




【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1:DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation
- 开源代码:GitHub - GigaAI-research/DriveDreamer4D: [CVPR 2025] DriveDreamer4D
- 核心思想:用世界模型(world models)的先验知识来增强 4D 场景表示
- 为什么需要世界模型?
- 现有的闭环仿真主要用Nerf、3DGS等重建技术,生成场景受限于训练数据分布(比如训练数据大多数是直行,那重建出来的大多也是直行的场景),所以在复杂操作(如变道、加速、减速)时表现不佳。然而世界模型能够生成多样化的驾驶视频。
- 使用 4DGS(3DGS+时间维度)表示4D场景
- 把场景中的物体表示为一堆高斯球(有椭球形状、位置、透明度、颜色)
- 用时间场模块预测每个timestep的高斯球变化情况
- 通过2D投影,算每个像素的颜色(透明度*颜色*高斯球权重),得到图像
- 损失函数:RGB 损失、深度损失和 SSIM 损失(结构相似性指数,度量两幅图像间的结构相似性)

- 使用扩散模型实现视频生成的世界模型

- DriveDreamer4D方法
- 由两部分组成:新型轨迹生成模块(NTGM)和 表亲数据训练策略(CDTS)
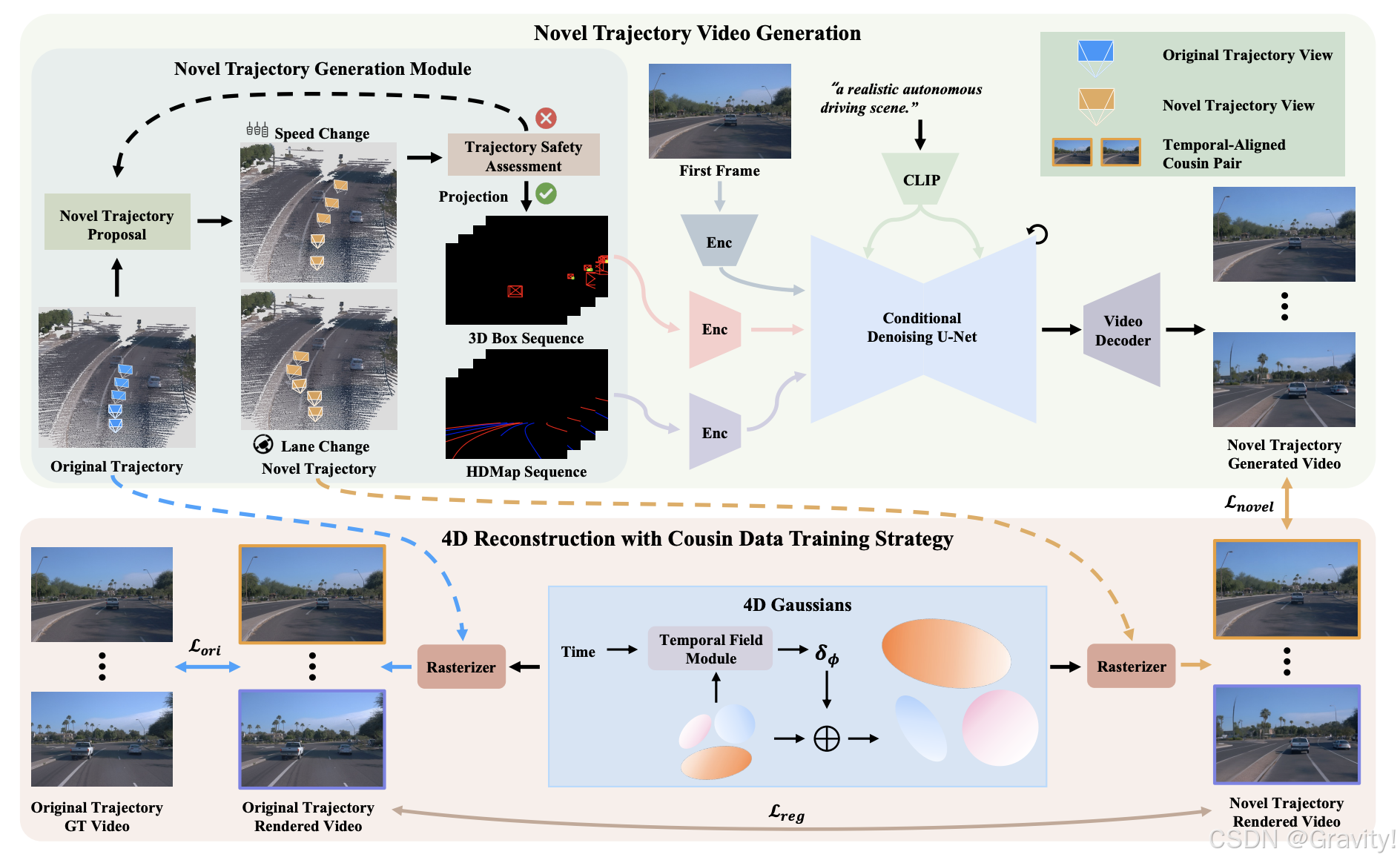
- Novel Trajectory Video Generation 新型轨迹生成模块
- 文本指令生成多样化复杂轨迹(text-to-trajectory)→ 安全性评估(是否在可行驶区域内,避免与其他交通参与者碰撞)→ 将新轨迹的3D box、HDMap投影到相机视角 → (+初始帧和文本指令)给视频扩散模型 → 生成符合新轨迹的视频
- Cousin Data Training Strategy 表亲数据训练策略
- 目的:更好地将生成的数据整合到4DGS中
- 如何理解这里的 Cousin Data:
- 真实视频的每一帧(比如车辆直行的画面)都有一个对应的模拟帧(比如同一时刻车辆变道的模拟画面)。
- CDTS将这两类数据按时间顺序一一配对,确保模型同时看到同一时间点下的真实和模拟场景,来帮助它理解两者之间的联系。
- 损失函数组成
- 原始数据损失
: 监督原始轨迹数据的重建,包含RGB损失、深度损失和SSIM损失
- 新轨迹数据损失
:监督生成的新轨迹数据,仅包含RGB和SSIM损失
- 正则化损失
: 感知特征对齐原始和新轨迹的渲染结果
- 原始数据损失
- 由两部分组成:新型轨迹生成模块(NTGM)和 表亲数据训练策略(CDTS)
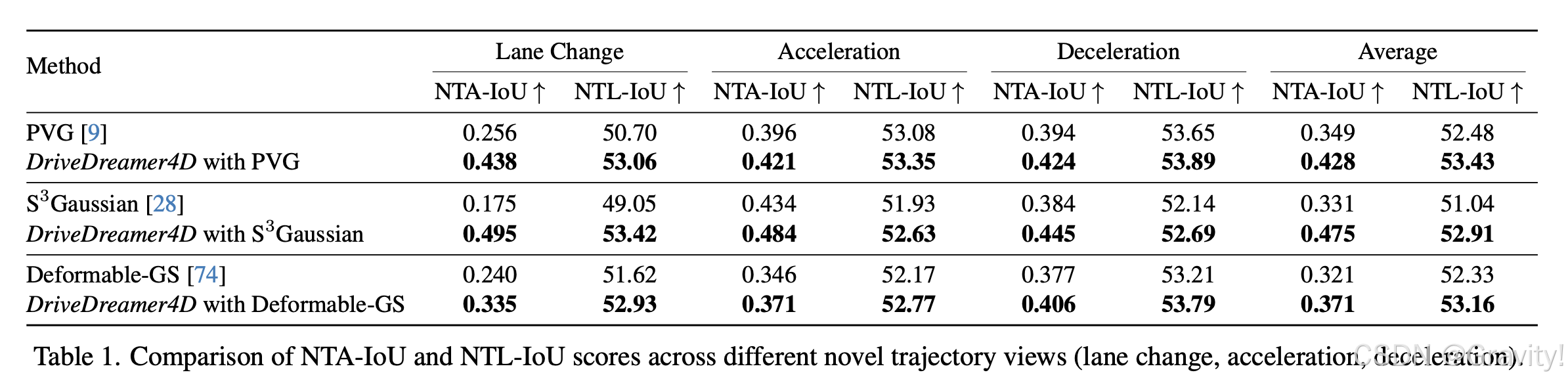
- 实验(不同新轨迹视角下的生成视频质量评估)
NTA-IoU(Novel Trajectory Agent IoU):评估新轨迹视图中前景交通元素(如车辆)的时空连贯性。通过计算渲染图像中检测到的 2D 边界框与通过几何变换投影到新视图的真实 3D 边界框之间的IoU来衡量。
NTL-IoU(Novel Trajectory Lane IoU):评估新轨迹视图中背景交通元素(如车道线)的时空连贯性的指标。它通过计算渲染车道线与真实车道线之间的mIoU来衡量。
论文2:ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
- 开源代码:https://github.com/GigaAI-research/ReconDreamer
- 过去工作的问题:在渲染新轨迹(尤其是大视角偏移,如跨多车道)时会出现伪影(ghosting artifacts)和时空不一致性(spatiotemporal incoherence)
- 核心思想:逐步整合世界模型知识来增强驾驶场景重建
- ReconDreamer方法:
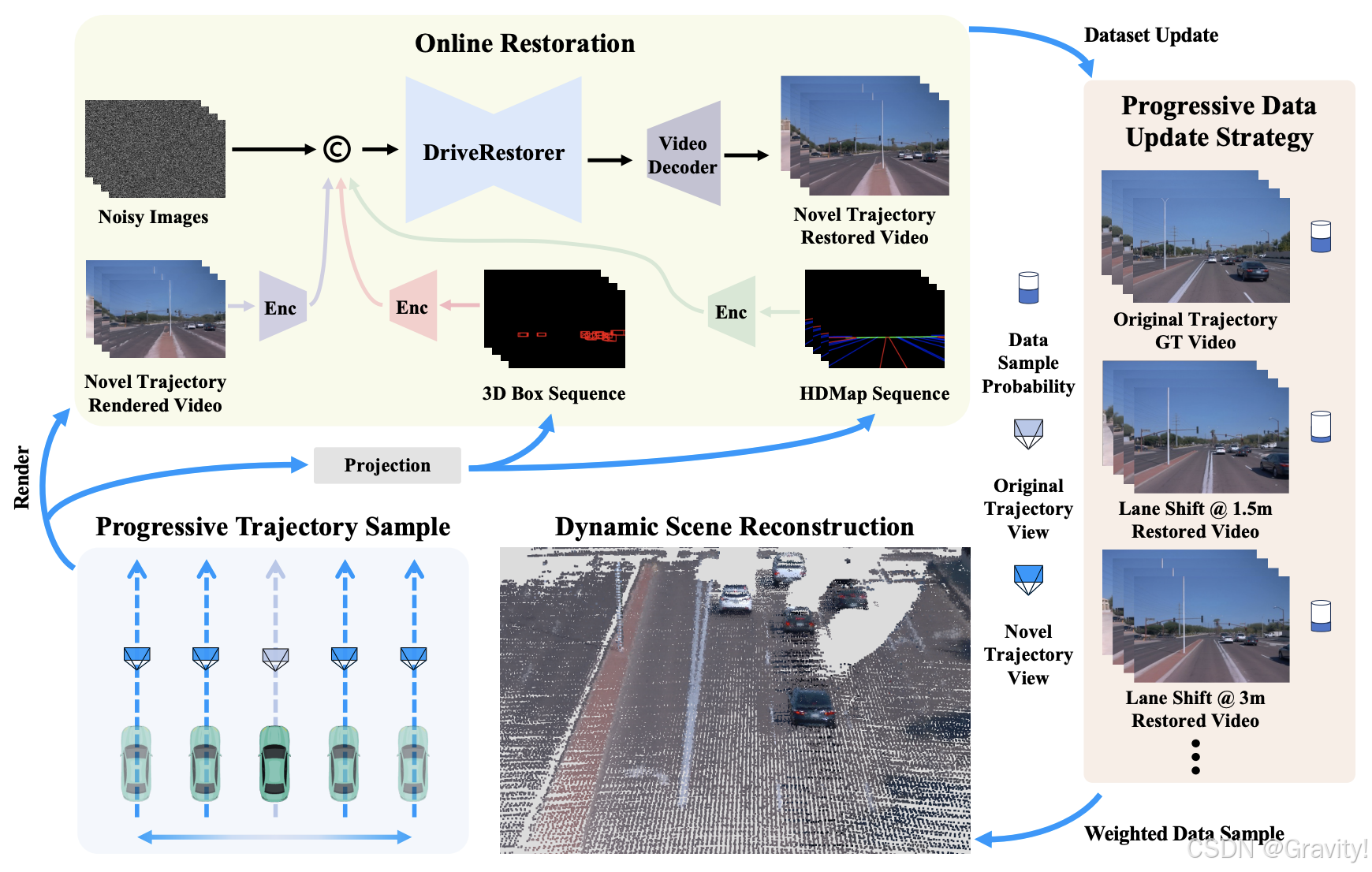
- DriveRestorer:用于修复渲染视频中的伪影。用修复数据集(降质视频帧+对应的真值视频帧)训练,使用掩码策略,让网络学习修复能力。
- 渐进式数据更新策略(Progressive Data Update Strategy)
- 混合数据集:原始轨迹视频数据集 + 修复后的新轨迹视频数据集
- 通过逐步扩展新轨迹来生成大范围驾驶视频,并使用 DriveRestorer 修复这些视频,然后将修复后的视频用于更新训练数据集。
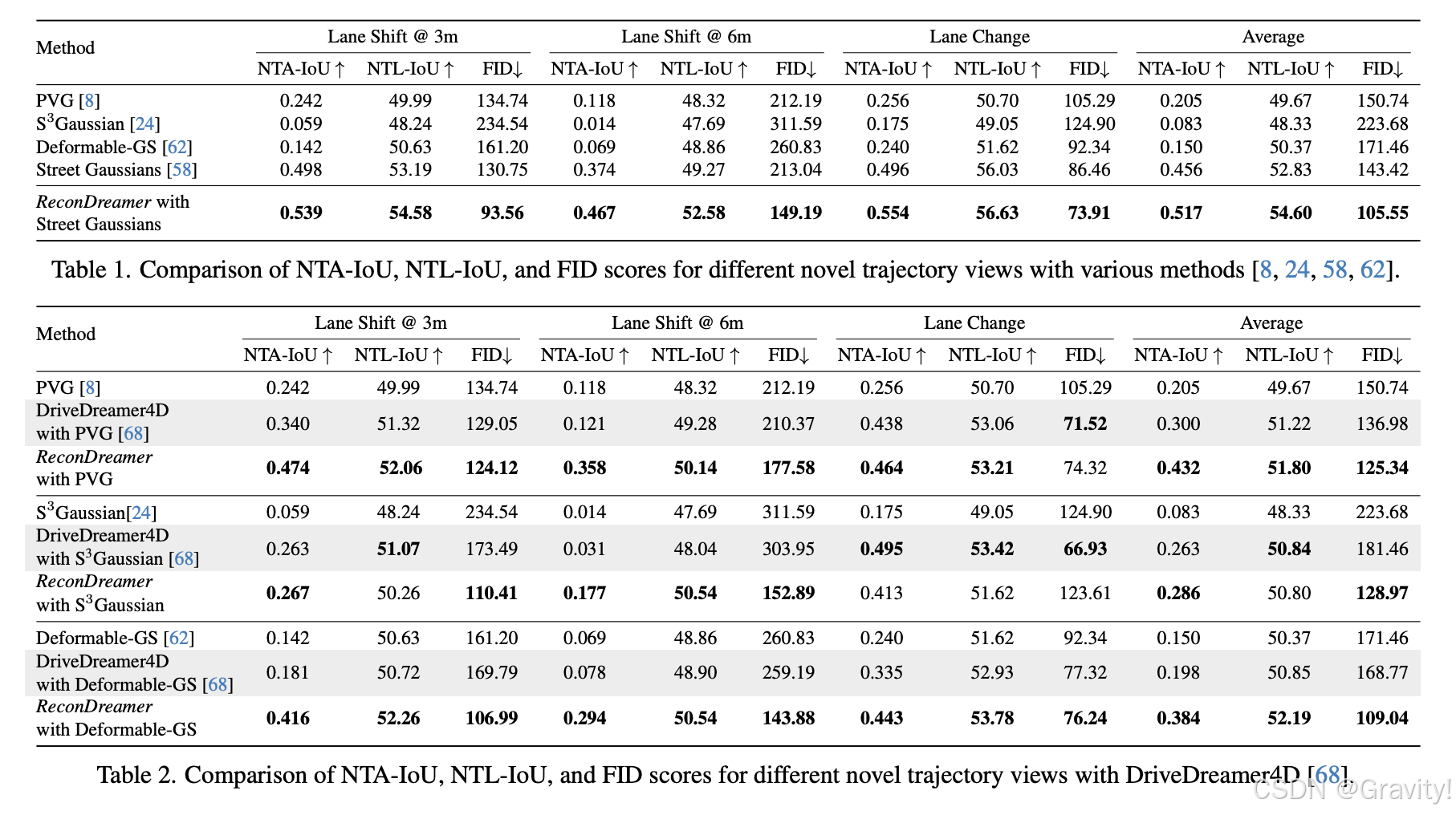
- 实验(超越DriveDreamer4D)

















 1837
1837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









