







An Attentive Survey of Attention Models 注意力模型综述
这篇博客是在阅读了 An Attentive Survey of Attention Models这篇论文之后所做的总结体会,若有任何不准确的地方,烦请大家指正。
1、注意力模型的由来以及技术核心
当人们过马路时注意力会集中于看红绿灯上面,此时眼睛能看到除了红绿灯之外的很多东西,但是大脑将大部分注意力分配于红绿灯;当人们观看某张图片时,习惯于将注意力集中于图片上的某一部分,此时我们的眼睛可以看到很多东西,只不过大脑分配给其他部分的注意力较少;类似人脑的此种机制,神经网络里面出现了注意力模型(Attention Model),或者称作注意力机制(Attention Mechanism)

如图(a)中是传统的 Encoder-decoder结构示意图,Encoder是一个RNN(循环神经网络),输入序列是 {x1,x2,…,xT},其中T是书输入序列长度,接着将其编码成一个固定长度的向量{h1,h2,…,hT}. Decoder也是一个RNN,将Encoder的输出即{h1,h2,…,hT}作为Decoder的输入,经过解码可得输出序列 {y1,y2,…,yT’} ,其中T’是输出序列的长度。
传统的Encoder-decoder结构面临的挑战:
- 传统的Encoder-decoder模型是将输入序列压缩为一个固定长度的向量,如果输入序列较长,会导致信息损失;
- 它无法对输入和输出序列之间的对齐进行建模,这是结构化输出任务(如翻译或汇总)的一个重要方面。
在人们的认知中,在sequence-to-sequence任务中,输入序列中的某一部分对所产生的输出序列的影响应该比其他部分要大,但是传统的Encoder-decoder结构中的decoder缺少这样的机制:在产生输出序列时没有去更多的关注与之相关的输入序列的部分。而Attention Model就是可以实现这样一种机制的模型。
Attention Model主要思想
其核心思想是在输入序列上引入注意力权重α,以优先考虑一组位置,在这些位置上,相关的信息形成将用来生成下一个输出标记。

如图(b)结构中的注意力部分负责学习注意权重αij,αij是捕获 hi (encoder的隐藏层状态,称之为(candidate state)和sj (decoder的隐藏层状态,称之为(query state)之间的相关性。接下来这些注意力权重被用来构建上下文向量C,接着向量C作为decoder的输入。在每一个解码位置j,上下文向量cj是编码器所有隐藏状态及其相应的注意权重的加权和,即
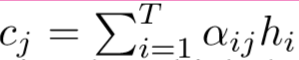
这个额外的上下文向量是解码器可以访问整个输入序列的机制,也可以关注输入序列中的相关位置。
注意力权重αij的学习:注意力权重是通过在体系结构中加入一个额外的前馈神经网络来学习的。该前馈网络用来学习注意权αij作为两种状态的函数,hi(candidate state)和sj−1(query state),这两种状态被神经网络作为输入。此前馈网络与的编码器-解码器组件结合,一起进行训练。
2、注意力模型分类
分为4大类,这些类别并不相互排斥。且一个任务可使用多种注意力模型(例如参考文献[1]使用 a一种multi-level, self and soft attention 结合的注意力模型):

2.1 Number of sequences
- distinctive:一个单独的输入和相应的输出序列。当候选状态和查询状态分别属于两个不同的输入和输出序列时使用。这种类型的注意力模型主要应用于 translation [2], summarization [3], image captioning [4] 以及 speech recognition[5]。
- co-attention model :同一时间有多个输入序列,一起学习它们的注意力权重以捕获这些输入序列之间的交互作用,[6]中使用该注意力模型用于visual question answering。此论文中作者认为,除了模拟图像中的视觉注意之外,问题的注意力也很重要,因为问题文本中的所有单词对问题的答案并不同等重要。
- self attention(inner attention):对于像文本分类和推荐系统这样的任务,输入是一个序列,但是输出不是一个序列。在此种注意力模型中,查询状态和候选状态属于同一序列。在[7]中提出了此种注意模型。
2.2 Number of abstraction levels
- single-level:只计算最初输入序列的注意力权重。
- multi-level :注意力可以以顺序的方式应用于输入序列的多个抽象级别。较低抽象级别的输出(上下文向量C)成为较高抽象级别的查询状态。且可再细分为两种:自上而下(从较高抽象级别到较低抽象级别)的学习权重[8]和自下而上的学习权重[7]。[7]是该种类中典型的例子,论文在两个不同的抽象层使用注意力权重:单词层和句子层,用于文档分类。这种模型被称为Hierarchical Attention Model(HAM)
2.3 Number of positions
- soft attention:该注意力模型使用所有书序列的隐藏层的加权平均去构建上下文向量C。采用软权值法使神经网络能够通过反向传播进行有效的学习,但也导致了计算成本的增加。此注意力模型由[2]提出。
- hard attention model :其中上下文向量是从输入序列中随机采样的隐藏状态计算出来的。这是通过一个由注意力权重参数化的多项式分布来实现的。此注意力模型的优点在于降低了计算成本,但是在输入的每个位置进行艰难的决策会使得到的框架不可微且难以优化。为了克服这一局限性,文献中提出了变分学习方法和强化学习中的策略梯度方法。该模型由[4]提出。
- global:由[9]提出,该注意力模型和软注意力模型类似。
- local :由[9]提出,介于软硬注意力之间。其关键思想是首先检测输入序列中的关注点或位置,然后在该位置周围选择一个窗口,以创建本地软关注模型。局部注意力的优点是在软注意力和硬注意力、计算效率和窗口内可微性之间提供了一个参数平衡。
2.4 Number of representations
- multi-representational AM(Attention model):该注意力模型可以确定输入的多个表示形式对下游应用程序的相关性。最终表示是这些多重表示及其注意力权重的加权组合。该模型的好处在于通过检查权重,可以直接评估哪些嵌入更适合于哪些特定的下游任务。[10]中,学习相同输入句子的不同单词嵌入的注意权重以改善句子表示。
- multi-dimensional attention:在多维注意力中,引入权重以确定输入嵌入向量每个维度的相关性。计算向量的每个特征的得分,可以选择能够在任何给定的上下文中最好地描述令牌的特定含义的特征。此注意力模型更适用于自然语言应用(嵌入词存在一词多义问题)。该方法的示例:[11]中达到了更有效的句子嵌入表示,[12]中使用该模型用于语言理解问题。
3、含有注意力模型的网络结构
与注意力结合使用的三种重要的神经结构: (1) the encoder-decoder framework, (2) memory networks which extend attention beyond a single input sequence, (3) architectures which circumvent the sequential processing component of recurrent models with the use of attention.
3.1 Encoder-Decoder
注意力的最早使用是作为基于RNN的编码器-解码器框架的一部分来编码长的输入语句[2]。AM可以采用任何输入表示,并将其减少到一个固定长度的上下文向量,用于解码步骤。因此,它允许将输入表示与输出分离。我们可以利用这一优势来引入混合编码器-解码器。最受欢迎的是卷积神经网络(Convolutional Neural Network(CNN) )作为编码器,循环神经网络(RNN)或者长短时记忆(Long Short Term Memory (LSTM) )作为解码器,这种类型的结构用于很多多模态任务:image and video captioning, visual question answering 和 speech recognition.。
然而,并非所有输入和输出都是顺序数据的问题都可以用上述方法解决(例如,排序或旅行商问题)。[13]提出了Pointer networks ,其有两个不同点:(1)输出是离散的,并指向输入序列中的位置(因此称为指针网络)(2)输出的目标类别设定步骤的数量取决于输入的长度(因此也是变量)。这不能用传统的编码器-解码器框架实现,在这个框架中,输出字典是先验的。作者利用注意权来模拟在每个输出位置选择第i个输入符号作为所选符号的概率。此方法可以用来解决排序和旅行商等离散优化问题。
3.2 Memory Networks
像问答和聊天机器人这样的应用程序需要能够从事实数据库中的信息中学习。网络的输入是知识数据库和查询,其中一些事实比其他事实更与查询相关。End-to-End Memory Networks [14]使用一个内存块数组来存储事实数据库,并注意对内存中每个事实的相关性进行建模以回答查询来实现上述问题。使用注意力模型还通过使目标连续并通过反向传播实现端到端训练来提供计算优势。端到端存储器网络可以被看作是AM的一个泛化,在这种泛化中,它们不只是在单个序列上建模注意力,而是在大型序列数据库(事实)上建模。
3.3 Networks without RNNs
循环体系结构依赖于编码步骤输入的顺序处理,这会导致计算效率低下,因为处理无法并行化。为了解决该问题[15]提出了Transformer architecture :编码器和译码器由一系列具有两个子层的相同的层组成:位置前馈网络层和多头自注意层。转换器结构实现了重要的的并行处理、更短的培训时间和更高的翻译精度,无需任何循环的组件。但是位置编码只对位置信息进行弱合并,可能无法解决对位置变化更敏感的工作问题。[12]利用时间卷积编码位置信息和变压器的自注意机制来克服此问题。另外,[16]提出了前馈注意模型(Feed Forward Attention models ),其中他们使用AM来折叠数据的时间维度,并使用FFN( Feed Forward Network)而不是RNN来解决顺序数据问题。在这种情况下,AM被用来从可变长度的输入序列中产生固定长度的上下文向量,可以将其作为输入输入到FFN前反馈网络。
4、应用
注意力模型三个主要的应用领域: (i) Natural Language Generation(NLG), (ii) Classification, (iii) Recommender systems.
参考文献
[1]: Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alexander J. Smola, and Eduard H. Hovy. Hierarchical attention networks for document classification. In HLT-NAACL, 2016
[2]: Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder–decoder approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pages 103–111, Doha, Qatar, October 2014. ACL.
[3]: Alexander M. Rush, Sumit Chopra, and Jason Weston. A neural attention model for abstractive sentence summarization. In EMNLP, pages 379–389, Lisbon, Portugal, September 2015. ACL.
[4]: Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, pages 2048–2057, 2015.
[5]:William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals. Listen, attendandspell: Aneuralnetworkforlargevocabularyconversational speech recognition. In ICASSP, pages 4960–4964. IEEE, 2016.
[6]:Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. Hierarchicalquestion-imageco-attentionforvisualquestionanswering. In NIPS, pages 289–297, 2016.
[7]:Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alexander J. Smola, and Eduard H. Hovy. Hierarchical attention networks for document classification. In HLT-NAACL, 2016.
[8]:Shenjian Zhao and Zhihua Zhang. Attention-via-attention neural machine translation. In AAAI, 2018.
[9]:Thang Luong, Hieu Pham, and Christopher D. Manning. Effective approaches to attention-based neural machine translation. In EMNLP, pages 1412–1421, Lisbon, Portugal, September 2015. ACL.
[10]:Douwe Kiela, Changhan Wang, and Kyunghyun Cho. Dynamic meta-embeddings for improved sentence representations. In EMNLP, pages 1466–1477, 2018.
[11]:Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, BingXiang,BowenZhou,andYoshuaBengio. Astructuredselfattentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017
[12]:Tao Shen, Tianyi Zhou, Guodong Long, Jing Jiang, Shirui Pan, and Chengqi Zhang. Disan: Directional self-attention network for rnn/cnn-free language understanding. In AAAI, 2018.
[13]:Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In NIPS,pages2692–2700, Cambridge, MA, USA,2015. MIT Press.
[14]:Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. In NIPS, pages 2440–2448, 2015.
[15]:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998–6008, 2017.
[16]:Colin Raffel and Daniel PW Ellis. Feed-forward networks with attention can solve some long-term memory problems. arXiv preprint arXiv:1512.08756, 2015.















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









