







server1是master,server2、3是slave
1 优化I/O线程:使用增强型半同步复制(无损复制)
异步主从主库和从库的数据之间难免会存在一定的延迟,这样存在一个隐患:当在主库上写入一个事务并提交成功,而从库尚未得到主库的BINLOG日志时,主库由于磁盘损坏、内存故障、断电等原因意外宕机,导致主库上该事务BINLOG丢失,此时从库就会损失这个事务,从而造成主从不一致。使得主从复制失去意义。下面使用增强型半同步复制优化I/O线程:半同步复制要求使用GTID模式。并设置半同步超时自动切换为异步进行数据同步
半同步复制
从MySQL5.5开始,引入了半同步复制,此时的技术暂且称之为传统的半同步复制,因该技术发展到MySQL5.7后,已经演变为增强半同步复制(也成为无损复制)。在异步复制时,主库执行Commit提交操作并写入BINLOG日志后即可成功返回客户端,无需等待BINLOG日志传送给从库,如图所示。
而半同步复制时,为了保证主库上的每一个BINLOG事务都能够被可靠地复制到从库上,主库在每次事务成功提交时,并不及时反馈给前端应用用户,而是等待至少一个从库(详见参数rpl_semi_sync_master_wait_for_slave_count)也接收到BINLOG事务并成功写入中继日志后,主库才返回Commit操作成功给客户端(不管是传统的半同步复制,还是增强的半同步复制,目的都是一样的,只不过两种方式有一个席位地方不同,将在下面说明)
半同步复制保证了事务成功提交后,至少有两份日志记录,一份在主库的BINLOG日志上,另一份在至少一个从库的中继日志Relay Log上,从而更进一步保证了数据的完整性。
半同步复制分为传统的半同步复制和增强半同步复制(也称无损复制)
在传统的半同步复制中,主库写数据到BINLOG,且执行Commit操作后,会一直等待从库的ACK,即从库写入Relay Log后,并将数据落盘,返回给主库消息,通知主库可以返回前端应用操作成功,这样会出现一个问题,就是实际上主库已经将该事务Commit到了事务引擎层,应用已经可以看到数据发生了变化,只是在等待返回而已,如果此时主库宕机,有可能从库还没能写入Relay Log,就会发生主从库不一致。增强半同步复制就是为了解决这个问题,做了微调,即主库写数据到BINLOG后,就开始等待从库的应答ACK,直到至少一个从库写入Relay Log后,并将数据落盘,然后返回给主库消息,通知主库可以执行Commit操作,然后主库开始提交到事务引擎层,应用此时可以看到数据发生了变化。增强半同步复制的大致流程如下图所示。
mysql5.7以后半同步都使用增强半同步,5.6之前使用传统半同步
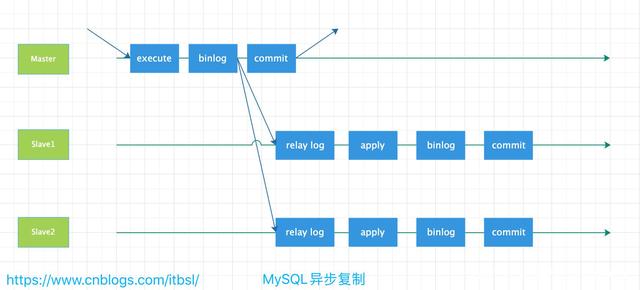

增强型半同步实现数据无损同步
安装半同步模块插件:实验环境继承上一篇
server1上

srever2、3上相同操作:中间两步是重启I/O

server1上查看状态:
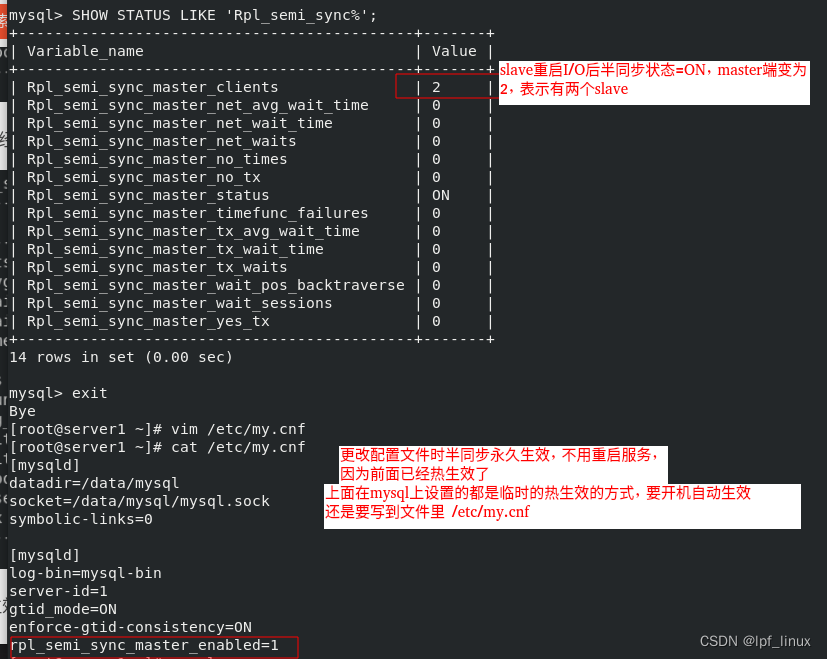
实验1:server1(master)添加数据查看半同步

server2、3上查看,同步成功。
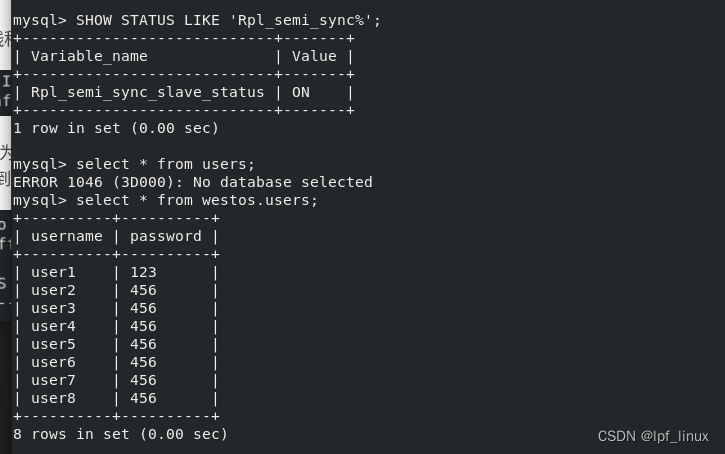
实验2:半同步超时自动切换为异步进行数据同步
server2、3上停止I/O:

server1上添加数据

server2、3上使用异步同步了数据。
当server2、3激活I/O,又自动转换为半同步模式,server1上查看状态
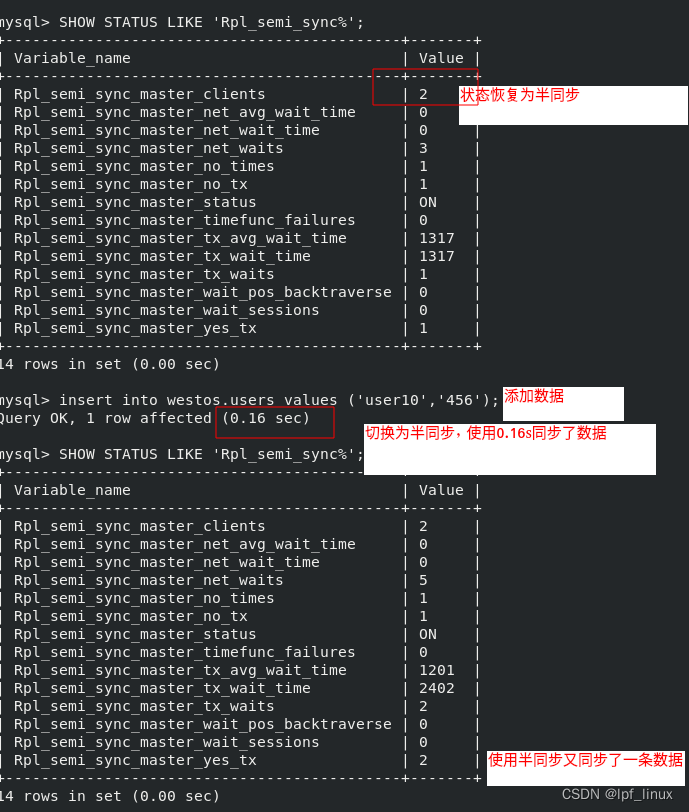
server2、3上成功使用半同步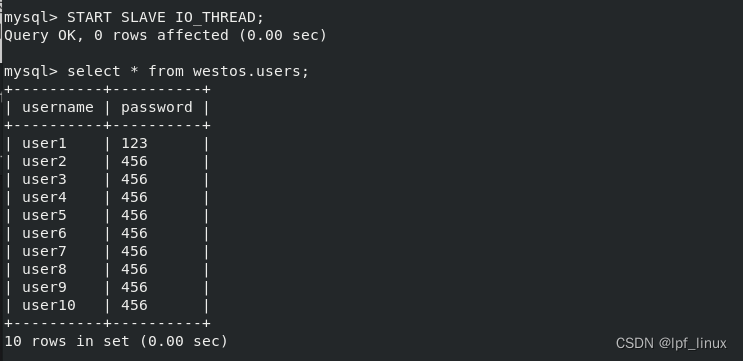
半同步模式:COMMIT: master端收到server端ack请求之前就提交,不确定slave端是否写入数据,
增强半同步:SYNC :server端存好数据发送ack,master端收到ack请求之后才会提交,
2 SQL操作和优化
I/O保证了数据一致性,I/O正常保证了slave端能和master进行相同的操作,但SQL线程来做回放,可以进行回放延时等。
2.1 延迟复制(SQL延迟)
延迟多少对业务产生影响,如果业务要求实时性高的话,延迟时间要小,或者不设置延迟,选择合适的延迟时间很重要。
SQL延迟指的是I/O将master传来的数据正常存储在中继日志,但是SQL使用中继日志回放操作时设置延时,如果master端误操作,slave端有时间恢复数据。
slave端:server2 设置延迟复制,server3不做设置对比
server2上:
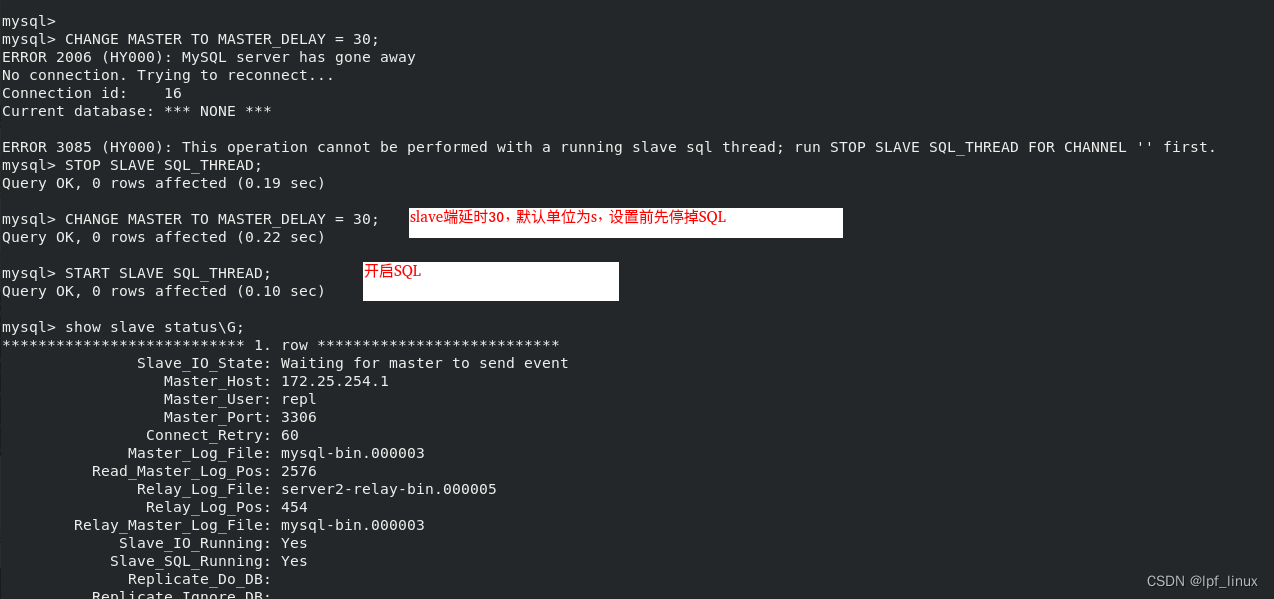
server1(master)上添加数据:
mysql> insert into westos.users values ('user12','456');server3上查到user12,server2上查看没有user12,查看server2状态: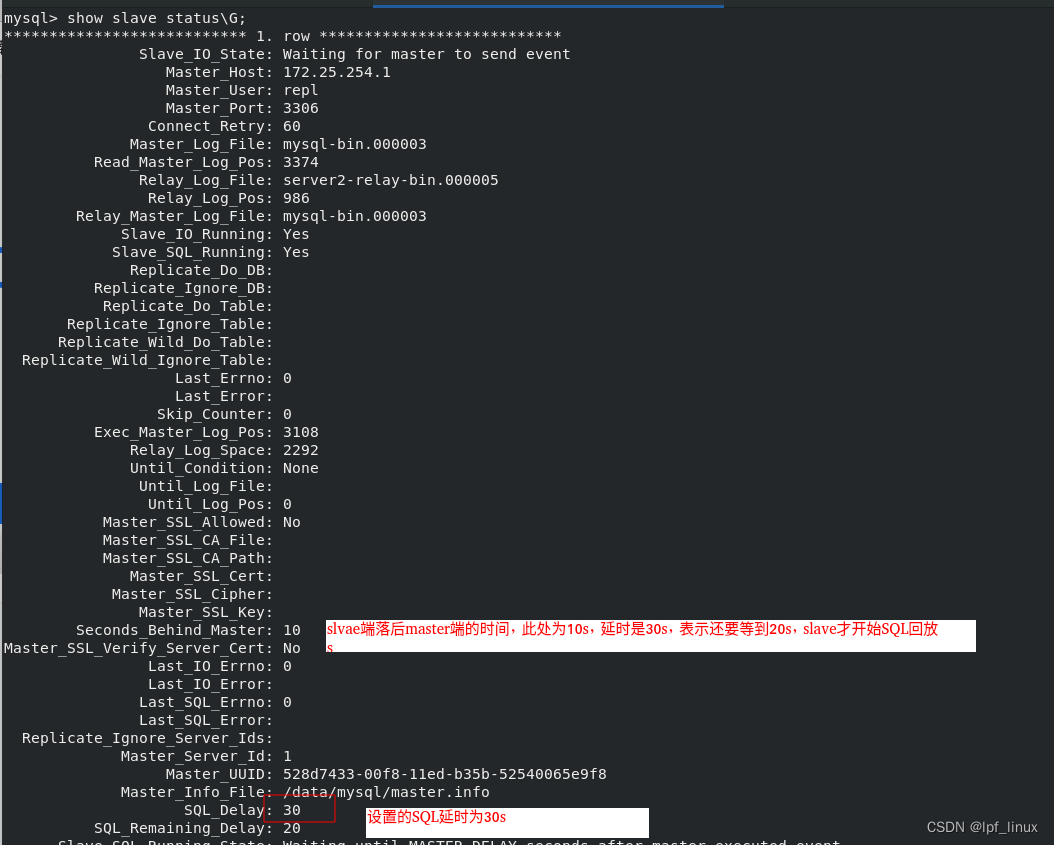
当30s后,server2上查到user12,

2.2 并行复制(MTS 快80%)
master端默认是很多用户多线程同时写入的,而slave端默认情况下SQL线程是单线程回放数据,这样在slave端回放来复制数据时与master端延迟会很大,可以设置slave端的并行复制来解决此问题。把SQL线程单线程变为多线程
server2上: 设置完成后重启

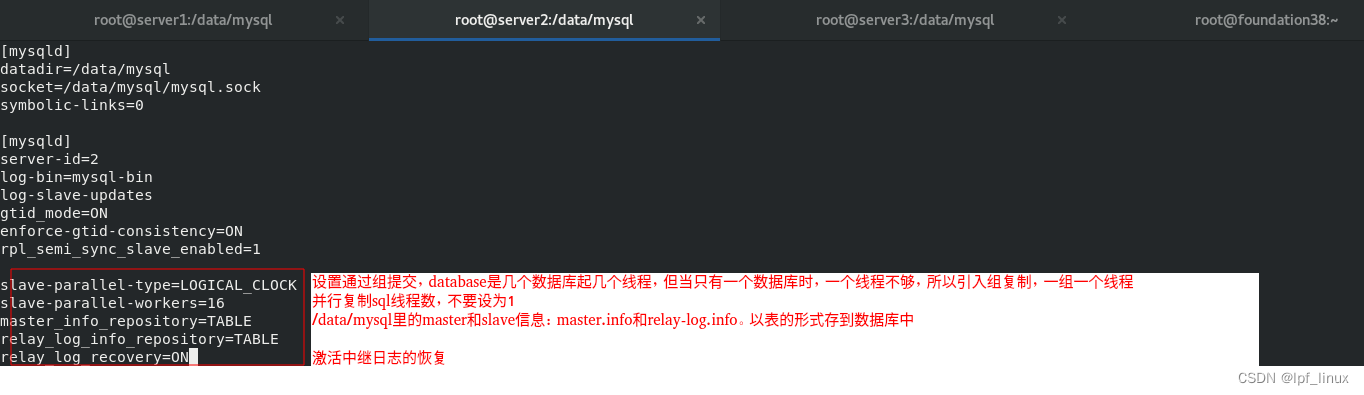
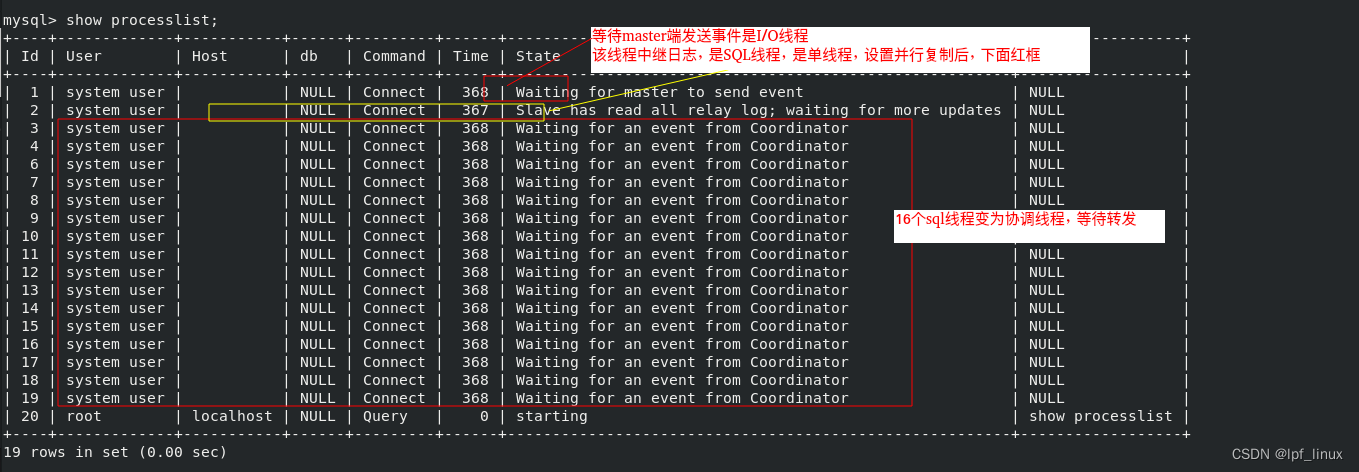
/data/mysql下master和slave信息,之前以文件形式存储。

现在以表的形式存到数据库中
3 慢查询
查找比较慢的SQL线程并显示出来。数据库可以把慢查询日志记录到文件里:
server1上: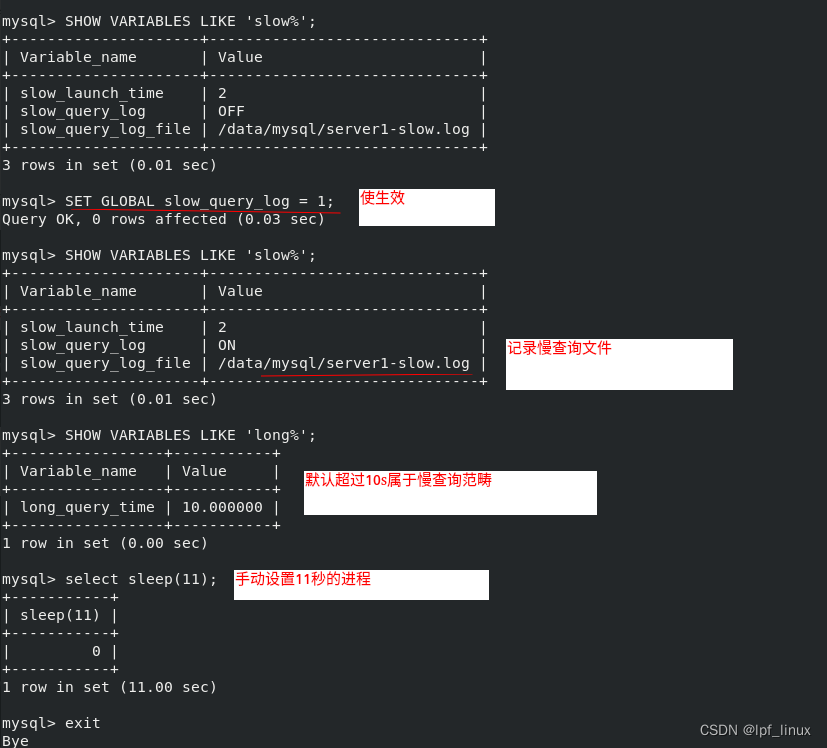
找到慢查询日志,查到哪个线程超时:

4 组复制
mysql分布式集群存储,分布式数据库:高可用、
组复制原理
- 组复制是一种可用于实现容错系统的技术。组复制在数据库层面上做到了,只要集群中大多数主机可用,则服务可用,3台服务器的集群,允许其中1台宕机。 复制组是一个通过消息传递相互交互的 server 集群。
- 通信层提供了原子消息(atomic message)和完全有序信息交互等保障机制。 这些是非常强大的功能,我们可以据此架构设计更高级的数据库复制解决方案。
MySQL 组复制以这些功能和架构为基础,实现了基于复制协议的多主更新。
复制组由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事务。但所有读写(RW)事务只有在冲突检测成功后才会提交。只读(RO)事务不需要在冲突检测,可以立即提交。换句话说,对于任何 RW 事务,提交操作并不是由始发 server 单向决定的,而是由组来决定是否提交。准确地说,在始发 server 上,当事务准备好提交时,该 server 会广播写入值(已改变的行)和对应的写入集(已更新的行的唯一标识符)。然后会为该事务建立一个全局的顺序。最终,这意味着所有 server 成员以相同的顺序接收同一组事务。因此,所有 server 成员以相同的顺序应用相同的更改,以确保组内一致。- 在不同 server 上并发执行的事务可能存在冲突。 根据组复制的冲突检测机制,对两个不同的并发事务的写集合进行检测。如在不同的 server 成员执行两个更新同一行的并发事务,则会出现冲突。排在最前面的事务可以在所有 server 成员上提交,第二个事务在源 server 上回滚,并在组中的其他 server 上删除。 这就是分布式的先提交当选规则。
组复制特点
● 高一致性
基于原生复制及 paxos 协议的组复制技术,并以插件的方式提供,提供一致数据安全保证;
● 高容错性
只要不是大多数节点坏掉就可以继续工作,有自动检测机制,当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理,并且内置了自动化脑裂防护机制;
● 高扩展性
节点的新增和移除都是自动的,新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致,如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息;
● 高灵活性
有单主模式和多主模式,单主模式下,会自动选主,所有更新操作都在主上进行;多主模式下,所有 server 都可以同时处理更新操作。
应用场景:
1弹性的数据库复制环境:组复制可以灵活的增加和减少集群中的数据库实例;
2高可用的数据库环境:组复制允许数据库实例宕机,只要集群中大多数服务器可用,则整个数据库服务可用;
3替代传统主从复制结构的数据库环境
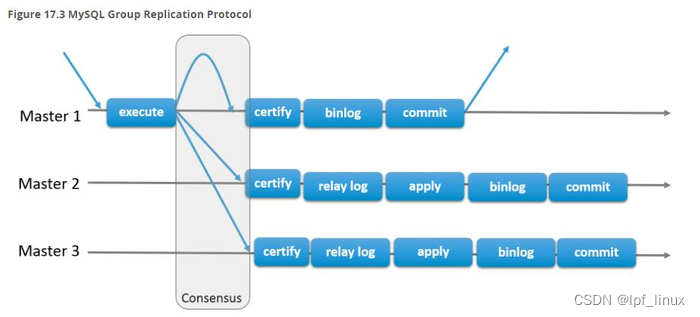
单主模型和多主模型
MySQL组复制是MySQL 5.7.17开始引入的新功能,为主从复制实现高可用功能。它支持单主模型和多主模型两种工作方式(默认是单主模型)。
单主模型:从复制组中众多个MySQL节点中自动选举一个master节点,只有master节点可以写,其他节点自动设置为read only。当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master。
多主模型:复制组中的任何一个节点都可以写,因此没有master和slave的概念,只要突然故障的节点数量不太多,这个多主模型就能继续可用。
多主模式配置:
在进行组复制之前先将所有节点的mysqld服务停掉,再将所有节点的mysql数据删掉。
server1上更改配置文件/etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
symbolic-links=0
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
plugin_load_add='group_replication.so'
transaction_write_set_extraction=XXHASH64
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address= "172.25.254.1:33061"
group_replication_group_seeds= "172.25.254.1:33061,172.25.254.2:33061,172.25.254.3:33061"
group_replication_bootstrap_group=off
group_replication_ip_whitelist="172.25.254.0/24,127.0.0.1/8"
group_replication_single_primary_mode=OFF
group_replication_enforce_update_everywhere_checks=ON
因为删除了mysql数据信息/data/mysql,所以要初始化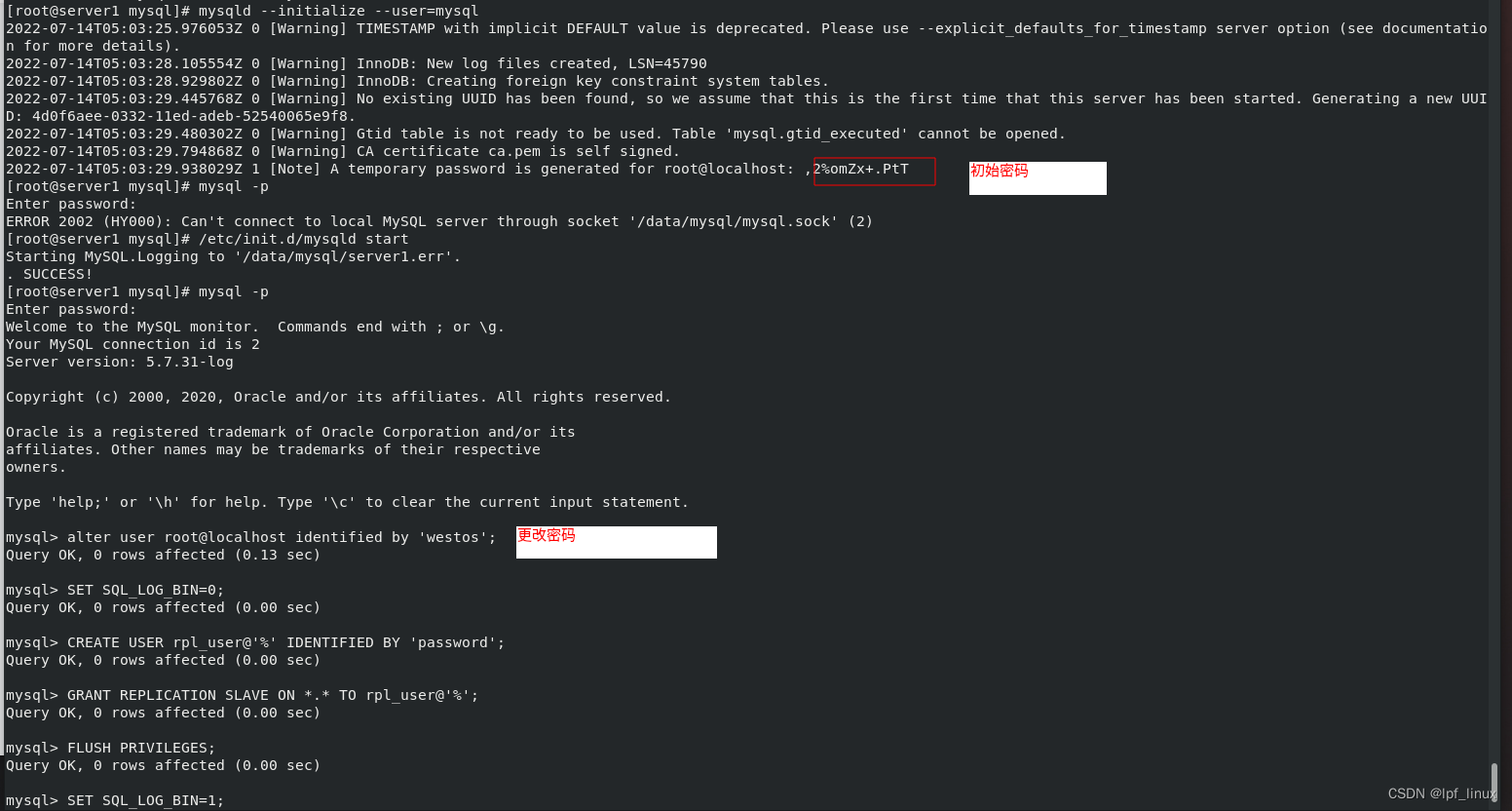

上面最后显示,第一个节点server1已经online,上面mysql内输入的信息如下:
mysql> SET SQL_LOG_BIN=0; #禁止记录二进制日志(禁止下面的操作记录下来)
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
mysql> FLUSH PRIVILEGES;
mysql> SET SQL_LOG_BIN=1; #操作完成之后再记录
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
mysql> SET GLOBAL group_replication_bootstrap_group=ON; #此条语句只需要在第一个启动的节点上运行即可,用于引导组复制
mysql> START GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;# 此条语句只需要在第一个启动的节点上运行即可,server2上停止mysqld、删除mysql数据文件和server1相同,从配置文件开始变化: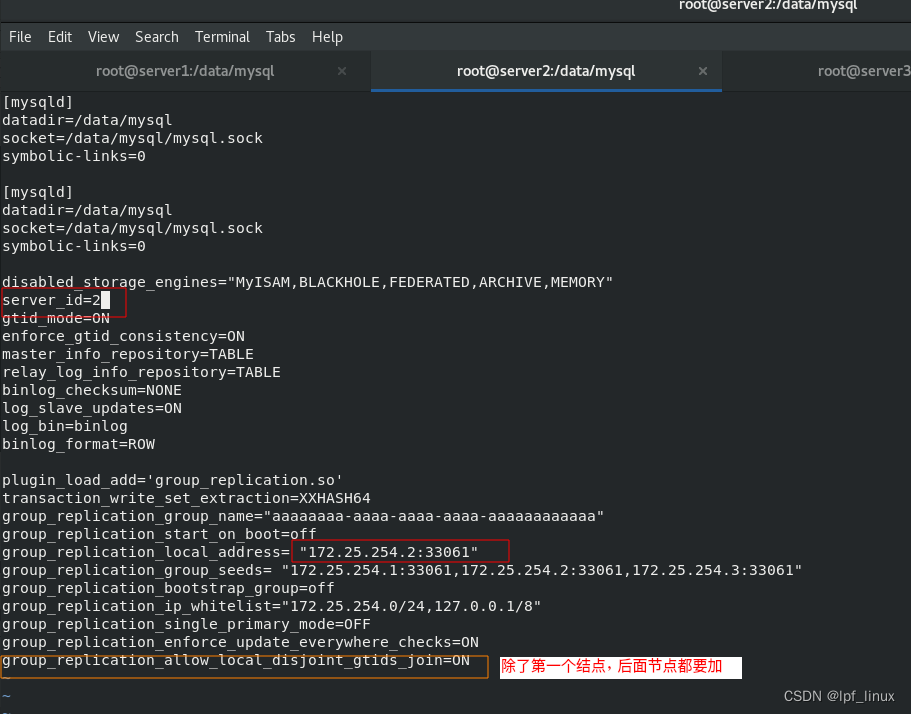
初始化和配置组复制,配置组复制时,和第一个节点配置相比,后面节点都要少作两行命令:

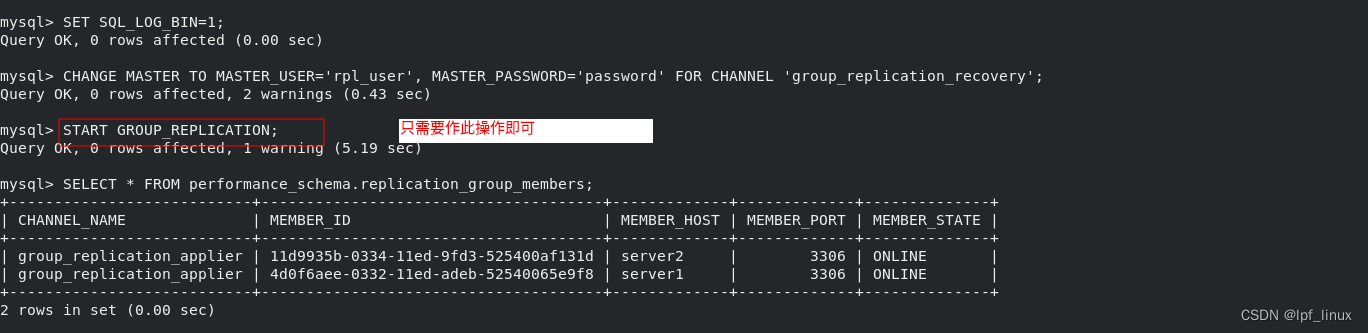
此时开启节点,节点server1、2已经online。
server3上和server2相同操作,只是/etc/my.cnf配置更改
server_id=3
group_replication_local_address= "172.25.254.3:33061"此时开启节点,节点server1、2已经online:
多主模式组复制节点配置完成
多主模式组复制不区分master和slave都可以读写。接下来在三个节点任意节点添加数据,另外两节点都能实现数据同步
选择在server1添加数据: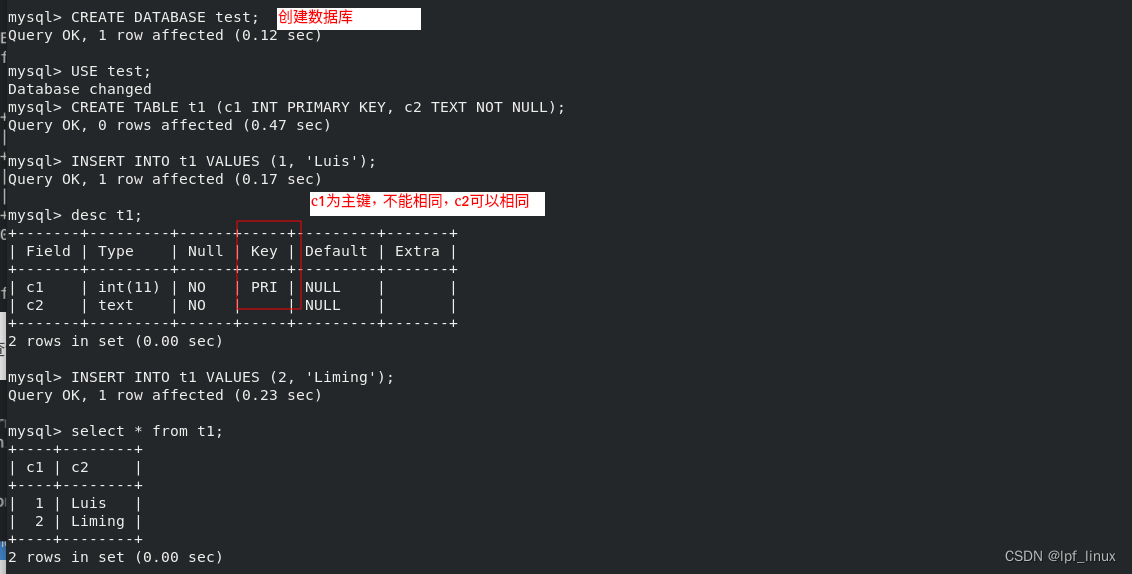
server2、3上数据同步过来:
server3上插入数据,server1、2上也同步过来:















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









