







1 mysql 路由器实现读写分离
简介: MySQL 路由器是 InnoDB 集群的一部分,是轻量级中间件,可在应用程序和后端 MySQL 服务器之间提供透明路由。它可用于各种用例,例如通过有效地将数据库流量路由到适当的后端 MySQL 服务器来提供高可用性和可伸缩性。mysql路由器不支持分库分表。
本实验利用mysql路由器可以通过绑定不同端口来实现不一样的读写分离的策略。下图mysql路由器在组复制集群和应用程序之间 。组复制多主模式,每个节点都可以读写,不需要作读写分离。在生产环境中会有要求数据库读写分离。
因为此实验前是多主模式组复制架构,不区分master、slave,集群三个节点都读写。实际中可以选择主从模式,master节点作为读写端,slave节点作为只读端。

添加虚拟机server4为 mysql路由器 来作读写分离。 mysql路由器直接定义策略就可以了。
server4上安装路由器mysql-router,并在 mysql路由器直接定义读写分离策略。

在其他任意一台mysql主机上授权用户,因为server1、2、3是多主模式组复制,其他节点也会自动执行相同操作。
1 在客户端 38上访问7001:
在server1上检查端口3306(mysqld的端口),发现是server4和server1相连的,server4就相当于一个代理,外部客户端通过读写分离层server4和server1服务器相连,链接到server1服务器mysqld的3306端口。
此是在其他服务器上查看3306端口没有和server4连接信息,意味着客户端通过路由器连接的不是此服务器。符合所写策略。
由于访问7001设置的是server1、2、3轮询, 客户端重新访问7001,会通过server4路由器依次路由到server2、server3服务器上
2 在客户端 38上访问7002端口:

由于设置的是一直访问第一个服务器。除非此服务器挂掉,然后按照顺序访问下一个服务器,以此类推。访问顺序为server3、2、1。所以server3上查到了
外部客户端通过读写分离层server4和server3服务器相连,链接到server3服务器mysqld的3306端口。
server3上停止mysqld服务后,再次访问,链接到server2服务器。
2 MHA高可用
MHA 自动解决数据同步,
一、MHA介绍
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是日本的一位MySQL专家采用Perl语言编写的一个脚本管理工具,该工具仅适用于MySQLReplication(二层)环境,目的在于维持Master主库的高可用性。是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA是自动的master故障转移和Slave提升的软件包.它是基于标准的MySQL复制(异步/半同步).该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
1. MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Manager会定时探测集群中的node节点,当发现master出现故障的时候,它可以自动将具有最新数据的slave提升为新的master,然后将所有其它的slave导向新的master上.整个故障转移过程对应用程序是透明的。
2. MHA Node运行在每台MySQL服务器上,它通过监控具备解析和清理logs功能的脚本来加快故障转移的。在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与增强型半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
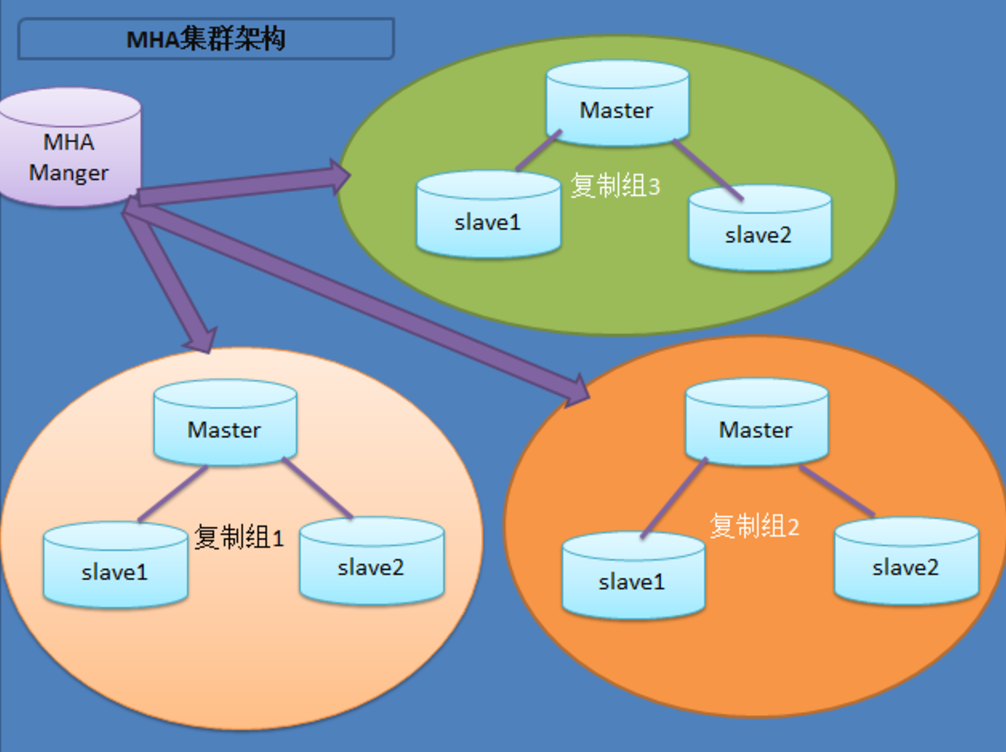
二、MHA工作架构说明
展示了如何通过MHA Manager管理多组主从复制。可以将MHA工作原理总结为如下:
相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。工作流程主要如下:
1. 从宕机崩溃的master保存二进制日志事件(binlog events);
2. 识别含有最新更新的slave;
3. 应用差异的中继日志(relay log)到其他的slave;
4. 应用从master保存的二进制日志事件(binlog events);
5. 提升一个slave为新的master;
6. 使其他的slave连接新的master进行复制;当master出现故障时,通过对比slave之间I/O线程读取master binlog的位置,选取最接近的slave做为latest slave。其它slave通过与latest slave对比生成差异中继日志。在latest slave上应用从master保存的binlog,同时将latest slave提升为master。最后在其它slave上应用相应的差异中继日志并开始从新的master开始复制。
在MHA实现Master故障切换过程中,MHA Node会试图访问故障的master(通过SSH),如果可以访问(不是硬件故障,比如InnoDB数据文件损坏等),会保存二进制文件,以最大程度保证数据不丢失。MHA和半同步复制一起使用会大大降低数据丢失的危险。
########## MHA如何保持数据的一致性呢?######### 主要通过MHA node的以下几个工具实现,但是这些工具由mha manager触发:
save_binary_logs 如果master的二进制日志可以存取的话,保存复制master的二进制日志,最大程度保证数据不丢失
apply_diff_relay_logs 相对于最新的slave,生成差异的中继日志并将所有差异事件应用到其他所有的slave注意:
对比的是relay log,relay log越新就越接近于master,才能保证数据是最新的。
purge_relay_logs删除中继日志而不阻塞sql线程################# MHA的优势 ##################
1. 故障切换快
在主从复制集群中,只要从库在复制上没有延迟,MHA通常可以在数秒内实现故障切换。9-10秒内检查到master故障,可以选择在7-10秒关闭master以避免出现裂脑,几秒钟内,将差异中继日志(relay log)应用到新的master上,因此总的宕机时间通常为10-30秒。恢复新的master后,MHA并行的恢复其余的slave。即使在有数万台slave,也不会影响master的恢复时间。DeNA在超过150个MySQL(主要5.0/5.1版本)主从环境下使用了MHA。当mater故障后,MHA在4秒内就完成了故障切换。在传统的主动/被动集群解决方案中,4秒内完成故障切换是不可能的。
2. master故障不会导致数据不一致
当目前的master出现故障时,MHA自动识别slave之间中继日志(relay log)的不同,并应用到所有的slave中。这样所有的salve能够保持同步,只要所有的slave处于存活状态。和Semi-Synchronous Replication(半同步复制)一起使用,(几乎)可以保证没有数据丢失。3. 无需修改当前的MySQL设置
MHA的设计的重要原则之一就是尽可能地简单易用。MHA工作在传统的MySQL版本5.0和之后版本的主从复制环境中。和其它高可用解决方法比,MHA并不需要改变MySQL的部署环境。MHA适用于异步和半同步的主从复制。启动/停止/升级/降级/安装/卸载MHA不需要改变(包扩启动/停止)MySQL复制。当需要升级MHA到新的版本,不需要停止MySQL,仅仅替换到新版本的MHA,然后重启MHA Manager就好了。
MHA运行在MySQL 5.0开始的原生版本上。一些其它的MySQL高可用解决方案需要特定的版本(比如MySQL集群、带全局事务ID的MySQL等等),但并不仅仅为了master的高可用才迁移应用的。在大多数情况下,已经部署了比较旧MySQL应用,并且不想仅仅为了实现Master的高可用,花太多的时间迁移到不同的存储引擎或更新的前沿发行版。MHA工作的包括5.0/5.1/5.5的原生版本的MySQL上,所以并不需要迁移。
4. 无需增加大量的服务器
MHA由MHA Manager和MHA Node组成。MHA Node运行在需要故障切换/恢复的MySQL服务器上,因此并不需要额外增加服务器。MHA Manager运行在特定的服务器上,因此需要增加一台(实现高可用需要2台),但是MHA Manager可以监控大量(甚至上百台)单独的master,因此,并不需要增加大量的服务器。即使在一台slave上运行MHA Manager也是可以的。综上,实现MHA并没用额外增加大量的服务。5. 无性能下降
MHA适用与异步或半同步的MySQL复制。监控master时,MHA仅仅是每隔几秒(默认是3秒)发送一个ping包,并不发送重查询。可以得到像原生MySQL复制一样快的性能。6. 适用于任何存储引擎
MHA可以运行在只要MySQL复制运行的存储引擎上,并不仅限制于InnoDB,即使在不易迁移的传统的MyISAM引擎环境,一样可以使用MHA。
实验环境配置:只使用一组集群:一主两从,server1为master,server2、3是slave,全部设置为GTID模式。server4为管理端,实现当master(server1)挂了之后,master自动切换到其他节点。
之前实验使用多主模式-组复制架构,本实验首先转换成一主两从架构,并且是GTID模式,
把所有节点上的mysqld服务关闭,并把/data/mysql 中的数据删除干净,修改配置/data/my.cnf文件、重新初始化:


server2上配置文件/etc/my.cnf和server1只有不同,srever2上:server_id=2

server3上:上配置文件/etc/my.cnf和server2只有不同,srever3上:server_id=3,后面操作和server2相同。
由于我们在master上已经创建了repl用户,此操作被写进二进制日志文件,在其他slave端同步进行了用户创建。
一主两从GTID配置完毕。
软件安装和管理端server4配置
在server4管理端安装mha的软件,从本机38上lftp到mha.zip,解压。安装管理端mha的时候有很多依赖性,依赖包全部放在了mha.zip中,直接全部安装即可。

管理节点server4免密连接所有服务器节点,并且服务器节点之间也要免密:

执行下面三步
ssh-copy-id server2
ssh-copy-id server3
ssh-copy-id server4 免密成功。
免密成功。
在服务器结点上安装mha,把rpm包scp到服务器端
服务器三个结点上安装mha:
yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm 管理端server4更改配置文件
编辑配置文件:
补充参数:check_repl_delay=0
[server]
hostname=172.25.254.2
candidate_master=1 #指定failover时此slave会接管master,即使数据不是最新的。 check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
检查环境配置是否成功需要两步:
1、检查免密masterha_check_ssh --conf=/etc/mha/app1.conf
![]()
2、检测数据库主从配置是否成功
错误原因:管理端server4无法远程访问集群服务器节点数据库。
解决:server1上 ,给root用户远程访问权限,由于上面配置了一主两从GTID模式,所以只需要在master上授予权限,其他节点会自动同步:
在此检测成功,上面两项检测都成功后证明mha环境配置成功。
2.1手动切换:
server1为master,server2、3为slave
实验前先删掉锁定文件rm -fr app1.failover.complete,否则禁止频繁转换master:
或者添加参数--ignore_last_failover忽略锁定文件,每次切换都要执行,因为每次切换master后/etc/mha都会再次生成锁定文件

2.1.1当master节点还活着时:
server4上执行:
masterha_master_switch --conf=/etc/mha/app1.conf --master_state=alive --new_master_host=172.25.254.2 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000全部选择yes,
server1上已经转换为slave;

现在server2是master,server1、3是slave
2.1.2当master挂掉后手动切换

server4上
--ignore_last_failover忽略锁定文件,因为系统为了防止频繁切换master做的,忽略的话强制切换master

此时查看server1状态切换成master。由于server2停掉了,当server2重新启动起来时,配置没变(还是master配置),所以要在server2上手动把master切到server1上:
完成后server1为master,server2、3为slave;
2.2自动切换
自动切换前先删掉锁定文件rm -fr app1.failover.complete,否则禁止频繁转换master:
自动切换只需要把程序打到后台即可。

测试:
将master server1的mysqld停掉:
在管理端server4上:没有自动检测,/etc/mha查看日志manager.log发现有错误
日志:
Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Monitoring server 172.25.254.38 is NOT reachable!
解决:更改server4管理端/etc/mha/app1.conf

恢复到本实验前状态server1为master,server2、3为slave;server4上删掉后台进程msterha_manager。
再次实验:
将master server1停掉:
server4上自动检测,自动切换server2为master,并退出后台监听程序,且生成锁定文件。

重新启动server1的mysqld,并在server1上将master设置为server2。
![]()

实验完成后,server2为master,server1、3为slave
2.3 使用脚本文件进行切换:
让用户始终访问VIP,VIP会跟着master节点作漂移。访问vip始终访问的是master的数据库。
实验前先删掉锁定文件rm -fr app1.failover.complete,否则禁止频繁转换master:
在源码包里,有自动切换ip和一个手动切换ip的脚本,通过修改这两个脚本来实现vip随着master节点漂移的目的:
从本机lftp下载已更改完成的两个脚本
修改两个脚本VIP端口,此脚本文件实现了VIP随着master漂移


实验:
server2 master上添加vip
在外部客户端38上访问VIP:访问的是master server2的数据库

手动切换master为server1:
此时的VIP已经漂移到server1上了: 
在客户端访问VIP,报错后又重新连接:因为master切换为server1,vip也漂移到server1上,客户端访问server1数据库。
做完此实验,master是server1,server2、3是slave。
自动切换master:
实验前先删掉锁定文件rm -fr app1.failover.complete,否则禁止频繁转换master:
打开自动切换到后台,停掉server1 master,发现已经自动切换到server2。

停掉server1 master:
![]()
master 自动切回到server2上,VIP也漂移到server2上:

客户端经过报错会重新连接上:此时连接的是server2的数据库














 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









