







进程与线程
CPU执行作业的顺序都是一样的。操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,这些任务都在就绪对列中等待,这样反复执行下去。物理层,每个任务都是交替执行的,但是,由于CPU的执行速度都非常快,逻辑上,就像所有任务都在同时执行一样。
对于操作系统来说,一个任务就是一个进程(Process)。在一个进程内部,需要同时执行多个任务,我们把进程内的这些“子任务”称为线程(Thread)。如:一个音乐播放器进程,需要运行声卡的线程(播放音频),有需要运行显卡的线程(显示歌词)。
多进程与多线程:
要加快任务的执行速度或要同时完成多个任务,就需要利用多进行或多线程。启动多个进程,每个进程虽然只有一个线程,但多个进程可以一块执行多个任务。还有一种方法是启动一个进程,在一个进程内启动多个线程,这样,多个线程也可以一块执行多个任务。
进程
Python的os模块封装了常见的系统调用。multiprocessing模块是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象。
from multiprocessing import Process
import os
def proc():
print("one of process is running...")
if __name__ == '__main__':
print("%s process is running..." % (os.getpid()))
print("Child process is start...")
p = Process(target=proc())
p.start()
p.join()
print("Child process end")
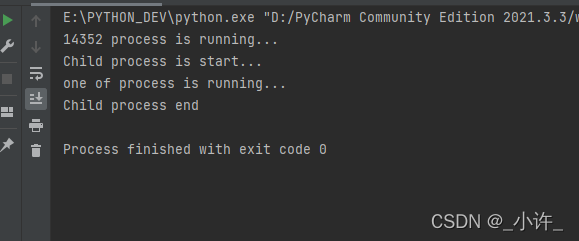
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。子进程只需要调用getppid()就可以拿到父进程的ID。
进程池(Pool)
要启动大量的子进程,可以用进程池的方式批量创建子进程。multiprocessing模块的Pool用于创建进程池。
from multiprocessing import Pool
import os, time, random
def __random_task():
start = time.time()
time.sleep(random.random()*3)
end = time.time()
print("%s process cast %0.2f seconds" % (os.getpid(), end-start))
if __name__ == '__main__':
pool=Pool(3)
for i in range(4):
pool.apply_async(__random_task())
print("wait all process start...")
pool.close()
pool.join()
print("all process end")

import time
from multiprocessing import Pool
def __task_one():
total = 0
for i in range(100):
total = total + i
print(total)
def __task_two():
total = 0
for i in range(5):
total = total + i ** 2
print(total)
def __task_three():
total = 1
for i in range(1, 10):
total = total * i
print(total)
if __name__ == "__main__":
pool = Pool(3)
start = time.time()
pool.apply_async(__task_one())
pool.apply_async(__task_two())
pool.apply_async(__task_three())
time.sleep(1)
end = time.time()
print("spend time %.2f" %(end-start))
Pool对象调用join()方法会将子进程加入到主进程中,便于进程的通讯。
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,
1、apply()
函数原型:apply(func[, args=()[, kwds={}]])
该函数用于传递不定参数,同python中的apply函数一致,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不在出现)。
2、apply_async
函数原型:apply_async(func[, args=()[, kwds={}[, callback=None]]])
与apply用法一致,但它是非阻塞的且支持结果返回后进行回调。
3、map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到结果返回。
注意:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
4、map_async()
函数原型:map_async(func, iterable[, chunksize[, callback]])
与map用法一致,但是它是非阻塞的。其有关事项见apply_async。
5、close()
关闭进程池(pool),使其不在接受新的任务。
6、terminal()
结束工作进程,不在处理未处理的任务。
7、join()
主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用。
线程
Python3 通过两个标准库 _thread和threading提供对线程的支持。
_thread提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
run(): 用以表示线程活动的方法。
start():启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
python3中推荐使用threading
threading模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
-
threading.currentThread(): 返回当前的线程变量。 -
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 -
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法: -
run(): 用以表示线程活动的方法。 -
start():启动线程活动。 -
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。 -
isAlive(): 返回线程是否活动的。 -
getName(): 返回线程名。 -
setName(): 设置线程名。
继承Thread类创建线程
通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程。Thread是一个类,用于创建线程,暴露了许多接口用于操作该线程。
import threading
class thread_one(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.name = threading.current_thread().name
def getName(self):
print(self.name)
if __name__ == '__main__':
one = thread_one()
two = thread_one()
one.start()
print("one threadTest start ")
two.start()
print("tow threadTest start")
one.join()
two.join()
继承Thread类后,其实例就是一个进程,通过编写继承类,传入方法来完成任务。继承类中必须要调用初始化函数Thread.__init__(self)。继承的好处是再线程的生命周期内可以重写完成额外任务的方法。
通过threading库的接口创建线程
除了通过继承Thread类外也可以使用threading的接口来创建线程,但是这样不能重写类方法。
t1 = threading.Thread(target=run_thread, name="one_thread", args=(5,))
t2 = threading.Thread(target=run_thread, name="two_thread", args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
Thread(group=None, target=None, name=None, args=(), kwargs={})接口有这些参数,其意义是:
group应当为 None,为将来实现Python Thread类的扩展而保留。
target是被 run()方法调用的回调对象(指向某个函数). 默认应为None, 意味着没有对象被调用。
name为线程名字。默认形式为’Thread-N’的唯一的名字被创建,其中N 是比较小的十进制数。
args是目标调用参数的tuple,默认为空元组()。
kwargs是目标调用的参数的关键字dictionary,默认为{}。
实现类方法
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.main_thread():返回主线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
run(): 用以表示线程活动的方法。 继承类重写的方法。若是接口实现和target参数指向方法名。
start():启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
继承实现线程能提供更多功能。
线程同步
在进程的若干线程中,往往多个线程辅助主线程完成作业,而不是一个个独立的存在。而对于新创建的线程就是独立的,之间的数据并不共享。
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。
import threading
total = 100
def accept_send(n):
global total
total = total - n
total = total + n
def times(n):
for i in range(2000000):
accept_send(n)
if __name__ == '__main__':
t1 = threading.Thread(target=times, args=(8,))
t2 = threading.Thread(target=times, args=(10,))
t1.start()
t2.start()
t1.join()
t2.join()
print(total)
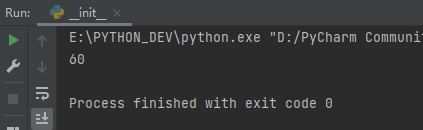
上面代码新建线程后各自完成各自的任务,数据并没有同步。
实际上一个进程的多个线程之间数据是需要同步的。可以使用共享数据锁可以实现对共享数据的同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire方法和 release方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。

Lock锁
Lock也是一个类同样可以通过继承和接口创建共享锁。lock = threading.Lock()。
# 创建锁
lock = threading.Lock()
# 获取锁:
lock.acquire()
# 一定要释放锁:
lock.release()
# 执行逻辑在获取和释放之间
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try…finally来确保锁一定会被释放。也就是当其他线程执行该执行体时,须等上一个施加共享锁的用户释放后才可以执行,这样就确保数据同步。
import threading
total = 100
# 创建共享锁
lock = threading.Lock()
def accept_send(n):
global total
total = total - n
total = total + n
def times(n):
for i in range(2000000):
# 施加共享锁
lock.acquire()
try:
accept_send(n)
finally:
lock.release()
if __name__ == '__main__':
t1 = threading.Thread(target=times, args=(8,))
t2 = threading.Thread(target=times, args=(10,))
t1.start()
t2.start()
t1.join()
t2.join()
print(total)
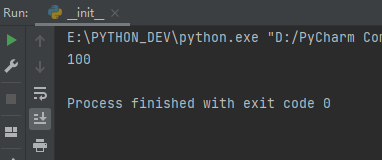
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
Lock用于实现简单的共享锁,Rlock运行共享锁中再施加共享锁。两种琐的主要区别是:RLock允许在同一线程中被多次acquire。而Lock却不允许这种情况。如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的锁。


还有一个更高级的锁Condition它提供了比Lock, RLock更高级的功能,允许我们能够控制复杂的线程同步问题。Condition在内部维护一个锁对象(默认是RLock),可以在创建Condigtion对象的时候把锁对象作为参数传入。Condition还提供了如下方法( 这些方法只有在占用锁(acquire)之后才能调用,否则将会报RuntimeError异常。)
Condition.wait([timeout]):wait方法释放内部所占用的锁,同时线程被挂起,直至接收到通知被唤醒或超时(如果提供了timeout参数的话)。当线程被唤醒并重新占有锁的时候,程序才会继续执行下去。
Condition.notify():唤醒一个挂起的线程(如果存在挂起的线程)。注意:notify()方法不会释放所占用的锁。
Condition.notify_all()或Condition.notifyAll()唤醒所有挂起的线程(如果存在挂起的线程)。注意:这些方法不会释放所占用的锁。
线程优先级队列( Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
对列的创建:
queue.Queue(maxsize) FIFO(先进先出队列)
Queue.LifoQueue(maxsize) LIFO(先进后出队列)
Queue.PriorityQueue(maxsize) 为优先级越高的越先出来,对于一个队列中的所有元素组成的entries,优先队列优先返回的一个元素是sorted(list(entries))[0]。至于对于一般的数据,优先队列取什么东西作为优先度要素进行判断,官方文档给出的建议是一个tuple如(priority, data),取priority作为优先度。
maxsize设置队列最大长度,如果设置的maxsize小于1,则表示队列的长度无限长
Queue 模块中的常用方法:
Queue.qsize()返回队列的大小
Queue.empty()如果队列为空,返回True,反之False
Queue.full()如果队列满了,返回True,反之False
Queue.full与 maxsize 大小对应
Queue.get([block[, timeout]])获取队列中的线程,timeout等待时间
Queue.get_nowait()相当Queue.get(False)
Queue.put(item,timeout)写入队列,timeout等待时间
Queue.put_nowait(item,timeout)相当Queue.put(item, False)
Queue.task_done()在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
Queue.join()实际上意味着等到队列为空,再执行别的操作
通过
put方法将线程放到对列中,get获取对列的线程,这个就是对列的存取,满足构建对列是的规则,如先进先出,或其他。要取出所有线程需要循环。和C语言的队列一样。
import threading
import queue
def func_one():
for i in range(1, 5):
print(i)
def func_two():
for i in range(6, 10):
print(i)
def func_three():
for i in range(11,15):
print(i)
if __name__ == "__main__":
t1 = threading.Thread(target=func_one, name="one_thread")
t2 = threading.Thread(target=func_two, name="one_thread")
t3 = threading.Thread(target=func_three, name="one_thread")
'''
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
'''
# 创建对列
queue_list = queue.LifoQueue(5)
lock = threading.Lock()
# 线程入队
lock.acquire()
queue_list.put(t1,block=True, timeout=None)
queue_list.put(t2,block=True, timeout=None)
queue_list.put(t3,block=True, timeout=None)
lock.release()
# 线程出队
for i in [1,2,3]:
queue_list.get().start() # 出队返回值是线程,调用线程方法开启线程
#等待对列清空
queue_list.join()
print("线程对列结束")
在上面代码中创建了三个线程,分别put方法加入到对列,通过循环get取出,由于创建的是LifoQueue()后进先出,所以出队时也满足规则。(若创建用 Queue,这先进先出)
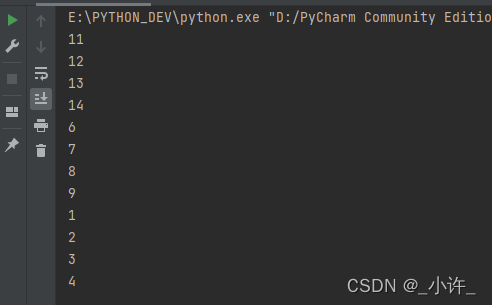
出队的返回值是线程,调用线程方法进行操作,如start()(queue_list.get().start())开启线程。
python3__多线程__threading、_thread、Queue
queue核心
在创建线程队列不同的方法出队规则不一样:
queue_list = queue.LifoQueue(maxsize)LIFO (后进先出)
queue_list = queue.Queue(maxsize)FIFO (先进先出)
queue_list = queue.PriorityQueue(maxsize)(优先级对列)
入队使用put方法:
Queue.put(item,timeout)
出队使用get方法,返回值是一个线程:
thread = queue.Queue().get()
开启出队的线程:
thread = queue.Queue().get()
# 开启出队线程
thread.start()
# 等待线程结束
thread.join()
















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











