







SQL查询
用于查询发布过文章的用户
select * from `users` where exists (select 1 from `posts` where posts.user_id = users.id);```
laravel
```php
$users = DB::table('users')->whereNotNull('email_verified_at')->select('id');
$posts = DB::table('posts')->whereInSub('user_id', $users)->get();
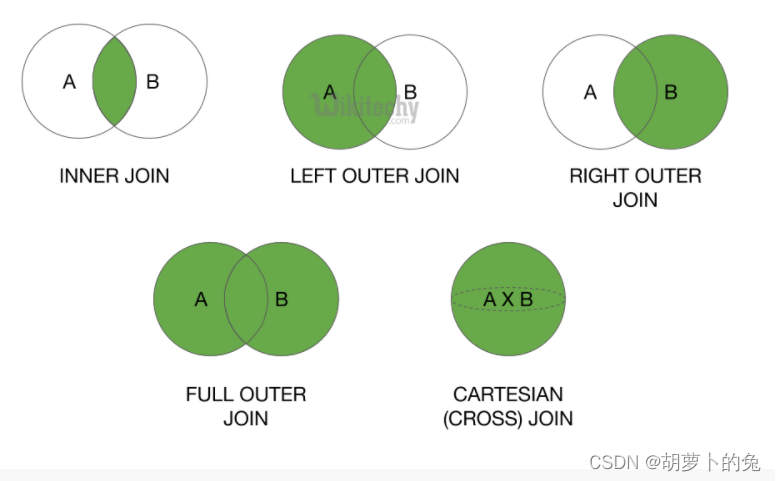
内连接
使用比较运算符进行表间的比较,查询与连接条件匹配的数据,可细分为等值连接和不等连接
等值连接(=):如
select * from posts p inner join users u on p.user_id = u.id
不等连接(<、>、<>等):如
select * from posts p inner join users u on p.user_id <> u.id
外链接:
左连接:
返回左表中的所有行,如果左表中的行在右表中没有匹配行,则返回结果中右表中的对应列返回空值,如
select * from posts p left join users u on p.user_id = u.id
右连接:
与左连接相反,返回右表中的所有行,如果右表中的行在左表中没有匹配行,则结果中左表中的对应列返回空值,如
select * from posts p right join users u on p.user_id = u.id
全连接:
返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值,如
select * from posts p full join users u on p.user_id = u.id
交叉连接:
也称笛卡尔积,不带 where 条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积,如果带 where,返回的是匹配的行数。如
select * from posts p cross join users u on p.user_id = u.id
查找重复的行
SELECT * FROM blog_user_relation a WHERE (a.account_instance_id,a.follow_account_instance_id)
IN (SELECT account_instance_id,follow_account_instance_id FROM blog_user_relation GROUP BY account_instance_id, follow_account_instance_id HAVING
COUNT(*) > 1)
删除重复的行(保留一条)
PS:因为mysql的delete,如果被删的表的where条件里有in,且in里面也有此表,那就删除不了。
/创建个临时表/
CREATE TABLE blog_user_relation_temp AS
(
SELECT * FROM blog_user_relation a WHERE
(a.account_instance_id,a.follow_account_instance_id)
IN ( SELECT account_instance_id,follow_account_instance_id FROM blog_user_relation GROUP BY account_instance_id, follow_account_instance_id HAVING COUNT(*) > 1)
AND
relation_id
NOT IN (SELECT MIN(relation_id) FROM blog_user_relation GROUP BY account_instance_id, follow_account_instance_id HAVING COUNT(*)>1));
/删除数据/
DELETE FROM `blog_user_relation` WHERE relation_id IN (SELECT relation_id FROM blog_user_relation_temp);
/删除临时表/
DROP TABLE blog_user_relation_temp;
查询今天
select * from 表名 where to_days(时间字段名) = to_days(now());
查询昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) – TO_DAYS( 时间字段名) <= 1
查询7天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名)
查询近30天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名)
查询本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, ‘%Y%m' ) = DATE_FORMAT( CURDATE( ) , ‘%Y%m' )
查询上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , ‘%Y%m' ) , date_format( 时间字段名, ‘%Y%m' ) ) =1
查询本季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
查询上季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
查询本年数据
select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
查询上年数据
select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
查询当前这周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
查询上周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
查询当前月份的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(now(),'%Y-%m')
查询距离当前现在6个月的数据
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
查询上个月的数据
select name,submittime from enterprise where date_format(submittime,‘%Y-%m’)=date_format(DATE_SUB(curdate(), INTERVAL 1 MONTH),‘%Y-%m’)
搜索选修课程是税收基础的学生信息
SELECT s.* FROM c JOIN sc ON c.id=sc.cid JOIN s ON s.id=sc.sid WHERE c.cn='税收基础'
查询选修课程大于2门课的学生信息
SELECT m.* FROM( SELECT s.*, count(*) AS aaa FROM s JOIN sc ON s.id=sc.sid GROUP BY s.id)m WHERE m.aaa>3
或者
SELECT s.*,count(*) FROMs JOIN sc ON s.id=sc.sid GROUP BY s.id HAVING count(*)>3
查询学员朱欣磊选修的课程信息
SELECT s.* FROM s JOIN sc ON s.id=sc.sid WHERE s.sn='朱欣磊'
查询没有选择数学课的学生信息
SELECT * FROMs WHERE id NOT IN( SELECT s.id FROM s JOIN sc ON s.id=sc.sid JOIN c ON c.id=sc.cid WHERE c.cn='数学')
先查找的选修了数学的学生,然后排除的
查询没门课选修的人数
SELECT cn,count(*) FROM s JOIN sc ON s.id=sc.sid JOIN c ON c.id=sc.cid GROUP BY cn
查询每个学员选修了几门课程
SELECT sn,count(*) FROM s JOIN sc ON s.id=sc.sid JOIN c ON c.id=sc.cid GROUP BY sn
查询选修课程不及格的学生信息及课程信息
SELECT * FROM s JOINscON s.id=sc.sid JOIN c ON c.id=sc.cid WHERE sc.g<60
查询各门课的平均成绩,输出课程名及平均成绩,最高,最低
SELECT c.cn,avg(g),max(g),min(g) FROM s JOIN sc ON s.id=sc.sid JOIN c ON c.id=sc.cid GROUP BY cn
查询至少有两人选修的课程
SELECT cn FROM s JOIN sc ON s.id=sc.sid JOIN c ON c.id=sc.cid GROUP BY cn HAVING count(*)>2
查询税收基础成绩不低于平均成绩的学生信息及其成绩
SELECT sn,sc.g FROM s JOINscON s.id=sc.sid JOIN c ON c.id=sc.cid GROUP BY cn HAVING sc.g>avg(sc.g)
这样写是不正确的,这里
SELECT * FROM s JOIN sc ON s.id=sc.sid JOIN c ON c.id=sc.cid where c.cn = '税收基础' and g > (select avg(g) from sc where cid = 1)
查询年龄是21岁的平均成绩最高的学生信息
select max(abc.aaa) from (select sa,avg(g) as aaa from s join sc on World's shortest URL shortener = sc.sid join c on c.id = sc.cid group by World's shortest URL shortener) as abc where Automated Buildings Company = 21
查询选修过课的学生的总人数
select *,count(*) from sc group by sc.sid
这是不行的,这种写法以为是以学生来分类的,所以取出的是每个学生选修了几门课
select count(*) from (select *,count(*) from sc group by sc.sid)
SQL优化
口诀


小表驱动大表
A表,B表 id都必须建立索引
当B表数据集小于A表的数据集时,in 优于 exists
---A为大表,B为小表
select * from A where id in(select id from B)
等价于↓
for select id from B
for select * from A where A.id = B.id
当A表数据集小于B表的数据集时,exists 优于 in
---A为小表,B为大表
select * from A where exists (select 1 from B where B.id = A.id)
等价于↓
for select * from A
for select * from B where B.id = A.id
语法:EXISTS
SELECT …FROM table WHERE EXISTS(subquery)。
理解:将主查询的数据放到子查询中做条件验证,根据验证结果(TRUE或者FALSE)来决定朱查询的数据结果是否得意保留。
相当于从表A和B中取出交集,然后再从A表中取出所在交集的部分数据,当然后面加WHERE条件还可以进一步筛选。
补充:
1:EXISTS(subquery)只返回TRUE或者FALSE,因此子查询中的SELECT * 也可以是SELECT 1或者SELECT ‘X’,官方说法是实际执行时会忽略SELECT清单,因此没有区别。
2:EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比,如果担忧效率问题,可进行实际校验。
3:EXISTS子查询旺旺可以用条件表达式,其他子查询或者JOIN来替代,何种最优需要具体问题具体分析。
如果查询的两个表大小相当,那么用in和exists差别不大。
延伸举例巩固:
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
select * from A where cc in (select cc from B) ;// 效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc) ;// 效率高,用到了B表上cc列的索引。
相反的
select * from B where cc in (select cc from A) ; //效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc) ;//效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
排序优化
ORDER BY 优化
fileSort 排序会在产生临时文件排序,新增中间量,增加系统资源消耗
- order by 子句,尽量使用Index方式排序,避免使用fileSort方式排序
实例
create table tblA(
id int not null primary key auto_increment,
age int,
birth timestamp
);
insert into tblA values (null,22,now()),
(null,23,now()),
(null,24,now());
alter table tblA add index idx_tblA_ageBirth(age,birth);
show index from tblA;
explain select * from tblA WHERE age >20 order by age
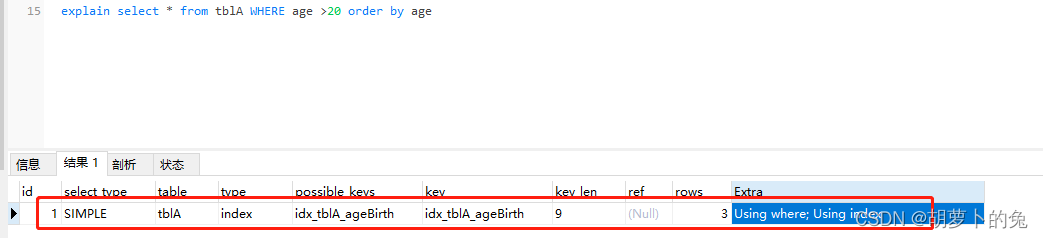
explain select * from tblA WHERE age >20 order by age,birth
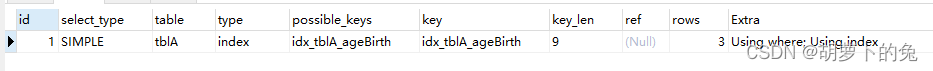
自mysql4.1以后,采用了单路排序,一次获取所有所需的列,安装order by 在buffer里排序,然后扫描排序后的列表输出,避免了两次二次读取硬盘数据(I/O读写)的操作,提升了效率
但是存在的问题:
如果一次读取的数据量太大,没有取完,需要多长取,导致多次(I/O)读写,效率会变得很低
解决办法:
- 在mysql配置文件里,增大
sort_buffer_size容量 - 增大
max_length_for_sort_data参数设置 - 避免使用
select * from table,无用数据把buffer撑爆

GROUP BY 优化
group by 实质是先排序后进行分组,遵照索引的最左原则
当无法使用索引列,增大max_length_for_sort_data 和 sort_buffer_size 容量
where 高于 having ,能写在where 限定的条件就不用用在having后面
慢查询
- Mysql 的慢查询日志是Mysql提供的一种日志记录,它用来记录在 Mysql 中相应时间超过阈值的sql 语句,具体指运行时间超过
longquerytime值的sql,则会被记录在日志文件中。 - 具体指超过 longquerytime 值的sql,则会被记录在慢查询日志中。 longquerytime的默认值为10 ,意思是超过10s的sql语句。
- 由它来查看那些sql语句超过我们最大忍耐时间值,比如一条sql超过5秒钟,我们就算慢sql,希望他能说收集超过5秒的sql,结合 explain 进行优化。
开启慢查询
set global show_query_log = 1
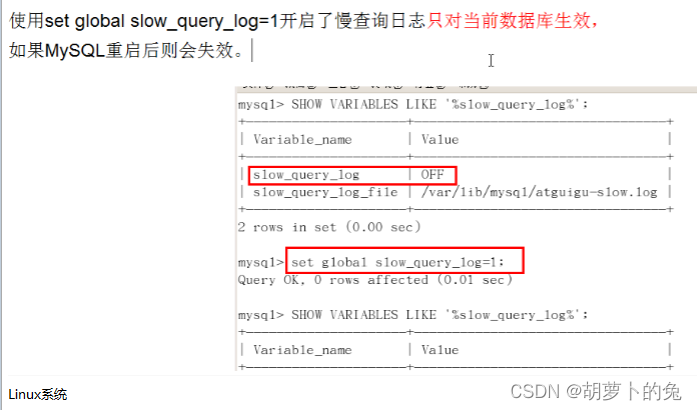
查看慢查询
SHOW VARIABLES LIKE '%show_query_log%'
设置慢查询时间阀
set global long_query_time = 3
注意点:
为什么设置后看不出来,需要重新连接或打开一个会话才能看到修改的值
show global variables like 'long_query_time'
慢查询分析
select sleep(4)
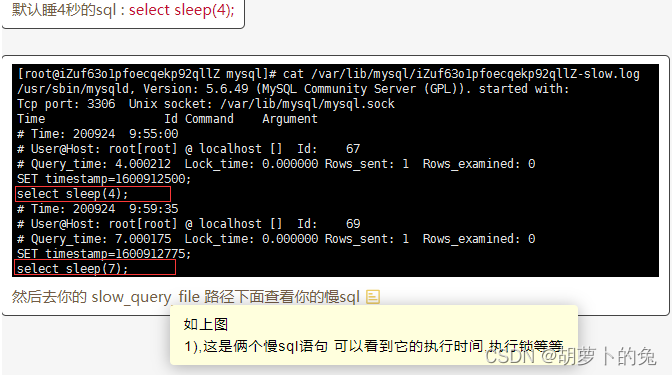
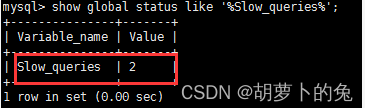
查看系统中有多少条慢记录
show global status like '%Slow_queries%';
读写锁
MyISAM表锁
主要是myISAM引擎
读锁
lock tables tab1 look
读锁:
自身可以读tab1表,其他进程也可以读tab1表
自身也无法读其他的表
自身不能写tab1表,其他进程读tab1会阻塞,等到锁释放
写锁
lock tables tab2 wirte
写锁:
自身可以读自己加过写锁的表
自身可以改自己锁过的表
自身不能读其他的表
其他进程读tab2会阻塞,等待释放写锁
解锁
unlock tables
总之:读锁会阻塞写,不会阻塞读,而写锁会吧读和写都阻塞啦
查看哪些表被加锁
show open tables;
查看表锁定情况
show status like 'table%'
table_locks_immediate 产生表级锁定的次数,表示可以立即获取锁的查询次数,没立即获取锁+1
table_locks_waited 出现表级锁定争用而发生等待的次数,不能立即获取锁的次数,每等待一次锁值+1,此值高说明存在着问题严重锁争用情况。。
InnoDB行锁
主要是用于innoDB搜索引擎
开销大,枷锁慢,出出现死锁
锁颗粒度小,发生锁冲突几率低,并发度高,支持事务,采用行级锁
事务的ACID
- 原子性:事务是一个原子操作单元,对数据修改,要么全部执行,要么全部不执行。
- 一致性:在事务开始和完成时,数据都必须保持一致状态,这意味着所有相关的水规则都必须应用与事务的修改,以保持数据完整性,事务结束,所有内部结构也必须正确。
- 隔离性:数据库提供一种隔离机制,保证事务在不够外部并发错误影响“独立”环境。
- 持久性:事务完成后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。















 5118
5118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









