







 本文介绍了Python中的分支和循环结构,包括if、elif、else关键字的使用,以及for和while循环的应用。通过实例展示了如何利用这些结构进行条件判断和重复执行任务。
本文介绍了Python中的分支和循环结构,包括if、elif、else关键字的使用,以及for和while循环的应用。通过实例展示了如何利用这些结构进行条件判断和重复执行任务。
分支结构
- 关键字:if、elif、else
- 缩进
a = 2
if a ==0:
print("a=0")
elif a == 1:
print("a=1")
elif a == 2:
print("a=2")
else:
print("a不等于0、1、2")
# a=2
“Flat is better than nested”:
提倡代码“扁平化”因为 嵌套结构的嵌套层次多了之后会严重的影响代码的可读性
循环结构
- 循环语句允许我们执行一个语句或语句组多次
- python 提供了for循环和while循环
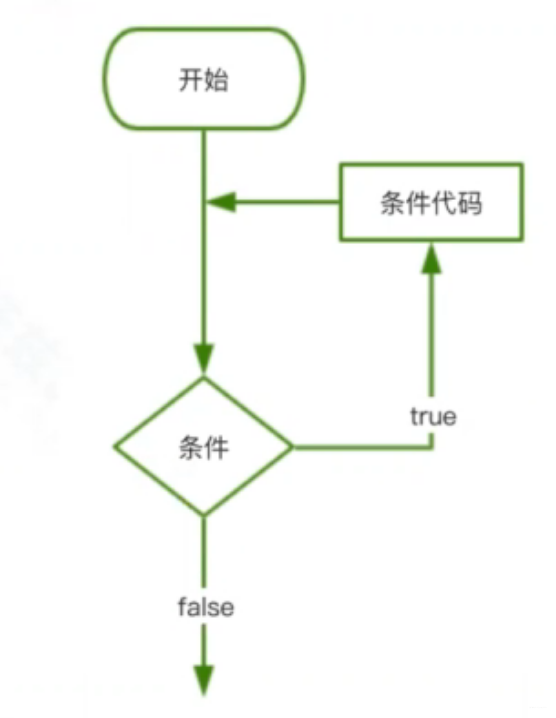
for-in循环:
如果明确的知道循环执行的次数或者要对一个容器进行迭代(推荐使用for-in)
-
range函数:
-
range可以用来产生一个不变的数值序列
range(101)可以产生一个0到100的整数序列
range(1,100)可以产生一个1到99的整数序列
range(1,100,2)可以产生一个1到99的奇数序列,步长是2
"""
1.计算1~100 求和
"""
result = 0
for i in range(101):
result = result + i
print(result) # 5050
"""
2.加入分支结构实现 1~100之间的偶数求和
"""
result = 0
for i in range(101):
if i%2==0:
result += i
print(result)
"""
3.使用python实现 1~100之间的偶数求和
"""
result = 0
for i in range(2,101,2):
result += i
print(result)
while循环:
- 若要构造不知道具体循环次数的循环结构,推荐使用 while循环。
- 通过一个能够产生或转换出bool值的表达式来控制循环(True:循环继续,False:循环结束)
a = 1
while a==1:
print("a==1")
a = a+1
else:
print("a!=1")
print(a)
# a==1
# a!=1
# 2
break 和 continue 语句
- break:跳出循环
- continue:跳过当前循环块中的剩余语句,进入下一轮循环
# 猜数字游戏
import random
computer_number = random.randint(1,100)
while True:
person_number = int(input("请输入一个数字"))
if person_number > computer_number:
print("小一点")
elif person_number < computer_number:
print("大一点")
elif person_number == computer_number:
print("猜对啦!!!")
break

















 3007
3007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









