目录
一.JAVA基础
1.八个基本数据类型,长,占几个字节,取值范围是多少。
基本类型:
2.面向对象的特征
1. 封装(Encapsulation)
3.实现多态的几种方式
4.什么叫装箱什么叫拆箱
5.装拆箱分别调用的是那个方法
6.Integer a=100; Integer b=100; a == b (true)Integer a=200; Integer b=200; a == b(false)为什么?
7.Object有那7个方法
8.常量(final)关键字的作用 他与finally,finalize的区别
9.*Voliate,(单例模式)
10.Static的作用
1. static关键字概述
2. static变量 | 类共享属性
3. static方法 | 两种访问方式
4. static代码块 | 静态属性初始化
5. static内部类 | 类的整体性质
11.*String buffer和String 以及String builder的区别
12.==和equals的区别
13.Java当中的四种引用类型(后续补充)
二.集合
1.*Java当中有那些集合类
2.**HashMap的底层原理(存储结构,put的过程,0.75,8,6,16)
HashMap精选面试题(2021版) - 知乎 (zhihu.com)3.*ArryList和LinkdcList的区别
4.HashMap的HashTable的区别
5.*如何使用线程安全的Map
6.ConcurrentHashMap的原理
三.线程
1.*创建线程有几种方式
2.线程的生命周期
3.***线程池的原理以及7个参数是什么(有什么作用),4个拒绝策略是什么
4.线程安全,线程通信
5.*Reentrantlock和synchromied lock的区别
6.synchromied lock 修饰实例方法 静态方法 代码块 分别的含义
7.Sleep和wait的区别
8.什么是反射机制
9.*Cglib的动态代理和jdk的动态代理的区别
10.JVM内存模型(每一步分别放什么内容)
11.垃圾回收算法
12.Java当中的四种引用类型
13.(如何控制线程的执行顺序)
14.*接口和抽象类的区别
15.JDK1.8的新特性
16.什么是双亲委派
17.为什么需要双亲委派
四.Redis
1.Redis为什么快?(单线程,内存)
2.*Redis常用的数据类型(5个)
3.*Redis的持久化策略
4.数据淘汰策略
5.*Redis中的大K问题
五.Mysql
1.sql语句的执行顺序
2.***Mysql索引失效的场景
3.**Sql语句如何优化
4.***Mysql数据库的优化(数据库里加索引一定有效吗?一定效率快吗?)
5.Mysql中索引有哪些类型
6.*B+树索引和Hash索引的区别
7.Mysql为什么使用B+树索引而不使用B-树索引
8.*列举一些Mysql当中常用的聚合函数
9.列举Mysql开窗函数
10.行转列,列转行
11.****Mysql事务的隔离级别
12.*事务的四个特性
13.****Mysql是如何使用MVC解决,脏读,幻读,不可重复读现象的
14.*Mysql的七大日志
15.Union和UnionAll的区别
16.*Mysql中常用的日期函数和字符串函数
六.Linux
1.列举常用的Linux命令
一.JAVA基础
1.八个基本数据类型,长,占几个字节,取值范围是多少。
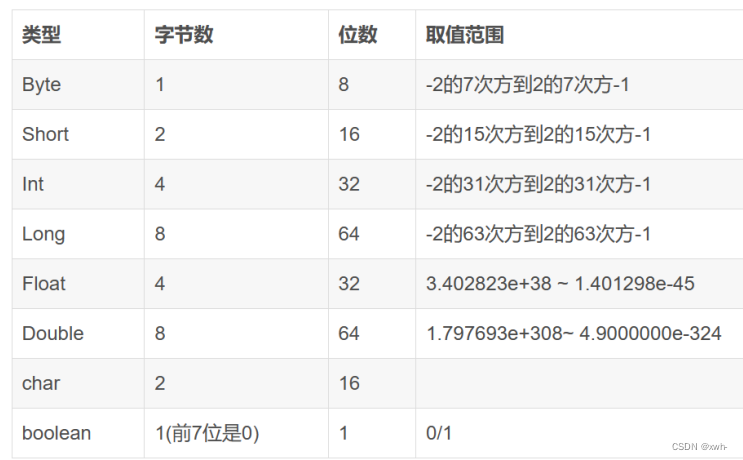
基本类型:
Byte 一般的数据 1个字节 占8位 取值范围 -2的7次幂—2的7次幂减一
short 极大的数据 2个字节 取值范围 -2的15次方到2的15次方减一
int 4个字节 取值范围 -2的31次方到2的31次方减一
long 8个字节 取值范围 -2的63次方到2的63次方减一
byte、short、int、long都是整数类型,并且是有符号整数 分别占用、2、4、8个字节。
浮点数
float 有效数字最长是7位 占四个字节,共32位,称为单精度浮点数
double 有效数字最长是15位 占八个字节,共64位,称为双精度浮点数
Java中的浮点型常量数值默认是double类型
注意: java提供的浮点类型不适合进行精确的运算
boolean
Boolean在内存中占用一个字节。
当java编译器把java源代码编译为字节码时,会用int或byte来表示boolean。在java虚拟机中,用整数零来表示false,用任意一个非零整数表示true。 java虚拟机这种底层处理方式对java虚拟机是透明的,在java源程序中boolean类型的变量取值只能是true或false。
char
char是字符类型 占用两个字节,java语言对字符采用Unicode字符编码
2.面向对象的特征
1. 封装(Encapsulation)
封装是面向对象编程中最基本的特征之一,它将数据和操作数据的方法(即方法)封装在一个单独的单元(即类)中。通过封装,我们可以隐藏对象的内部细节,只暴露出必要的接口供其他对象进行交互,从而实现了信息的隐藏和保护。
2. 继承(Inheritance)
继承是面向对象编程中的另一个重要特征,它允许一个类继承另一个类的属性和方法,从而实现代码的重用和扩展性。被继承的类称为父类(或超类),继承这个类的类称为子类。子类可以继承父类的所有非私有属性和方法,并可以在其基础上添加新的属性和方法。
3. 多态(Polymorphism)
多态是面向对象编程的第三个特征,它允许一个对象在不同的情况下表现出不同的行为。多态分为编译时多态和运行时多态。编译时多态是通过方法重载来实现的,而运行时多态是通过方法重写和向上转型来实现的。
3.实现多态的几种方式
1. 方法重载
方法重载是一种实现多态的简单方式。它允许在同一个类中定义多个同名但参数列表不同的方法。当调用这些方法时,编译器会根据参数的类型和数量来确定具体调用哪个方法。这样就实现了多态性。
2. 方法重写
方法覆盖是一种实现多态的常用方式。它允许子类重新定义父类中已经定义的方法。当子类对象调用这个方法时,将会执行子类中的方法实现,而不是父类中的方法。
3. 接口实现
接口是一种定义了一组方法的抽象类型。类可以通过实现接口来达到多态的目的。当一个类实现了一个接口时,它必须实现该接口中定义的所有方法。
方法重载允许根据不同的参数类型来实现多态;方法覆盖允许子类重新定义父类中的方法以实现多态;接口实现允许类根据实现的接口来实现多态
4.什么叫装箱什么叫拆箱
装箱就是自动将基本数据类型转换为包装器类型;
装箱(Boxing): 装箱是指将基本数据类型转换为对应的包装类对象。
这是通过调用包装类的构造函数或静态工厂方法来完成的。装箱过程将基本数据类型的值封装成一个包装类对象。
拆箱就是自动将包装器类型转换为基本数据类型
拆箱(Unboxing): 拆箱是指将包装类对象转换为基本数据类型。
这是通过调用包装类的 xxxValue() 方法来完成的。拆箱过程将包装类对象中的值提取出来,转换为对应的基本数据类型。
5.装拆箱分别调用的是那个方法
装箱:这是通过调用包装类的构造函数或静态工厂方法来完成的。
装箱过程将基本数据类型的值封装成一个包 装类对象。
拆箱:这是通过调用包装类的 GetValue() 方法来完成的。
拆箱过程将包装类对象中的值提取出来,转换为对应 的基本数据类型。
6.Integer a=100; Integer b=100; a == b (true)
Integer a=200; Integer b=200; a == b(false)
为什么?
integer :integer是int的包装类,首先它是一个类用==比较的是内存的地址,在integer类里面有一个成员静态 内部类IntegerCache,这成员静态内部类缓存了-128到127之间的所有的整数对象,并在jdk1.5之后引用了自 动 装箱,在将整数类型装箱时进行了判断,如果这个之大于-128到127之间就会重新new一个新的integer, 所 以尽 管两个数值相同,但地址不同,所以返回false。
7.Object有那7个方法
- getClass():获取类的class对象。返回对象的运行时类。返回的是 Class 对象,可以获取类的信息,如类名、父类、接口等。
- hashCode:返回对象的哈希码值。哈希码是根据对象的内容计算得出的一个整数,用于快速查找和比较对 象。在重写 equals 方法时,通常也要同时重写 hashCode 方法,以保证相等的对象具有相同的哈希码
- equals():比较对象是否相等,比较的是值和地址,子类可重写以自定义。默认情况下,使用 == 运算符进行比较,即判断两个对象的 引用是否指向同一个内存地址。如果需要自定义比较规则,可以重写该方法。
- clone():克隆方法。创建并返回当前对象的副本。默认情况下,使用浅拷贝方式复制对象,即只复制对象的字段值,而不 复制引用类型的对象。如果需要实现深拷贝,可以重写该方法
- toString():将对象转换为字符串表示形式。 如果没有重写,应用对象将打印的是地址值。
- notify():随机选择一个在该对象上调用wait方法的线程,解除其阻塞状态。该方法只能在同步方法或同步块内部调用。如果当前线程不是锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
- notifyall():解除所有那些在该对象上调用wait方法的线程的阻塞状态。该方法只能在同步方法或同步块内部调用。如果当前线程不是锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
- wait():导致线程进入等待状态,并释放对象锁。直到它被其他线程通过notify()或者notifyAll唤醒。该方法只能在同步方法中调用。如果当前线程不是锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
- finalize(饭no来吱):在对象被垃圾回收器回收之前调用。可以重写该方法来执行资源释放等清理操作。
8.常量(final)关键字的作用 他与finally,finalize的区别
final:
- 定义:在Java等编程语言中,final是一个关键字,用于表示某个变量、方法或类是不可变的。
- 用途:使用final关键字可以使变量成为常量,一旦赋值后不能修改;方法不能被子类重写;类不能被继承。
finally:
finally是在异常处理时提供finally块来执行任何清除操作。不管有没有异常被抛出、捕获,finally块都会被执行。
- 定义:在异常处理中,finally块是用来指定无论是否发生异常都要执行的代码块。
- 用途:无论try块中的代码是否抛出异常,finally块中的代码都会执行,例如关闭文件、释放资源等。
finalize:
- 定义:在Java等面向对象的编程语言中,finalize()方法是Object类的一个方法,当垃圾收集器决定回收对象时,会先调用该对象的finalize()方法。
- 用途:在这个方法中,你可以定义一些清理资源或执行必要操作的代码,以防止资源泄漏和其他问题。finalize()方法通常在对象的生命周期结束时被调用。
9.*Voliate,(单例模式)
单例模式:
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
特点
1、单例类只能有一个实例。
2、单例类必须自己创建自己的唯一实例。
3、单例类必须给所有其他对象提供这一实例。
优点:
系统内存中该类只存在一个对象,节省了系统资源,对于一些需要频繁创建销毁的对象,使用单例模式可以提高系统性能。
缺点:
没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
Voliate:
volatile主要有两层语义:
- 内存可见性。
- 禁止指令重排序。
在实现单例模式时,通常会将构造函数私有化,并提供一个静态的getnstance()方法来获取单例对象。由于单例对象只会被创建一次,因此需要保证其线程安全性,避免多个线程同时访问导致的并
发问题。
在Java 1.5之前,通常使用双重检査锁定(double-checked locking)来实现单例模式的线程安全性,这种实现方式会在getlnstance()方法中使用synchronized关键字来保证线程安全,但synchronized关键字会影响性能。为了避免synchronized关键字的影响,可以使用volatile关键字来保证单例对象的可见性和原子性,从而保证线程安全性。
具体来说,当一个变量被声明为volatie时,它的值的修改会立即被其他线程可见,避免了多线程访问时出现的问题。在使用双重检查锁定实现单例模式时,使用volatile关键字可以保证在初始化单例对象时,多个线程能够正确地访问和修改变量。如果不使用volatile关键字,则可能出现多个线程同时访问变量导致的并发问题。
需要注意的是,使用volatile关键字不能完全避免线程安全问题,它只能保证可见性和原子性,不能保证有序性和互斥性。在实现单例模式时,需要考虑到多种因素,包括性能、可靠性和安全性等,选择最合适的实现方式。
10.Static的作用
static关键字用于修饰类的成员,表示静态的、与类相关的属性。它可以修饰变量、方法、代码块和内部类。作用在于为类的所有对象共享相同的属性或方法,而不是每个对象都拥有一份独立的拷贝。
1. static关键字概述
static关键字表示静态的、与类相关的成员。它可以修饰变量、方法、代码块和内部类,每一种应用都有着独特的特性。
2. static变量 | 类共享属性
被static修饰的变量是属于整个类的,而不是属于类的某个对象。这意味着由该类创建的所有对象共享同一个static属性。在内存中,static变量只有一份拷贝,这有助于节省内存空间。
3. static方法 | 两种访问方式
static方法可以通过对象名.方法名和类名.方法名两种方式来访问。这使得static方法可以直接通过类名调用,而不需要先创建类的对象。这在某些工具类或者辅助方法中很常见。
4. static代码块 | 静态属性初始化
static代码块在类第一次加载时执行,且只被执行一次。主要作用是实现static属性的初始化。这在一些需要在类加载时进行一次性初始化操作的场景中非常有用。
5. static内部类 | 类的整体性质
被static修饰的内部类属于整个外部类,而不属于外部类的每个对象。它只能访问外部类的静态变量和方法,这为某些特殊的设计提供了更灵活的选择。
11.*String buffer和String 以及String builder的区别
相同点: 他们的底层都是由char数组实现的。
不同点:
String对象一旦创建,是不能修改的,如果要修改,会重新开辟空间来存储修改后的对象;而String Buffer和String Builder创建的对象是可以修改的。
String Buffer是线程安全的,他几乎所有方法都被synchronization 所修饰,允许采用多线程的方式执行添加或删除字符的操作,但是效率比较低;而String Builder是单线程的。如果所有字符串在一个单线程中编辑(通常都是这样),则应该使用String Builder。这两个类的API大部分是相同的。
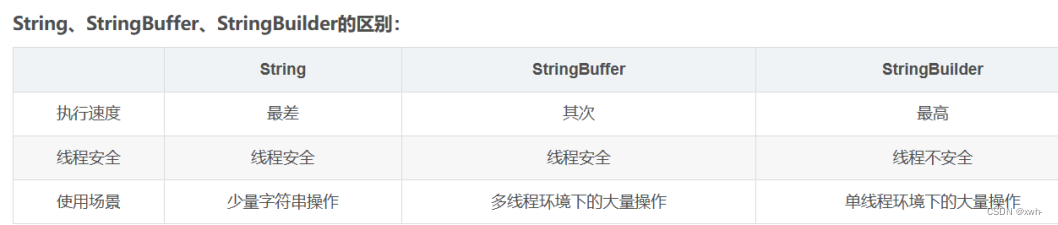
- String 是不可变的字符串类,每次对其进行修改都会创建一个新的对象。
- StringBuffer 和 StringBuilder 是可变的字符串类,可以高效地进行字符串操作。
- StringBuffer 是线程安全的,适合多线程环境下使用;StringBuilder 不是线程安全的,适合单线程环境下使用。
12.==和equals的区别
1. == 既可以比较基本类型也可以比较引用类型,对于基本类型就是比较值,对于引用类型及时比较内存的地址
2.equals的话,他是属于java.lang.Object类里面的方法,如果该方法没有被重写过默认也是== ,我们可以看到String等类的equals方法是被重写过的,而且String类在日常开发中用的比较多,久而久之,形成了equasl是比较值的错误观点.
3.具体要看自定义类里面有没有重写Object的equals方法来判断
4.通常情况下,重写equals方法,会比较类中的属性是否相等
13.Java当中的四种引用类型(后续补充)
强引用(Strong Reference)
1.强引用是指创建一个对象并把这个对象赋值给一个引用变量
Java中默认声明的就是强引用,只要强引用存在,垃圾收集器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了
软引用(Soft Reference)
1.当一个对象只有软引用,当内存空间足够的时候,它不会被回收,只有当内存不足的时候,软引用才会被回收。
软引用是用来描述一些非必需但仍有用的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出OutOfMemoryError。这种特性常常被用来实现缓存技术,比如网页缓存,图片缓存等。
在 JDK1.2 之后,用 SoftReference 类来表示软引用。
在内存不足的情况下,软引用才会被回收
弱引用(WeakReference)
1,当一个对象只有弱引用,无论内存空间是否足够,垃圾回收的时候,弱引用都会被回收。
弱引用的引用强度比软引用要更弱一些,无论内存是否足够,只要 JVM 开始进行垃圾回收,那些被弱引用关联的对象都会被回收。在 JDK1.2 之后,用 WeakReference 来表示弱引用。
虚引用(PhantomReference)
1,虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期,如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。
为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
虚引用必须和引用队列关联使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会把这个虚引用加入到与之关联的引用队列中。
虚引用是最弱的一种引用关系,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,它随时可能会被回收。
二.集合
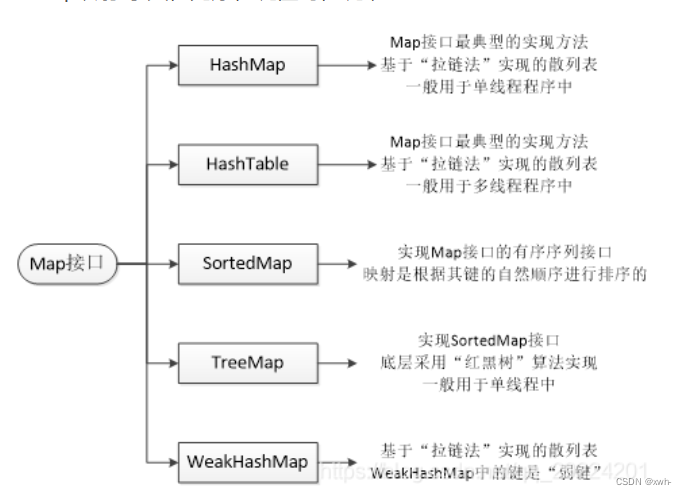
1.*Java当中有那些集合类
一、Java中的集合主要分为四类:
1、List列表:有序的,可重复的;
2、Queue队列:有序,可重复的;
3、Set集合:不可重复;
4、Map映射:无序,键唯一,值不唯一。
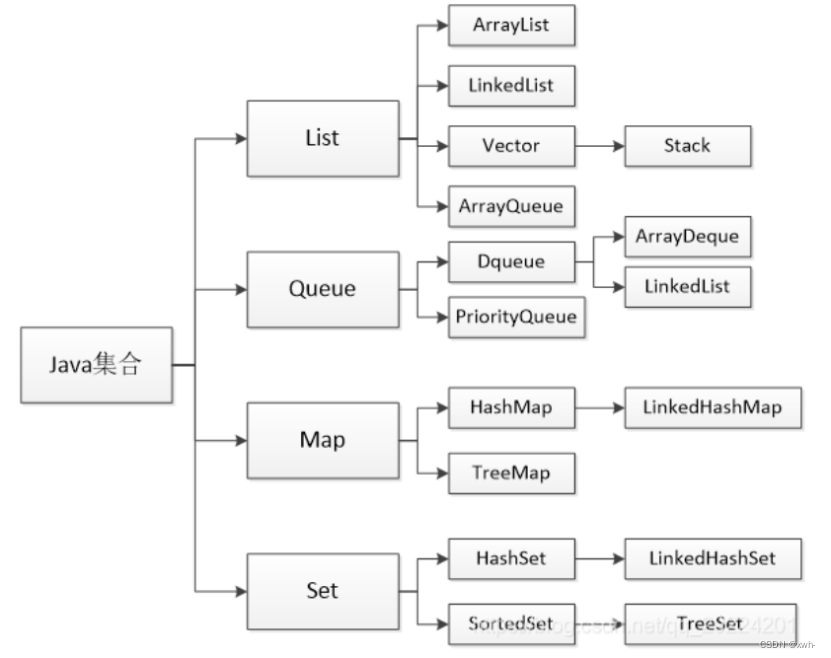
List列表:有序,可重复
1.1 ArrayList数组列表,有序,可重复,内部是通过Array实现。对数据列表进行插入、删除操作时都需要对数组进行拷贝并重排序。因此在知道存储数据量时,尽量初始化初始容量,提升性能。
1.2 LinkedList双向链表,每个元素都有指向前后元素的指针。顺序读取的效率较高,随机读取的效率较低。
1.3 Vector向量,线程安全的列表,与ArrayList一样也是通过数组实现的,不同的是Vector是线程安全的,也即同一时间下只能有一个线程访问Vector,线程安全的同时带来了性能的耗损,所以一般都使用ArrayList。
1.4 Stack栈,后进先出(LIFO),继承自Vector,也是数组,线程安全的栈。但作为栈数据类型,不建议使用Vector中与栈无关的方法,尽量只用Stack中的定义的栈相关方法,这样不会破坏栈数据类型。
1.5 ArrayQueue数组队列,先进先出(FIFO)
2 Queue队列,有序、可重复
2.1 ArrayDeque数组实现的双端队列,可以在队列两端插入和删除元素
2.2 LinkedList也是双向链表
2.3 PriorityQueue优先队列,数组实现的二叉树,完全二叉树实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值)
3 Map映射/字典,无序,键值对,键唯一
3.1 HashMap哈希映射/字典,无序字典,键值对数据,key是唯一的,Key和Value都可以为null
3.2 TreeMap红黑树实现的key->value融合,可排序,红黑树是一种自平衡二叉查找树。
3.3 LinkedHashMap链表映射/字典,继承了hashmap的所有特性,同时又实现了双向链表的特性,保留了元素插入顺序。
4 Set集合,不可重复
4.1 HashSet基于HashMap实现的集合,对HashMap做了一些封装。与HaspMap不同的是元素的保存为链表形式,插入数据时遍历链表查看是否有相同数据,有则返回false,没有则返回true.
4.2 LinkedHashSet链表集合,继承自HashSet与LinkedHashMap相似,是对LinkedHashMap的封装。
4.3 TreeSet红黑树集合,与TreeMap相似,是对TreeMap的封装。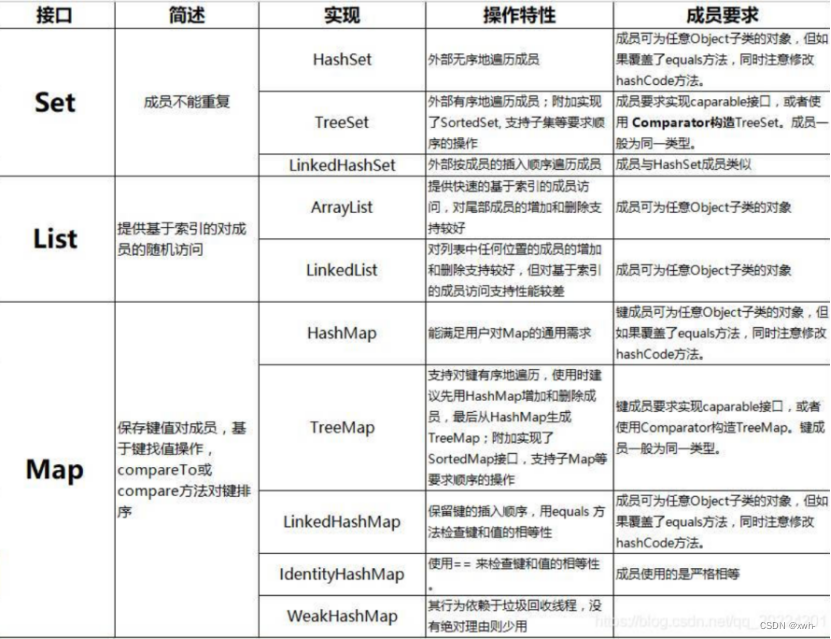
2.**HashMap的底层原理(存储结构,put的过程,0.75,8,6,16)
ArrayList: ArrayList,底层基于数组实现。ArrayList的特点是支持动态数组,可以自动扩容,适合顺序访问和随机访问。
LinkedList: LinkedList,底层基于链表实现。LinkedList的特点是支持高效的插入和删除操作,但随机访问的性能相对较差。
存储结构:ArrayList使用数组作为底层数据结构,数据在内存中是连续存储的,因此支持随机访问非常快速。LinkedList则使用链表作为底层数据结构,每个元素都包含指向前后元素的指针,插入和删除操作非常高效。
插入与删除操作:在ArrayList中,如果插入或删除元素,可能会导致数组元素的移动,从而影响性能。而LinkedList在插入和删除操作上具有明显优势,因为只需修改指针的指向,不需要移动大量元素。
随机访问性能:由于ArrayList的数组连续存储特性,它在随机访问上具有很好的性能。通过索引即可直接访问元素。而LinkedList需要从头或尾开始遍历链表,随机访问性能较差。
内存占用:由于LinkedList每个元素都需要存储前后指针,相对于ArrayList会占用更多的内存空间。如果需要存储大量数据,考虑内存占用也是一个重要因素。
迭代性能:在迭代(遍历)操作上,ArrayList由于连续存储的特性,性能通常较好。而LinkedList在迭代操作上由于需要通过指针跳转,性能相对较差。
使用ArrayList的场景:
需要频繁进行随机访问,例如根据索引获取元素。
数据集合相对固定,不需要频繁的插入和删除操作。
内存占用相对较少,不会造成严重的资源浪费。
使用LinkedList的场景:
需要频繁进行插入和删除操作,尤其是在中间位置。
不关心随机访问性能,而更关注插入和删除的效率。
可能需要更少的内存占用,尤其是在元素数量较少的情况下。
4.HashMap的HashTable的区别
HashMap不是线程安全的
HashMap是map接口的子类,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
HashTable是线程安全。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。 HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。 Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。 最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差。
Java经典面试题:HashMap和HashTable以及ConcurrentHashMap分析 - 知乎 (zhihu.com)
5.*如何使用线程安全的Map
方式一、使用HashTable
实现原理是在增删改查的方法上使用了synchronized锁机制,在多线程环境下,无论是读数据还是修改数据,在同一时刻只能有一个线程在执行synchronized方法(所有线程竞争同一把锁),因为对整个表进行锁定。所以线程越多,对该map的竞争越激烈,效率越低。
方式二、使用Collections.synchronizedMap
调用synchronizedMap()方法后会返回一个SynchronizedMap类的对象,而在SynchronizedMap类中使用了synchronized同步关键字来保证对Map的操作是安全的。
实现原理是使用工具类里的静态方法,把传入的HashTable包装成同步的,即在增删改查的方法上增加了synchronized锁机制,每次操作hashmap都需要先获取到这个对象锁,这个对象锁加了synchronized修饰,其实现方式和HashTable差不多,效率也很低。
方式三、使用ConcurrentHashMap
实现原理是HashTable是对整个表进行加锁,而ConcurrentHashMap是把表进行分段,初始情况下分成16段,每一段都有一把锁。当多个线程访问不同的段时,因为获取到的锁是不同的,所以可以并行访问。效率比HashTable
ConcurrentHashMap的实现——JDK7版本
ConcurrentHashMap在对象中保存了一个Segment数组,即将hash表分成16个桶(默认值),而每个Segent元素即每个桶类似于一个Hashtable,诸如get、put、remove等常用操作只锁当前需要用到的桶。原来Hashtable只能一个线程进入,现在能同时16个进程进入(写进程才需要锁定,而读进程几乎不受限制)。
ConcurrentHashMap的实现——JDK8版本
在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。因此,在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HahsMap蕾丝的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
JAVA中线程安全的map有:Hashtable、synchronizedMap、ConcurrentHashMap。
6.ConcurrentHashMap的原理
ConcurrentHashMap和HashMap一样,是一个存放键值对的容器。使用hash算法来获取值的地址,因此时间复杂度是O(1)。查询非常快。
同时,ConcurrentHashMap是线程安全的HashMap。专门用于多线程环境。
ConcurrentHashMap底层采用“分段锁”机制,将数据分成一段段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问,
能够实现真正的并发访问。ConcurrentHashMap结构如下:
- Segment数组:存放数据段,默认16个段,数组大小始终为2的幂次方。
- 每个Segment是一把锁,锁定一个段数据的所有访问。
- 每个Segment包含一个HashEntry数组,用来存储链表结构的数据。
一个HashEntry就是一个节点,存储key-value键值对。
三.线程
1.*创建线程有几种方式
1.继承 Thread 类并重写 run 方法创建线程,实现简单但不可以继承其他类
2.实现 Runnable 接口并重写 run 方法。避免了单继承局限性,编程更加灵活,实现解耦。
3..实现 Callable 接口并重写 call 方法,创建线程。可以获取线程执行结果的返回值,并且可以抛出异常。
4.使用线程池创建(使用 java.util.concurrent.Executor 接口)
5. 使用匿名内部类 直接在创建 Thread 对象时定义线程要执行的任务逻辑,
2.线程的生命周期
- 新建:当一个Thread类或者其子类的对象被声明并创建时,新生的线程对象处于新建状态
- 就绪:处于新建状态的西纳城被start()之后,将进入线程队列等待CPU时间片
- 运行:当就绪的线程被调度并会的处理器资源时,便进入运行状态,run()方法定义了线程的操作和功能
- 阻塞:在某种特殊情况下,被人为挂起挥着执行输入输出操作时,让出CPU并临时中止自己的执行,进入阻塞状态
- 死亡:线程完成了它的全部工作或者线程被提前强制性的中止
3.***线程池的原理以及7个参数是什么(有什么作用),4个拒绝策略是什么
原理:

7个参数:

(1)corePoolSize:线程池中常驻核心线程数
(2)maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1
(3)keepAliveTime:多余的空闲线程存活时间。当前线程池数量超过corePoolSize时,当空闲时间到达keepAliveTime值时,多余空闲线程会被销毁直到只剩下corePoolSize个线程为止。
(4)unit:keepAliveTime的时间单位
(5)workQueue:任务队列,被提交但尚未执行的任务
(6)threadFactory:表示生成线程池中的工作线程的线程工厂,用于创建线程,一般为默认线程工厂即可
(7)handler:拒绝策略,表示当队列满了并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝来请求的Runnable的策略
4个拒绝策略:
(1)AbortPolicy(中止策略)
(默认) 直接抛出RejectedExecutionException异常阻止系统正常运行。
(2)CallerRunsPolicy (调用者运行策略)
“调用者运行”一种调节机制,该策略既不会丢弃任务,也不会抛出异常,而是将某些任务回退给调用者,从而降低新任务的流量。
(3)DiscardOldestPolicy (丟弃最旧策略)
抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务。
(4)DiscardPolicy (丢弃策略)
直接丢弃任务,不予任何处理也不抛出异常。如果允许任务丢失,这是最好的一种方案。
4.线程安全,线程通信
1. 线程池核心3队列长度5 最大是10 问:第7个任务在哪?(在任务队列内)第9个任务在哪?(创建新线程执行任务)第16个任务在哪?(执行拒绝策略): 只要没有超过最大线程10 超过队列也会再执行 第16个执行了拒绝策略

2. 使用多线程和线程池分别的好处: 使用多线程的好处? 提高CPU利用率。简化编程模型。防止程序阻塞
使用线程池的好处? 降低资源消耗 提高响应速度 便于线程管理(资源可控) 避免线程溢出
5.*Reentrantlock和synchromied lock的区别
6.synchromied lock 修饰实例方法 静态方法 代码块 分别的含义
7.Sleep和wait的区别
8.什么是反射机制
9.*Cglib的动态代理和jdk的动态代理的区别
10.JVM内存模型(每一步分别放什么内容)
11.垃圾回收算法
12.Java当中的四种引用类型
13.(如何控制线程的执行顺序)
14.*接口和抽象类的区别
15.JDK1.8的新特性
16.什么是双亲委派
17.为什么需要双亲委派
四.Redis
1.Redis为什么快?(单线程,内存)
2.*Redis常用的数据类型(5个)
3.*Redis的持久化策略
4.数据淘汰策略
5.*Redis中的大K问题
五.Mysql
1.sql语句的执行顺序
2.***Mysql索引失效的场景
3.**Sql语句如何优化
4.***Mysql数据库的优化(数据库里加索引一定有效吗?一定效率快吗?)
5.Mysql中索引有哪些类型
6.*B+树索引和Hash索引的区别
7.Mysql为什么使用B+树索引而不使用B-树索引
8.*列举一些Mysql当中常用的聚合函数
9.列举Mysql开窗函数
10.行转列,列转行
11.****Mysql事务的隔离级别
12.*事务的四个特性
13.****Mysql是如何使用MVC解决,脏读,幻读,不可重复读现象的
14.*Mysql的七大日志
15.Union和UnionAll的区别
16.*Mysql中常用的日期函数和字符串函数
六.Linux
1.列举常用的Linux命令
ps , kill(和kill -9的区别), telnet, tail , source ,
top* ,grep |(管道符) ,mvn 查看帮助,history,cat,vim ,yum,rpm,ping ifconfig ipcon
知识点汇集
2024/5/10 12:04
stock
localhost:3000/print.html
1/178
Java
基础
3. Java
中的数据类型
5. instanceof
用来测试一个对象是否是一个类、接口的实例。用法如下:
7. OOP
的基本特征是什么?
OOP
就是面向对象。 它有三个特性olean 规范中没有定义。现在实现为:单个是转成int型,boolean[]
中则占一个字节。
引用类型
boolean
result = obj
instanceof
Integer;
#
在
java
规范中,如果
obj
为
null
,则无论后面的类和接口是什么,都返回
false
。
#
也就是说
null
不是任何类的实例。
Assert.assertFalse(
null instanceof
Object);
// true
指将对象信息状态隐藏在内部,只能通过对象提供的方法来访问,这个增强安全性和可靠性的方法称为封
装。
指子类可以通过继承父类的属性和方法实现重用代码的方式。
2024/5/10 12:04
stock
localhost:3000/print.html
2/178
3.
多态
一般认为指不同对象对同一消息做出响应,但是这只反映出了重写实现的多态。我认为多态
有两种表现:
重写(类的多态):
子类覆盖父类的方法。
重载(方法多态):
一个类里面方法名相同,参数类型或个数不同。
8. ==
和
equals
==
比较的是内存地址
equals
比较的是值,但是自定义类如果没有覆盖
equals
方法的话,效果等同于
==
9. hashcode
的作用
使用在
Set
和
Map
中,使用
hash
算法计算一个值,然后根据这个值确定数据要存放的地址。
HashMap vs HashTable
1. Hashtable
是线程安全的,
Hashmap
不是线程安全的,可以使用
ConcurrentHashMap
,有
锁且速度快,因为它使用了分段锁。
2. Hashtable
的
key
和
value
不能为
null
,
HashMap
没有限制。
3.
父类不一样,
Hashtable
继承
Dictionary
类,
Hashmap
继承
AbstractMap
抽象类。
HashMap
结构
1.
发生在父子类之间
2.
方法名、参数列表和返回类型必须相同
3.
访问修饰符限制不能小于被重写方法
4.
不能抛出新的或大的异常。
1.
方法同名,参数类型、个数、顺序不同。
2.
返回值可以相同也可不相同。
HashMap
中有一个
Node(Map.Entry
的子类
)
数组,当向
map
中放置数据时,
它首先根据
hashcode
找到要放的位置,如果该位置没有数据就放入数据,
有的话就比较
key
值是否相等,相等则覆盖,否则放入列表中,
当列表数量大于
8
时会将列表变成一个树,以提高效率。
2024/5/10 12:04
stock
localhost:3000/print.html
3/178
ConcurrentHashmap
1.8
之前是使用分段锁实现同步。
1.8
之后是通过
CAS+Synchronized
来保证并发安全的
HashMap
中的
Key
可以使用任何类作为
key
吗?
最好是不可变的 例如使用
String, Integer
等不可变对象。
一般需要重写
equals
和
hashCode
方法。
如果是自定义类作为
key
的话,需要重新定义
equals
和
hashCode
方法。
10. String
,
StringBuffer
,
StringBuilder
的区别是什么
String
是只读字符串,所有对
String
的修改都会重新创建对象。因此对它的修改操作就会比较
慢。
StringBuffer
和
StringBuilder
适合频繁修改场景。
但是
StringBuffer
是线程安全
的,因此适合多线程场景下。
15.
泛型
泛型就是泛指的类型,目的是提高代码的复用性,在向支持泛型的数据结构中存储数据时会转型为
Object
,这时它就丢失了数据本来的类型,称为数据擦除。 在获取的时候会进行类型强制转换。
16. Java
创建对象有几种方式
1. new
创建新对象
2.
通过反射机制
3.
采用
clone
机制
4.
通过序列化机制
Object o =
new
Object();
Employer emp = (Employer)
Class.forName(
"org.example.model.Employuer"
).newInstance();
Employer ano = (Employer)emp.clone();
2024/5/10 12:04
stock
localhost:3000/print.html
4/178
17.
浅拷贝和深拷贝
1.
浅拷贝仅仅考虑复制对象本身的字段,对引用字段指向的对象不拷贝。
2.
深拷贝会把引用字段指向的对象也复制一遍。
24. Exception
和
Error
1. RuntimeException
2. Exception
3. Error
4.
怎么处理
Java
异常的 一般使用
try-catch-finally
来实现。其中
try
块监控可能出现异常的代码;
catch
负责捕获可能出现的异常;
finally
负责清理各种资源,不管是否出现异常都会执行。
ObjectInputStream in =
new
ObjectInputStream(
new
FileInputStream(
"data.obj"
));
Employer emp = in.readObject();
浅拷贝对象修改拷贝对象时,可能会影响原对象,因为引用指向的对象仍然一样。
ClassCastException
IndexoOutOfBoundsException
NullPointerException
ArithmeticException
IOException
FileNotFoundException
SQLException
OutOfMemoryError
2024/5/10 12:04
stock
localhost:3000/print.html
5/178
25 OOM
OOM
就是
Out of Memory
,表示内存耗尽。
1. java.lang.OutOfMemoryError: Java heap spaces
内存泄漏
内存溢出
可以使用
-Xms, -Xmx
参数来设置。
1. java.lang.OutofMemoryError: PermGen/Metadata space
永久区、元数据溢出,一般是因
为类太多导致。使用
-XX: PermSize
和
-XX: MaxPermSize
设置。
2. StackOverflowError
一般是深度递归导致或死循环导致。
30
反射
反射机制是指在运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意个对
象, 都能够调用它的任意一个方法。这种在运行时获取类信息或调用对象功能的机制称之为反
// finally
中不要使用
return
语句,否则会覆盖正常的
return
语句。
@Test
public void
testTry
()
{
int
ok = tryCatchFinally(
5
);
System.out.println(
"ok = "
+ ok);
int
result = tryCatchFinally(
0
);
System.out.println(
"result = "
+ result);
}
public int
tryCatchFinally
(
int
n)
{
try
{
int
i =
10
/n;
return
i;
}
catch
(ArithmeticException e) {
return
-
2
;
}
finally
{
return
-
1
;
}
}
内存申请,以后不再使用但是也不能释放。
不存在,但是因为还要使用,所以也不能释放。
2024/5/10 12:04
stock
localhost:3000/print.html
6/178
射。
35 ArrayList
和
LinkedList
的区别
1. ArrayList
基于动态数组,查询效率高,因为要移动数据,所以插入和删除操作效率比较低。
循环删除时容易有问题。
2. LinkedList LinkedList
是基于链表的数据结构,因此新增、删除操作比较有优势。
LinkedList
适用于头尾操作。 但查询效率低。
3.
适用场景
随机访问多,使用
ArrayList
多次增删改,使用
LinkedList
扩展
1. TreeMap vs LinkedHashMap
1. TreeMap
按照
key
排序
2. LinkedHashMap
按照放入的顺序排序。
2.
线程安全版本
HashMap -> ConcurrentHashMap
ArrayList -> CopyOnWriteArrayList
LinkedList -> ConcurrentLinkedQueue
TreeMap -> ConcurrentSkipListMap
3. AQS
AQS
即
AbstractQueuedSynchronizer
,它提供了一套可用于实现锁同步机制的框架,它内部维护
一个
FIFO
队列维护线程状态,继承该类并重写指定方法即可实现线程同步机制。
AQS
根据资源互斥级别提供了独占和共享两种资源访问模式。
2024/5/10 12:04
stock
localhost:3000/print.html
7/178
4.
接口和抽象类的区别
实现
抽象类的子类需要使用
extends
继承; 接口需要使用
implements
来实现
构造函数
抽象类可以有构造函数,接口不能有(现在的版本也可以有
default
实现)。
main
方法(
17
不适用)
抽象类可以有
main
方法,且可以运行。接口不能有
main
方法
实现数量
类可以实现多个接口,但是只能继承一个抽象类
访问修饰符
接口中的方法默认使用
public
修饰;抽象类中的方法可以是任意访问修饰符。
5. IO
模型
1. BIO
阻塞
IO
,在读取、写入数据时,会阻塞线程,直到数据读取或写入完成。
2. NIO
非阻塞
IO
,在读取、写入数据时,如果没有数据直接返回装填,如果有数据需要等待数
据读取完成(从内核态拷贝数据到用户态)。 一般和多路复用模型结合,可以减少轮询读取
数据的开销。
3. AIO
异步
IO
,基于事件和回调实现的
IO
模型。据说和
NIO
相比性能变化不是很大。
8. Java 8
有哪些新特性。
1. Lambda
表达式
2.
方法引用
3. Stream API
相比数据结构,流具有
无存储
天生函数化
懒执行
可能无界
可消费的。 常用的方法有:
filter
过滤
map
映射
sorted
排序
2024/5/10 12:04
stock
localhost:3000/print.html
8/178
forEach
终结方法
collect
终结方法
1. Optional
类
解决空指针情况
List<List<Student>> collect = Optional.ofNullable(students)
.orElse(
new
ArrayList<>())
//
处理空对象
.stream()
.collect(Collectors.groupingBy(student -> {
return
""
+ student.grade()+
"_"
+student.classId();
}))
//
分组
.values()
.stream()
.collect(Collectors.toList());
2024/5/10 12:04
stock
localhost:3000/print.html
9/178
JVM
1. JVM
内存模型
1.
程序计数器
保存当前线程执行的字节码位置,每个线程工作时都有独立的计数器。
2.
栈
线程私有的方法栈。
3.
本地方法栈
执行
Native
方法时使用本地栈。
4.
堆
(
线程公有
)
JVM
内存管理最主要的部分,线程共享,用于存放对象的实例。
5.
方法区
/
元数据空间
(
线程公有
)
3.
类的加载与卸载
1.
加载
双亲委派模式是指先把请求委托给自己的父类加载器执行,父类没有加载成功才自己尝试加
载。
避免类的重复加载
避免
Java
核心
API
被篡改。
2.
验证
检验
Class
文件是否符合虚拟机要求
3.
准备
内存分配,为
static
变量分配内存并设置初始值(注意:
final
修饰的静态变量在编译时分
配)。
4.
解析
常量池中的符号引用替换为直接引用。
加载
验证
准备
解析
初始化
2024/5/10 12:04
stock
localhost:3000/print.html
10/178
5.
初始化
静态块的执行、静态变量的赋值等。初始化发生在类首次被使用时。
17.
调优命令
1. jps
2. jstat
用于监视虚拟机运行状态信息
3. jmap
生成堆
dump
文件
4. jstack
生成
Java
虚拟机的线程快照
重点关注:
runnable
执行中
deadlock
死锁
(
重点关注
)
blocked
被阻塞
(
重点关注
)
5. jinfo
实时查看和跳转虚拟机运行参数
class
Car
{
private
Engine engine;
}
class
Engine
{
private
Stirng name;
}
#
显示系统内的
Java
虚拟机进程
jps
#
垃圾回收统计
jstat -gc <pid>
#
类加载统计
jstat -class <pid>
#
堆内存统计
jstat -gccapacity <pid>
#
查看有哪些选项
jstat -options
#
以二进制格式导出指定
pid
的堆,之后可以使用
jhat
分析;更多使用
MAT
来分析
jmap -dump:live,format=b,file=path/dump.log <pid>
jstack <pid>
2024/5/10 12:04
stock
localhost:3000/print.html
11/178
29.JVM
调优参数
1. -Xms -Xmx
初始和最大堆
2. -XX:NewSize
新生代大小
3. -Xss
每个线程的堆栈大小
4. -XX:+PrintGCDetails
打印
GC
信息
5. -XX:+HeapDumpOnOutOfMemoryError
内存溢出时自动生成内存快照
6. -XX:+UseG1GC
指定使用某
G1
垃圾收集器
使用在新生代和老年代中,
JDK9
之后成为默认垃圾回收器。分区但无比例设置,采用复制算
法;分为三个阶段: 新生代;标记复制算法到幸存者区。
幸存者:部分到另一个幸存者,部分升级到老年代。 老年代:超过阈值后,会进行并发标
记。会根据暂停时间要求,优先回收价值高的区域。混合回收。
参数哪里设置
war
catalina.sh
里有一个
JAVA_OPTS="-Xms512m -Xmx=1024m"
jar
30 GC
算法和垃圾回收器
GC
算法是方法论,垃圾回收器是具体实现。
GC
算法
1.
标记清除 两个阶段
2.
复制算法 内存分为两块
3.
标记整理 标记后整理到一端
4.
分代算法 新生代采用复制算法,老年代采用标记整理算法。
#
nohup
后台运行不中断
#
&
在后台运行
nohup java -Xms512m -Xmx1024m -jar aa.jar -spring.profiles.active=prod &
2024/5/10 12:04
stock
localhost:3000/print.html
12/178
垃圾回收器
1.
串行(复制)
2.
并行(复制)
3. CMS(
标记清除算法
)
4. G1
(标记整理算法) 标记整理算法,回收范围是整个堆。
5. ZGC
(分区整理算法) 动态分区内存布局,采用多种技术(多重映射、读屏障、染色指针)
实现的可并发标记整理算法的收集器,优点是低停顿、高吞吐量。缺点:有浮动垃圾。
31.
怎么选择垃圾回收器
1.
单核或堆比较小,可以选用串行垃圾收集器。
2.
如果吞吐量优先,对停顿没有要求,可以采用并行收集器
3.
其他选择
CMS
,
G1
,或
ZGC
。
实践
1. OOM
1.
找到
java
进程
2.
导出堆内容
3.
启动时添加
Dump
参数
(jmap
来不及使用
)
4.
查看堆中的信息,推断分析
jps
jmap -dump:live,format=b,file=name.hprof pid
-XX:+HeapDumpOnOutOfMemoreyError
-XX:HeapDumpPath=/home/app/dumps
MAT / VisualVM
2024/5/10 12:04
stock
localhost:3000/print.html
13/178
2. CPU
飙高
按照以下步骤处理:
找到
CPU
占用最高的进程
找到占用最高的线程
打印堆栈
线程
ID
进制转换
10 -> 16
垃圾回收算法
Zero
垃圾回收算法讲解
#
找到
CPU
占用高的进程
id
top
#
找到
CPU
占用高的线程
,
与下面的方法类似
top -H -p <pid>
#
找到进程中占用高的线程
ps H -eo pid,tid,%cpu|grep <pid>
jstack pid
printf "%x\n" 2276
2024/5/10 12:04
stock
localhost:3000/print.html
14/178
多线程
1.
创建线程的方法
1.
继承
Thread
类
2.
实现
Runnable
接口
3.
实现
Callable
接口 相对于
Runnable
接口,
Callable
接口可以有返回值,可以声明抛出异常。
4.
使用线程池
2.
如何停止正在运行的线程
1. stop()
方法 不推荐,过期方法。
2. interrupt()
方法
3.
使用退出标志
3. notify
和
notifyAll
有什么区别
notifyAll
唤醒所有处于
WAIT
状态的线程。
notify
随机唤醒一个
wait
线程。
public class
ThreadInterrupt
extends
Thread
{
public void
run
()
{
try
{
sleep(
50000
);
}
catch
(InterruptedException e) {
System.out.println(e.getMessage());
}
}
public static void
main
(String[] args)
throws
Exception {
Thread thread =
new
ThreadInterupt();
thread.start();
System.out.println(
"
按键中断线程
"
);
System.in.read();
thread.interrupt();
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
15/178
4. java
中的
wait
和
sleep
方法有什么不同
相同点
wait(),wait(long),sleep(long)
都让当前线程暂时放弃
CPU
的使用权,进入阻塞状态
不同点
1.
方法归属不同,
sleep
是
Thread
的静态方法;
wait
是
Object
的成员方法。
2.
醒来时机不同 执行
sleep(long)
和
wait(long)
的线程都会在相应毫秒后醒来。
wait(long)
和
wait()
还可以被
notify
唤醒,
wait()
不唤醒就一直等待。
3.
锁特性不同
wait
方法必须先获取
wait
对象的锁,
sleep
无限制。
wait
执行后会释放对象
锁,
sleep
不会释放锁。
5. volatile
是什么?
变量被
volatile
修饰后,具有两层语义:
1.
保证不同线程对变量的操作的可见性,它会强迫将更新写入到主存。
2.
禁止指令重排序,确保它前面的语句还在前面,后面的还在后面。
6.
调用
Thread
的
run
方法和
start
方法有什么区别
run
方法是一个普通方法,不会启动线程。
start
方法用来启动线程,该线程执行
run
方法
8.
为什么
wait
和
notify
方法要在同步块中调用
1.
只有在调用线程拥有某个对象的独占时,才能调用该对象的
wait,notify,notifyAll
方法。
2.
不这么做就会抛出
ILLegalMonitorStateException
异常。
10. Java
中的
synchronized
和
ReentrantLock
有什么不同
1. synchronized
是
Java
语言的关键字,是原生语法层面的互斥。
wait
方法强制当前线程释放对象锁,这意味着当前线程必须已经获得该对象锁。
notify
和
notifyAll
要讲锁交给别的线程,如果自己没有锁怎么交给别人。
2024/5/10 12:04
stock
localhost:3000/print.html
16/178
2. ReentrantLock
是
API
层面的互斥锁,需要
lock(),unlock()
方法配合
try/finally
来完成。
11.
新建
t1
,
t2
,
t3
三个线程,怎么让他们按顺序执行
可以使用线程中的
join
方法解决。
13.
什么是线程安全
多个线程执行相关联的代码时,不会产生不确定的结果。一般是通过锁来实现的。
17.
怎么使用
synchronized
关键字
1.
使用在实例方法上
执行时会获得当前实例的锁。
2.
使用在类方法上
执行时会获取当前类对象的锁。
3.
使用在代码块上
执行时会获得给对对象上的锁
syncronized
语句编译时会在同步块的前后分别形成
monitorenter
和
monitorexit
这两个字节码指令,
执行
monitorenter
时会首先尝试获取对象锁,如果能够获取则会将锁的计算器加
1
,
响应的
monitorexit
执行后会将锁的执行器减一,当计算器为
0
时,锁就释放了。
相比
syncronized
,
ReentrantLock
有提供了一些高级功能:
1.
等待可中断,可以设定最长等待多长时间锁。
2.
多个线程等待锁时,可以按照申请时间顺序获得锁,实现公平锁。
3.
锁绑定多个对象。
Thread t1 =
new
Thread(() -> {
System.out.printnln(
"t1"
)
});
Thread t2 =
new
Thread(() -> {
t1.join();
System.out.printnln(
"t1"
)
});
t2.start();
t1.start();
2024/5/10 12:04
stock
localhost:3000/print.html
17/178
23.
锁的升级
1.
偏向锁
2.
轻量级锁
3.
重量级锁
为什么有了轻量级锁还要重量级锁?
24.
进程和线程的区别
进程是程序运行的实例,进程中包含了线程,每个线程执行不同的任务。
不同的进程使用不同的内存空间,在当前进程下的所有线程可以共享内存空间
线程更轻量,线程上下文切换成本一般要比进程上下文切换低。
25.
产生死锁的四个必要条件
1.
互斥
2.
请求并保持
3.
不剥夺
无锁
偏向锁
自旋锁
重量级锁
在
java
对象头上标记线程
ID
,这样下次在进入是如果是同样线程
ID
直接进入即可。
偏向锁在有竞争的时候才会撤销。
当有不同的线程来竞争锁时,会暂停当前线程,然后使用
CAS
抢占轻量级锁。
当有多个线程在抢占锁或某个线程抢占多次仍然没有抢到锁时会升级到重量级锁。
重量级锁需要走内核态,会比较慢。但是它有等待队列,需要获取锁的线程会在这里登记,等待调用
是因为轻量级锁是使用
CAS(
比较并替换
)
算法,就会涉及到浪费
cpu
的循环,
较多线程竞争或较长时间获取不到锁的时候会浪费
cpu
。
资源只能被一个线程使用
一个线程因请求资源而阻塞时,对自己持有的资源保持不放。
2024/5/10 12:04
stock
localhost:3000/print.html
18/178
4.
循环等待
35.
线程池
为什么使用线程池?
1.
降低资源消耗。
可以重复利用已经创建的线程,降低创建和销毁造成的消耗。
2.
提高响应速度。
可以直接复用线程池中已有的线程。
3.
提高线程的可管理性
使用线程池能够统一分配、监控和优化。
ThreadPoolExecutor
核心参数
1. corePoolSize
核心线程数量,
2. maximumPoolSize
最大线程数量
3. keepAliveTime
线程空闲存活时间
4. unit
线程存活时间单位
5. workQueue
任务队列,用于存放已提交的任务
6. threadFactory
,线程工厂
7. handler
拒绝策略
添加任务到线程池时的流程
worker =
正在工作的线程数目
1.
如果
worker < corePoolSize ,
直接创建线程执行提交的任务。
2.
如果
worker >= corePoolSize &&
阻塞队列未满 , 将任务添加到阻塞队列,等待后续线程来
执行改任务。
获得的资源,未使用完之前,不能被强行剥夺
若干线程之间互相错位需要对方的资源
为什么使用阻塞队列?
避免线程池内部使用阻塞
-
唤醒机制。这样当从空队列获取或向满队列插入时会自动阻塞,
当队列状态变化时也会自动唤醒等待线程。
2024/5/10 12:04
stock
localhost:3000/print.html
19/178
3.
如果
worker >= corePoolSize &&
阻塞队列已满
&& worker < maximumPoolSize
创建新线
程执行提交的任务。
4.
如果 阻塞队列已满
&& worker >= maximumPoolSize
则执行拒绝策略
合理设置线程数
CPU
密集
(
计算类
) CPU
数目
+1
IO
密集(网络读取之类)
CPU * 2
2024/5/10 12:04
stock
localhost:3000/print.html
20/178
36.
线程池拒绝策略
AbortPolicy
直接拒绝抛出异常
DiscardPolicy
直接丢弃任务。
DiscardOldPolicy
丢弃阻塞队列中的任务,执行当前任务
CallerRunPolicy
让提交任务的线程来执行任务
xx.
线程池的五种状态
RUNNING
能够接收新的任务以及处理阻塞队列中的任务
SHUTDOWN
不接收新到来的任务,但继续处理阻塞队列中的任务
STOP
不再接收新到来的任务,不处理阻塞队列中的任务,会中断正在处理中的任务。
TIDYING
所有任务已终止,线程数为
0
,运行
terminated
方法
TERMINATED terminated
方法运行后进入这个状态
39. CyclicBarrier
和
CountDownLatch
的区别
1. CyclicBarrier
的某个线程运行到某点时会停止运行,等待其它线程到达所有线程再运行。
CountDownLatch
是运行到某点后对计数器减一,线程继续运行。
2. CyclicBarrier
只能唤起一个任务(
?
),
CountDownLatch
可以唤起多个任务。
3. CyclicBarrier
可重用,
CountDownLatch
不可重用。
41.
信号量
Semaphore
Semaphore
是一个信号量,它的作用是限制某段代码块的并发数。如果并发数限制为
1
,则相当于
变成一个
synchronized
了。
2024/5/10 12:04
stock
localhost:3000/print.html
21/178
45.
什么是
Daemon
线程
Daemon
线程
=
后台线程
=
守护线程
指在程序运行时,在后台提供服务的线程,当所有非后台线程执行结束时,程序也将结束运行。可
以通过在线程启动之前设置
setDaemon()
方法将线程设置为后台线程。
JVM
中的垃圾回收线程就是
Daemon
线程。
46.
乐观锁和悲观锁
1.
悲观锁
总是假设最坏的情况,每次拿数据时都会认为别人会修改,所以每次都会上锁。
数据库中有行锁,表锁,写锁,读锁等。
Java
中的
Synchronized
也是悲观锁
2.
乐观锁
每次拿数据时都认为别人不会修改,因此不会上锁,但是在更新的时候会判断是否有人在这
期间修改了。
数据库中可以使用版本号机制
CAS
实践
1.
为什么不建议使用
Executors
//
请求等待队列允许的长度为
Inter.MAX_VALUE
Executors.fixedThreadPool(size)
Executors.singleThreadTool()
//
允许创建的线程数量为
Integer.MAX_VALUE
Executors.cachedThreadPool()
Executors.ScheduledThreadPool()
//
看个栗子
public static
ExecutorService
newCachedThreadPool
()
{
return new
ThreadPoolExecutor(
0
, Integer.MAX_VALUE,
60L
, TimeUnit.SECONDS,
new
SynchronousQueue<Runnable>());
}
2024/5/10 12:04
stock
localhost:3000/print.html
22/178
2.
核心线程是否会被回收
默认不回收核心线程,我们可以使用
allowCoreThreadTimeOut(true)
方法允许回收核心线程。
3.
并行与并发有什么区别
并发同一时间应对多件事情的能力(多个线程轮流使用
cpu
的情况)。 并行是同一时间做多件事情
的能力
单
CPU
宏观并行,微观串行
多
CPU
现代情况下都是多核
CPU
。
4. Runnable
和
Callable
接口有什么区别
1. Callable
有返回值,配合
Future
和
FutureTask
配合可以获得异步执行的结果,
Runnable
没有
返回值。
2. run
方法不能抛出异常,
call
可以抛出异常。
5.
线程包含了哪些状态,状态之间如何变化
NEW (
新创建
)
RUNNABLE
(就绪【没有抢到
CPU
】和运行【抢到
CPU
】)
BLOCKED
(有资格但无法获得锁)
WAITING
(调用
wait
放弃
CPU
之后)
TIME_WAITING
(
Thread.sleep
之后)
2024/5/10 12:04
stock
localhost:3000/print.html
23/178
TERMINATED
(线程结束)
6. AQS
介绍
AQS
就是
AbstractQueuedSynchronizer,
它是
JUC(Java
并发工具包
)
的基础。它内部维护了一个
volatile int state
变量和一个
CLH
双向队列,队列中的节点持有线程引用,每个节点均可通过
getState/setState/compareAndSetState
对
state
进行修改和访问。 当线程试图获取锁时,它就尝
试对
state
进行修改,修改成功则获取锁,修改失败则包装成节点挂载到队列中,然后等待持有锁
的线程释放锁并唤醒队列中的节点。
实现类根据情况可以只实现
tryAcauire/tryRelease
或
tryAcquireShared/tryReleaseShared
方法。
7. JUC
JUC
就是
java.util.concurrent
包的简称,目的就是支持高并发任务,让开发者进行多线程编程时减
少竞争条件和死锁问题。
2024/5/10 12:04
stock
localhost:3000/print.html
24/178
一个线程等待一组线程完成工作
一组线程在某公共点汇合后再运行
计数信号量
_
控制并发
需要任务重复执行
同步原语
_AQS
也有引用
JUC
tools
CountDownLatch
CyclicBarrier
Semaphore
executor
ScheduledThreadPoolExecutor
atomic
AtomicBoolean
AtomicInteger
AtomicIntegerArray
locks
ReentrantLock
ReentrantReadWriteLock
LockSupport
collections
CopyOnWriteArrayList
CopyOnWriteArraySet
ConcurrentHashMap
2024/5/10 12:04
stock
localhost:3000/print.html
25/178
Spring
2. Spring
的好处
1. IOC/DI
控制反转或依赖注入
2.
简化事务管理
3.
面向切面编程
4.
方便集成各种优秀框架
5. MVC
框架
6.
异常处理
3. Autowired
和
Resource
的区别:
1.
是否绑定
Spring
。
1.
注入方式不同
非侵入式设计
方便解耦,简化开发。
使单元测试容易实现。
通过配置就可以完成事务管理。
通过添加
@EnableTransactionManagement
和
@Transactional
注解就可以实现。
提供了对
AOP
的支持,方便实现对安全、事务、日志等进行集中式处理。
例如对
RocketMQ
,
Kafka
,
Redis
等的支持让我们使用非常方便。
Spring MVC
框架是个精心设计的框架,使用方便功能强大。
提供方便的
API
将具体技术的相关异常转化为一致的
unchecked
异常。
Autowired
是
Spring
提供的注解,依赖于
Spring
。
Resource
是
J2EE
提供,不依赖于
Spring
。
2024/5/10 12:04
stock
localhost:3000/print.html
26/178
4.
依赖注入的方式有几种
1.
构造器注入
2. setter
方法注入
3.
接口注入
6.
对
Spring MVC
的理解
1. DispatchServlet
分发器,总控制中心。
Resource
有两个属性
name
和
type
,它可以根据名称和类型注入,缺省按名称注入。
Authwired
缺省以类型注入,以名称注入的话需要加
Qualified
。
优点:初始化完成后即可获得可使用对象。
缺点:构造参数列表太长,不好看。
优点:简单灵活
缺点:容易造成类功能膨胀
侵入性太强,或者说和框架绑定。
Spring MVC
是
MVC
设计模式在
Spring
平台中的实现。
其中
M
是模型,负责业务逻辑的实现。
V
是视图,负责界面展示。
C
是控制器,负责接收请求,调用
Model
,根据结果派发到不同的视图。
2024/5/10 12:04
stock
localhost:3000/print.html
27/178
2. HandlerMapping
将请求映射为
HandlerExecutionChain(
包含
Handler
,多个
HandlerInterceptor
拦截器
)
3. HandlerAdapter
根据
Handler
找到对应的
HandlerAdapter
,然后
HandlerAdapter
会适配不同类型的
Handler
。
4. Handler
@RequestMapping
Controller
接口
HttpRequestHandler
继承
HttpServlet
类
5. ViewResolver
将逻辑视图解析为具体的
View
6. View
视图
7. Spring
的常见注解
Spring
常见注解
@Component
@Autowired
@Qualifier
@Scope
@Configuration
@ComponentScan
@Bean
@Import
Aspect Before After Around
SpringMVC
常见注解
@Controller
@RestController
RequestMapping
RequestBody
RequestParam
PathVariable
2024/5/10 12:04
stock
localhost:3000/print.html
28/178
ResponseBody
RequestHeader
SpringBoot
常见注解
@SpringBootApplication
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan
8. AOP
AOP
是面向切面编程,切面可以理解为对业务流程横截面,它是解决与业务无关但是又比较普遍的
需求。 例如日志记录,权限管理,事务等。
AOP
实现分为静态和动态
AOP
,静态
AOP
可以使用
AspectJ
,它是在编译期增强。另外一种是动态
AOP
,实现方式又分为动态代理和动态字节码生成。
动态代理是
Java
原生支持,比较简单,但是被代理的必须是接口,字节码使用的是
CGLib
,它比较
灵活,但是对
final
方法则无法织入。
1.
一些概念
连接点 代表一个应用程序的某个位置。
切入点 一个或一组连接点
通知 在切入点要执行的操作
before
after
方法执行之后调用的通知
after-returning
成功完成后的通知
after-throwing
方法抛出异常退出时执行的通知
around
切面 包含切点和相应的通知。
2024/5/10 12:04
stock
localhost:3000/print.html
29/178
11. Bean
的生命周期
14. Spring
用到了哪些设计模式
工厂模式
单例模式
原型模式
容器关闭
实例化
依赖注入
Aware
接口
BeanPostProcessor#before
InitializingBean or initMethod
BeanPostProcessor#after
disPosableBean
destroyMethod
BeanFactory..getBean()
简单工厂模式
FactoryBean
工厂方法模式,
在调用
getBean
获取该
Bean
时,会自动调用该
bean
的
getObject()
方法,所以放回的不是
factory
这
个
bean
,
而是这个
factory
的
getObject()
方法返回的
bean
2024/5/10 12:04
stock
localhost:3000/print.html
30/178
迭代器模式(
Iterator
)
代理模式
(AOP)
适配器模式
观察者模式
模板方法模式
(JdbcTemplate)
责任链模式
16. Spring
框架中的单例
Bean
是线程安全的吗?
因为大部分单例
Bean
没有可变的状态,所以是线程安全的。 但是如果
Bean
有可变状态的话他就不
是线程安全的。
17. Spring
中的循环引用
1.
什么是循环依赖
当然下面这种也是
两个或两个以上的
bean
互相引用对方,最终形成闭环。
2.
循环依赖是怎么解决的?
基于
set
依赖 使用三级缓存来解决。
基于构造方法循环依赖 当有循环依赖时会导致
Spring
没有办法创建
Bean
,导致抛出
BeanCurrentlyInCreationException
异常。
A
B
A
B
C
D
singletonObjects
已经初始化完成的
bean
对象
earlySingletonObjects
缓存早期的
bean
对象
singletonFactories
缓存的是
ObjectFactory
2024/5/10 12:04
stock
localhost:3000/print.html
31/178
怎么解决?
重新设计
使用
setter/field
方法注入
使用
@Lazy
注解
其中一个类使用
@PostContruct
注解
实现
ApplicationContextAware
和
InitializeBean
接口
19.
事务传播类型
1. REQUIRED Spring
默认事务传播类型,如果当前没有事务则新建一个事务,如果当前存在事
务则加入这个事务。
2. SUPPORTS
当前存在事务,则加入当前事务,如果当前没有事务,就以非事务方法执行。
3. MANDATORY
当前存在事务,则加入当前事务,如果当前事务不存在,则抛出异常。
4. REQUIRES_NEW
创建一个新事物,如果存在当前事务,则挂起该事务。
5. NOT_SUPPORTED
始终以非事务方式执行,如果当前存在事务,则挂起当前事务。
6. NEVER
不使用事务,如果当前事务存在,则抛出异常。
7. NESTED
如果当前事务存在,则在嵌套事务中执行,否则开启一个事务(和
REQUIRED
一
样)。
@Service
public class
ServiceB
{
private
ServiceA serviceA;
@Autowired
public
ServiceB
(ServiceA serviceA)
{
this
.serviceA = serviceA;
}
}
@Service
public class
ServiceA
{
private
ServiceB serviceB;
@Autowired
public
ServiceA
(ServiceB serviceB)
{
this
.serviceB = serviceB;
}
}
会先注入一个代理,然后使用时在用真正的实例。
在
@PostContruct
修饰的方法中设置另外一个实例对本实例的依赖。
通过
ApplicationContextAware
的
setApplicationContext
方法获取上下文对象,
然后在回调方法
afterPropertiesSet
中获取
bean
并设置字段值。
2024/5/10 12:04
stock
localhost:3000/print.html
32/178
xx. Spring
事务失效场景
1.
捕获异常但是没有再次抛出
2.
抛出检查异常
Transactional
缺省只对非检查异常处理,可以使用
@Transactional(rollbackFor=Exception.class)
来对所有异常生效。
3.
非
public
方法导致事务失效
4.
有事务的方法被内部调用
参考
1.
事务传播机制
vs REQUIRED_NEW:
REQUIRED_NEW
是新建一个事务且新开启的事务与原有事务无关,
而
NESTED
则是在当前存在事务时会开启一个嵌套事务。
在
NESTED
情况下父事务回滚时子事务也会回滚。
vs REQUIRED
REQUIRED
情况下,调用方存在事务时,则被调用方和调用方使用同一事务,被调用方出现异常时,
由于共用一个事务,无论调用方是否
catch
其异常,事务都会回滚。
在
NESTED
情况下,被调用方发生异常时调用方可以
catch
其异常,
这样只有子事务回滚,父事务不受影响。
2024/5/10 12:04
stock
localhost:3000/print.html
33/178
MyBatis
1.
什么是
Mybatis
1.
半
ORM(
对象关系映射
)
程序员还要写
sql
,但是可以省掉加载驱动、创建连接创建
statement
及部分对象表映射。
2.
可以在
XML
或注解配置映射。
2. Mybatis
的优缺点
1.
优点
基于
SQL
语句,非常灵活,支持动态编写
sql
。
与
JDBC
相比,减少了不少代码
和数据库兼容性好
和
Spring
集成好
支持对象与数据库表映射
2.
缺点
SQL
编写工作量大
SQL
依赖于数据库,数据库移植性差。
3. Mybatis
中的
$
和
#
的区别
相同点是都能取到变量的值。
'$'
$
是直接进行字符串替换,一般是用于内部
sql
拼接。
'#'
#
可以实现预编译成?,在执行时再取值,可以防止
sql
注入。
4.
当实体类中的属性名与表中的字段名不一样时怎么办?
1.
在查询
sql
中使用别名,让别名和实体类的属性名一样。
2.
使用
resultMap
来定义映射关系。
2024/5/10 12:04
stock
localhost:3000/print.html
34/178
8. Mybatis
中的标签
1. select,insert,update,delete
2. resultMap
3. if, foreach, choose
4. where, set
5. sql, include
6. trim
10. Mybatis
是否支持延迟加载
支持,默认不开启。
lazyLoadingEnabled=true
原理: 使用
cglib
创建目标对象的代理对象,当调
用目标对象时进入拦截器
invoke
方法, 如果目标是
null
则调用,
11. Mybatis
的一级二级缓存
SalSession
的一级缓存 默认打开
flush
(增删改)和
close
会关掉缓存。
基于
namespace
和
Mapper
的作用域的二级缓存 默认关闭,打开
cacheEnable=true
在
Mapper
中添加标签
12. JDBC
编程有哪些步骤
1.
装载响应数据库的
JDBC
驱动并初始化
2.
建立
JDBC
和数据库之间的
Connection
连接
3.
创建
Statement
和
PrepareStatement Statement
PrepareStatement
Class.forName(
"com.mysql.jdbc.Driver"
);
Connection conn =
DriverManager.getConnection(
"jdbc:mysql://localhost:3306/temp?
serverTimezone=UTC"
,
"dev"
,
"123456"
);
String sql =
"select * from message"
;
Statement statement = conn.createStatement();
2024/5/10 12:04
stock
localhost:3000/print.html
35/178
1.
处理和显示结果
1.
关闭连接
Mybatis
配置文件
1.
加载
Mybatis
配置文件
2.
构建会话工厂
3.
创建
SqlSession
对象
4.
操作
Executor
执行器
5.
执行
Stattement
执行语句
6.
结果映射
String psql =
"select * from message where id < ?"
;
PreparedStatement preparedStatement = conn.prepareStatement(psql);
preparedStatement.setInt(
1
,
3
);
ResultSet resultSet = preparedStatement.executeQuery();
ResultSet resultSet = statement.executeQuery(sql);
while
(resultSet.next()) {
System.out.println(resultSet.getInt(
1
)+
" , "
+resultSet.getString(
2
));
}
conn.close();
2024/5/10 12:04
stock
localhost:3000/print.html
36/178
SpringBoot
1.
为什么要使用
SpringBoot
1.
简化配置
spring-boot-starter-web
启动器自动依赖其他组件,简化
maven
配置
2.
独立运行
可以内嵌各种
servlet
容器,一个
jar
包就可以独立运行
web
服务。
3.
自动配置
可以扫描
jar
包自动配置
bean
。
4.
应用监控
提供了一系列断点可以监控服务。
2. Spring Boot
核心注解
1. @SpringBootApplication
@SpringBootConfiguration
这个组合了
@Configuration
注解。
@EnableAutoConfiguration
打开自动配置功能,可以关闭指定的自动配置
@SpringBootApplication(exclude={DataSourceAutoConfiguration.class})
@ComponentScan
4. SpringBoot
自动配置原理
@SpringBootApplication
SpringBootConfiguration
EnableAutoConfiguration
ComponentScan
核心注解,它会引入
@Import(AutoConfigurationImportSelector.class),
他会加载并实例化
META-INFO
目录下的
spring.factories
文件中的各配置类,
这些配置类会使用
Conditional
系列注解。例如:
ConditionalOnClass
ConditionOnMissingBean
等注解实现条件实例化。
另外因为
starter
的
pom
文件会包含它的依赖。
所以结合起来就可以获得需要的
jar
包并根据需要实例化相关类,从而实现自动配置。
2024/5/10 12:04
stock
localhost:3000/print.html
37/178
8.
如何使用
Spring Boot
实现异常处理
我们可以使用
@ControllerAdvice
或
@RestControllerAdvice
注解来实现全局异常处理。 通过在被
这些注解修饰的类中使用
@ExceptionHandler
注解来实现对具体异常的处理,特别是可以传入具
体的异常类,这样就可以实现对不同的类使用不同的处理方式。
9.
配置文件加载顺序 优先级
1. properties
文件
2. yaml
文件
3.
系统环境变量
4.
命令行参数
xx.
过滤器和拦截器
1.
实现的接口不同
一个是实现了
javax
下的
Filter
接口,这是
j2ee
规范,另外一个是
Interceptor
接口,这是属于
Spring
框架内的定义。
2.
触发时机不同
Filter
刚在外一些,
Interceptor
更靠里。也就是说
Filter
先触达。
3.
初始化时机不同
初始化时机不同,
Filter
是跟随
Tomcat
容器启动而进行初始化。
Interceptor
是跟随
spring
容
器进行初始化。
两者都可以通过设置
order
来定义加载顺序,越小越早执行。
@RestControllerAdvice
public class
ExceptionProcessor
{
@ExceptionHandler({Exception.class})
public
Result<Exception>
handleException
(Exception e)
{
return
Result.ok(e, -
1
,
"
通用异常
"
);
}
@ExceptionHandler({BizException.class})
public
Result<BizException>
handleException
(BizException e)
{
return
Result.ok(e,e.getState(),e.getMessage());
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
38/178
Mysql
1.
三范式
1.
原子性
列不可再分
学生
课程
成绩
张三,男
语文
77
2.
唯一性
非主键列不能依赖联合主键的部分字段
学生
性别
课程
成绩
学分
张三
男
语文
77
2
将上述表拆分为下面的两个表:
学生
性别
课程
成绩
张三
男
语文
77
课程
成绩
学分
语文
77
2
3.
独立性
非主键列不能依赖于另一个非主键列
学生
性别
院系
院系电话
张三
男
计算机
010-88002200
2.
存储引擎
1.
什么是存储引擎?
处理存储数据,建立索引,更新、查询等技术的实现方法和代码实现。
2. Mysql
中有哪些存储引擎?
MyISAM
读快,不支持事务,只有表级锁。 不建议使用。
InnoDB(
缺省
)
事务,行级别锁和外键约束功能
Memory
只存在内存中,快。临时表多使用这个引擎。
MyISAM Merge
可以将几个
MyISAM
合并为一个虚表。
archive
只支持
select
和
insert
,不支持索引。
2024/5/10 12:04
stock
localhost:3000/print.html
39/178
存储引擎是基于表的,所以可以在创建表的时候指定存储引擎。
3.
查看系统支持哪些引擎
4.
数据库的事务
一组操作的集合,是一个不可分割的工作单元,这些操作要么同时成功,同时失败。事务具有
ACID
特性。
事务的特性:
原子性
(Atomic)
组成一个事务的多个数据库操作是一个不可分割的原子单元,只有所有操作都成功,整个事
务才会提交。任何一个操作失败,已经执行的任何操作都必须撤销。
一致性
(Consistency)
事务操作成功后,数据库所处的状态和它的业务规则是一致的。即数据不会被破坏。
隔离性
(Isolation)
并发操作时,不同事务拥有各自的数据空间,彼此不会打扰。
持久性
(Durability)
一旦事务提交成功,事务中的所有操作都必须持久化到数据库中。
5.
索引原理
索引是一种高效获取数据的有序数据结构。在数据之外,数据库还维护着满足 特定查找算法的数
据结构(
B+
树),
B+
树是多叉路平衡查找树,因此它会更矮些,另外非叶子节点只存储指针,只
有叶子节点存储数据,因此磁盘读写代价更低,它还便于扫库和区间查询,因为叶子节点是一个双
向链表。
索引分类
物理存储的角度
聚集索引(聚簇索引);二级索引
create table
test_myisam(
id
int
primary
key
auto_increment,
name
varchar
(
12
)
NOT
NULL
)
engine
= MyISAM;
create table
test_innodb(
id
int
primary
key
auto_increment,
name
varchar
(
12
)
NOT
null
);
show engines
;
2024/5/10 12:04
stock
localhost:3000/print.html
40/178
索引字段特性
主键索引;唯一索引;联合索引;前缀索引,空间索引
实现的数据结构分
B+
树索引、
hash
索引、
R-Tree
索引、
FULLTEXT
索引
15.
索引的优缺点
1.
优点:
提高检索速度,降低数据库
IO
成本。
降低数据排序成本,降低
CPU
消耗
2.
缺点:
占用存储空间,索引实际上也是一张表,记录了主键和索引字段,以索引文件的形式存储。
降低更新表的速度。
6. SQL
优化手段有哪些
0.
使用索引,避免全表扫描
1.
查询语句尽量不要使用
select *
2.
尽量减少子查询,使用关联查询语句替代。
3.
减少使用
IN
或
NOT IN
,使用
exists
、
not exits
或关联语句替代。
4. or
的查询尽量用
union
或
union all
代替。
5.
避免在
where
子句中时用
!=
或
<>
操作,否则引擎放弃使用索引而进行全表扫描。
6.
避免在
where
子句中对字段进行
null
值判断。否则将导致引擎放弃使用索引而进行全表扫
描。一般可以通过设置合理的缺省值来解决。
8.
什么是视图
视图是虚拟的表,它建立在已有表的基础上,视图赖以建立的这些表称为基表,视图的创建和 删
除只影响视图,不会影响基表,但是当对视图中的数据进行增加、删除和修改时基表中的数据也会
编号。
1,
减少回表。
2
,降低网络传输、数据处理开销。
2024/5/10 12:04
stock
localhost:3000/print.html
41/178
9.
什么是内连接、左外连接,右外连接
1.
内连接 匹配两张表中相关联的记录
2.
左外连接 除了匹配两张表中相关联的记录外,还会匹配左表中剩余记录,右表中未匹配到的
字段用
Null
表示。
3.
右外连接 除了匹配两张表中相关联的记录外,还会匹配右表中剩余的记录,未匹配到的记录
字段用
Null
表示。
左,右连接是要用小表驱动大表。原因是这样性能更好。
12.
大表如何优化
1.
限定数据的范围
禁止不带任何限制数据范围条件的查询语句。
2.
读写分离
3.
垂直分区 将一张列比较多的表拆分成多张表。
好处: 是可以使列数据变小,查询时减少读取的
Block
次数,减少
I/O
次数。
坏处:主键出现冗余,并会引起
join
操作。事务也不好解决。
4.
水平分区 保存表结构不变,通过某种策略存储数据分片,这样每一片数据分散到不同的表或
库中。
好处: 支持数据量非常大。
坏处:让逻辑处理、部署、运维都变的复杂,事务也不好处理 两种分区方案:
客户端分区
Sharding-JDBC
、
TDDL
服务端分区 阿里的
Mycat
、
360
的
Atlas
13.
分库分表后的主键怎么处理
Twitter
的
snowflake
算法
美团的
Leaf
分布式
ID
生成器
对数据库自增
ID
生成不同的步长。
CREATE VIEW
v_students
AS
SELECT id
,
name
,sex
FROM
student t
where id
<
901
;
2024/5/10 12:04
stock
localhost:3000/print.html
42/178
14.
查询
Sql
是如何执行的
1.
取得连接
2.
查询缓存,
key
为
sql
语句,
value
为查询结果(
8.0
已经去除该功能)。
3.
分析器,词法和语法分析。
4.
优化器,决定使用那个索引及表的链接顺序。
5.
执行器,先检查权限,通过则使用引擎的接口获取数据。
16. varchar
和
char
的区别
1. char
是固定长度类型,
varchar
是可变长度类型。
2.
对效率要求高用
char
,对空间要求高用
varchar
。
varchar
(
30
)中的
30
是什么意思
这里的
30
是代表最多存放
30
个字符,
varchar(30)
和
varchar(130)
存储
'hello'
占的空间一样,但是
后者在排序的时候消耗更多内存,因为
ORDER BY
采用的是定长计算列的长度。
26. Mysql
中的锁
共享锁(读锁)
排它锁(写锁)
行锁 并发高。
innoDB
支持行锁,但是行锁时基于索引的,所以在加锁时必须命中索引,否
则将使用表锁。
表锁
27.
说说什么是锁升级
1. Mysql
行锁只能加载索引上,如果操作不走索引,就会升级为表锁
2.
当非唯一索引上记录超过一定数量时,行锁也就会升级为表锁。测试发现非非遗索引相同的
内容超过二分之一时会升级为表锁。
29.
怎么避免死锁
1.
设置获取锁的超时时间,保证在最差的情况下可以退出。
2.
设置按照统一顺序访问资源。
2024/5/10 12:04
stock
localhost:3000/print.html
43/178
3.
保持事务简短并在一个批处理中。
4.
使用低隔离级别。
33.
主键和索引有什么区别
1.
主键一定会创建一个唯一索引,但有唯一索引的不一定是主键。
2.
主键不允许为空值,唯一索引允许空值。
3.
一个表只能有一个主键,但可以有多个唯一索引。
4.
主键可以被其他表引用为外键,唯一索引不可以。
补充
1. sql
执行顺序
书写顺序
执行顺序
on
会在生成临时表是起作用,
where
是在生成临时表后过滤
2.
聚集索引和二级索引
1.
聚集索引和二级索引
将数据与索引放到了一块,索引结构的叶子节点保存了行数据。
二级索引将数据和索引分开存储,索引结构的叶子节点关联的是对应的主键。
2.
覆盖索引
vs
回表查询
指查询使用了索引,并且需要返回的列在该索引中全部能够找到。
select
from
where
group by
having
order by
limit
from
where
group by
having
select
order by
limit
#
查看数据文件路径
show global variables like
'%datadir%'
2024/5/10 12:04
stock
localhost:3000/print.html
44/178
3.
索引失效情况
违反最左前缀法则
范围查询右边的列,不能使用索引
不能再索引的列上进行运算
字符串不做单引号,造成索引失效
模糊查询有可能导致索引失效,以
%
开头的模糊查询,索引失效
4.
索引创建原则
针对数据量大,且查询比较频繁的表建立索引(
>10
万
)
针对常作为查询条件、排序,分组操作的字段建立索引
选择区分度高的列作为索引
优先建立联合索引,减少单列索引
控制索引的数量
列添加
Not Null.
5.
数据库优化经验
1.
表的设计优化
设置合适的数值类型
设置合适的字符串类型
2. sql
语句优化
select
后避免
*
sql
避免造成索引失效的写法
尽量使用
union all
代替
union
避免在
where
子句中对字段进行表达式操作。
能用
inner join
就不要用
left
或
rightjoin
,如必须使用则要以小表驱动。
3.
主从复制、读写分离
4.
分库分表
6.
数据库事务
事务的定义: 一组操作,要么同时成功,要么同时失败,没有部分成功。
ACID
(原子性,一致
性,隔离性,持久性)
redo:
持久性
undo
: 原子和一致性
2024/5/10 12:04
stock
localhost:3000/print.html
45/178
并发事务问题
脏读
A
事务读到
B
事务没有提交的内容。
不可重复读
一个事务内读取两次,数据不一致。
幻读
查询时没有,但是插入时又发现有了。
解决方式是采用更严格的隔离级别。
隔离级别
脏读
不可重复读
幻读
读未提交
有
有
有
读已提交
无
有
有
可重复读
(
缺省
)
无
无
有
串行化
无
无
无
7. mvcc(
多版本并发控制
)
事务一
事务二
事务三
事务四
开始事务
开始事务
开始事务
开始事务
set age=3 where id=30
select where id=30
提交事务
隐藏字段
DB_TRX_ID
最近修改事务
ID
,记录插入或修改该记录的事务
ID DB_ROLL_PTR
回
滚指针,指向这条记录的上一个版本,用于配合
undo log
,指向上一个版本。
DB_ROW_ID
隐藏主键,如果表没有指定主键则使用它。
undo log
在
insert
,
update
,
delete
时产生的便于数据回滚的日志。 版本链,事务对同一条
记录修改,会导致该记录在
undo log
中生成一条记录版本链表。
read view ReadView
是快照读
SQL
执行时
MVCC
提取数据的依据。 当前读 读取的最新版本,
要保证其它并发事务不能修改当前记录,会对读取的记录进行加锁。 快照读,读取的记录数
据的可见版本,可能是历史数据。
ReadView
中有四个核心字段:
m_ids
当前活跃的事务
ID
集合
min_trx_id
当前最小的事务
ID max_trx_id
当前最大的事务
ID creator_trx_id
创建者的
事务
ID
不同的隔离级别,生成
ReadView
的时机不一样
2024/5/10 12:04
stock
localhost:3000/print.html
46/178
8.
全面优化
优化的哲学
不要过早优化!
###sql
处理流程:
优化的范围
存储、主机和操作系统方面 主机架构、
IO
规划、
OS
内核参数、网络
应用程序方面
SQL
语句性能
数据库优化方面 内存、数据库结构、实例配置
数据库层面
1.
应急调优思路
包含权限检查
执行计划
客户端
查询缓存
解析器
预处理器
查询优化器
执行引擎
2024/5/10 12:04
stock
localhost:3000/print.html
47/178
2.
常规调优思路
查看
slowlog
,分析找出查询慢的语句。
按照一定的优先级,进行一个一个的排查所有的慢语句
分析
top sql
,进行
explain
调试,
调整索引或语句本身
系统层面
1. cpu
vmstat
#
查询当前连接
show processlist;
#
查看某语句的执行计划
explain select id,name from test_innodb;
#
查看某表的索引
show index from test_innodb;
#
查看锁的状态
show status like '%lock%';
show variables like '%quer%';
select * from mysql.slow_log limit 1;
possible_keys
可能会使用到的索引
key
当前命中的索引
key_len
索引占用的大小
Extra
额外的优化建议
Using where; Using Index
使用了索引
Using index condition
使用了索引,需要回表查询
type
NULL
,没有使用表
system
, 使用内置表
const
,根据主键查询
eq_ref,
根据主键索引或唯一索引查询
ref
, 索引查询
range,
范围查询
index,
全索引,索引树
all,
全盘扫描
2024/5/10 12:04
stock
localhost:3000/print.html
48/178
top
ps -aux
2.
内存
3. IO
设备
iostat
9.
如何定位慢查询
Arthas
Skywalking
mysql
的慢日志查询
重新启动后会在
localhost-slow.log
中看到日志
proces(r/b)
r => ready
在运行队列中等待的进程数
b => block
在等待
I/O
的进程数
swap(si/so)
si => swap in
交换进
so => swap out
交换出
io(bi/bo)
bi => block in
读入的块
bo => block out
写入的块
cpu(us/sy/id/wa/st)
us => user
用户
sy => system
系统
id => idle
空闲
wa => waiting
等待
free
tps
该设备每秒传输次数
KB_read/s
每秒从设备读取的数据量
KB_wrtn/s
每秒向设备写入的数据量
#
慢查询日志会减慢查询。
#
开启
Mysql
慢日志查询开关
slow_query_log=1
#
设置慢日志的时间标准
long_query_time=2
2024/5/10 12:04
stock
localhost:3000/print.html
49/178
10.
如何分析解决慢查询
聚合查询
创建临时表
多表查询
优化
sql
结构
表数据量过大
添加索引 使用
explain/desc
查看执行计划
深度分页查询
11.
锁
1.
按照锁的粒度来分
行级锁
会死锁,并发度高
表级锁
不会死锁,开销小,并发度最低
页级锁
一次锁定相邻的一组记录
2.
按照锁的共享策略来分
共享锁
排它锁
意向共享锁
possible_keys
可能会使用到的索引
key
当前命中的索引
key_len
索引占用的大小
rows Mysql
估算会扫描的行数,数值越小越好
Extra
额外的优化建议
Using where; Using Index
使用了索引
Using index condition
使用了索引,需要回表查询
type
NULL
,没有使用表
system
, 使用内置表
const
,根据主键查询
eq_ref,
根据主键索引或唯一索引查询
(not null)
ref
, 索引查询
range,
范围查询
index,
全索引,索引树
all,
全盘扫描
select * from tb_user order by id limit x, y;
#
覆盖索引
+
子查询
select * from tb_user t, (select id from tb_user order by id limit x,y) where
t.id=a.id
2024/5/10 12:04
stock
localhost:3000/print.html
50/178
意向排它锁
意向锁是加行锁时添加到表上的锁,表名有锁在表上发生。
3.
按照加锁策略来分
悲观锁,认为修改一定会发生,不加锁一定会出问题。
乐观锁,认为修改不会发生,所以不加锁,一般在修改的时候判断。
12.
索引
帮助
Mysql
高效获取数据的数据结构,在数据之外,数据库系统还维护着满足特定 查找算法
的数据结构(
B+
树),这些数据结构以某种方式引用数据,这样可以 在这些数据结构上实现
高级查找算法,这种数据结构就是索引。
提高检索效率,降低
IO
成本
通过索引列对数据进行排序。
12.1
索引底层的数据结构
二叉树 退化成列表。
红黑树 数据量大时会导致层级太高。
B
树 多叉路平衡查找树
B+
树 与
B
树相比,非叶子节点不存储数据,只存储指针。
1.
磁盘读写代价
B+
树更低
2.
查询效率
B+
树更加稳定
3.
便于扫库和区间查询。
12.2
聚簇索引
->
聚集索引
代表问题:
什么是聚集索引,什么是二级索引。 聚集索引:将数据存储和索引放到了一块,索引结构的
叶子节点保存了行数据
二级索引:将数据和索引分开存储,索引结构的叶子节点关联的是对应的主键。
什么是回表 通过二级索引查找到对应的主键值,然后再在聚集索引中找到整行数据的过程叫
回表。
如果存在主键,主键索引就是聚集索引
如果不存在主键,则将第一个唯一索引作为聚集索引
如果没有主键和合适的唯一索引,则
InnoDB
自动生成一个
rowid
作为隐藏的聚集索引。
2024/5/10 12:04
stock
localhost:3000/print.html
51/178
12.3
覆盖索引
指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
id
name
gender
created
1
Arm
1
2022-12-01
2
Rose
2
2022-12-02
13.
创建索引原则
数据量大,且查询比较频繁的表建立索引
针对于常作为查询条件
(where)
,排序
(order by)
,分组
(group by)
操作的字段建立索引。
选择区分度高的列作为索引,尽量建立唯一索引,区分度越高效率越高。
如果是字符类型字段,且比较长,可以建立前缀索引。
尽量使用联合索引,
控制索引的数量,
如果索引列不能存储
NULL
值,则在创建时声明
NOT NULL
14.
什么情况下索引会失效
违反了最左前缀法则
范围查询右边的列,不能使用索引
在索引上做了运算操作
字符串不加单引号(发生类型转换),造成索引失效
以
%
开头的模糊查询,索引失效。尾部模糊不会失效。
15.
并发事务
并发事务的问题
脏读 一个事务读取到了另外一个事务未提交的修改。
#
select * from tb_user where id=1
#
select id,name from tb_user where name='Arm'
#
select id,name,gender from tb_user where name='Arm'
2024/5/10 12:04
stock
localhost:3000/print.html
52/178
不可重复读 一个事务先后读取同一条数据,但是两次读取的数据不同
(
另外一个事务有修改
且提交
)
幻读 按条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存
在。
解决这些问题
隔离级别
脏读
不可重复读
幻读
读未提交
Y
Y
Y
读已提交
X
Y
Y
可重复读
X
X
Y
串行化
X
X
X
undo log
和
redo log
redo log
保证了事务的持久性,
undo log
保证了事务的原子性和一致性。
redo log
在
update/delete
时,首先操作缓冲池,后期再同步到磁盘上(数据页)。 如果同步时发生错误,
就可以使用
redolog
恢复数据。
redolog Buffer -> redolog
undo log
回滚日志,用于记录数据被修改前的信息,作用有两个:回滚和
MVCC
。
当
delete
一条记录时,
undo log
中会记录一条对应的
insert
记录。
当
update
一条记录时,它记录一条相反的
update
记录。 这样当回滚时,就可以从
undo log
中读到相应的数据并进行回滚。
隔离性怎么保证
锁
如果一个事务获取了一个数据行的排它锁,其他事务就不能再获取改行的其它锁。
2024/5/10 12:04
stock
localhost:3000/print.html
53/178
mvcc
多版本并发控制
实现原理
隐藏字段
undo log
日志
undo log
的版本链,事务对同一条记录进行修改,会导致该记录的
undolog
生成一条记录版本 链
表,链表的头部是最新的记录,尾部是最早的旧记录。
readView
快照读
SQL
执行时
MVCC
提取当前数据的依据,记录并维护系统当前活跃的事务
id
集合。
1.
当前读 读取记录的最新版本,需要保证其他并发事务不能修改当前记录,会对读取的记录加
锁
2.
快照读 读取的是可见版本,根据事务隔离级别读到的数据不一定一样。
RC
读提交
RR
重复
读
16. Mysql
主从
核心是一个二进制日志,记录了所有
DDL
及
DML
语句
主库写数据到
binlog
中
从库读取
binlog
并写入
relay log
中。
从库重做中继日志中的数据,并写入数据库中
DB_TRX_ID
最近修改事务
ID
DB_ROLL_PTR
回滚指针,记录上一个版本(
undo log
日志)
DB_ROW_ID
如果没有指定主键,则生成该隐藏字段
在
insert
、
update
和
delete
时产生的便于回滚的日志
insert
日志可在事务提交后可以被立即删除。
undo
和
delete
在
MVCC
中也会使用,不会立即删除。
事务
ID
集合
最小事务
ID
最大事务
ID =
预分配事务
ID
ReadView
创建者事务
ID
select ... lock in share mode
select ... for update
update
insert
delete
2024/5/10 12:04
stock
localhost:3000/print.html
54/178
17.
分库分表
业务数据库逐渐增多,单表达到
1000
万或
20G
之后。 优化解决不了问题
IO
瓶颈,
CPU
瓶颈(聚合
查询,连接数太多)
垂直
分库 以表为依据,根据业务将不同表拆分到不同库中。 提高磁盘
IO
分表 以字段为依据,根据字段属性才分到不同表中。 将不常用的字段单独放 将
text,blog
等
字段拆分出来放。
水平
分库
分表
问题
分布式事务一致性问题
跨节点关联查询
跨节点分页,排序函数
主键避免重复 引入中间件;
mycat
sharding-sphere
冷热数据分离
减少
IO
争抢
2024/5/10 12:04
stock
localhost:3000/print.html
55/178
18. B
树
BST
(
Binary Search Tree
)二叉查找树。
查找过程落地到硬件上时:
2024/5/10 12:04
stock
localhost:3000/print.html
56/178
Mysql 8
新特性
1.
隐藏索引 用于优化时验证索引是否生效。
2.
设置持久化
3.
缺省
utf8mb4
编码
4. CTE
通用表表达式 让复杂
sql
更易懂一些。
5. rank()
窗口函数
6.
函数索引
SET PERSIST max_connection = 500;
2024/5/10 12:04
stock
localhost:3000/print.html
57/178
SpringCloud
2.
什么是微服务
微服务架构是一种架构风格,提倡将应用划分为一组小的服务,每个服务运行在独立的进程中,服
务之间相互协调配合,为用户提供最终价值。优势是在应用很大时可以将应用中的独立服务隔离出
来,形成高内聚低耦合的服务,各服务可以独立升级,并且可以采用不同语言。劣势是系统更加复
杂,维护更困难。
3. SpringCloud
有什么优势
微服务架构会引起新的复杂性,体现在:
1.
各微服务之间如何发现彼此。
2.
怎么解决负载均衡问题
3.
微服务调用因为网络引起的延迟,失败率高的问题。
4.
怎么解决请求路由问题。
5.
怎么发现请求链路中的问题点 以上这些微服务不可避免的问题都可以使用
springCloud
组件
来解决。
4.
什么是服务熔断?什么是服务降级?
1.
熔断是应对雪崩效应的一种微服务链路保护机制。
当服务调用失败率超过一定阈值时,切断对下游服务的调用,直接返回失败的情况。
2.
降级是指从整体负荷考虑,当被调用服务不可用时使用本地准备的一个
fallback
,返回缺省
值的策略
5. Eureka
和
zookeeper
都可以提供服务注册与发现功能,有什
么区别。
Eureka
采取了
AP(
高可用、分区容错性
)
策略,
Eureka
各节点平等,几个节点挂掉不影响剩余
节点的正常工作。
Zookeeper
采取了
CP(
一致性、分区容错性
)
策略。
zk
会因为网络故障导致节点失去联系时,
剩余节点会重新选
leader
,选取期间
zk
集群不可用且持续时间较长,这导致它不适合作为微
服务中的服务与注册服务提供者。
2024/5/10 12:04
stock
localhost:3000/print.html
58/178
8.
什么是
Hystrix
?怎么实现容错?
1. Hystrix
是
Spring Cloud
中的服务容错与降级组件。
2.
它会在请求失败超时或
Hystrix
处于熔断状态时返回事先准备的
fallback
方法中的内容,通过
这种手段避免错误在整个集群中蔓延从而形成雪崩。
x1. Nacos
的心跳机制
Nacos
提供了两种健康检查机制,这两种健康检查机制分别适用于两种不同的实例类型:
临时实例
临时实例时客户端主动上报,每
5s
发送一个心跳包给
Nacos
服务器端,服务器接收到心跳包
之后将健康状况同步到其他注册中心。
永久实例
永久实例时使用服务器反向探测的方式实现健康检查的,探测周期为
2s+
随机时间,如果检
查异常则标记为非健康实例, 反向探测缺省使用的
TCP
探测。(
HTTP/TCP/MYSQL
)
x2. Eureka
和
Nacos
的区别
1.
从功能上
Nacos = Eureka + Config
2.
从注册中心功能细节上讲
Nacos
区分临时实例和永久实例
Eureka
采用
AP
模式;
Nacos
集群默认采用
AP
模式,当有非
临时实例时采用
CP
模式;
连接方式不同
nacos
是使用的
netty
长链接,反映更迅速。
eureka
使用定时任务与服务端练
习。
Nacos
支持服务端探测和客户端上报心跳,
Eureka
只支持客户端上报心跳。
自我保护机制不一样
Nacos
是针对某个具体服务的,
Eureka
是针对所有服务的。
2024/5/10 12:04
stock
localhost:3000/print.html
59/178
Dubbo
2024/5/10 12:04
stock
localhost:3000/print.html
60/178
Nginx
1.
简述一下什么是
Nginx
Nginx
是一个
web
服务器和反向代理服务器,可以用于
HTTP
、
HTTPS
、
SMTP
、
POP3
及
IMAP
协
议。它有几个特点:
1.
更快,无论单次还是高并发情况下。
2.
高扩展性、跨平台。
3.
高可靠性。
4.
低内存消耗,
10000
个非活跃的
Keep-Alive
连接在
Nginx
中仅消耗
2.5M
内存。
5.
单机支持
10
万以上并发。
6.
热部署,
master
进程与
worker
进程分离设计,使得
Nginx
能够提供热部署功能。
7.
使用了
BSD
协议(允许免费使用、修改
Nginx
源代码并发布)。
2024/5/10 12:04
stock
localhost:3000/print.html
61/178
消息队列
1.
为什么要使用
MQ
1.
解耦 如果
A
系统发生的事件或产生的数据多个系统都需要,如果通过接口调用发送就会导致
系统之间严重耦合。使用
MQ
,
A
可以将数据直接发送到
MQ
里,需要的系统直接订阅这个消
息即可。
2.
异步 同上例,每一个远程调用
300
毫秒,当有
3
个系统需要被调用时,加上自己本身的处理时
间就需要有
1200
毫秒处理请求。
3.
消峰 可以将瞬间高峰熨平然后慢慢处理。
2. MQ
的缺点
1.
系统的可用性降低
系统引入的外部依赖越多,越容易出现问题。
2.
复杂度提高
代码复杂,也会引入新的问题,例如: 消息丢失问题,消息重复消费问题。
3.
一致性问题
部分消费者成功,部分消费者失败。
5.
消息丢失
RocketMQ
1.
生产者 自动重试机制(同步、异步)
+
多个
Master
节点
+
失败日志。
2.
消息队列服务器
同步刷盘
集群部署
3.
消费者
关闭自动确认,消费者业务逻辑处理完成后再进行
ack
确认。
flushDiskType =
SYNC_FLUSH
brokerRole=
SYNC_MASTER
2024/5/10 12:04
stock
localhost:3000/print.html
62/178
CommitLog & ConsumeQueue
CommitLog
RocketMQ
的所有消息都存储在一个称为
CommitLog
文件中,默认最大文件为
1GB
。消息以
顺序的方式写入。
ConsumeQueue
一个
ConsumeQueue
表示一个
topic
的
queue
,其中只存储消息在
CommitLog
中的偏移量
(offset)
、消息的大小及消息所属的
tag
的
hash
。
7.
几百万消息积压怎么办?
1.
紧急临时扩容
新建
topic
,分区
(partition)
和队列(
queue
)均设置为原来的
10
倍,然后写一个临时的分发
程序,消费原来积压的数据并直接写到新建的
topic
中。
2.
修复问题并恢复
修复
consumer
的问题,并临时征用
10
倍机器部署
consumer
,每个
consumer
消费一个临时
queue
的数据。消费完成后恢复原来的架构。
8.
如果让你来设计一个消息队列,你会怎么设计。
1.
消息队列要支持伸缩性
设计为
broker->topic->partion->queue
2.
数据要落盘
写的时候顺序写,提升速度。
3.
高可用。
主从多副本
x1. zookeeper
对
kafka
的作用
kafka
是一个分布式应用,各元素之间需要协调,
zookeeper
就是服务于这个集群的协调的。
1. leader
选举
2. broker
,
topic,
消费者注册
3.
消费者消费进度
4.
生产者、消费者负载均匀
5.
分区和消费者的关系
2024/5/10 12:04
stock
localhost:3000/print.html
63/178
Linux
x1.
常用命令
#
ps
命令
ps -aux
ps -aux | grep <str>
#
查看当前系统负载
top
#
强制杀掉进程
kill -9 <pid>
#
安全杀掉进程
kill -15 <pid>
#
查看当前目录
pwd
#
查看文件
#
显示全部文件
cat <file>
#
分页显示文件
more <file>
#
分页显示文件,可以向前翻页
less <file>
#
查看文件尾部
tail <file>
#
查看文件头部
head <file>
#
查看文件列表
ls -l
#
不忽略以
.
开头的文件
ls -a
#
创建目录
mkdir
#
删除目录
rmdir
#
打包
tar -zvf <path>
#
解压
tar -xvf <x.zip>
2024/5/10 12:04
stock
localhost:3000/print.html
64/178
x2.
系统调优相关
#
查看磁盘占用状态
df -h
#
查看各文件大小
du -sh *
#
查看
cpu
占用高
top
#
查找
cpu
占用高的线程
top -Hp pid
#
将
tid
转换为十六进制
printf '%x\n' 3816
#
用于
jstack
中查找
jstack pid | grep tid -A 30
2024/5/10 12:04
stock
localhost:3000/print.html
65/178
ZooKeeper
忽略
2024/5/10 12:04
stock
localhost:3000/print.html
66/178
Redis
1.
为什么要用
Redis
1.
缓存数据 提升系统的读性能,支持更高的并发量。
2.
作为分布式锁
2.
为什么
Redis
单线程效率也能那么高。
1.
纯内存操作
2. C
语言实现,效率高
3.
基于非阻塞的
IO
复用模型机制
4.
单线程的话能避免多线程频繁的上下文切换问题
5.
丰富的数据结构
8. Redis
同步机制
如果是第一次进行主从同步,主节点需要使用
bgsave
命令,再将后续修改操作记录到内存的缓冲
区,等
RDB
文件全部同步到复制节点,复制节点将
TDB
镜像加载到内存中。等加载完成后,复制节
点通知主节点将复制期间修改的操作记录同步到复制节点,即可完成同步过程。
10.
说一下
Redis
有什么优点和缺点
1.
优点
速度快
支持丰富的数据结构
持久化存储
高可用 内置
Redis Sentinel
, 提供高可用方案,实现主从故障自动转移。 内置
Redis
Cluster
,实现基于槽的分片方案,从而支持更大的
Redis
规模
丰富的特性
key
过期、计数,分布式锁、消息队列
2.
缺点
由于
Redis
基于内存数据库,所以存储的数据规模受限。
重启时间可能比较久。
2024/5/10 12:04
stock
localhost:3000/print.html
67/178
11. Redis
的缓存刷新策略有哪些
12. Redis
持久化方式有哪些?
1. RDB
是指用数据集快照的方式持久化记录。好处是:
只有一个文件
dump.rdb
新能最大化,
fork
子进程来完成写操作,主进程继续处理命令。
相对于数据集大时,比
AOF
启动效率高。
缺点是:
数据安全性低,
RDB
是间隔一段时间进行持久化,所以可能发生数据丢失。
2. AOF
AOF
是指所有命令行记录以
Redis
命令请求协议格式完全持久化存储。
数据安全,
AOF
持久化可以可以配置
appendfsync
,设置为
always
可以即时写入命令。
通过
append
模式,即使中途服务器宕机,也可以通过
redis-check-aof
工具解决数据一致性
问题。
AOF
的
rewrite
模式,可以压缩文件大小
缺点有:
文件比较大
数据集大时比
RDB
启动效率低 两种持久化都开启的情况下,
Redis
优先使用
AOF
方式构建数
据。因为
AOF
数据更为完整。
Redis
刷新策略
LRU
LFU
超时删除
主动更新
2024/5/10 12:04
stock
localhost:3000/print.html
68/178
14.
怎么使用
Redis
实现消息队列
一般使用
list
结构作为队列,
rpush
生产消息,
lpop
消费消息,当
lpop
没有消息的时候,要适当
sleep
一会儿再试,也可以使用
blpop
,它会阻塞直到消息到来。另外如果要有多个消费者,可以
使用
pub/sub
模式,但是
pub/sub
模式会在消费者下线的情况下丢失消息。
消息队列参考
15.
对
Redis
事务的理解
Redis
中的事务和数据库中的事务不同,它仅意味着属于一个事务的命令会作为一个最小的执行单
位执行,它保证事务中的命令会按顺序运行,并且在执行的过程中不会被其他客户端发来的命令请
求打断。但是需要注意:它不支持回滚。
17.
什么是
bigkey
,存在什么影响。
bigkey
是指键值占用内存空间比较大的
key
。它有如下影响:
1.
读取
bigkey
时因为传输数据量大,会造成网络阻塞。
2.
因为占用空间较大,操作起来效率也比较低。
3.
造成内存空间不平衡。
18. Redis
的集群模式
主从复制
写主读从,全量同步
主从增量同步
1. slaver
执行
replicaof (replid.offset)
请求数据同步。
2,
判断是否是第一次。是第一次则传回数据版本信息。
3,slaver
保存版本信息。
4,
执行
bgsave
,生成
RDB
,
5
,发送
RDB
,
6
,
slaver
清空本地数据,加载
RDB
文件
7,
记录
RDB
期间的所有命令,发送记录的命令
8,
执行接收到的命令
2024/5/10 12:04
stock
localhost:3000/print.html
69/178
哨兵模式
主从保证不了高可用,为了保证高可用,引入了哨兵模式
脑裂
redis
中有两个配置参数
分片集群
海量数据和高并发解决。通过使用将
16384
个哈希槽分配到集群中的实例来实现。
23. Redis
常见性能问题和解决方案
1. Master
最好不要做持久化工作
2.
如果数据比较重要,则让某个
Slave
开启
AOF
备份数据。
1. slave
重启
(psync replid offset)
2.
不是第一次,回复
continue
3,
去
repl_baklog
中获取
offset
后的数据
4,
发送
offset
后的命令
5
,
slaver
执行命令
1,
监控:
sentinel
会不断检查您的
master
和
slave
。
每隔一秒向集群中每个实例发送
ping
命令,如果没有回应则认为下线。
如果超过指定数量的
sentinel
都认为该实例主观下线,则认为该实例客观下线。
2
,自动故障回复:
如果
master
故障,
sentinl
会将一个
slave
提升为
master
3
,通知:
sentinel
充当
Redis
客户端的服务来源,当集群发生故障时通知
RedisClient
。
1,
因为网络分区,导致产生了两个主节点。
2
,老的主节点继续接收数据。
3
,网络恢复,老的主节点降级为从节点。
4
,老的主节点丢弃老的数据,从主节点拉取数据。
#
最少的
slave
节点为一个
min-replicas-to-write 1
#
数据复制和同步的延迟不能超过
5
秒
min-replicas-max-lag 5
对
key
使用
CRC
算法然后取模,然后就匹配到不同的实例上,其中可以使用
{}
确定
做哈希的部分。
2024/5/10 12:04
stock
localhost:3000/print.html
70/178
3.
主从最好在一个局域网内。
24. Redis
中有
1
亿个
key
,如何找出部分固定的已知的前缀开头
的内容。
1. keys
会引起
Redis
停顿,一般不建议。
2. scan
命令 不会阻塞线程,但是数据可能存在重复。
26.
什么情况下会造成
Redis
阻塞
1.
内部原因
Redis
主机负载过高
数据持久化资源过多
对
Redis
的指令不合理,例如
keys
命令
2.
外部原因
例如服务器的
CPU
线程在切换过程中竞争过大。
内存出现问题
网络问题
28.
怎么提高缓存的命中率
1.
提前加载数据到缓存中。
2.
增加缓存的存储空间。
3.
提升缓存的更新频率。
30. Redis
报内存不足怎么处理。
1.
修改
redis.conf
的
maxmemory
参数,增加
Redis
可用内存。
2.
设置缓存淘汰策略,提高内存使用效率
3.
使用
Redis
集群模式,提高存储量。
2024/5/10 12:04
stock
localhost:3000/print.html
71/178
32.
使用场景
遇到某些情况
1.
穿透
查询一个不存在的数据,
mysql
查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
解决方案
缓存空数据
布隆过滤器 缓存预热时,也预热布隆过滤器
2.
击穿
给某一个
key
设置了过期时间,当
key
过期的时候,恰好这时间点对这个
key
有大量的并发请求过
来,这些并发的请求可能会瞬间把
DB
压垮
解决方案
互斥锁 抢到互斥锁,没抢到则休眠
逻辑过期 抢到互斥锁则新开线程去读取数据,然后返回
雪崩
缓存雪崩是指在同一时段大量的缓存
key
同时失效或者
Redis
服务宕机,导致大量请求到达数据
库,带来巨大压力。
解决方案
给不同的
key
的
TTL
添加随机值 (同时过期的情况下)
使用
Redis
集群提交服务的可用性
(redis
宕机
)
哨兵模式;集群模式
添加限流降级策略
使用多级缓存
guava
;
37.
过期策略及内存淘汰机制
两种策略同时使用。
2024/5/10 12:04
stock
localhost:3000/print.html
72/178
惰性删除 读取的时候再判断是否过期
定期删除 每隔一段时间(默认
100ms
一次),就对一些
key
进行检查,短时间检查过期
淘汰策略
无论是定期删除还是惰性删除,都会存在
key
没有被删除掉的场景,所以需要内存淘汰策略作为补
充。
1.
不删除,直接报错
noeviction
不淘汰。内存使用超过配置时,直接返回错误。
2.
删除马上要过期的键
volatile-ttl
对设置了
ttl
的,越小越早删除
3.
随机删除
allkeys-random
全体随机
volatile-random
对
ttl
的可以随机删除
4.
最近最少使用
allkeys-lru
加入键的时候,如果过限,首先使用
LRU
算法驱逐最久没有使用的键。
volatile-lru
最近最少使用
5.
删除使用频率最低
allkeys-lfu
volatile-lfu
最近频率最少的删除
使用场景:
allkeys-lru
有明显的冷热区分,缺省使用这个。
allkeys-random,
没有明显的冷热区分
volatile-lru
,置顶需求,置顶数据不设置过期时间。
lfu
短时高频数据请求
38. Redis
为什么是单线程的
因为
Redis
是基于内存的操作,所以
CPU
不会是
Redis
的瓶颈。使用单线程容易实现还可以避免不必
要的上下文切换。
2024/5/10 12:04
stock
localhost:3000/print.html
73/178
41. Redis
事务命令
1. MULTI
命令开启一个事务
2. EXEC
执行事务块内的所有命令
3.
调用
DISCARD
客户端可以清空事务队列,并放弃执行事务。
4. WATCH
命令可以为
Redis
事务提供
CAS
行为,可以监控一个或多个键,一旦其中有被修改,
之后的事务就不会执行。
42.
数据类型及使用场景
string
value
可以是
String
也可以是数字,可以做一些复杂的计数功能。
list
可以做简单的消息队列和分页功能
(lrange)
。
set
因为
set
存放的是一堆不重复值的集合,因此可以做全局去重功能。另外可以利用交集、并
集、差集功能计算类似共同喜好、全部喜好、独有喜好等功能。
zset
实现类似排行榜或延时任务等功能。
Hash
value
存放的是结构化对象。
双写一致性
修改了数据库的数据同时也要更新缓存的数据,保持两者一致。 先介绍业务场景
一致性要求高
允许延迟一致
//
放入
redisTemplate.opsForZSet().add(name,obj,time);
//
取出
redisTemplate.opsForZSet().rangeByScore(name,
0
,time,offset,count);
加上分布式锁;性能优化可以使用读写锁
延时双删,
MQ
,
cannal
2024/5/10 12:04
stock
localhost:3000/print.html
74/178
其他
1.
分布式锁
集群情况下的定时任务、抢单、幂等性场景
1. setNx
2. redisson
可重入意思是同一个线程是否可以再次获得这个锁,不能解决主从不一致问题
watchdog
while
尝试抢到锁
3. red lock
要获得锁需要在多数节点上都写成功才能进行。 如果非要保证强一致性,可以使用
zookeeper
,因为
zookeeper
是
cp
型的
给锁续期
2024/5/10 12:04
stock
localhost:3000/print.html
75/178
分布式
1.
如何实现幂等
1.
创建唯一索引
2. token
机制
前端在提交数据前一步骤向服务器申请
token
,校验
token
后操作才能进行,并同时删除
token
。
3.
悲观锁
4.
乐观锁
5.
分布式锁
使用
Redis
,
Zookeeper
实现。
6.
保底
操作前先查询是否存在此数据。
2. HTTP
请求
1. Http
请求流程
select id
,
name from
table_x
where id
=
''
for update
update table_x set name=#{name},version=version+1 where version=#{version}
2024/5/10 12:04
stock
localhost:3000/print.html
76/178
2. TCP
包格式
用户
浏览器
DNS
服务器
输入域名并确认
查询
baidu.com
的
IP
(会有查询缓存的步骤)
返回
IP
地址
组装
HTTP
数据
打包成
TCP
数据
三次握手,建立连接
IP
包
链路层数据
接收并解包
四次握手,关闭连接
渲染页面
用户
浏览器
DNS
服务器
2024/5/10 12:04
stock
localhost:3000/print.html
77/178
3. TCP
三次握手
为什么要三次握手?
确认连接意愿
确认连接能力
#
可以防止客户端建立连接请求被延迟导致的问题
客户端: 我要连接
服务端: 你要连接?
客户端: 我确实要连接!
2024/5/10 12:04
stock
localhost:3000/print.html
78/178
4. TCP
四次挥手
TCP
是全双工连接,关闭连接时需要双方都确认关闭,以客户端关闭连接为例:
客户端
服务端
发送连接请求
-
证明客户端发送能力
发送确认并请求连接
-
证明服务端接收能力
发送确认
-
证明服务端发送能力;证明客户端接收能力
客户端
服务端
2024/5/10 12:04
stock
localhost:3000/print.html
79/178
客户端请求关闭
服务端确认关闭
服务端请求关闭
客户端确认关闭
3.
说说你对分布式事务的了解
1. ACID
原子性
(Atomicity)
一致性
(Consistency)
隔离性
(Isolation)
持久性
(Durability)
2. CAP
指在一个分布式系统中的一致性、可用性和分区容忍性,
CAP
理论指的是这三个要素最
多只能同时实现两点,不可能三者兼顾。
一致性 在分布式系统中的所有数据备份,在同一时刻是否是同样的值
2024/5/10 12:04
stock
localhost:3000/print.html
80/178
可用性 在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求
分区容忍性 以实际效果而言,分区相当于对通信的时限要求,如果系统不能再时限内达成数
据一致,就认为是发生了分区。
3. BASE BASE
理论是对
CAP
的一致性和可用性进行权衡的结果,核心就是:我们无法做到强一
致,但是各应用可以根据自身的业务特点,采用适当的方式使系统达到最终一致性。
BA Basically Available
基本可用
S Soft state
软状态
E Eventually consistent
最终一致性
4.
你知道哪些分布式事务解决方案
1.
两阶段提交
(2PC)
2.
三阶段提交
(3PC)
3.
补偿事务
(TCC = Try - Confirm - Cancle)
4.
本地消息列表
(MQ)
5. Sagas
事务模型
(
最终一致性
)
2024/5/10 12:04
stock
localhost:3000/print.html
81/178
5.
二阶段提交
优点:
强一致,适合数据强一致性很高的关键领域
问题:
1.
性能问题
参与者在提交阶段处于同步阻塞状态,占用系统资源。
2.
可靠性问题
协调者存在单点故障问题,出现故障会导致参与者一直处于锁定状态。
3.
数据一致性问题
如果协调者和参与者挂掉,可能会导致数据不一致。
协调者
参与者
A
参与者
B
请求提交
执行事务操作并回答
yes
请求提交
执行事务操作并回答
yes
提交
/
回滚
ACK
提交
/
回滚
ACK
协调者
参与者
A
参与者
B
2024/5/10 12:04
stock
localhost:3000/print.html
82/178
AT
模式
增强
2PC
,
6.
三阶段提交
协调者
参与者
A
参与者
B
可以提交
(CanCommit)
?
根据自身情况回答
-yes
可以提交
(CanCommit)
?
根据自身情况回答
-yes
预提交
(PreCommit)
执行事务并回答
-ACK
预提交
(PreCommit)
执行事务并回答
-ACK
提交
(DoCommit)
ACK
提交
(DoCommit)
ACK
协调者
参与者
A
参与者
B
2024/5/10 12:04
stock
localhost:3000/print.html
83/178
与
2PC
的区别:
1.
多了一个
canCommit
阶段,减少了不必要的资源浪费。
2PC
在第一步就要占用资源,而
3PC
这一步只是校验下是否可以执行,不占用资源。
2.
在参与者中引入超时机制
2PC
阶段只有协调者有超时机制,超时后发送回滚指令,
3PC
协调
者和参与者都有超时机制
协调者超时
canCommit,preCommit
中,如果收不到参与这的反馈,则发送中断指令
参与者超时
preCommit
阶段超时,参与者中断;
doCommit
阶段,参与者提交。
7.
补偿事务(
TCC
)
通过引入补偿机制,而不是锁定资源,可以提高并发量。
TCC
就是
Try
,
Confirm
和
Cancel
操作。
以转账为例说明:
1. Try Try
阶段主要是对业务系统做检测及资源预留。
2. Confirm
对业务系统确认提交。
3. Cancel
在业务执行错误时,执行回滚机制 以老王向老田转账为例:
优点
1.
性能提升 锁粒度变小。
2.
数据最终一致性 基于
Confirm
和
Cancel
的幂等性,保证事务最终完成确认
3.
可靠性
缺点
业务耦合度高,开发成本高。
1. Try
冻结老王和老田的钱。
2. Confirm
调用转账操作。
3. Cancel
失败则进行解冻操作。
2024/5/10 12:04
stock
localhost:3000/print.html
84/178
8.
消息队列是怎么实现的
9. Sagas
事务模型
是一种分布式异步事务,一种最终一致性事务。比较流行的两种方式是:
1.
事件 每个服务执行成功或失败都会发送一个消息,消息接收者,根据消息进行提交或回滚操
作。
特点
实现简单,容易理解,适合事务步骤不多的情况,如果步骤太多就容易混乱。
2.
命令模式 引
入
Saga
协调器(
OSO
),由
OSO
向事务中的参与者发送命令来驱动事务。
OSO
需要知道
“
创建订
单
”
事务所需的流程。
优点
避免服务之间的循环依赖关系。参与者只需要执行命令和回复,降低参
与者的复杂性。
10.
分布式
ID
生成方案
1.
分布式
ID
特性:
唯一性 确保全网唯一
有序递增 对于某业务是按照一定数字有序递增
高可用 确保任何时候都能正确生成
ID
带时间
ID
包含时间,
2.
分布式
ID
方案
ORDER_CREATED
BILL_ORDERED
ORDER_PREPARED
ORDER_DELIVERD
订单服务
支付服务
库存服务
货运服务
2024/5/10 12:04
stock
localhost:3000/print.html
85/178
雪花算法介绍
1
位符号位
41
位时间戳
10
位数据机器位
12
位毫秒内的序列
13.
限流算法
1.
计数器算法(固定窗口) 使用计数器在周期内累加访问次数,到达限流值时,触发限流策
略。下一周期开始重新计数。
临界问题,在前一周期末尾和后一周期起始这一段时间内,负
载可能会超负荷
2.
滑动窗口 将时间周期分为
N
个小周期,分别记录每个小周期的访问次数,并根据时间逐步删
除过期的小周期
3.
漏桶算法 是访问到达时直接放入漏桶,如当前容量已达到上限,则进行丢失。漏桶以固定的
速率进行释放访问请求。直至漏桶为空。
4.
令牌桶算法 算法以固定速率放入令牌桶中,直至令牌桶满,请求到达时向令牌桶请求令牌,
若获取到令牌则通过请求,否则触发限流策略。
依赖
Redis
依赖数据库
需独立部署数据库
无序
分布式
ID
生成方案
雪花算法
美团
Leaf
Redis.incr
批量生成
ID
数据库自增
ID
UUID
2024/5/10 12:04
stock
localhost:3000/print.html
86/178
14.
数据库如何处理海量数据
1.
分库分表
垂直
水平
2.
主从架构,读写分离
2024/5/10 12:04
stock
localhost:3000/print.html
87/178
网络篇
1. HTTP
响应码
200
301
永久重定向
302
临时重定向
400
客户端请求错误,多为参数不合法
404
找不到
500
服务端错误
502
网关错误,
Nginx
不能访问后端应用
503
服务不可用,停机
504
网关超时
4. TCP
和
UDP
的区别
1. TCP
是面向连接,
UDP
是无连接。
2. TCP
提供可靠的服务,
UDP
尽最大努力交付。
tcp
通过校验和,重传控制,序号标识,滑动窗
口,确认应答实现可靠传输。
3. UDP
具有较好的实时性,工作效率比
TCP
高。 适用于高速传输和实时性要求较高的场景。
4. TCP
是点对点,
UDP
支持一对一,一对多。
5. TCP
对系统资源要求多,
UDP
对系统资源要求少。
6. HTTP
,
TCP
,
Socket
的关系是怎样的
1. TCP/IP
代表传输控制协议
/
网际协议,指的是协议簇
2. HTTP
是超文本传输协议,是服务器和浏览器之间的文本传输协议。
3. Socket
是
TCP/IP
的网络的
API
,它是一个门面模式。
7. HTTP
的长连接和短连接
短连接:
HTTP/1.0
模认是使用短连接。获取数据就断开。 长连接:
HTTP/1.1
默认使用长连接。
2024/5/10 12:04
stock
localhost:3000/print.html
88/178
8. TCP
为什么要三次握手
需要确认客户端和服务端的序列号。
10. TCP
如何保证可靠性
1.
序列号和确认号机制:
TCP
发送端发送数据包时会选择一个
seq
序列号,接收端收到数据包
后会检测,通过后会确认。
2.
超时重发机制:
TCP
发送端发送数据后会启动定时器,一定时间没有收到接收端的确认会重
新发送该数据包。
3.
对乱序数据包重新排序
IP
网络层传输到
TCP
的数据可能会乱序,
TCP
会对数据包重新排序后
再发给应用层。
4.
丢弃重复数据
IP
发送给
TCP
的数据包可能会重复,
TCP
会丢弃重复的数据包。
5.
流量控制
TCP
发送端和接收端都有一个固定大小的缓冲空间,发送和接收端之间会通过流浪
控制协议沟通防止接收端缓冲区溢出。
11. OSI
的七层模型
1.
应用层 负责为用户提供各种应用服务。
HTTP,FTP
等。
2.
表示层 负责数据格式的转换、加密解密,压缩和解压缩等功能,确保格式兼容。
3.
会话层 负责建立、管理和终止会话连接,提供会话控制和同步功能。
SSL
,
TLS(
升级版
SSL)
4.
传输层 负责在源节点和目标节点之间简历可靠的端到端通信,提供流量控制、拥塞控制等功
能,常见的协议有
TCP
和
UDP
。
5.
网络层 负责为数据包选择合适的路径,并进行逻辑地址转发,实现节点间通信。
6.
数据链路层 负责在直接相连的节点间传输数据帧,提供了错误检测和纠正、传输控制和帧同
步等功能。
7.
物理层 机械、电子通信信道上的原始比特流传输,关注物理介质、电压等细节。
13.
如何实现跨域
1. JSONP
方式
script/img/iframe/linke/video/audio
等标签的
src
可以实现跨域。
2. CORS
方式 需要浏览器和服务器协同支持。
3.
代理方式 跨域限制是浏览器的同源策略限制,所以可以通过代理服务器来解决。一般前端项
目开发中会配置
,
例如在
vue.config.js
中
2024/5/10 12:04
stock
localhost:3000/print.html
89/178
27. IP
地址分为几类
1.
公共地址
2.
私有地址
3. 0.0.0.0
路由器全转发
/
本机所有
ip
4. 127.x.x.x
保留做本地回环地址
5. 255.255.255.255
局域网广播。
devServer: {
host:
'0.0.0.0'
,
port: port,
open:
true
,
proxy: {
// detail: https://cli.vuejs.org/config/#devserver-proxy
[process.env.VUE_APP_BASE_API]: {
target:
`http://localhost:8080`
,
changeOrigin:
true
,
pathRewrite: {
[
'^'
+ process.env.VUE_APP_BASE_API]:
''
}
}
},
disableHostCheck:
true
},
10.0.0.0
~
10.255.255.255
172.16.0.0
~
172.31.255.255
192.168.0.0
~
192.168.255.255
2024/5/10 12:04
stock
localhost:3000/print.html
90/178
2024/5/10 12:04
stock
localhost:3000/print.html
91/178
设计模式
2024/5/10 12:04
stock
localhost:3000/print.html
92/178
设计模式
创建型
单例模式
原型模式
工厂方法
抽象工厂
建造者模式
结构型
代理模式
适配器模式
门面模式
/
外观模式
行为型
责任链模式
策略模式
迭代器模式
状态模式
2024/5/10 12:04
stock
localhost:3000/print.html
93/178
1.
单例模式
单例模式保证在整个系统中只能使用一个对象实例,可以节省系统资源。
1.
饿汉式
2.
懒汉式
3.
双检锁
class
Singleton
{
//
私有化构造器
private
Singleton
()
{
}
//
内部创建对象实例
private final static
Singleton instance =
new
Singleton();
//
对外公有的静态方法
public static
Singleton
getInstance
()
{
return
instance;
}
}
class
Singleton
{
//
线程不安全
private static
Singleton instance;
private
Singleton
()
{}
public static
Singleton
getInstance
()
{
//
调用时才实例化对象,懒汉式
if
(instance ==
null
) {
instance =
new
Singleton();
}
return
instance;
}
}
class
Singleton
{
//
双重检查
private static volatile
Singleton instance;
private
Singleton
()
{}
public static
Singleton
getInstance
()
{
if
(instance ==
null
) {
//
判断是否实例化
synchronized
(Singleton.class) {
if
(instance ==
null
) {
instance =
new
Singleton();
}
}
}
return
instance;
//
否则直接
return
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
94/178
2.
代理模式
代理模式是指由
A
对象代替
B
对象与外界交互,
A
收到外界请求后转交给
B
处理。
AOP
3.
工厂模式
工厂模式
=
简单工厂模式
=
静态工厂方法模式
4.
抽象工厂模式
工厂的工厂。通过简单工厂模式获得工厂,这个工厂负责生产具体的产品。
public class
ShapeFactory
{
//
使用
getShape
方法获取形状类型的对象
public
Shape
getShape
(String shapeType)
{
if
(shapeType ==
null
){
return null
;
}
if
(shapeType.equalsIgnoreCase(
"CIRCLE"
)){
return new
Circle();
}
else if
(shapeType.equalsIgnoreCase(
"RECTANGLE"
)){
return new
Rectangle();
}
else if
(shapeType.equalsIgnoreCase(
"SQUARE"
)){
return new
Square();
}
return null
;
}
}
public class
Circle
implements
Shape
{
@Override
public void
draw
()
{
System.out.println(
"Inside Circle::draw() method."
);
}
}
public interface
Shape
{
void
draw
()
;
}
2024/5/10 12:04
stock
localhost:3000/print.html
95/178
5.
装饰器模式
动态的给一个对象增加一些额外的功能,同时不改变其结构。
装饰器和代理实现上很类似,区别在于代理模式重在对被代理对象的控制或保护;装饰器重在功能
的加强。
7.
模板方法
定一个一个算法骨架,将具体内容延迟到子类中去实现。
11.
责任链模式
行为设计模式,将链中的每一个节点看做一个对象,每个对象负责处理单一职责,整体组成一个复
杂的处理。
Filter
、
Interceptor
、
Mybatis
插件机制
12.
适配器模式
通过将一个类的接口变成客户端所期望的另一种接口,从而使得原来因为接口不匹配而无法一起工
作的两个类能够一起工作。
public class
FactoryProducer
{
public static
AbstractFactory
getFactory
(String choice)
{
if
(choice.equalsIgnoreCase(
"SHAPE"
)){
return new
ShapeFactory();
}
else if
(choice.equalsIgnoreCase(
"COLOR"
)){
return new
ColorFactory();
}
return null
;
}
}
request -->
是否已登录
-->
记录日志
-->
访问频次限制
-->
业务逻辑处理
2024/5/10 12:04
stock
localhost:3000/print.html
96/178
13.
观察者模式
定义对象间的一对多依赖关系,使得当一个对象发生改变时,与其相关的依赖对象得到通知。又名
发布订阅模式,监听器模式。
优点
解耦,易扩展。
2024/5/10 12:04
stock
localhost:3000/print.html
97/178
maven
2. maven
能为我们解决什么问题?
1.
解决了包之间的依赖关系。
2.
方便的获取到第三方包。
3.
方便对项目进行管理。 支持将项目分为多个工程模块。
8.
如何解决依赖传递引起的版本冲突
<dependency>
<exclusions>
<exclusion>
</exclusion>
</exclusions>
</dependency>
2024/5/10 12:04
stock
localhost:3000/print.html
98/178
ElasticSearch
1.
什么是倒排索引
1.
分词 将句子分成一个个的单词。
2.
倒排索引 倒排索引就是根据词找文档。
7. ElasticSearch
深翻页的问题
因为检索时,
ES
需要轮询所有分片,然后汇集数据,根据
TF-IDF
算法打分,排序后将前
10
条数据
返回。这样会比较耗时间。
ES
使用
index.max_result_window:10000
作为保护措施,防止
from+size
大过
10000.
1. scroll
分为初始化和遍历两个步骤,初始化时将所有符合条件的
doc_id
结果缓存起来,遍历
的时候就从这个结果中取到数据。
2. search_after
需要有一个唯一属性的字段进行排序,然后在这个上次查询的基础上查询。
3.
解决办法是将用户的检索结果缓存在
redis
中,这样大概率可以覆盖用户最近的翻页查询。
TF-IDF
TF
词频
IDF
# GET product/_search
{
"size":
10
,
"query": {
"match": {
"name":
"
苹果
"
}
},
"search_after": [
133444
,
"624"
],
"sort": [
{"date":
"asc"
},
{"_id":
"desc"
}
]
}
词出现的次数
/
文字总词数
2024/5/10 12:04
stock
localhost:3000/print.html
99/178
8. ES
性能优化措施
1.
批量提交
2.
优化硬盘
索引文件会产生很多小文件(段文件),磁盘
IO
就会形成
ES
的性能瓶颈。换固态硬盘
3.
减少副本数量
副本可以提高集群的可用性,但是也会严重影响写索引的效率。
9. ES
的查询优化手段有哪些?
1.
设计阶段
根据业务增量需求,采取基于日期模板创建索引,通过
roll over API
滚动索引。
每天定时对索引做
force_merge,
节省磁盘空间。
采取冷热分离机制,热数据存储到
SSD
,冷数据定期
shrink
,缩减存储。
Mapping
阶段充分结合各字段属性,是否需要检索,是否需要存储等。
2.
写入调优
降低刷新频率
refresh_interval
这个参数控制内存同步到磁盘的时间。
bulk
批量写入
尽量使用自动生成的
id
写入端使用特定的
id
将数据写入
es
时,
es
需要去检查
index
下是否存
在相同的
id
。
3.
查询调优
禁用
wildcard wildcard
就是模糊匹配,模糊匹配会使得数据量线性增长。所以尽量使用
match
的精确匹配。
禁用批量
terms
充分利用倒排索引机制 能用
keyword
类型就使用
keyword
。
数据量大时可以先基于时间敲定索引再检索 通过限定时间达到只需要检索部分索引的目的,
从而优化查询性能。
log(
文档数
/
包含该词文档数
+1)
1.
创建一个带别名的索引。
2.
过一段时间,
ES
自动创建新的索引,别名指向新的索引。
2024/5/10 12:04
stock
localhost:3000/print.html
100/178
14. ES
中的集群、节点、索引、文档是什么?
1.
集群
集群是一个或多个节点的集合,他们共同保存整体数据,并提供跨节点的联合索引和搜索功
能。集群由唯一名称标识。
2.
节点
单个服务器,它存储数据并参与集群索引及搜索功能。
3.
索引
类似于关系数据库中的数据库。索引是逻辑名称空间,映射到一个或多个主分片。
4.
文档
类似于关系数据库中的一行,不同之处在于每个文档可以有不同的结构。但是对于通用字段
应该具有相同的数据类型。
15. ES
中的分片
ES
是一个分布式搜索引擎,因此索引通常被分隔分布在多个节点上,这分隔的一块就是一个分
片。
16. ES
中的副本
为了数据安全,每个分片都会有一份或几分拷贝,这些拷贝就是副本。
2024/5/10 12:04
stock
localhost:3000/print.html
101/178
tomcat
2024/5/10 12:04
stock
localhost:3000/print.html
102/178
Git
7. git pull
和
git fetch
有什么区别
1. git pull
pull
会从中央存储库中提取特定分支的新更改或提交,并更新本地存储库的目标分支。
2. git fetch
fetch
从所需的分支中提取所有新提交并存储在本地存储库的新分支中,如果要在目标分支中
反映这些更改,必须在
fetch
之后进行
merge
。
git pull = git fetch + git merge
8. git
中的
staging area
或
index
是什么
9.
什么是
git stash
你正在写或修改代码,这时候忽然需要切换分支去处理其他事情,直接切会引起混乱,你还不想提
交做了一般的工作,这时候可以使用
git stash save
将目前的工作暂时保存在一堆未完成的更改
中。
工作区
staging area
local_repo
remote_repo
git add
git commit
git push
git pull
git checkout
git merge
工作区
staging area
local_repo
remote_repo
2024/5/10 12:04
stock
localhost:3000/print.html
103/178
11.
如何找到特定提交中已更改的文件列表
18.
描述一下你使用的分支策略
1. Master
分支
版本发布状态,与线上一致。
2. Develop
分支
最新的开发进度。
3. Featuer
分支
任务分支。开发完成后合并到
Develop
分支
4. Release
分支
提交测试时从
Develop
中检出,在
Release
分支上修改,发布前合并到
Develop
和
master
分
支。
Master
打
tag
。
5. Hotfix
分支 线上经济
bug
修复。
xx.
常用
git
命令
#
列出该提交中更改或添加的所有文件
-r
会列出单个文件
git diff-tree -r {hash}
git init
git add <file>
git commit <file> -m '
备注
'
git push
git pull
git checkout -b <branch_name>
2024/5/10 12:04
stock
localhost:3000/print.html
104/178
软实力
2024/5/10 12:04
stock
localhost:3000/print.html
105/178
前端
1. vue
生命周期
2.
双向绑定
v-model
3.
组件间传递参数
1.
父组件向子组件传递参数
props
2.
子组件向父组件传递参数
emit
传递参数
3.
非父子间传递参数 借用
eventBus,
使用它来传递和接收事件。
4.
跨级传递参数
provide
和
inject
4. Vue
路由实现
1. hash
模式 浏览器路径中
#
后面的参数,通过监听
hashchange
事件,实现路由跳转
2. history
模式 使用
api
,
pushState
,
replaceState
,实现路由跳转。
5. v-show vs v-if
v-show:
通过修改元素的
dispaly
属性,实现隐藏和显示。
v-if:
通过移除和添加元素,实现隐藏和显示。
6. v-slot
插槽
BeforeCreate
Created
BeforeMount
Mounted
BeforeUpdate
Updated
BeforeDestroy
Destroyed
2024/5/10 12:04
stock
localhost:3000/print.html
106/178
练习
2024/5/10 12:04
stock
localhost:3000/print.html
107/178
Java
基础练习
3. java
基础类型
1. int
和
Integer
的相等
?
在
-128
和
127
以内使用
==
会是
ture
,之外会是
false
。 因为
java
对期间的数进行了特殊处理。
// -127 ~ 128
之间测试
@Test
public void
testIntEqual
()
{
//int
对于
-128
到
127
之间会有缓存,对这个等于进行了特殊处理
int
a =
123
;
Integer b = Integer.valueOf(
123
);
Integer c = Integer.valueOf(
123
);
System.out.println(
"a=b is "
+ (a==b));
//true
System.out.println(
"b==c is "
+ (b==c));
//true
int
d = -
127
;
Integer e = Integer.valueOf(-
127
);
//true
Integer f = Integer.valueOf(-
127
);
//true
System.out.println(
"d=e is "
+ (d==e));
System.out.println(
"e==f is "
+ (e==f));
}
//
上述范围之外的处理
@Test
public void
testIntEqual2
()
{
int
a =
128
;
Integer b = Integer.valueOf(
128
);
Integer c = Integer.valueOf(
128
);
System.out.println(
"a=b is "
+ (a==b));
// true
System.out.println(
"b==c is "
+ (b==c));
//false
Assert.assertTrue(b==c);
}
2024/5/10 12:04
stock
localhost:3000/print.html
108/178
2. float
和
double
的相等
?
9. HashMap
任何类做
Key
30.
反射
jar
包
@Test
public void
testFloatEqual
()
{
float
a =
2.13f
;
float
b =
21.3f
/
10
;
//2.13 ---> 2.1299999999
System.out.println(
"a==b is "
+ (a==b));
//false
boolean
equal = a-b <
0.001
;
System.out.println(
"a==b is "
+ (equal));
//true
}
2024/5/10 12:04
stock
localhost:3000/print.html
109/178
public class
MyReflect
{
public static void
main
(String[] args)
throws
ClassNotFoundException,
NoSuchMethodException, InvocationTargetException, IllegalAccessException {
Class<?> stuClass = Class.forName(
"org.example.reflect.Student"
);
Field[] declaredFields = stuClass.getDeclaredFields();
for
(Field field : declaredFields) {
System.out.println(field.getName() +
" "
+
field.getType().getName());
}
Method[] declaredMethods = stuClass.getDeclaredMethods();
for
(Method method : declaredMethods) {
System.out.println(method.getName() +
" "
+ params2Str(method));
}
Student student =
new
Student();
student.setAge(
22
);
student.setName(
"
大青蛙
"
);
Method detail = stuClass.getDeclaredMethod(
"detail"
,
null
);
Object result = detail.invoke(student,
null
);
System.out.println(result);
}
private static
String
params2Str
(Method method)
{
StringBuffer sb =
new
StringBuffer();
Class<?>[] parameterTypes = method.getParameterTypes();
for
(Class cls : parameterTypes) {
sb.append(cls.getName()).append(
","
);
}
return
sb.toString();
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
110/178
Spring Cloud
2024/5/10 12:04
stock
localhost:3000/print.html
111/178
Redis
Redis
的数据类型
常见的
5
中数据类型
1. String
1.1
数据结构
String
类型的底层数据结构主要是
int
和
SDS(
简单动态字符串
)
类型
编码
指针
string
int
ptr
string
embstr(<32)
ptr
string
raw
ptr
SDS
free
len
buf
1.2
使用场景
1.
缓存对象
2.
常规计数
3.
分布式锁
Redis
String
List
Set
Zset
Hash
set user:1 '{}'
set article:readcount:1001 1
incr article:readcount:1001
2024/5/10 12:04
stock
localhost:3000/print.html
112/178
2. List
2.1
数据结构
quickList(
以前是双向链表和压缩列表
)
2.2
应用场景
1.
消息队列
消息保序
list
本身就是支持先进先出的顺序对数据进行存取的。
消息可靠性
BRPOPLPUSH,
从一个
list
中读取消息,同时会把这个消息再插入到另一个
List
留存。
处理重复消息?
自行生成唯一消息
ID
。
3. Hash
3.1
数据结构
listpack(7.0
之前是压缩列表或哈希表
)
# lock_key
就是
key
# client_uiq
客户端生成唯一标识 后续删除用
# NX
代表
lock_key
不存在时才对
lock_key
进行设置操作
# PX 10000
设置过期时间为
10s
,防止锁死
set lock_key client_uniq NX PX 10000
#
将一个或多个值插入到列表的表头
LPUSH key value
#
将一个或多个值插入到列表的表尾
RPUSH key value
#
移除表头元素
LPOP
#
移除表尾元素
RPOP
lpush
头部插入
rpop
尾部弹出
# rpop
需要持续读取,浪费
cpu
,所以可以使用
brpop
brpop
阻塞式尾部弹出
2024/5/10 12:04
stock
localhost:3000/print.html
113/178
3.2
应用场景
1.
缓存对象
2.
购物车
4. Set
无序、唯一。
4.1
数据结构
hash
表或整数集合。
4.2
使用场景
1.
用户点赞
2.
共同好友、关注
3.
抽奖活动
ZSet 5
相比
set
类型多了一个排序属性
score
。对于有序集合来说,每个存储元素有两个值组成。
#
存储一个
hash
表
key
的
field
字段值
HSET key field value
SADD key member
SMEMBERS key
SADD uid:
1 5 6 7 8
SADD uid:
2 2 7 8 10
SINTER uid:
1
uid:
2
7
,
8
#
支持重复中奖
SRANDMEMBER set 1
#
不允许重复中奖
SPOP set 1
2024/5/10 12:04
stock
localhost:3000/print.html
114/178
5.1
数据结构
listpack(
压缩列表或跳表
)
5.2
使用场景
1.
排行榜
2.
电话、姓名排序
新增的数据类型
6 BitMap
位图
6.1
数据结构
string
(也可以说是
bit
数组)
6.2
使用场景
1.
签到统计
2.
判断用户登录状态
3.
连续签到的用户总数
Redis
Stream
GEO
HyperLogLog
BitMap
#
记录用户
100
的
11
月份的登录信息,
SETBIT uid:sign:100:202311 2 1
#
获取登录状态
GET login_status 10001
#
设置登出
SETBIT login_status 10001 0
2024/5/10 12:04
stock
localhost:3000/print.html
115/178
7 HyperLogLog
7.1
内部实现
7.2
使用场景
1.
百万级
UV
统计
8. GEO
8.1
数据结构
直接使用了
Sorted Set
集合类型
8.2
滴滴打车
9. Stream
支持消息持久化,支持生成全局唯一
ID
,支持
ack
确认消息模式,支持消费组模式。
9.2
应用场景
对二维地图做区间划分
对区间进行编码
2024/5/10 12:04
stock
localhost:3000/print.html
116/178
Vue3
ref vs reactive
1. ref
适用于所有类型,
reactive
只适用于对象类型
(
对象、数组以及
Map
,
Set
集合类型
)
。
2.
实现方式不一样,
ref
是通过对属性访问的
getter
和
setter
来实现,
reactive
是通过
Proxy
来实
现。
3.
解构后都会失去响应性。
v-on:click vs @click
@keyup.enter @keydown.tab @keyup.a
v-show vs v-if
v-show
会创建元素但是不显示;
v-if
不会创建元素。
v-bind:value vs :value
v-bind vs v-model
v-bind
是单向数据绑定;
v-model
是双向数据绑定。
2024/5/10 12:04
stock
localhost:3000/print.html
117/178
watch vs watchEffect
父子组件通信
1.
父组件向子组件传递数据:
props
2.
子组件向父组件传递数据:事件
3.
深层传递
provide inject
slot vs
具名
slot vs
作用域插槽
toRef vs toRefs
//
父组件
provide(
"name"
, value);
//
子组件
const
name = inject(
"name"
);
<slot/>
<template #url></template>
2024/5/10 12:04
stock
localhost:3000/print.html
118/178
扩展知识
2024/5/10 12:04
stock
localhost:3000/print.html
119/178
Docker
2024/5/10 12:04
stock
localhost:3000/print.html
120/178
分库分表
-Mycat
下载
下载
jar
包
下载模板
安装
可能需要修改
bin
下的运行权限
可能需要创建新的
mysql
用户。
http://dl.mycat.org.cn/2.0/
http://dl.mycat.org.cn/2.0/install-template/
解压
template
,并将
jar
包放入
template
中
lib
目录下。
create user 'mycat'@'%' identified by '123456';
grant all privileges on *.* to 'mycat'@'%';
flush privileges;
修改
mycat
的
prototype
的配置
conf/datasource/
2024/5/10 12:04
stock
localhost:3000/print.html
121/178
运行
windows
概念
配置文件:
conf
中
users
配置用户信息 命名方式
username.user.json isolation:
设置事务隔离级别
transactionType: xa proxy
查看事务类型
select @@transaction_type
datasources
命名方式: 数据源名字
.datasources.json
集群
clusters
命名方式: 集群名称
.cluster.json
逻辑库表 命名方式: 逻辑库名称
.schemas.json
需要以
administrator
运行。
需要先安装服务
mycat install
启动
mycat start
start
启动
stop
停止
console
前台运行
install
添加到系统自动启动
remove
取消系统自动启动
restart
重启服务
pause
暂停
status
查看状态
管理员用命令
mysql -umycat -P 9066
我们用的:
mysql -uroot -P 8066
逻辑库
逻辑表
物理库
物理表
单表
广播表
2024/5/10 12:04
stock
localhost:3000/print.html
122/178
分库分表
分表
分片算法:
create database
db1;
//
广播表
create table
db1.type(
id
bigint
NOT
NULL
auto_increment,
name
varchar
(
255
)
NOT
NULL
,
primary
key
(
id
)
)
ENGINE
=
InnoDB DEFAULT charset
=utf8 BROADCAST;
insert into type
(
id
,
name
)
values
(
1
,
"
食品
"
);
insert into type
(
id
,
name
)
values
(
2
,
"
饮料
"
);
//
分表
create table
db1.orders (
id
bigint
not
null
auto_increment,
customer_id
int
,
primary
key
(
id
)
)
engine
=
innodb default charset
=utf8 tbpartition
by
mod_hash(customer_id)
tbpartitions
2
;
INSERT INTO
`orders`
VALUES
(
1
,
1
);
INSERT INTO
`orders`
VALUES
(
2
,
2
);
INSERT INTO
`orders`
VALUES
(
3
,
1
);
INSERT INTO
`orders`
VALUES
(
4
,
2
);
// ER
表
create table
db1.orders_detail(
id
bigint
not
null
auto_increment,
detail
varchar
(
200
),
order_id
int
,
primary
key
(
id
)
)
engine
=
INNODB DEFAULT CHARSET
=utf8 tbpartition
BY
mod_hash(order_id)
tbpartitions
2
;
insert into
orders_detail(
id
, detail, order_id)
values
(
1
,
"
苹果
"
,
1
);
insert into
orders_detail(
id
, detail, order_id)
values
(
2
,
"
梨
"
,
1
);
insert into
orders_detail(
id
, detail, order_id)
values
(
3
,
"
香蕉
"
,
2
);
insert into
orders_detail(
id
, detail, order_id)
values
(
4
,
"
梨
"
,
2
);
//
查看配置的表是否有
ER
关系
/*+ mycat:showErGroup {}*/
;
mod_hash
YYYYMM
YYYYDD
YYYYWEEK
STR_HASH
2024/5/10 12:04
stock
localhost:3000/print.html
123/178
分库分表
2
1.
引入依赖
<dependency>
<groupId>
org.apache.shardingsphere
</groupId>
<artifactId>
shardingsphere-jdbc-core-spring-boot-starter
</artifactId>
<version>
5.2.1
</version>
</dependency>
<dependency>
<groupId>
org.yaml
</groupId>
<artifactId>
snakeyaml
</artifactId>
<version>
1.33
</version>
</dependency>
2024/5/10 12:04
stock
localhost:3000/print.html
124/178
2.
添加配置
spring:
shardingsphere:
#
定义
shardingsphere
配置
datasource:
names:
stock0,stock1
#
定义多个数据源
stock0:
type:
com.alibaba.druid.pool.DruidDataSource
driver-class-name:
com.mysql.cj.jdbc.Driver
url:
jdbc:mysql://localhost:3306/stock_0
username:
dev
password:
123456
stock1:
type:
com.alibaba.druid.pool.DruidDataSource
driver-class-name:
com.mysql.cj.jdbc.Driver
url:
jdbc:mysql://localhost:3306/stock_1
username:
dev
password:
123456
props:
sql-show:
true
rules:
sharding:
tables:
orders:
actual-data-nodes:
stock${0..1}.orders_${0..1}
key-generate-strategy:
column:
id
key-generator-name:
snowflake
table-strategy:
standard:
sharding-column:
uid
sharding-algorithm-name:
order-inline
default-database-strategy:
standard:
sharding-column:
uid
sharding-algorithm-name:
database-inline
sharding-algorithms:
database-inline:
type:
INLINE
props:
algorithm-expression:
stock${uid %
2
}
order-inline:
type:
INLINE
props:
algorithm-expression:
orders_${uid %
2
}
key-generators:
snowflake:
type:
SNOWFLAKE
2024/5/10 12:04
stock
localhost:3000/print.html
125/178
3.
可能需要排除第三方数据源定义
其他
1.
可能的其他依赖
@SpringBootApplication(exclude = {DruidDataSourceAutoConfigure.class})
@MapperScan("com.ruoyi.mapper")
public class
MySharding
{
public static void
main
(String[] args)
{
System.out.println(
"Hello world!"
);
SpringApplication.run(MySharding.class, args);
}
}
<dependency>
<groupId>
com.alibaba
</groupId>
<artifactId>
druid-spring-boot-starter
</artifactId>
<version>
1.1.10
</version>
</dependency>
<!--
因为是基于
mysql
开发,所以一并引入
-->
<dependency>
<groupId>
mysql
</groupId>
<artifactId>
mysql-connector-java
</artifactId>
<version>
8.0.33
</version>
</dependency>
<dependency>
<groupId>
org.projectlombok
</groupId>
<artifactId>
lombok
</artifactId>
<version>
1.18.18
</version>
</dependency>
<dependency>
<groupId>
com.baomidou
</groupId>
<artifactId>
mybatis-plus-boot-starter
</artifactId>
<version>
3.5.2
</version>
</dependency>
2024/5/10 12:04
stock
localhost:3000/print.html
126/178
架构演进
单机
浏览器通过网络访问
tomcat
,
tomcat
和数据库部署在同一台机器上。
tomcat
和数据库竞争资源,单机性能不足
tomcat
和数据库分开部署
浏览器通过网络访问
tomcat
,
tomcat
和数据库分开部署。
用户数增长后,并发读写数据库称为瓶
颈
引入本地缓存和分布式缓存
tomcat
引入本地缓存,也可以增加分布式缓存。
查询
baidu.com
访问
10.10.10.10
服务器
数据库
Tomcat
浏览器
DNS
服务器
返回
10.10.10.10
查询
ip
浏览器
DNS
服务器
Tomcat
数据库
2024/5/10 12:04
stock
localhost:3000/print.html
127/178
随着用户数增长,并发压力主要落在单
tomcat
上
引入反向代理实现负载均衡
使用
nginx/HAProxy
反向代理服务器将请求均匀分发到每个
tomcat
上,这样就可以倍数增加并发
数。
反向代理可以支持更高的并发量,从而导致数据库压力更大
数据库读写分离
一般情况下数据库读大大高于数据库写,因此我们可以通过读写分离降低写库的压力。
查询
ip
服务器
本地缓存
Tomcat
浏览器
DNS
服务器
Redis
查询
ip
数据
数据库
缓存
浏览器
DNS
服务器
Nginx
Tomcat_1
Tomcat_2
Tomcat_3
2024/5/10 12:04
stock
localhost:3000/print.html
128/178
业务逐渐变多,不同业务之间竞争数据库
数据库按业务分库
不同业务之间会互相影响,导致开发上线受到影响。
随着用户数增长,单机的写库会逐渐达到性能瓶颈
将大表拆分为小表
根据业务特征进行分表,例如针对商品评论,可以按照商品
ID
进行
hash
,然后路由到对应的表中
存储。针对支付记录可以按照时间进行分表。
查询
ip
数据
binlog
数据库读
缓存
数据库写
浏览器
DNS
服务器
Nginx
Tomcat_1
Tomcat_2
Tomcat_3
查询
ip
商品
binlog
binlog
数据库读
缓存
数据库写
浏览器
DNS
服务器
Nginx
Tomcat_1
Tomcat_2
用户
2024/5/10 12:04
stock
localhost:3000/print.html
129/178
使用
LVS
或
F5
来使多个
Nginx
负载均衡
到达单台
Nginx
服务的极限时,只能使用
LVS(Linux Virtual Server)
或
F5
来解决。其中
LVS
是软件,
可以支持几十万个并发的请求转发,
F5
是一种负载均衡硬件,性能更好。两者都工作在第四层。
LVS
可以设置备用节点,主备之间使用
keepalived
实现。 根据业务特征进行分表,例如针对商品评
论,可以按照商品
ID
进行
hash
,然后路由到对应的表中 存储。针对支付记录可以按照时间进行分
表。
查询
ip
商品
数据库读
1
结尾
按用户
ID
分
2
结尾
3
结尾
缓存
浏览器
DNS
服务器
Nginx
Tomcat_1
Tomcat_2
用户
2024/5/10 12:04
stock
localhost:3000/print.html
130/178
LVS
也是单机,并发到几十万时就会遇到瓶颈
通过
DNS
轮询实现机房间的负载均衡
在
DNS
服务器中配置一个域名对应多个
IP
地址,每个
IP
地址对应到不同机房的
IP
。
随着业务的发展,检索分析需求越来越丰富,单单依靠数据库无法解决
查询
ip
商品
数据库读
1
结尾
按用户
ID
分
2
结尾
3
结尾
缓存
浏览器
DNS
服务器
LVS
虚拟
IP
Nginx
Tomcat_1
Tomcat_2
用户
keepalived
可以模拟出虚拟
IP
,然后把虚拟
IP
绑定到多台
LVS
上,当有请求时,
会被路由器定向到真实的
LVS
服务器。
查询
ip
DNS
10.10.10.10
baidu.com
10.10.10.11
商品
数据库读
1
结尾
按用户
ID
分
2
结尾
3
结尾
缓存
浏览器
DNS
服务器
LVS
虚拟
IP
Nginx
Tomcat_1
Tomcat_2
用户
2024/5/10 12:04
stock
localhost:3000/print.html
131/178
引入
NoSQL
数据库和搜索引擎等技术
对于海量文件存储,可以使用
HDFS
解决。
key value
类型数据使用
HBase
和
Redis
解决
全文检索使用
ElasticSearch
解决
多维分析,使用
Kylin
或
Druid
方案解决
微服务
将业务按照功能划分为单独的一个个服务,服务之间相互协作完成需求处理。可以使用
Dubbo
,
Spring Cloud
等框架实现服务治理,限流、熔断、降级等功能。
调用链复杂
容器化
Docker
,
K8S
大数据
(
临时
)
1.
数据采集
Flume
Sqoop
Kettle
2.
数据存储
HDFS
FastDFS
HBase
MongoDB
3.
数据分析
Spark
机器学习
2024/5/10 12:04
stock
localhost:3000/print.html
132/178
Disruptor
LMAX
开源的,用于替代并发线程间数据交换的环形队列、基本无锁的高性能 线程间通讯框架。
1.
环形队列
RingBuffer
2.
弃用锁机制使用
CAS
3.
解决伪共享,采用缓存行填充
环形队列可以循环使用,没有
GC
压力。
通过扩充数据填满缓冲行,避免伪共享的实现
2024/5/10 12:04
stock
localhost:3000/print.html
133/178
Springfox & ApiFox
SpringDoc
1.
添加依赖
2.
添加
Swagger3
注解
3.
Springfox
swagger
是一个业界
restful API
标准,用于描述、生成
restful
风格的
api
。
springfox
是
spring
中对
swagger
支持比较好的工具。
添加
Swagger2
支持
添加注释
入口类添加注解
<dependency>
<groupId>
org.springdoc
</groupId>
<artifactId>
springdoc-openapi-starter-webmvc-ui
</artifactId>
<version>
2.0.2
</version>
</dependency>
<dependency>
<groupId>
org.springdoc
</groupId>
<artifactId>
springdoc-openapi-starter-webmvc-api
</artifactId>
<version>
2.0.2
</versin>
</dependency>
@tag(name="
买卖股票
")
@RestController
<dependency>
<groupId>
io.springfox
</groupId>
<artifactId>
springfox-boot-starter
</artifactId>
<version>
3.0.0
</version>
</dependency>
2024/5/10 12:04
stock
localhost:3000/print.html
134/178
可以通过添加
Docket
实例配置暴露的
api
访问应用的地址:
http://IP:
端口
/swagger-ui/index.html
ApiFox
ApiFox
是一款集成
Swagger
支持,
Mock
,
PostMan
和
Jmeter
功能的工具。基本上覆盖了开发的整
个流程。
从
swagger
中导入
api
定义。
打开
ApiFox
在团队首页,点击引入项目(或新建项目后点击引入项目)。
apifox
导入
swagger
文档 然后在导入页面点击
URL
导入后输入下图中红线部分的
url
:
swagger-ui
@SpringBootApplication
@EnableScheduling
@EnableSwagger2
public class UserApp {
public static void main(String[] args) {
System.out.println("Hello world!");
SpringApplication.run(UserApp.class, args);
}
}
@Bean
public Docket petApi() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
//.apis(RequestHandlerSelectors.any())
.apis(RequestHandlerSelectors.basePackage("org.example.controller"))
.build();
}
2024/5/10 12:04
stock
localhost:3000/print.html
135/178
sql
1.
简单查询
1.1
查询所有姓猴的的同学
1.2
查询名称中带猴的同学
1.3
查询姓孟的老师的个数
1.4
查询不及格的课程,并由大到小排列
2.
汇总分组分析
2.1
查询课程编号为
0002
的总成绩
2.2
查询选了某课程的人数
select
*
from
student
where name like
'
猴
%'
;
select
*
from
student
where name like
'%
猴
%'
select count
(teacher_no)
from
teacher
where name like
'
孟
%'
;
select
course_no,score
from
score
where
score<
90
order by
score
desc
;
select sum
(score)
from
score
where
course_no=
'0002'
;
select
course_no,
count
(
distinct no
)
as num from
score
group by
course_no;
2024/5/10 12:04
stock
localhost:3000/print.html
136/178
2.3
查询各科成绩的最高和最低分
2.4
查询每门课程被选修的学生数
2.5
查询男生、女生人数
3.
分组结果作为条件
3.1
查询平均成绩大于
60
分的学号和成绩
3.2
查询至少选修两门课程的学生学号
3.3
查询同名学生的人数
3.4
查询每门课程的平均成绩,结果按照平均成绩升序排序,平均成绩相同时按课程
号降序排列
select
course_no,
max
(score)
as max
,
min
(score)
as min from
score
group by
course_no;
select
course_no,
count
(
no
)
from
score
group by
course_no;
select
sex,
count
(
no
)
from
student
group by
sex;
select no
,
avg
(score)
from
score
group by no having avg
(score)>
60
;
select no
,
count
(course_no)
as num from
score
group by no having
count
(course_no)>
1
;
select name
,
count
(
name
)
as num from
student
group by name
;
select
course_no,
avg
(score)
as
avg_score
from
score
group by
course_no
order
by
avg_score
asc
, course_no
desc
;
2024/5/10 12:04
stock
localhost:3000/print.html
137/178
3.5
查询两门以上不及格课程的同学的学号及其平均成绩
4.
复杂查询
4.1
查询所有有不及格课程的学生学号和姓名
4.2
查询没有学全所有课程的学生
4.3
查询只选修了两门课程的全部学生的学号和姓名
4.4
查询
1990
年出生的学生
select no
,
avg
(score)
as
avg_score
from
score
where
score <
90
group by no
having count
(
1
) >
2
;
select no
,
name from
student
where no in
(
select no from
score
where
score <
60
);
select no
,
name from
student
where no in
(
select no from
score
group by no having
count
(course_no) < (
select count
(
no
)
from
course))
select no
,
name from
student
where no in
(
select no from
score
group by no
having count
(course_no) =
2
)
select no
,
name from
student
where year
(birthday)=
1990
;
2024/5/10 12:04
stock
localhost:3000/print.html
138/178
5.
面试题解析,
top N
问题
mysql 5
5.1
查询各科最高成绩所在行的数据
5.2
查询各科成绩前两名
mysql 8
5.2
查询各科成绩前两名
6.
多表查询
6.1
查询所有学生的学号,姓名,选课数,总成绩
select
*
from
score
as
a
where
score = (
select max
(score)
from
score
as
b
where
b.course_no=a.course_no);
(
select
course_no,score,
no from
score
where
course_no=
'0001'
order by
score
desc limit
2
)
union all
(
select
course_no,score,
no from
score
where
course_no=
'0002'
order by
score
desc limit
2
);
select
a.id, a.classname,a.score
from
scores
as
a,
(
select id
, row_number()
over
(
partition by
classname
order by
score
desc
)
as
rownum
from
scores)
as
b
where
a.id=b.id
and
b.rownum<=
1
;
select
a.no, a.name,
count
(b.course_no)
as
course_num,
sum
(b.score)
as
sum_score
from
student a
left join
score b
on
a.no = b.no
group by
a.no;
2024/5/10 12:04
stock
localhost:3000/print.html
139/178
6.2
查询平均成绩大于
85
的所有学生学号,姓名和平均成绩
6.3
查询每门课程的及格人数和不及格人数
6.4
查询优秀(
>=85
)
,
良好
(<85 && >= 75 ),
一般
(<75 && >= 60),
不及格
(<60)
的课
程号,课程名称以及人数
6.5
行列互换
select
a.no, a.name,
avg
(b.score)
as
avg_score
from
student a
left join
score b
on
a.no=b.no
group by
a.no
having avg
(b.score)>
85
;
select no
,
sum
(
case when
score >=
60
then
1
else
0
end
)
as
ok,
sum
(
case when
score <
60
then
1
else
0
end
)
as
not_ok
from
score
group by
course_no;
select
b.no, b.name,
sum
(
case when
score
between
85
and
100
then
1
else
0
end
)
as
'
优秀
'
,
sum
(
case when
score
between
84
and
75
then
1
else
0
end
)
as
'
良好
'
,
sum
(
case when
score
between
74
and
60
then
1
else
0
end
)
as
'
一般
'
,
sum
(
case when
score<
60
then
1
else
0
end
)
as
'
不及格
'
from
score
as
a
right join
course b
on
a.course_no = b.no
group by
b.no;
2024/5/10 12:04
stock
localhost:3000/print.html
140/178
7.
三个
join
比较
Mysql 8
1. CTE (common table expression)
通用表表达式,是一个命名的临时
(
单语句范围内
)
的结果集,后续可以引用多次;
2.
窗口函数
窗口函数式针对返回的结果的,是对返回结果进行二次加工。窗口函数具有类似的语法:
select no
,course_no,score
from
score;
select no
,
(
case
course_no
when
'0001'
then
score
else
0
end
)
as
语文
,
(
case
course_no
when
'0002'
then
score
else
0
end
)
as
数学
,
(
case
course_no
when
'0003'
then
score
else
0
end
)
as
英语
from
score ;
select no
,
max
(
case
course_no
when
'0001'
then
score
else
0
end
)
as
语文
,
max
(
case
course_no
when
'0002'
then
score
else
0
end
)
as
数学
,
max
(
case
course_no
when
'0003'
then
score
else
0
end
)
as
英语
from
score
group by no
;
select
a.no, a.name,b.course_no, b.score
from
student a
right join
score b
on
a.no = b.no ;
select
a.no, a.name,b.course_no, b.score
from
student a
left join
score b
on
a.no = b.no ;
select
a.no, a.name,b.course_no, b.score
from
student a
join
score b
on
a.no = b.no ;
WITH
score_with_num
AS
(
SELECT id
,
classname,
score,
ROW_NUMBER()
OVER
(
PARTITION BY
classname
ORDER BY
score
DESC
) row_num
from
scores
)
select
*
from
score_with_num
where
row_num<=
2
;
2024/5/10 12:04
stock
localhost:3000/print.html
141/178
分区定义
顺序定义
分帧定义
暂时忽略
2.1 ROW_NUMBER
为行分配序号 从
1
开始为每一行分配一个序号。
top N
问题
删除重复的行
表初始化
window_function(
表达式
)
OVER (
[
分区定义
]
[
顺序定义
]
[
分帧定义
]
)
PARTITION BY course_no
ORDER BY score DESC
select
row_number()
over
(
order by id desc
) row_num, classname
from
scores
order by
classname;
select
a.id, a.classname,a.score
from
scores
as
a,
(
select id
, row_number()
over
(
partition by
classname
order by
score
desc
)
as
rownum
from
scores)
as
b
where
a.id=b.id
and
b.rownum<=
1
;
2024/5/10 12:04
stock
localhost:3000/print.html
142/178
使用
row_number()
根据电话号码分区,每个分区单独排序
删除重复的行
检查结果
2.2 RANK
rank()
函数为结果集的分区中每一行分配一个排名,行的等级为前面的等级加一得到。
查询成绩按科目排名
drop table if exists
contacts;
create table
contacts (
id
INT
,
phone
varchar
(
11
)
NOT
NULL
);
insert INTO
contacts(
id
,phone)
values
(
1
,
'18600160903'
),
(
2
,
'18600160903'
),
(
3
,
'18600160904'
),
(
4
,
'18600160904'
),
(
5
,
'18600160905'
),
(
6
,
'18600160905'
),
(
7
,
'18600160905'
);
select id
,phone,
row_number()
over
(
partition by
phone
order by
phone)
as
row_num
from
contacts;
WITH
dups
as
(
select
id
,
phone,
row_number()
over
(
partition by
phone
order by
phone)
as
row_num
from
contacts
)
delete
contacts
from
contacts
inner join
dups
on
contacts.id=dups.id
where
dups.row_num>
1
;
select
*
from
contacts;
SELECT
phone,
rank
()
over
(
order by
phone) my_rank
from
contacts;
select id
,classname,
rank
()
over
(
partition by
classname
order by
score)
from
scores;
2024/5/10 12:04
stock
localhost:3000/print.html
143/178
2.3 DENSE_RANK
与
rank
的区别在于,
dense_rank
排名不会有间隙。
主要是针对排名一致的行并不会按多行计算。
2.4 CUME_DIST
累计分布
2.5 FIST_VALUE
获取窗口内的第一个值。
2.6 NTH_VALUE
2.7 PERCENT_RANK
2.8 LEAD
select id
,phone,
dense_rank
()
over
(
order by
phone) my_rank
from
contacts;
2024/5/10 12:04
stock
localhost:3000/print.html
144/178
HDFS
HDFS
全名为
Hadoop Distributed File System
,它是一个分布式文件系统。 是
Hadoop
的三大核
心组件之一,另外还有
MapReduce
(分布式计算框架)
,YARN(
分布式资源管理框架
)
。
HDFS
组件
块
名称节点
(NameNode)
数据节点
(DataNode)
维护文件系统树及整棵树内所有的文件和目录。
文件节点需要保持高可用。
保持高可用需要:
1.
元数据保持一致。
2.
主节点故障时切换,如果要实现自动切换需要配合
ZKFC(Zookeeper FailOver Controller)
组件
来实现。
块放在数据节点上。
文件一般配置副本数量,副本一方面防止数据丢失,另外还可以提高读取速度。
副本放置策略:
三分之一位于写入器节点上。
三分之一位于同一机架上。
三分之一平均分布在其余机架上。
副本数量不能大于
DataNode
数量。为什么?
数据节点在将数据存储到本地文件系统目录中时,可以通过
hdfs-site.xml
文件配置写入目录的路径。
在写入新块时,数据节点会采用
round-robin
(循环)或
available space
(可用空间)来选择卷。
另外还有个命令行工具
DiskBalancer
,用于在某数据节点内的磁盘间移动数据。
2024/5/10 12:04
stock
localhost:3000/print.html
145/178
写入流程:
Client
提交写操作到
NameNode
上,
NameNode
判断在该目录下时候有写权限,并查看是很
存放的数据节点,之后返回给客户端。
Client
拿到节点位置信息后,会和对应的
DataNode
节点直接交互。
读取流程:
客户端
(Client)
HBASE
大数据量,支持高并发的随机写和实时查询。
2024/5/10 12:04
stock
localhost:3000/print.html
146/178
名称
大数据量
随机写
实时查询
Mysql
No
Yes
Yes
Kafka
Yes
No
No
Redis
No
Yes
Elastic
Yes
Yes
近实时
HDFS
Yes
No
No
HBASE
Yes
Yes
Yes
HBase VS ES
偏分析选
HBase
,偏查询选
ES
HBase
支持的数据量更大些,
结构介绍
Client
即客户端,提供了访问
Hbase
的接口,一般会维护
cache
以加速
HBase
的访问。
Zookeeper
存储
HBase
的元数据,读写数据前需要从
Zookeeper
里拿到元数据
(meta data)
了
解去那台机器读写。
HMaster
管理
HRegion
的分配和转移。
HRegionServer
具体处理客户端的读写请求,负责与
HDFS
底层交互。
HRegionServer
负责管理
HRegion
,
HRegion
下面有
Store
,
Store
保存列族,一个列族的数
据存储在一个
Store
里面。
2024/5/10 12:04
stock
localhost:3000/print.html
147/178
Store
的结构有
Mem Store
和
StoreFile
,
Hbase
写数据时,会首先写到
Mem Store
,当超过
一定阈值时会刷到硬盘上,形成
StoreFile
,
StoreFile
底层就是以
HFile
的格式保存。
HLog
有点类似
Mysql
中的
binlog
或
Redis
中的
AOF
的日志文件。
HBASE
安装
1.
选择使用的版本:
apache-hbase
在页面的靠上部分有推荐的下载地址,进入后选择合适的
版本。
2.
下载和安装
3.
连接
HBase
4.
操作
HBase
#
下载
hbase
curl 'https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz' -O
#
解压
tar xzvf hbase-2.4.17-bin.tar.gz
cd hbase-2.4.17
#
如果没有设置
JAVA_HOME
则设置它
,
例如我本地路径如下
#
也可以在
hbase-env.sh
中设置
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
#
运行
hbase
bin/start-hbase.sh
#
可以使用
jps
查看
hbase
是否已经运行
,
如果包含
HMaster
则表示已经正常运行
jps
#
之后可以通过
http://localhost:16010
查看
HBase Web UI
./bin/hbase shell
#
输入
help
命令,查看帮助
help
#
当查看具体命令或命令组的帮助时,需要对命令或命令组加上引号。
help "ddl"
2024/5/10 12:04
stock
localhost:3000/print.html
148/178
5. hbase
伪分布式设置
6.
#
创建表
create 'test', 'cf'
#
查看表
list 'test'
#
查看表的详情
describe 'test'
#
插入三条数据
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'
#
取出所有数据
scan 'test'
#
获取一行数据
get 'test', 'row1'
#
在删除表前或修改它的设置时,需要先
disable
表
disable 'test'
#
如果需要可以
enable
表
enable 'test'
#
可以删除表
drop 'test'
#
退出
shell
quit
# quit
只是退出
shell
,
hbase
仍旧在运行,如果要停止
hbase
./bin/stop-hbase.sh
#
如果
hbase
仍旧在运行,则停止他
./bin/stop-hbase.sh
#
修改
hbase-site.xml
配置,添加指示
HBase
运行在分布式模式下的配置
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
#
添加
hbase.rootdir
配置
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8020/hbase</value>
<property>
#
去掉
hbase.tmp.dir
和
hbase.unsafe.stream.capability.enforce
配置
#
启动
hbase
./bin/start-hbase.sh
#
在
HDFS
中检查
HBase
目录
# HMaster
服务控制
Hbase
集群,你可以启动
9
个备份
HMaster
服务,这样加上
# primary
服务,则总共有
10
个服务,启动备份
HMaster
,使用
local-master-backup.sh.
#
对于需要启动的备份服务器,你使用一个参数表示端口
offset
,
#
每一个
HMaster
使用两个端口(缺省是
16000
和
16010
)
./bin/local-master-backup.sh 2 3 5
#
上述命令会启动
16002/16012, 16003/16013
和
16005/16015
三对服务器
#
杀掉备份服务器可以使用类似下面的命令
cat /tmp/hbase-testuser-X-master.pid |xargs kill -9
#
其中的
X
表示
offset
#
也可以启动和关闭额外的区域服务器
2024/5/10 12:04
stock
localhost:3000/print.html
149/178
算法
&
数据结构
排序算法
冒泡排序
命名: 一般是将大的元素往后移,这样就好像小的元素慢慢
'
浮
'
到数组前面,所以叫冒泡算
法。
算法描述:
1.
比较相邻的两个元素,如果第一个大,则交换顺序。
2.
从第一对到最后一对依次进行同样的操作。
3.
从第一个元素到倒数第二个元素依次进行以上的步骤。
堆排序
public static void
bubbleSort
(
int
[] arr)
{
int
temp =
0
;
for
(
int
i=arr.length-
1
; i >
0
; i--) {
// 3.
供进行
arr.length-1
次
for
(
int
j=
0
; j<i; j++) {
if
(arr[j] > arr[j+
1
]) {
temp = arr[j];
arr[j] = arr[j+
1
];
arr[j+
1
] = temp;
}
}
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
150/178
区块链介绍文档:
区块链
是一种去中心化的分布式数据存储技术,它具有:
1.
去中心化
2.
不可篡改
3.
匿名
4.
安全 等特性。
区块
链
通过区块头里的
hash
值连接区块形成区块链。
fabric
的特征
fabric
是联盟链,它适用于企业内部或企业之间。
为什么我们的项目要使用区块链
在从农户生产农产品到消费者食用农产品之间会经历农户、运输、工厂、运输、零售等环节,理论
上讲任何一个节点都有可能出问题。如果在区块链上记录这些数据就可以保证出现问题时可以通过
可信的记录数据查出问题的根源。
区块头: 前一区块
hash
值;
区块体: 张三向李四转了
10
元钱,转后张三有
20
元,李四有
40
元钱。
2024/5/10 12:04
stock
localhost:3000/print.html
151/178
Java
进展
JDK 8
1. Lamda
表达式与函数接口
2.
方法引用
3. Stream
1.
通过集合获取
2.
通过数组
3.
通过值直接获取
4.
操作
(type name,....) -> {
代码块
}
list.stream();
String[] array = {
"are"
,
"you"
,
"ok"
};
Stream<String> stream = Arrays.stream(array);
Stream.of(
"are"
,
"you"
,
"ok"
);
filter()
distinct()
limit()
skip();
map()
flatMap()
anyMatch()
findFirst()
collect()
2024/5/10 12:04
stock
localhost:3000/print.html
152/178
4. Optional
JDK 9
1.
模块系统
isPresent();
get()
orElse();
java --list-modules
2024/5/10 12:04
stock
localhost:3000/print.html
153/178
JDK 11
1. ZGC
JDK 17
1. ZGC(oracle)/Shenandoah(openjdk)
JDK 11
开始推出了一种低延迟垃圾回收器
ZGC
。
ZGC
使用了一些新技术和优化算法,可以将
GC
暂
停时间控制在
10
毫秒以内,而在
JDK 17
的加持下,
ZGC
的暂停时间甚至可以控制在亚毫秒级别!
Z Garbage Collector
是
Java11
引入的可伸缩、低延迟的垃圾收集器, 主要特点有:
停顿时间不超过
10ms
既能处理几百
M
的小堆,也能处理几个
TB
的大堆。
UseZGC
使用
ZGC
时
-Xmx
是最重要的调优选项,主要要保证在
GC
的时候堆中有足够的
内存分配对象。
2. String
1. Compact String
Java 9
开始
String
内部表达不在是
char[]
,而是变成了
byte[]
,为了区分编码又加了一个字段
coder
,表示编码方式是
LATIN1
还是
UTF-16.
2.
新的
String
方法
isBlank(); repeat(); indent(); strip(); transform();
3. switch
switch
表达式将允许
switch
有返回值,并且可以直接作为结果赋值给一个变量,
assertThat(
" "
.isBlank());
assertThat(
"Twinkle "
.repeat(
2
)).isEqualTo(
"Twinkle Twinkle "
);
assertThat(
"Format Line"
.indent(
4
)).isEqualTo(
" Format Line\n"
);
assertThat(
"Line 1 \n Line2"
.lines()).asList().size().isEqualTo(
2
);
assertThat(
" Text with white spaces "
.strip()).isEqualTo(
"Text with white
spaces"
);
assertThat(
"Car, Bus, Train"
.transform(s1 ->
Arrays.asList(s1.split(
","
))).get(
0
)).isEqualTo(
"Car"
);
2024/5/10 12:04
stock
localhost:3000/print.html
154/178
4.
文本块
Java17
引入了文本块语法。通过三个双引号可以定义一个文本块,并且结束的三个双引号不能和
开始的在同一行。
5. instanceof
通常我们使用
instanceof
时,一般发生在需要对一个变量的类型进行判断,如果符合指定的类型,
则强制类型转换为一个新变量。 新语法会让这个操作更简单。
@Test
public void
test
()
{
int
age =
12
;
int
price =
switch
(age) {
case
0
,
1
,
2
->
0
;
//
不用
break
case
3
,
4
,
5
,
6
,
7
->
10
;
default
->
50
;
};
System.out.println(
"
需要花费价格:
"
+ price);
}
//
引入
yield
@Test
public void
testYield
()
{
int
age =
12
;
int
price = getPrice(age);
System.out.println(
"
需要花费价格:
"
+ price);
}
private int
getPrice
(
int
age)
{
return switch
(age) {
case
0
,
1
,
2
: yield
0
;
case
3
,
4
,
5
,
6
,
7
: {
yield
10
;
}
default
: yield
50
;
};
}
@Test
public void
testString
()
{
String json =
"""
{
"
name
": "
nxf
",
"
age
": 8
}
"""
;
System.out.println(json);
}
2024/5/10 12:04
stock
localhost:3000/print.html
155/178
6. Record
类
record
用于创建不可变的数据类。在这之前如果你需要创建一个存放数据的类,通常需要先创建
一个
Class
,然后生成构造方法、
getter
、
setter
、
hashCode
、
equals
和
toString
等这些方法,或
者使用
Lombok
来简化这些操作。
7. seald
密封类可以让我们更好的控制哪些类可以对我定义的类进行扩展。密封类可能对于框架或中间件的
开发者更有用。在这之前一个类要么是可以被
extends
的,要么是
final
的,只有这两种选项。
密封类可以控制有哪些类可以对超类进行继承,在
Java 17
之前如果我们需要控制哪些类可以继
承,可以通过改变类的访问级别,比如去掉类的
public
,访问级别为默认。
8.
有帮助的
NullPointerExceptions
当有类似
的调用发生空指针异常
(NullPointerExceptions)
时,
14
以前的版本不能知道具体是哪里抛出了空指
针异常,但是从
14
开始可以通过设置打开从而知道 具体是哪里抛出异常,例如抛出这样的错误:
15
以后就不用设置打开了,因为这个设置缺省就是打开的。
if
(object
instanceof
Kid kid) {
// ...
}
else if
(object
instanceof
Kiddle kiddle) {
// ...
}
public
record
User
(String name,
int
age)
{
}
public
sealed
class
Person permits Teacher
,
Worker
,
Student
{ }
student.getAddress().getCity().toLowerCase();
Cannot invoke
"String.toLowerCase()"
because the
return
value of
"com.baeldung.java8to17.Address.getCity()"
is
null
2024/5/10 12:04
stock
localhost:3000/print.html
156/178
JDK 21
虚拟线程
1.
创建方法
1.
使用
Thread.startVirtualThread()
创建
2.
使用
Thread.ofVirtual()
创建
3.
使用
ThreadFactory
创建
public class
VirtualThreadTest
{
public static void
main
(String[] args)
{
CustomThread customThread =
new
CustomThread();
Thread.startVirtualThread(customThread);
}
}
static class
CustomThread
implements
Runnable
{
@Override
public void
run
()
{
System.out.println(
"CustomThread run"
);
}
}
public class
VirtualThreadTest
{
public static void
main
(String[] args)
{
CustomThread customThread =
new
CustomThread();
//
创建不启动
Thread unStarted = Thread.ofVirtual().unstarted(customThread);
unStarted.start();
//
创建直接启动
Thread.ofVirtual().start(customThread);
}
}
static class
CustomThread
implements
Runnable
{
@Override
public void
run
()
{
System.out.println(
"CustomThread run"
);
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
157/178
4.
使用
Executors.newVirtualThreadPerTaskExecutor()
创建
graalVM
GraalVM
是一个高性能
JDK
,可提高基于
Java
和
JVM
的应用的性能并简化
Java
云原生服务的构
建和运行。它提供优化的编译器,可以更快地生成代码并降低计算资源消耗,实现微服务即时启
动
.
提高启动时间 因为
graalvm
将代码直接编译成
native
代码,所以省去了
jvm
的启动时间。
降低
CPU
和内存使用
降低代码风险 排除不使用的类、方法、字段等。它限制了反射等动态特性只能在编译期使
用。 并且不允许在运行时运行任何未知代码。
public class
VirtualThreadTest
{
public static void
main
(String[] args)
{
CustomThread customThread =
new
CustomThread();
ThreadFactory factory = Thread.ofVirtual().factory();
Thread thread = factory.newThread(customThread);
thread.start();
}
}
static class
CustomThread
implements
Runnable
{
@Override
public void
run
()
{
System.out.println(
"CustomThread run"
);
}
}
public class
VirtualThreadTest
{
public static void
main
(String[] args)
{
CustomThread customThread =
new
CustomThread();
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
executor.submit(customThread);
}
}
static class
CustomThread
implements
Runnable
{
@Override
public void
run
()
{
System.out.println(
"CustomThread run"
);
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
158/178
1.
安装
1.
下载:
在下载页下载
https://www.graalvm.org/downloads/
.
2.
解压到指定的路径
:
3.
配置环境变量
:
4.
重启命令窗口
:
重启以重新装载环境变量。
5. Native Image:
windows
下
Native Image
需要安装
https://visualstudio.microsoft.com/zh-hans/thank
you-downloading-visual-studio/?sku=BuildTools&rel=16
MSVC
(
Visual Studio
和
Microsoft Visual C++
)
2.
简单的例子
1.
编写
java
代码
2.
编译成
class
文件
3.
编译成
native
代码
4.
测试运行
3.
编译一个
spring
项目
1.
生成项目 生成项目方式很多,不是必须这种。
JAVA_HOME
PATH
public class
HelloWorld
{
public static void
main
(String[] args)
{
System.out.println(
"Hello, World!"
);
}
}
javac HelloWorld
native-image HelloWorld
./helloworld
2024/5/10 12:04
stock
localhost:3000/print.html
159/178
2.
编译项目
4.
本地影像基础
Native Image
是
Java
写的,它将
Java
字节码作为输入产生独立的二进制。在产生 二进制的过程中
可以运行用户代码。最终,
Native Image
链接编译的用户代码,部分
Java
运行时,最终生成二进制
代码。
4.1
编译时
vs
运行时
在
Native Image
构建时,可以运行用户的代码,例如可以写值到类的静态字段。我们就说这些代
码是执行在编译时。写到这些静态字段的值保存在映像堆上。有 两种方式在编译时激发类初始化
传递
--initialize-at-build-time=
给
native-image
编译期
By using a class in the static initializer of a build-time initialized class.
普通的方式运行和编译它
使用
native-iamge
去初始化
Greeter
curl https://start.spring.io/starter.zip -d type=maven-project -d
dependencies=native,web -d name=hi -d artifactId=hi -d baseDir=hi -
o hi.zip
mvn -Pnative native:compile
public class
HelloWorld
{
static class
Greeter
{
static
{
System.out.println(
"Greeter is getting ready!"
);
}
public static void
greet
()
{
System.out.println(
"Hello, World!"
);
}
}
public static void
main
(String[] args)
{
Greeter.greet();
}
}
javac HelloWorld.java
java HelloWorld
Greeter is getting ready!
Hello, World!
2024/5/10 12:04
stock
localhost:3000/print.html
160/178
4.2
本地映像堆
本地映像堆
(Native Image heap)
又称为映像堆
(Image heap)
,它包含:
应用代码可以触达的在映像编译期生成的对象
本地映像中使用的对象的类
(java.lang.Class)
内嵌在方法代码中的对象常量 怎么在映像堆中包含对象?
普通运行
编译时初始化:
可以发现在编译时初始化之后,再次运行时不会再运行初始化代码。
native-image HelloWorld --initialize-at-build-time=HelloWorld\$Greeter
./helloworld
Hello, World!
class
Example
{
private static final
String message;
static
{
message = System.getProperty(
"message"
);
}
public static void
main
(String[] args)
{
System.out.println(
"Hello, World! My message is: "
+ message);
}
}
javac Example.java
java -Dmessage=hi Example
Hello, World! My message is: hi
java Example
Hello, World! My message is: null
#
编译
native-image Example --initialize-at-build-time=Example -Dmessage=native
#
运行
./example
#
带参数运行
./example -Dmessage=aNewMsg
2024/5/10 12:04
stock
localhost:3000/print.html
161/178
4.3
静态分析
静态分析是一个决定某些程序元素是被应用使用的进程。这些元素被称为可达代码。这个分析有两
部分。
扫描方法的字节码决定其他哪些元素可以触达。
从静态映像的堆中决定哪些类似可以触达的。 从入口类开始递归运行直到没有新的元素可以
触达。
2024/5/10 12:04
stock
localhost:3000/print.html
162/178
Stream
和集合
Stream
练习
有以下两个文件。
student
文件,包含两个字段
“
姓名
”
和
“id”
,具体内容如下:
salary
数据,包含
“student_id”,"
月份
"
和
“
工资
”
,具体内容如下:
根据以上两个文件中的数据,完成以下题目:
ArrayList
ArrayList
中有以下内容
张三
, 1
李四
, 2
王五
, 3
赵六
, 4
任七
, 5
1, 4, 12000
2, 3, 5000
2, 4, 15000
3, 4, 5000,
4, 3, 6000
4, 4, 18000
1
,找出工资最高的学生
使用
Stream API
找出工资最高的学生并返回其名字。
2
,计算每个学生的总工资
对学生工资数据使用
Stream API
进行聚合操作,计算每个学生的总工资,并返回结果。
3
, 找出工资超过平均工资的学生
计算所有学生的平均工资,然后使用
Stream API
找出工资超过这个平均工资的学生名字。
4
,按照工资降序排列学生
使用
Stream API
根据工资对学生进行降序排列,并返回排序后的学生名字列表。
5
, 找出在特定月份有工资记录的学生
例如,找出在
4
月份有工资记录的所有学生名字。
6
,计算每个月份的总工资
使用
Stream API
对工资数据进行分组,计算每个月份的总工资。
7
,找出工资最高的月份
对工资据进行聚合操作,找出工资最高的月份及其总工资。
8
,按工资将学生分组
使用
Stream API
将学生按工资区间进行分组,例如:低工资组、中工资组和高工资组。
2024/5/10 12:04
stock
localhost:3000/print.html
163/178
请编写代码删除数组中索引为
1
,
3
,
5
,
7
,
9
的数据。
[2, 3,0, 1, 4, 5, 8, 9, 6, 7]
2024/5/10 12:04
stock
localhost:3000/print.html
164/178
Rouyi
1.
初始化数据库
1.
创建
ry-cloud
数据库并导入
2.
创建
rc-config
数据库并导入
3.
创建
rc-seata
数据库并导入
2.
搭建配套
Nacos
1.
下载源代码
2.
编译和安装
3.
编译并修改数据库配置
4.
启动
git clone https://github.com/alibaba/nacos.git
mvn -Prelease-nacos -Dmaven.test.skip=true clean install -U -Drat.skip=true
# -P
表示
profile
# -Dmaven.test.skip=true
跳过测试阶段
# -Drat.skip=true
跳过
license
检查
# -U
强制刷新依赖
#
编译后在路径
distribution\target\nacos-server-2.1.0\nacos\conf
下
### Connect URL of DB:
spring.datasource.platform=mysql
### Count of DB:
db.num=1
### Connect URL of DB:
#
如果是
mysql8.0
,需要在原来的基础上加上这个参数
&allowPublicKeyRetrieval=true
db.url.0=jdbc:mysql://127.0.0.1:3306/ry-config?
characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=tru
e&useUnicode=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
db.user=dev
db.password=123456
2024/5/10 12:04
stock
localhost:3000/print.html
165/178
5.
关闭
3.
修改
Nacos
中的配置文件
1. auth
2. system
3. gen
4. job
4.
启动服务端
1. RouYiGatewayApplication
2. RouYiAuthApplication
3. RouyiSystemApplication
6.
前端运行
cd distribution/target/nacos-server-$version/nacos/bin
#
注意上面的
$server
需要换成你点前的版本
#
例如我使用时的版本为
2.3.0-SNAPSHOT
cd distribution\target\nacos-server-2.3.0-SNAPSHOT\nacos\bin
# windows
startup.cmd -m standalone
# linux
sh startup.sh -m standalone
#linux
sh shutdown.sh
#windows
shutdown.cmd
#
以下都是修改
mysql
的链接配置,具体可以参考上面的配置修改
cd ruoyi-ui
npm install --registry=https://registry.npmmirror.com
npm run dev
2024/5/10 12:04
stock
localhost:3000/print.html
166/178
7.
登录
(admin/admin123)
2024/5/10 12:04
stock
localhost:3000/print.html
167/178
Jekins
1.
安装
1.
Jenkins
下载
2.
启动
3.
初始化 访问
http://localhost:8080
,
按照 系统指示初始化系统。
2.Hello world
1.
在项目中中添加命名为
Jenkinsfile
的文件
windows
环境中,上面的
sh
换成
bat
。
2.
在
Jenkins
中新建一个项目
3.
选择
Add Source(
添加资源
)
选择使用的仓库
4.
保存并观察运行
2. Jenkins
构建类型
1.
自由风格软件项目
配置源代码路径
编译步骤中执行
shell
2. maven
项目
java -jar jenkins.war -httpPort=8080
pipeline {
agent { docker 'maven:3.3.3' }
stages {
stage('build') {
steps {
sh 'mvn --version'
}
}
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
168/178
3.
流水线项目
pipeline
需要创建一个
Jenkinsfile
文件。可以放到源代码中也可以由
Jenkins
来管理。编写方
式有声明式和
script
两种方式。
2024/5/10 12:04
stock
localhost:3000/print.html
169/178
ai
AI
的兴起对软件开发影响之大无法想象。未雨绸缪,我们一定要接触
ai
,利用
ai
。借用美国佬的一
句话:
要么你学会使用
ai
,要么被
ai
替换
但是现在
ai
还不够强大,使用时需要有一些技巧。借下面的例子给大家讲一下:
1.
在
ai
的帮助下解决资源使用时间总计问题。
1.1
问题出现
1.2
问题分析
ai
很聪明,但不够智慧,它现在还不能解决复杂的问题,所以我们可以将复杂的问题分解为简单的
问题来让他解决。
2024/5/10 12:04
stock
localhost:3000/print.html
170/178
让
ai
帮助我们生成测试数据
2024/5/10 12:04
stock
localhost:3000/print.html
171/178
让
ai
根据测试数据生成处理数据的代码
看看
ai
生成的代码
2024/5/10 12:04
stock
localhost:3000/print.html
172/178
from
datetime
import
datetime
#
原始数组
array = [
{
'res_id'
:
1
,
'start_time'
:
'2023-01-01 09:00:00'
,
'end_time'
:
'2023-01-01
10:00:00'
},
{
'res_id'
:
2
,
'start_time'
:
'2023-01-01 11:00:00'
,
'end_time'
:
'2023-01-01
12:00:00'
},
{
'res_id'
:
1
,
'start_time'
:
'2023-01-01 14:00:00'
,
'end_time'
:
'2023-01-01
15:00:00'
},
{
'res_id'
:
3
,
'start_time'
:
'2023-01-01 16:00:00'
,
'end_time'
:
'2023-01-01
17:00:00'
},
]
#
用于存储每个资源
ID
的总使用时间的字典
resource_usage = {}
#
遍历数组中的每个元素
for
item
in
array:
res_id = item[
'res_id'
]
start_time = datetime.strptime(item[
'start_time'
],
'%Y-%m-%d %H:%M:%S'
)
end_time = datetime.strptime(item[
'end_time'
],
'%Y-%m-%d %H:%M:%S'
)
#
计算单个资源的使用时间(以秒为单位)
usage_time_seconds = (end_time - start_time).total_seconds()
#
将资源
ID
的总使用时间累加到字典中
if
res_id
in
resource_usage:
resource_usage[res_id] += usage_time_seconds
else
:
resource_usage[res_id] = usage_time_seconds
#
打印每个资源的使用时间
for
res_id, usage_time
in
resource_usage.items():
print(
f"Resource ID {res_id} usage time: {usage_time} seconds"
)
#
如果需要将使用时间转换为更易读的格式(例如小时、分钟和秒)
def
format_time
(
seconds
):
hours, remainder = divmod(seconds,
3600
)
minutes, seconds = divmod(remainder,
60
)
return
f"{int(hours)}h {int(minutes)}m {int(seconds)}s"
for
res_id, usage_time
in
resource_usage.items():
formatted_time = format_time(usage_time)
print(
f"Resource ID {res_id} usage time: {formatted_time}"
)
2024/5/10 12:04
stock
localhost:3000/print.html
173/178
Java
锁 介绍
Java
中的锁分为两类
:
一
. Synchronized
使用场景
Synchronized
是
Java
语言层面提供的锁,它既可以修饰方法,也可以修饰代码块。 修饰方法时,
锁住的是当前对象。修饰代码块时,锁住的是指定的对象。
锁的实现原理
1.
对象在内存中的布局
对象头
hashcode,
对象分代年龄
轻量级锁
重量级锁
实例数据
对齐填充
2.
老版本
synchronized
锁定 直接使用操作系统的
Mutex Lock
来实现的,但是使用它涉及线程
的阻塞和唤醒比较耗费
CPU
,因此从性能上有一定问题。
public class
SynchronizedDemo
{
private int
i;
public synchronized void
increment
()
{
i++;
}
public void
other
()
{
synchronized
(
this
) {
//
指定锁对象
i++;
}
}
public synchronized void
increStatic
()
{
//
静态方法
}
}
2024/5/10 12:04
stock
localhost:3000/print.html
174/178
3.
新版本
synchronized
锁定 涉及到了锁的升级过程,从无锁到偏向锁,到轻量级锁再到重量级
锁。
偏向锁
轻量级锁
重量级锁
二
. Lock
(
jdk5
)
与
synchronized
相比,
Lock
的使用稍微麻烦一些,需要手动加锁和解锁。
但是它有如下的好处:
1.
可以设置锁的超时时间,避免死锁。
2.
支持公平锁。
记下当前线程
ID
,如果线程
ID
相同,则直接进入锁,否则升级为轻量级锁。
由虚拟机实现,当并发不大时优先使用轻量级锁,而轻量级锁是使用
CAS
来实现,代价更小。
使用操作系统互斥锁来实现,
import
java.util.concurrent.locks.ReentrantLock;
public class
ReentrantLockTest
{
private final
ReentrantLock lock =
new
ReentrantLock();
public void
writeDiary
()
{
lock.lock();
//
上锁
try
{
//
做一些事情
}
finally
{
lock.unlock();
//
释放锁
}
}
}
public boolean
tryLock
(
long
timeout, TimeUnit unit)
throws
InterruptedException
;
2024/5/10 12:04
stock
localhost:3000/print.html
175/178
Lock
的实现原理
以
ReentrantLock
为例,底层是基于
AQS
和
CAS
来实现的。
AQS
是
AbstractQueuedSynchronizer
的缩写,是
Java
中用来构建锁和同步器的框架。它维护了一个
FIFO
的等待队列,使用一个状态变量
来控制对 共享资源的访问,这个状态变量可以通过
CAS
操作来进行原子性的更新。
三
.
两种锁的比较
1. synchronized
没有灵活性,
Lock
使用更灵活,例如在一个方法中获取,另一个方法释放。
2. synchronized
更简单安全,
Lock
需要程序员控制,容易遗忘。
3. synchronized
是非公平锁,
Lock
支持公平和非公平锁。
4. synchronized
无法限制等待时间,无法监控锁的信息,
Lock
具有更多方法实现灵活的功能。
5.
默认使用
synchronized
,如果需要使用
Lock
,可以调用
synchronized
的实现。
四
.
其他分类方法
根据锁的特性
1.
悲观锁
2.
乐观锁
根据是否公平
1.
公平锁
2.
非公平锁
看法悲观,因此是先获取锁,然后再去执行。
看法乐观,因此是先去尝试执行,直到成功。
按照申请顺序来获取锁
效率高
2024/5/10 12:04
stock
localhost:3000/print.html
176/178
是否独占
1.
独占锁
2.
共享锁
volatile
关键字
用以实现线程间的通信,保证可见性。
禁止指令重排序
线程对变量修改后,立刻写回主存。
线程对变量读取时要从主存读取。
ReentrantLock
和
synchronized
都是独占锁,即同一时刻只能有一个线程持有锁。
ReentrantdWriteLock
的读锁是共享锁,即同一时刻可以有多个线程持有锁。
2024/5/10 12:04
stock






















 1540
1540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









