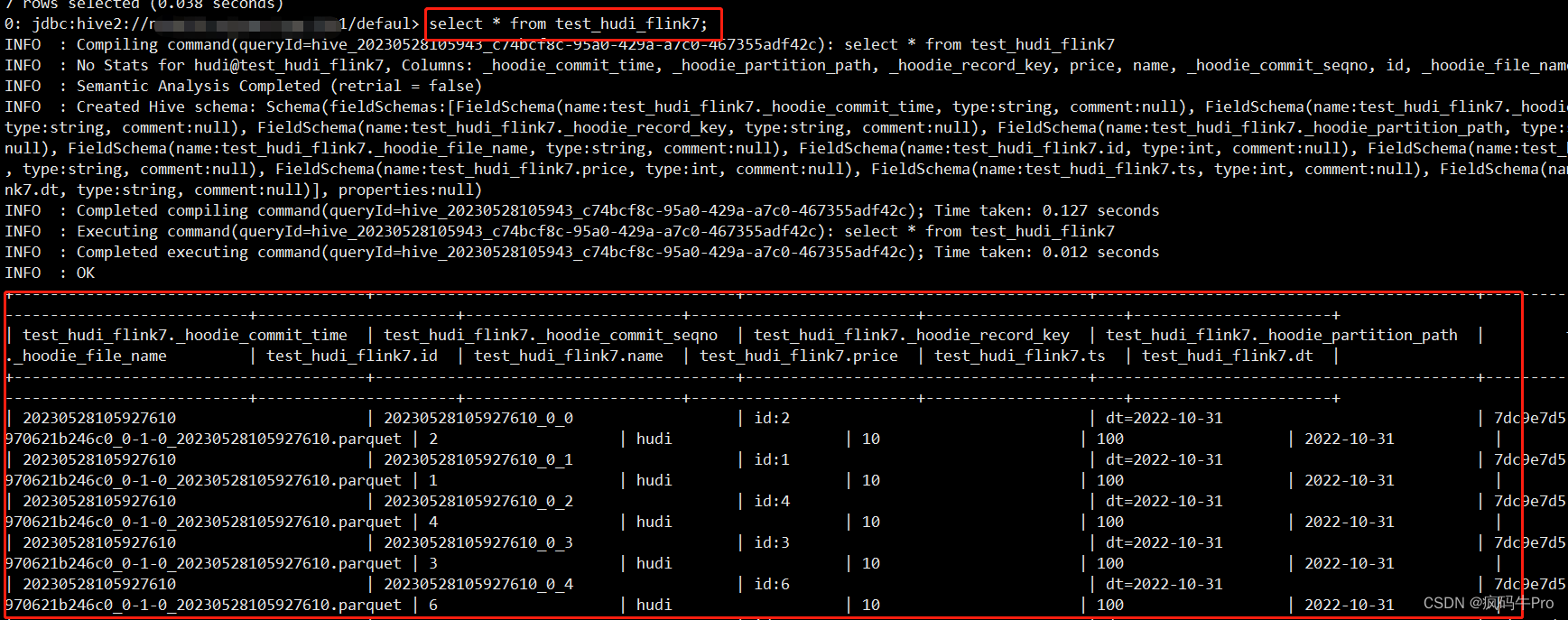
select * from test_hudi_flink7;HIve中查看,生成一张表,且能查到数据
四 Spark建表,数据同步
4.1 Flink SQL 写入Spark创建的Hudi分区表
#----------------------------------------------------------------------Flink SQL 写入Hudi分区表-------------------------------------------------
#Flink中向由Spark创建的Hudi表写入数据
create database hudiods;
create table hudiods.flow_business_mor (
id STRING PRIMARY KEY NOT ENFORCED,
cost DOUBLE COMMENT '费用',
DATA_DT STRING
)
PARTITIONED BY (DATA_DT)
WITH (
'connector' = 'hudi',
'path' = 'hdfs:warehouse/tablespace/external/hive/hudiods.db/flow_business_mor',
'ROW FORMAT SERDE'='org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe',
'STORED AS INPUTFORMAT'='org.apache.hudi.hadoop.HoodieParquetInputFormat',
'OUTPUTFORMAT'='org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat',
'LOCATION'='hdfs:///warehouse/tablespace/external/hive/hudiods.db/flow_business_mor',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://node20:9083',
'hive_sync.conf.dir'='/opt/cloudera/parcels/CDH/lib/hive/conf',
'hive_sync.db' = 'hudi',
'hive_sync.table' = 'flow_business_mor',
'hive_sync.partition_fields' = 'DATA_DT',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor'
);
insert into hudiods.flow_business_mor values ('hudi',10100.01,'2022-10-31'),('spark',10100.02,'2023-05-26'),('flink',10100.06,'2023-05-27'),('hive',10100.00,'2023-05-28');
#Hive中查看数据
alter table flow_business_mor add if not exists partition(`DATA_DT`='2023-05-28') location 'hdfs:///warehouse/tablespace/external/hive/hudiods.db/flow_business_cow/2023-05-28';
select * from flow_business_mor where `data_dt`='2023-05-28';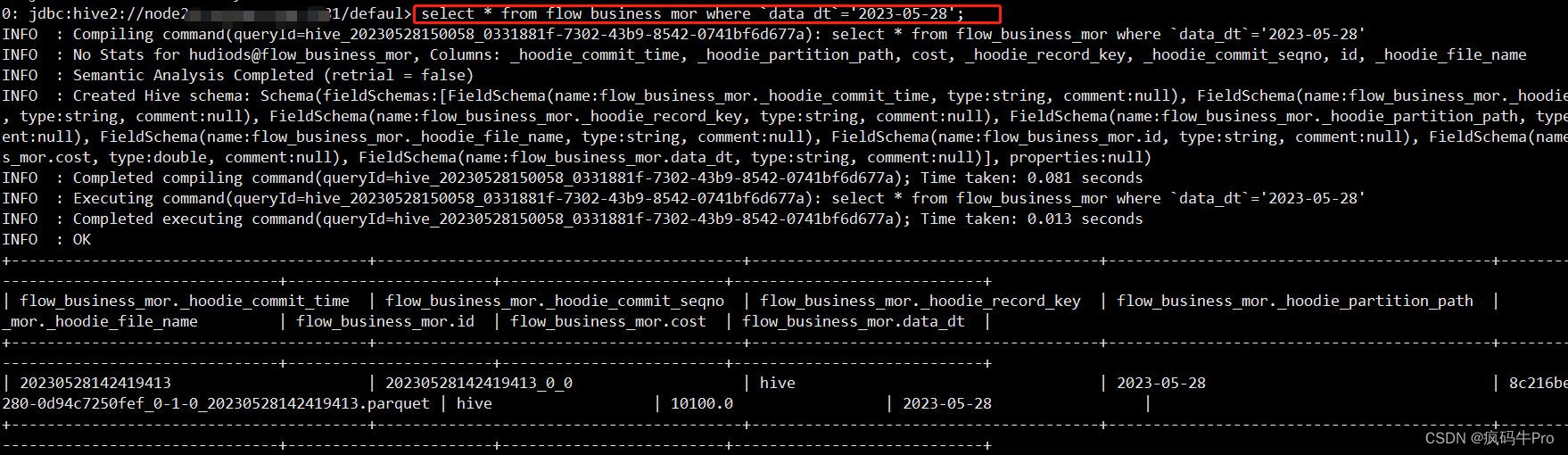
4.2 Flink SQL 写入Spark创建的Hudi分区表
create table hudiods.flow_business_cow (
id STRING PRIMARY KEY NOT ENFORCED,
cost DOUBLE COMMENT '费用',
DATA_DT STRING
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs:warehouse/tablespace/external/hive/hudiods.db/flow_business_cow',
'ROW FORMAT SERDE'='org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe',
'STORED AS INPUTFORMAT'='org.apache.hudi.hadoop.HoodieParquetInputFormat',
'OUTPUTFORMAT'='org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat',
'LOCATION'='hdfs:///warehouse/tablespace/external/hive/hudiods.db/flow_business_cow',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://node20:9083',
'hive_sync.conf.dir'='/opt/cloudera/parcels/CDH/lib/hive/conf',
'hive_sync.db' = 'hudi',
'hive_sync.table' = 'flow_business_cow',
'hive_sync.partition_fields' = 'DATA_DT',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor'
);
insert into hudiods.flow_business_cow values ('hudi',10100.01,'2022-10-31'),('spark',10100.02,'2023-05-26'),('flink',10100.06,'2023-05-27'),('hive',10100.00,'2023-05-28');
#Hive中查看数据
select * from flow_business_cow;
5 结论
1)由flink创建的Hudi表,需要同步元数据到hive,后续Hive SQL,Spark SQL都可以进行查询
2)由Spark SQL创建的Hudi表,Flink SQL也可以操作,但在操作之前需要进行数据库和表的创建
3)不管是什么方式创建的Hudi表,想要用其他引擎进行操作,需要将元数据同步到Hive,同时,其他引擎在操作的时候,需要对catalog、database及table进行映射,这是很关键的点,区别于其他数据库系统














 2281
2281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









