






预备:链表的理论基础
- 数据结构中的链表和数组的存储方式不一样,链表中的节点可以分散在不同的位置,在java中引用存放对象在堆内存中的地址,所以链表节点这个对象包含了两部分内容,一部分是自己的值val,另一部分是next,存放下一个节点在堆内存中的地址。(java中没有指针的概念,只有引用)
- 链表中主要应用的是单链表中的增加和删除节点,不适用查找节点,因为要一个一个遍历。
- 无论是增加还是删除节点,需要找到前驱节点,然后修改前驱结点的next值,所以创建一个虚拟节点,将处理第一个节点和其他节点的操作统一起来。 以及便于返回新的头结点。
1、删除链表元素

注意点
1、头结点不能随便动 要重新定义新的临时指针来动
2、定义一个虚拟节点2指向head+赋给一个temp节点来遍历
3、值相等 temp.next = temp.next.next; 不相等 temp = temp.next;
4、之所以不return head了,因为head可能已经被删了,只有dummy确定在,所以返回它的next即可; 也不能用temp,temp遍历到最后了
代码
public ListNode removeElements(ListNode head, int val) {
//注意异常处理
if (head == null){
return head;
}
ListNode dummy = new ListNode(-1, head);
dummy.next = head;
//定义一个临时指针来遍历链表,不能直接用头指针遍历,不然最后头指针不指向头就没发返回链表值了
ListNode temp = dummy;
while(temp.next != null){
if(temp.next.val == val){
temp.next = temp.next.next;
}else{
temp = temp.next;
}
}
//之所以不return head了,因为head可能已经被删了,只有dummy确定在,所以返回它的next即可;也不能用temp,temp到最后了
return dummy.next;
}2、设计链表

注意点
链表定义自带ListNode next和val
记得用临时指针指向头结点,这样才好动
插入的时候注意顺序以及<index这个边界点带入算
自定义得时候定义一个虚拟头结点和size,操作完别忘了移动size
代码
class MyLinkedList {
int size;
ListNode head;
public MyLinkedList() {
size = 0;
head = new ListNode(-1);
}
public int get(int index) {
if (index < 0 || index >= size) {
return -1;
}
ListNode temp = head;
for (int i = 0; i <= index; i++){
temp = temp.next;
}
return temp.val;
}
public void addAtHead(int val) {
addAtIndex(0, val);
}
public void addAtTail(int val) {
addAtIndex(size, val);
}
public void addAtIndex(int index, int val) {
// if (index < 0){
// index = 0;
// }
if (index > size){
return;
}
ListNode newNode = new ListNode(val);
ListNode temp = head;
for (int i = 0; i < index; i++) {
temp = temp.next;
}
newNode.next = temp.next;
temp.next =newNode;
size++;
}
public void deleteAtIndex(int index) {
while (index < 0 || index > size - 1){
return;
}
ListNode temp = head;
if (index == 0){
head = head.next;
}
for (int i = 0; i < index; i++){
temp = temp.next;
}
temp.next = temp.next.next;
size--;
}
}3、返转链表

注意点
- 3个指针:头结点指针、返转的指针、暂存向后指针(不然没发往后动)
- 两步赋值,两步移动
- 这个移动画图想想,先保存原来下一个指针,然后将反转值赋给回去;
- 返转完移动剩余结点时,先动前面的,不然后面的动了前面的就找不到了!!
动态过程
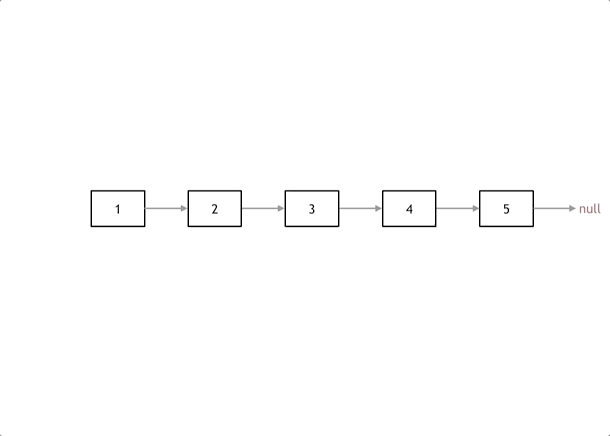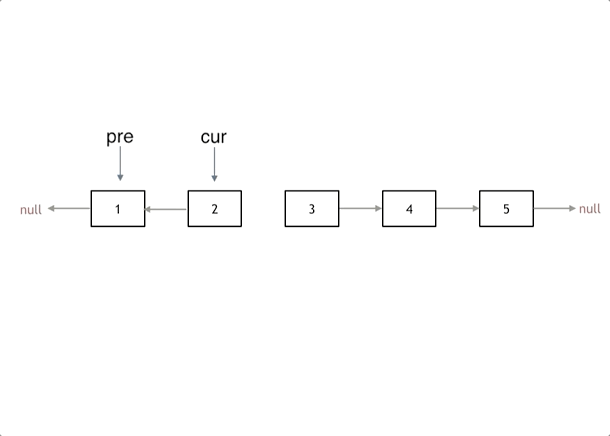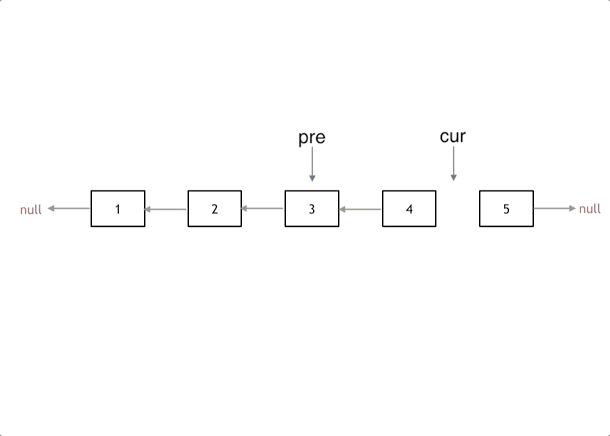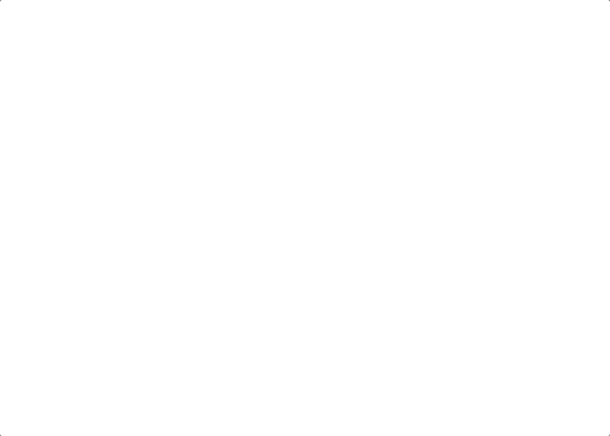
代码
public ListNode reverseList(ListNode head) {
ListNode pre = null, temp = null;//要给他们赋值初始化
ListNode cur = head;
//两步操作,记录下一个节点;返转一个节点,
while (cur != null) {
//这个移动画图想想,先保存原来下一个指针,然后将反转值赋给回去;
temp = cur.next;
cur.next = pre;
//先动前面的,不然后面的动了前面的就找不到了!!
pre = cur;
cur = temp;
}
//这个就是新链表的头结点了
return pre;
}递归的思想---另一种写法
class Solution {
public ListNode reverseList(ListNode head) {
return reverse(null, head);
}
ListNode reverse(ListNode pre, ListNode cur) {
if(cur == null){
return pre;
}
ListNode temp = cur.next;
cur.next = pre;
return reverse(cur, temp);//这里要加返回值
}
}递归思想博客
关于递归来做这道题 可以看看这边博客的思维三道题套路解决递归问题 | lyl's blog
要点总结
- 是否要添加虚拟头结点 :
虚拟头结点的主要目的是为了避免对头结点的特殊处理;这个处理就指的是修改操作。所以可以这样:涉及到对链表修改(如插入,删除,移动)的,都加个dummy,只是遍历取点就可以不用加- 链表一定要分清节点和指针的概念: new ListNode()是真实存在的一个节点, head = new ListNode() 相当于 head指针指向了一个真实的节点, node = head, 相当于node和head同时指向了这个真实的节点
为什么有时候需要判定cur->next !=null,有时候又不需要,只用判断cur!=null呢? 其实这个要看场景,一般就是看你如果不判断的话会不会导致空指针异常,因为如果你的指针遍历到null还调用它的属性或方法肯定就会报错的,但是有时候的情况不会遍历到cur->next,所以要看具体情况。
操作指针时,一定要先判断指针是否为空,若为空,则编译报错(操作空指针)
对于链表问题可以多用笔画画图,这样会加深你对指针和节点实体的理解,代码的鲁棒性如何通常可以利用边界case尝试















 1414
1414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









