







上一篇介绍了Pandas和Numpy这两个包,个人认为比较常用且方便的是Pandas,因此代码第一篇对Pandas的常用函数做一些介绍。
做简单的数据分析用Jupyter Notebook非常方便,利用写这篇文章正好也做一些整理,避免每次都去翻一大堆ipynb文件。
遇到问题优先参考Pandas官方说明文档。
 ←下载Anaconda,打开Jupyter Notebook
←下载Anaconda,打开Jupyter Notebook
0. 配置镜像源
1. 万事第一步——安装并导入包
本篇先讲直接在notebook里用pip安装
notebook运行cells的快捷键↓
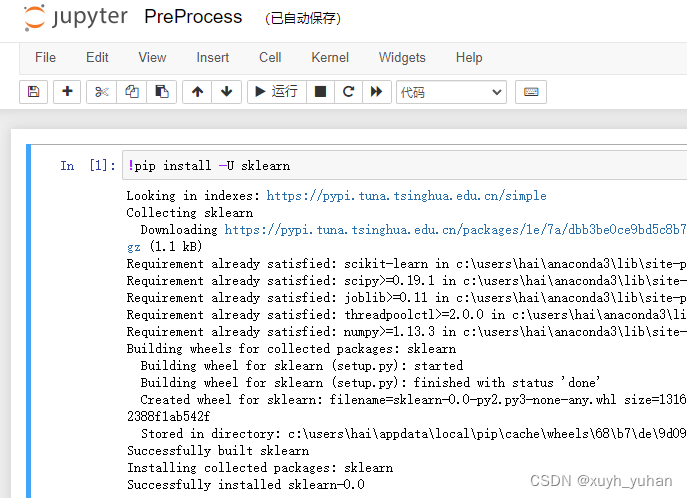
输入以下代码,Shift+Enter运行
!pip install pandas
!pip install numpy看到Successfully install 即安装完成
然后就可以导入了,无报错即安装成功
import pandas as pd
import numpy as np2. 第二步——读写数据及查看信息
因为导入导出的数据一般都来自于gis,所以空间分析数据一般用.csv格式
【重要】导出csv之后请另存一个excel格式做分析,N次做完直接保存然后丢失所有格式、图片、数据透视表
# 读取数据命名根据自己的分析内容,这里以简单的df代替分析的dataframe
df = pd.read_csv('D://005//03-Data//visitation_data_ca.csv')
df = pd.read_csv('D://005//03-Data//visitation_data_ca.csv', encoding='gbk') #如有中文使用gbk编码
# 将df显示完整
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('max_colwidth',100)
# 打印数据信息
print(df) #打印所有数据,最下面一行会有row和column的数量
print(df.shape) #打印数据的形状
print(df.head(5)) #打印数据前五行
# 把处理好的数据写为csv
df.to_csv('D://005//03-Data//visitation_data_ca_process.csv', index=False) #index=False表示不写出索引行3. 数据清洗
数据清洗是非常重要且关键的一步,大部分空间分析所用数据都存在缺失等问题。
3.1 首先查看数据信息
df.info()3.2 查找并处理空缺数据
# 是否空值判断
df.isnull()
df.isna()
# 每列是否含有空值判断
df.isnull().any()
# 对于空间分析来说,一般会把空值行去掉
df.dropna()
# 再打印df的行列数看看
df.shape
# 但比如手机信令数据,需要全覆盖的基站数据,就要考虑填充空值
# 用相邻的值填充空值,比如
df.fillna(method="bfill",inplace=True)4. 筛选数据
# 构建dataframe
df = pd.DataFrame(np.arange(16).reshape(4,4),columns=["sh","bj","sz","gz"],index=["one","two","three","four"])4.1 基于数值比较筛选
方法一:直接简单筛选
df[df["sh"]>5] # 筛选大于5
df[df["sh"]==5] # 筛选等于5方法二:利用匿名函数筛选
df[df["sh"].map(lambda x:x>5)]
df[df["sh"].map(lambda x:x==5)]方法三:利用isin()函数多值筛选
df[df["sh"].isin([5])]4.2 模糊筛选
方法一:str.contains()函数
province = pd.DataFrame(['广东', '广西', '福建', '福建省'], columns=['省份'])
province.loc[province["省份"].str.contains("福")] # 筛选出福建省数据方法二:正则匹配
import re
province = pd.DataFrame(['广东', '广西', '福建', '福建省'], columns=['省份'])
# 自定义函数,如果包含“广”字,则返回True,否则返回False
def func(x):
if re.search(".*广.*",x):
return(True)
else:
return(False)
province[province["省份"].apply(func)]方法三:切片
df = pd.DataFrame({"date":["2020efgdh0228","2021hijik0228","2019hokh0201"],"value":[9999,777,4]})
# 筛选出2019年的数据
df[df["date"].map(lambda x:x[0:4])=="2019"]5. Groupby函数分组
参考
# 创建dataframe
data = {'name': ['apolo', 'apolo', 'apolo', 'adm', 'adm', 'adm', 'bolon', 'bolon', 'bolon',
'ali', 'ali', 'ali', 'cathy', 'cathy', 'cathy', 'jack', 'jack', 'jack'],
'subjects': ['math', 'english', 'chinese', 'math', 'english', 'chinese', 'math', 'english', 'chinese',
'math', 'english', 'chinese', 'math', 'english', 'chinese', 'math', 'english', 'chinese'],
'grades' : [89, 78, 84, 89, 83, 85, 77, 88, 79, 89, 86, 83, 95, 90, 94, 78, 70, 80]
}
df = pd.DataFrame(data)
df
# 求平均值(会输出每个学生的平均成绩)
df.groupby('name').mean()
# 用聚合函数求平均和最小值(输出平均成绩和最低成绩)
df.groupby('name').agg(['mean', 'min'])
# 传入自定义的面向分组的函数
df.groupby('name').apply(lambda x:x[x['subjects'] == 'math']['grades'].mean() - x[x['subjects'] == 'english']['grades'].mean())
6. dataframe, array, list格式互换
# array转dataframe
df = pd.DataFrame(array)
# dataframe转array
array1 = np.array(df)
# list转dataframe
df = pd.DataFrame(mylist1, columns=['name1', 'name2', 'name3'])
# dataframe转list
mylist2 = df['name1'].to_list()














 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









