










前言
有温度 有深度 有广度 就等你来关注哦~

所有文章完整的素材+源码都在👇👇
XX联盟(爬虫案例基本上都是用的谐音或者代号,应该猜到了哈),多少人的青春。网吧,泡
面,通宵,Pentakill!
我不怎么玩游戏,玩的第一个游戏就是XX联盟,玩的时间最长,最上瘾的一款游戏。直到
现在,XXXX联盟也一直是我无聊时候的消遣游戏,尤其是XXXXXXXX之弈。
不知道你们在XX联盟买了多少皮肤。我其实对皮肤可有可无,没有说多喜欢,也没有说买皮肤多
不值。应该很少有人能把全部英雄的全部皮肤都买了吧(真真真土豪除外).
今天就给大家介绍一个非常好用的皮肤盒子,就是说,所有的人物,所有的皮肤都可以使用,
全部免费。像付费的xxx提莫,XX战士系列,XX之月系列,都可以体验。
(哈哈哈,就是给大家开个玩笑——是不是激动了一下下,哎呀~)
今天给大家带来的一个爬虫实战案例其实是一个新手零基础教程的啦,没有这么6的。

正文



哇哇哇,这高清壁纸你爱了嘛?
一、运行环境
1)Python环境
环境: Python 3 、Pycharm、requests 。 其他内置模块(不需要安装 re json csv),安装 好
python环境就可以了。 (win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安
装速度比较慢, 你可以切 换国内镜像源))
2)第三方库的安装
pip install + 模块名 或者 带镜像源 pip install -i pypi.douban.com/simple/ +模块名
二、代码实现
1)本节课整体爬虫流程:
1. 确定目标需求 xx所有人物皮肤图片
找到一张英雄皮肤图片的来源
找这个英雄所有的图片来源是在哪?
2. 对 url地址发送请求 获取数据
3. 解析数据 获取想要内容
获取英雄皮肤图片 url 地址 / 英雄名字/ 皮肤名字
4. 保存数据, 图片保存到本地文件夹
2)代码实战
import requests # 第三方模块 pip install requests
import pprint # 格式化输出的模块 在打印json的数据的时候,可以更加方便 查看数据信息
import os # 内置模块 不需要安装 自带的
import re # 内置模块 不需要安装
# 对 url地址发送请求 获取数据
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
# 需要要加一个请求头? 伪装浏览器发送请求
# 请求头 是一个字典的数据 一个关键字 对应一个值
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
def change_title(title):
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_title = re.sub(mode, '_', title)
return new_title
def save(title, name, img_url):
# 我想要把每个英雄皮肤图片,单独保存在一个文件里面
filename = f'{title}\\'
# 自动创建文件夹
# 如果没有这个文件夹 / 没有这个路径 那么就创建这个文件夹
if not os.path.exists(filename):
os.mkdir(filename)
# 获取图片内容,是要获取它一个二进制数据内容
# 文本数据 response.text json数据 response.json() 二进制数据 response.content
img_content = requests.get(url=img_url, headers=headers).content
with open(filename + name + '.jpg', mode='wb') as f:
f.write(img_content)
print(name)
response = requests.get(url=url, headers=headers)
# pprint.pprint(response.json())
# 解析数据 获取 英雄ID
# json数据提取数据 和 字典类似 根据关键字提取值 通俗的讲 根据冒号左边的内容 提取冒号右边的内容
hero_list = response.json()['hero'] # 返回的数据内容 是列表形式
# 通过遍历/for 循环 提取它每一个英雄ID
lis = []
for index in hero_list:
hero_id = index['heroId']
lis.append(hero_id)
# 字符串 格式化方法
# 对英雄的皮肤数据 url地址 发送请求 获取英雄皮肤图片数据
lis = lis[27:]
for li in lis:
hero_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(li)
response_1 = requests.get(url=hero_url, headers=headers)
# pprint.pprint(response_1.json())
# 解析数据 获取英雄皮肤url地址/英雄名字/皮肤名字
skins = response_1.json()['skins']
for index_1 in skins:
# 皮肤图片地址
img_url = index_1['mainImg']
# 英雄名字
title = index_1['heroTitle']
# 皮肤名字
name = index_1['name']
new_name = change_title(name)
new_title = change_title(title)
if img_url:
save(new_title, new_name, img_url)
else:
chroma_img = index_1['chromaImg']
save(new_title, new_name, chroma_img)三三、效果展示
1)来源数据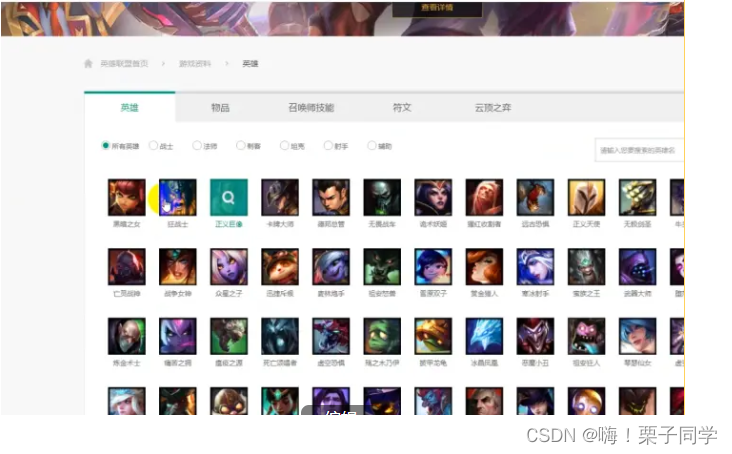
2)效果图
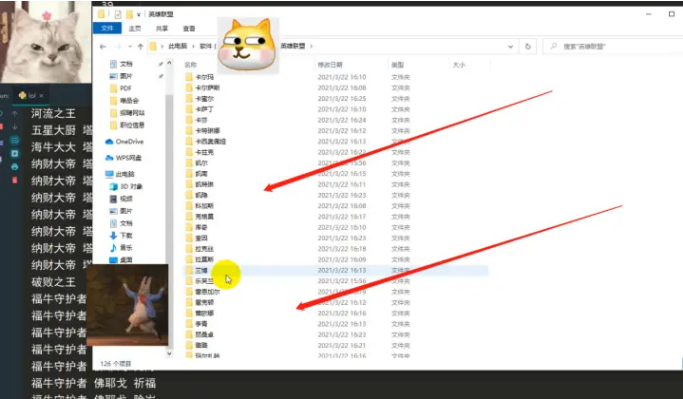

总结
看着这么多的高清皮肤,有没有很心动呀?那好不赶紧找我拿代码试试满!
-
本文的例子没有什么实际价值,不过对于入门的新手有一定的帮助作用。
-
爬虫的思路基本上是一样的,懂一点儿爬虫就可以上手实操(案例超级简单啦)
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目0.2 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目0.3 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.1 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
项目0.4 【Python实战】海量表情包炫酷来袭,快来pick斗图新姿势吧~(超好玩儿)
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









