 关注
关注
 分享
分享
文章平均质量分 75
在企业级应用中,flume是个经常使用的管道工具,本专栏旨在解决在flume遭遇文件性能瓶颈时的优化思路与具体配置,帮助企业解决类似问题。
ESOO
君子不器
展开
-
flume高并发优化——(16)解决offsets变小问题
offsets初始化在上篇博客中《flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题 》我们遗留了一个小问题,就是offsets变小的问题,迟迟未解决,经过研究flume代码发现,flume中,是自己管理offsets关系的,每个kafkachannel的代码中保留了一份topic-offsets的关系,源码:@Override public void start原创 2017-07-31 10:24:51 · 2569 阅读 · 5 评论 -
flume高并发优化——(15)中间件版本升级
在系统平稳运行一年的基础上,为提供更好的服务,现针对java,kafka,flume,zk,统一进行版本升级,请各位小伙伴跟着走起来,不要掉队啊! 名称 老版本号 新版本号 jdk 1.7.0_25 1.8.0 kafka 2.10-0.8.0.1 2.10-0.10.2.1 flume 1.6.0 1.7.0 zookeeper 3.4.6原创 2017-07-21 16:10:53 · 3463 阅读 · 2 评论 -
flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题
日志平台运行一段时间,发现日志有部分丢失,通过检查日志,发现有两个问题导致数据丢失,一个是遇到空行后,日志停止收集,还有就是kafka监控offsets时变小,通过分析代码,找到如下方法:空行问题: 在系统稳定运行一段时间之后,发现了一个致命性的bug就是在遇到空行时,无法自动跳过,导致识别为文件结束,再次读取还是空行,跳入了死循环解决办法: 解决的办法也非常简单,就是增加对文件大小与当前行数的原创 2017-07-21 15:42:48 · 2607 阅读 · 2 评论 -
flume高并发优化——(13)扩展三级文件配置&利用Headers扩展属性
上篇博客中,我们对flume进行了文件组进行了扩展,但是我们现在的配置还是针对某组文件单独配置,这样的维护成本还是太高,为了持续优化,我们对常见的三级文件进行优化(**logs/**project/**type/*.log)利用公司内部的约定,大家一起为简单配置努力。1,规范目录结构 在本项目约定下,日志结构采取如下:/logs/*project/type-tomcat/*.log2原创 2016-10-12 09:10:09 · 3658 阅读 · 8 评论 -
flume高并发优化——(12)filesource 支撑文件组&兼容cat监控
主因 在上篇博客中,我们已经做到了非常不错的多文件检索,但是,还有一个问题,就是针对不同的项目,需要多个配置文件,这样,对运维,是个非常繁琐的问题,针对这个问题,本版对flume扩展了文件组(以|切分父文件)。 cat监控,是个久经考验的监控报警平台,因此决定兼容cat的协议,对source进一步扩展。 针对很多人说方法过大的问题,本次也做了调整,优化了面原创 2016-09-29 21:04:43 · 2189 阅读 · 6 评论 -
flume高并发优化——(11)排除json转换及中文乱码
在使用flume收集数据,转换为json格式时,常常遇到特殊符号的问题,而json对于”引号,是非常敏感的,大家处理json数据的时候,要特别注意,在前不久,向es插入数据时,报错就是json转换失败原因: json通用格式: {"key":"value"} {"key":{}} {"key":[]} ["one","two"]原创 2016-08-19 18:31:04 · 5429 阅读 · 3 评论 -
flume高并发优化——(10)消灭elasticsearch sink多次插入
在flume作为通道接收json数据时,最近遇到一个问题,当flume-es-sink遭遇一个错误的时候,会不断尝试插入数据,而以前的数据又没有进行回滚,导致数据重复插入,脏数据累积,为了解决这个问题,现解决如下:原因如下: 1,事务控制在channel端 2,事务回滚,未处理已插入es中数据解决方案: 1,es批量操作不做回滚 2,es插入原创 2016-08-19 18:14:42 · 5470 阅读 · 9 评论 -
flume高并发优化——(9)配置文件交由zookeeper管理
我们都希望,配置文件是从一个服务引出,然后客户端监听服务端变化,实时重启自身加载最新配置,这样,我们就不用维护每个独立的客户端配置,更新也变得非常简单,而flume,显然意识到了这一个巨大的实惠,他是支持配置文件交由zookeeper维护的,这样我们在修改配置时,flume会自动重新加载。1,zookeeper 添加节点 我们利用博客《使用zkweb维护zookeeper数据》中介绍原创 2016-07-22 14:49:09 · 9135 阅读 · 3 评论 -
flume高并发优化——(8)多文件source扩展断点续传
在很多情况下,我们为了不丢失数据,一般都会为数据收集端扩展断点续传,而随着公司日志系统的完善,我们在原有的基础上开发了断点续传的功能,以下是思路,大家共同讨论:核心流程图: 源码:/* * 作者:许恕 * 时间:2016年5月3日 * 功能:实现tail 某目录下的所有符合正则条件的文件 * Email:xvshu1@163.com * T原创 2016-06-22 18:21:43 · 9556 阅读 · 4 评论 -
flume高并发优化——(7)RandomAccessFile升级多文件source
本篇文章旨在解决tail文件io断裂问题,我们使用linux原生的tail ,启动多个线程,做到对多个文件的数据收集,但是,随着业务日志增多,日志以日期分割,是个常用的做法,但是这样,就使得我们的flume插件在日期交换的凌晨,出现io断裂,造成不能继续收集数据原创 2016-05-11 11:54:02 · 5460 阅读 · 2 评论 -
flume高并发优化——(6)开发多文件检索source插件
To detect all files in a folderstep: 1,config one path 2,find all file with RegExp 3,tail one children file 4,batch to channal demo: demo.sources.s1.type = org.apache.flume.source.ExecTailSource demo.sources.s1.filepath=/export/原创 2016-05-03 18:20:01 · 8795 阅读 · 3 评论 -
flume高并发优化——(5)KafkaOffsetMonitor
本片博客是介绍一款kafka监控的软件,以配合查看flume的kafka channel性能,其实这是个非常简单的项目,我们只需要下载好jar包,就可以使用了1,下载jar包http://pan.baidu.com/s/1eSPlzpw2,启动java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \ com.quantifind.kafka.offseta原创 2016-04-25 18:05:14 · 3417 阅读 · 3 评论 -
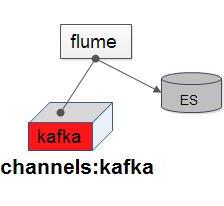
flume高并发优化——(4)kafka channel
在上篇博客中,我们还留了一个小疑问,就是我们对最后一个flume的优化是如何做的,关于这一点,我们的思路是这样的,file的瓶颈是io,而我们使用的硬盘是5400转1t硬盘,如果想要优化,我们必须找到性能和memory相当,但是又能较好的保存数据,保证事务性的channel,符合这样要求的一款channel进入了我们的视线,就是kafkachannel,具体怎么做的,请大家看详细介绍:优化之前的架原创 2016-04-25 17:40:04 · 13535 阅读 · 6 评论 -
flume高并发优化——(3)haproxy
在上篇博客中,我们虽然进行了较大的改动,但是,没有料到的是,flume的file性能瓶颈会如此快的到来,由于我们使用了一个filechannel作为负载均衡的通道,导致性能瓶颈很快到来,为了应对这样的瓶颈,我们对结构进行了第三次升级,替换了负载均衡的前端,换为性能更好的haproxy作为分发端,大家一起来看看是如何优化的。 还是老样子,大家看看上次优化过之后的结构: 我原创 2016-04-25 17:09:14 · 6858 阅读 · 6 评论 -
flume高并发优化——(2)精简结构
大家在上篇博客中,可以看到,对flume本身的优化,我们可以说是一个较大的进步,但是,后期梳理时,发现,数据的处理经过了很多没有必要的步骤,我们的处理有些多余,但是精简哪里,又成为了一个问题,本篇博客带领大家一起看看,精简的关键位置及效果。还是老样子,大家会议上篇博客的架构: 不难看出,有一个性能点就是从主端口下发的时候,三个端口到es的过程中,为了让数据有较好的缓冲,我们使用了ka原创 2016-04-25 16:51:27 · 8184 阅读 · 9 评论 -
flume高并发优化——(1)load_balance
通过一年多时间的使用,统一日志系统,已经接入公司前台,在20个节点,几十万用户,数百亿交易额的大压力下,仅仅使用了一个普通的服务器,承受住了严峻的考验,在公司今年更宏大的目标,也是为了给大数据组提供更加全面信息的需求下,公司所有项目,要接入ULOG系统,主要包含管理后台,wap,app等,流量一下达到一个峰值,flume的瓶颈凸显出来,在解决的过程中,对flume的了解以及性能调优,有了更深入的认原创 2016-04-25 16:33:22 · 13833 阅读 · 9 评论