






在教材上都会讲如何通过真值表通过门电路实现加法器,但是作为 RTL 设计工程师,实际上并不需要从门电路开始写,而是使用“+”号调用综合库的 IP 即可。一般来说,IP 库的加法会比自己重新写的快。因此相较于如何写定点数加法,IC 工程师更应该懂得如何“复用”加法器。现在考虑下面的功能:
功能需求
设计一个加法器,可以完成 4 个 byte 或者 2 个 short 或者一个 32 比特数据的加法,需要支持有符号,无符号以及饱和截断功能。
设计分析
核心问题:如何使用最少的加法逻辑完成不同的加法功能?
使用iAdda[31:0]和iAddb[31:0]分别表示两个加数输入,iAddcin[3:0]表示进位。当加法器进行32比特加法时,iAdda和iAddb正好是两个加数,使用iAddcin[0]表示32比特加数来自低位的进位;该加法器可以作为2个16比特加法器使用,此时iAdda[31:16]和iAddb[31:16]对应为第一个16比特加法器的两个加数,iAdda[15:0]和iAddb[15:0]对应为第二个16比特加法器的两个加数,iAddcin[2]和iAddcin[0]分别是第一个16比特加法器和第二个16比特加法器来自低位的进位;加法器还可以作为4个8比特加法器使用,此时iAddcin[i]为第i个加法器来自低位的进位。iAddtype[1:0]表示加法器类别, iAddsign[3:0] 表示加法器是有符号数加法还是无符号数加法,iAddsat[3:0]表示加法器采用饱和还是截断方式进行。oAddsum[31:0]表示加法器输出,在word、short和byte类型加法时,其输出字段与输入对应;oAddcout[3:0]表示进位输出,其字段也和输入对应;oAddspill[3:0]表示加法器是否溢出,在有符号加法时,溢出包含了上溢和下溢。各接口特性和对应取值含义如下表:
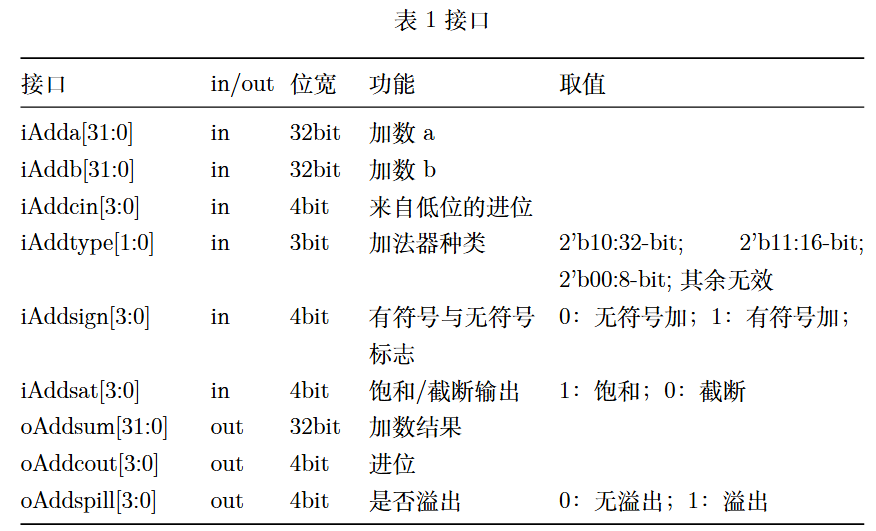
注:作为32-bit加法器时,iAddcin[3:0],iAddsign[3:0]和oAddcout[3:0]仅最低位有效;作为两个16-bit加法器时,第2比特和第0比特有效;作为四个8-bit加法器时,全部比特位有效;
如何判断有符号加法和无符号加法溢出?
对于无符号加法,当有向高位的进位时表示有溢出;对于有符号加法,溢出的判断主要是两种情况:
- 正数+正数=负数 —— 即两个加数最高位为0而进位为1
- 负数+负数=正数 —— 即两个加数最高位为1而进位为0
可以为加数进行高位扩展,无符号扩展0,有符号扩展符号位(即双符号位)。无符号和的最高位为1时表示溢出,有符号最高位和次高位不同时表示溢出。
三种微架构实现
v1:行波进位加法器
这里三种微架构的基本思想是使用4个byte加法器实现该需求,在不同的数据类型时使用不同的拼接方式即可。
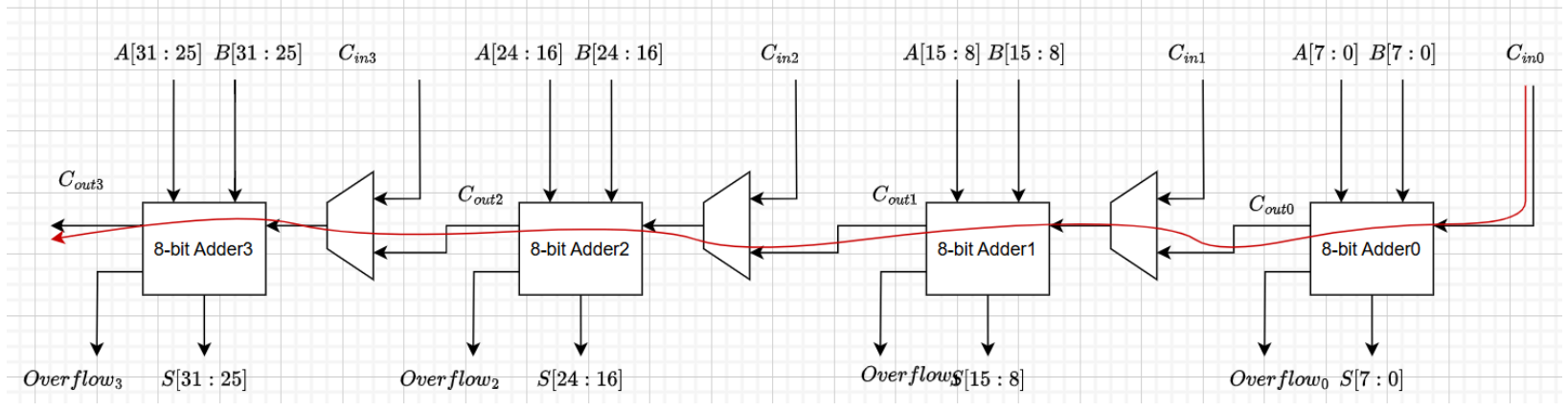
上图显示了行波进位加法器的加法结构,它由三个基本的byte加法器连接而成。使用4个byte寄存器构成。在图中,从右往左四个8比特加法器依次计算。最低位的byte加法器直接使用iAddcin[0]作为进位,因为在word、short和byte加法器时该信号含义一致。从右往左的三个byte加法器的进位则需要根据加法器类型进行判断。当进行word加法操作时,所有的加法器均使用来自上一个加法器的进位输出作为自己的进位输入。当进行short加法时,加法器1和加法器3使用上一个加法器的进位输出作为自己的进位输入,而加法器2则使用iAddcin[2]作为进位输入(图中记为Cin2)。当加法器作为byte加法器计算时,每个加法器都使用对应的iAddcin作为进位输入。关键路径如红色曲线所示,可以看到加法器的延时主要来源于进位的传播。
图中没有画出饱和截断时的处理操作。当饱和选项iAddsat有效时,饱和判断的处理流程如下:1、判断有符号还是无符号运算;2、在无符号时根据加法器类型判断对应的进位输出是否为1,为1时则产生饱和数据,即无符号最大值。有符号时使用加数iAdda,iAddb以及相加结果对应类型下的最高位判断产生上溢还是下溢,从而产生对应的有符号数最大值和有符号数最小值。
v2: 进位旁路
对于一个二进制的全加器,以A和B作为加法的输入,Ci作为进位输入,S作为和输出,Co时进位输出,则可以得到以下真值表:
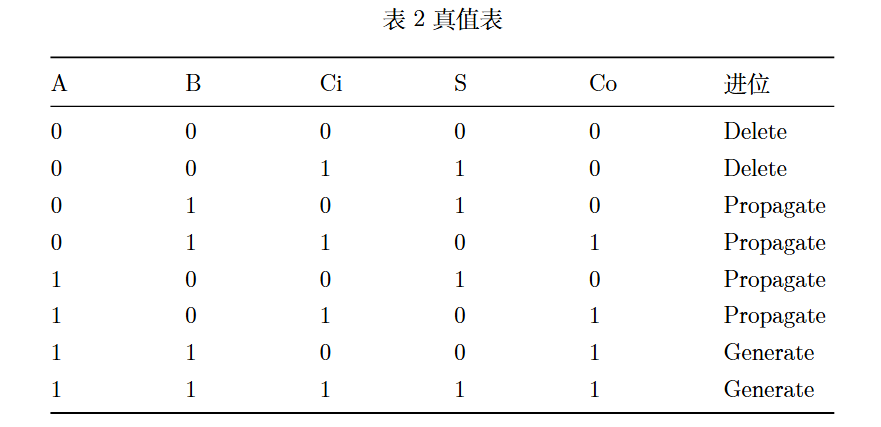
由以上真值表可以看出,当A,B,Ci有奇数个1时,S为1,因此有 。当A,B,Ci有两个以上为1时,进位输出为1,因此有Co = AB + BCi + CiA 。如果更仔细的观察上述真值表,可以看到,当A和B其中有一个值为1时,则Co = Ci,此时相当于Ci的值传到了Co(Propagate)。当A和B都是1时,则Co一定为1,此时称为Generate。
传播信号P和产生信号G可以由A和B决定:
根据上述关系,可以将Co写为:
现在考虑多比特的全加器,以4比特为例,记加数为Ai和Bi( 0 < i <= 4),进位输入表示为C0,进位输出表示为C4,那么输出进位可以计算如下:
C4 = G4 + P4C3
= G4 + P4(G3 + P3C2)
= G4 + P4(G3 + P3(G2 + P2C1))
= G4 + P4(G3 + P3(G2 + P2(G1 + P1C0)))
= G4 + P4G3 + P4P3G2 + P4P3P2G1 + P4P3P2P1C0
此时可以看到当P4P3P2P1为1时,C4 = C0,而P4P3P2P1为0时,则由Pi和Gi产生进位输出,此时进位输出与进位输入无关。因为对于多比特的加法器还可以采用下图的结构实现。
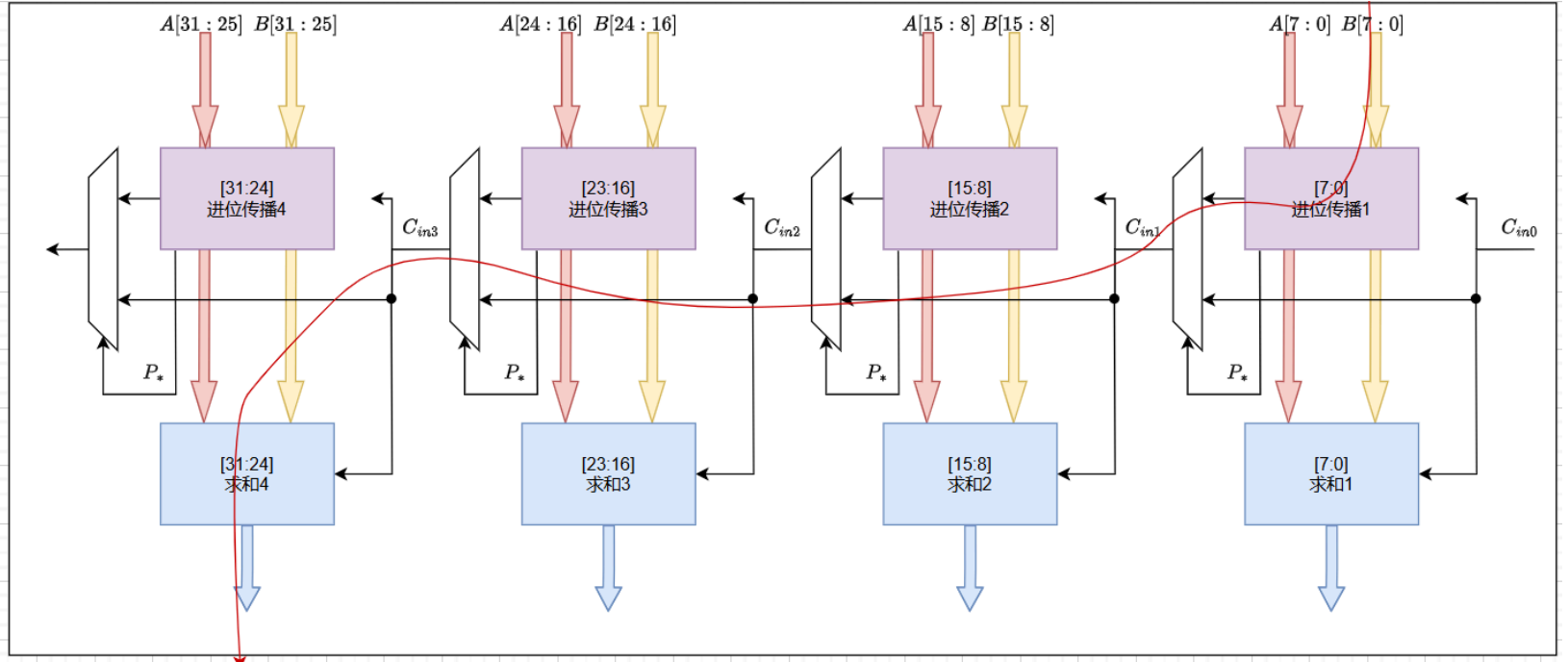
由于加法器的关键路径是在word类型计算的时候,因此上图画出了word类型时的数据路径图。当配置为short类型或者byte类型加法器时,可以通过配置选择器的选择信号来完成,其原理与v1的行波进位加法器相同。该加法器分为上下两个部分,上半部分根据加数计算相应的传播信号和生成信号,并根据传播信号的值 (P^∗ = PiPi+1……Pi+7)决定是将来自上一个信号的进位直接送到下一个加法器还是重新计算。由于四个进位模块不依赖与其他的进位模块,因此他们可以直接计算,并同时产生选通信号。因此关键路径如红色曲线所示,从进位传播1产生进位,经过两次选择器后到求和4模块进行求和求得最高值。
v3:进位选择
影响传播延时的关键路径是进位信号的传播路径,因为高位的加法无法确定来自低位的进位的值是多少,因此需要等待低位进位的到来。实际上,低位的进位只有两种可能,即0和1。因此,下图的加法器结构预先给高位的加法器两种进位情况,让他们完成计算,等来自低位的进位值确定时再根据进位值选择对应的计算结果。
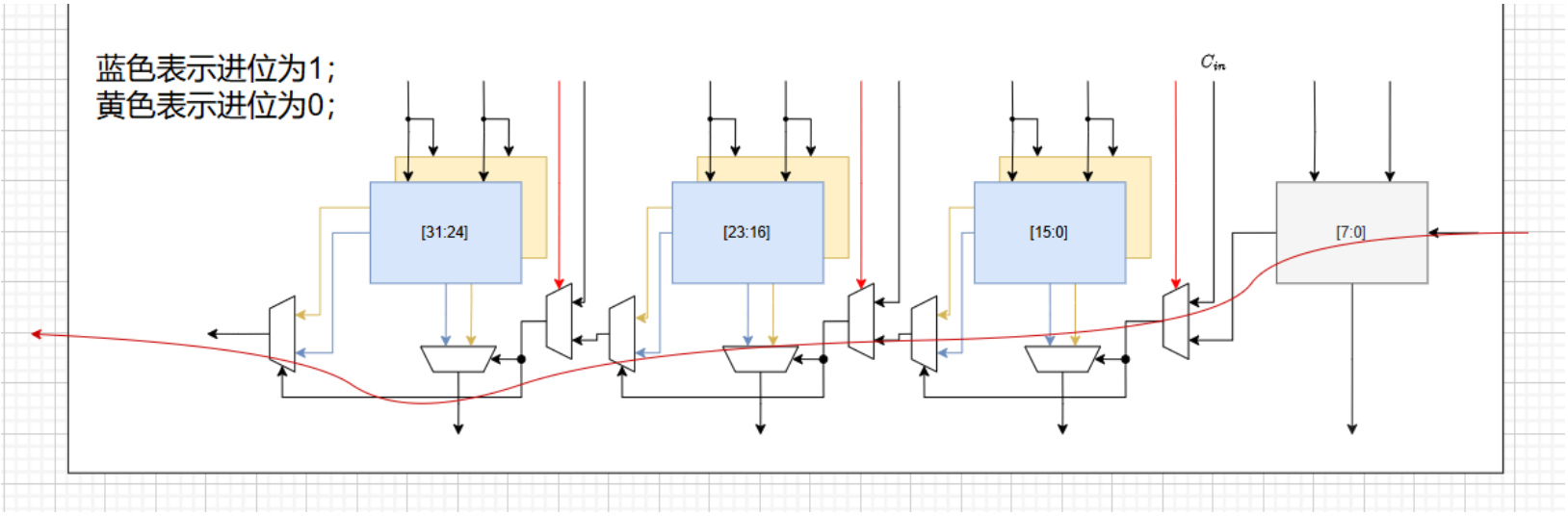
该加法器由4个8比特加法器构成,高位的三个8比特加法器复制两份,分别假设低位来自低位的进位为0或者1并将计算结果和对应的进位输出送到选择器,选择器的选通信号即来自低位8比特加法器的进位输出。所有的8比特加法器都是同时开始计算的,因此该结构的关键路径从第一个加法器开始,并经过高位的结果选择器到达最终的进位输出,如红色曲线所示。
综合结果
将三种设计都进行了VCS编译且tb验证通过后进行综合,设置最大延时为0,最大面积为99,并且写了32比特、16比特以及8比特直接相加的加法器作为对比(调用IP),对比结果如下:
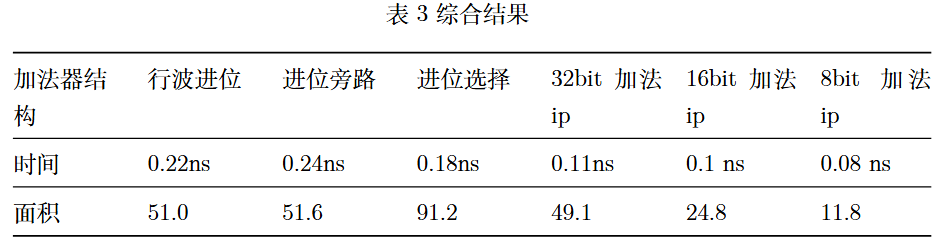
可以看到三种实现方法中,进位选择最快,这是在意料之中的,然后是行波进位,再然后是进位旁路。进位旁路比行波进位慢是有点出乎意料的,分析过后个人认为其原因是DC对加法器的优化做的极好,因此进位经过加法器的传播比经过G,P计算的快。此外,通过比较32比特、16bit以及8比特加法ip看,它们的延时不是线性的,但是面积又基本保持线性,这说明在多比特加法器设计时,不要拆分得太散,尽量让它作为整个加法器综合可能性价比更高。
更快的微架构
之前总结了DC综合出的加法器速度和位宽是非线性关系,这意味着两个8比特的加法进行拼接不如直接实现一个16比特的加法器快。前面三种微架构的思想都是实现4各byte加法器合成一个word加法器,现在换一种思路,使用一个word加法器拆分完成4个byte粒度的加法器。
该架构的实现思想是先对两个加数进行处理拼接,然后使用一个完整的加法器进行相加,让DC综合这个完整的加法器,获得更快的速度,然后再对加法的结果分离得到对应数据粒度的数。
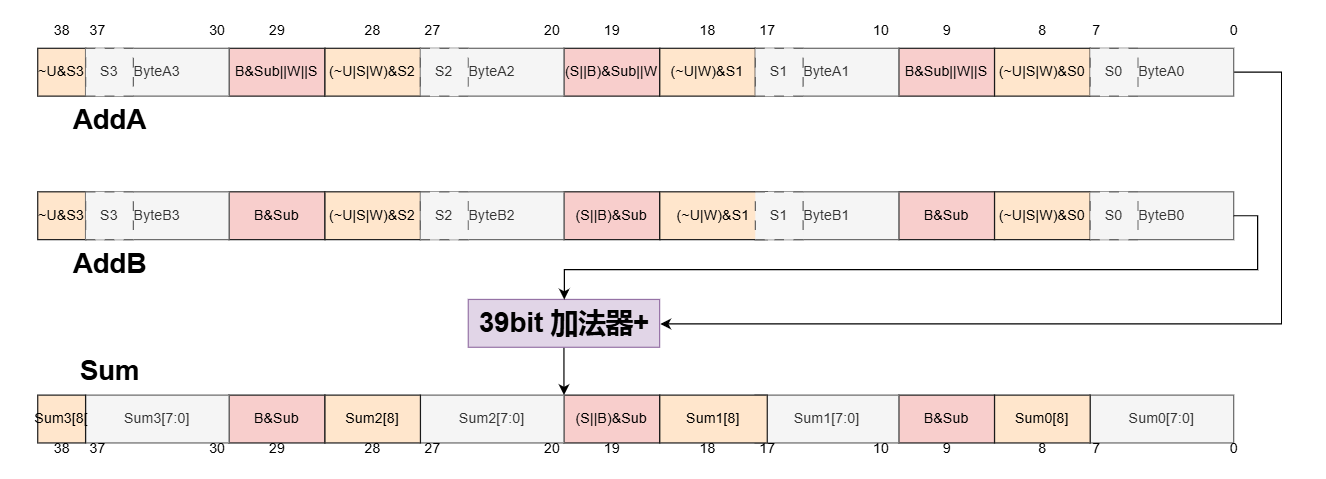
对加数的处理如上图所示,它将4对byte数据进行拼接分别,并在拼接处加上扩展比特(黄色字段)和进位比特(粉色字段)。其中ByteA表示加数A,而ByteB在加法操作时表示加数B,在减法操作时表示加数B的取反。扩展字段用于各粒度时候的溢出检测,进位比特用于作为进位通道和减法的最低位加1选项。下面分各数据粒度情况说明该架构原理:
- Byte加/减法 计算Byte加法时,根据是有符号数还是无符号数对每个byte数据的最高位进行扩展,有符号数时扩展为符号位,无符号数时则扩展为符号位(黄色字段)。在加法操作时,操作数A和操作数B的粉色字段为0,可以避免低位的Byte加数影响高位的Byte加数。在减法操作时,操作数A和操作数B的粉色字段为1,两者相加可以作为取反加1的低位进位1,同时下一个Byte的进位也无法传递到高位的Byte中。
- Short加法/减法 在Short加法时,两个Byte组成一个Short数,此时两个Byte之间的黄色字段进行扩展为Byte的符号位,而Short之间的黄色字段仍然根据有无符号计算设为0或者1。而Short之间的粉色字段都设置为1,但是操作数A的Short内部粉色字段设置为1,操作数B内部粉色字段设计为0,这样低位的Byte的进位可以顺利到达高位。
- Word加/减法 此时Byte,Short的进位都应该传递上去,操作数A的粉色字段均设置为1,操作数B的粉色字段均设置为0。而除了最高位根据有无符号加法进行设置外,其余黄色字段都进行Byte,short数的高位进行扩展。
该架构先对加数进行处理再经过一个39比特的加法器。由于DC工具会将最占时序的加法器综合出最优网表,因此它的时序会比前三者更好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









