






eBPF是什么?
eBPF是一个能够在内核运行沙箱程序的技术,提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,使得非内核开发人员也可以对内核进行控制。随着内核的发展,eBPF 逐步从最初的数据包过滤扩展到了网络、内核、安全、跟踪等,而且它的功能特性还在快速发展中,早期的 BPF 被称为经典 BPF,简称cBPF,正是这种功能扩展,使得现在的BPF被称为扩展BPF,简称eBPF。
eBPF的应用场景是什么?
网络优化
eBPF兼具高性能和高可扩展特性,使得其成为网络方案中网络包处理的优选方案:
高性能
JIT编译器提供近乎内核本地代码的执行效率。
高可扩展
在内核的上下文里,可以快速地增加协议解析和路由策略。
故障诊断
eBPF通过kprobe,tracepoints跟踪机制兼具内核和用户的跟踪能力,这种端到端的跟踪能力可以快速进行故障诊断,与此同时eBPF支持以更加高效的方式透出profiling的统计数据,而不需要像传统系统需要将大量的采样数据透出,使得持续地实时profiling成为可能。
安全控制
eBPF可以看到所有系统调用,所有网络数据包和socket网络操作,一体化结合进程上下文跟踪,网络操作级别过滤,系统调用过滤,可以更好地提供安全控制。
性能监控
相比于传统的系统监控组件比如sar,只能提供静态的counters和gauges,eBPF支持可编程地动态收集和边缘计算聚合自定义的指标和事件,极大地提升了性能监控的效率和想象空间。
eBPF 架构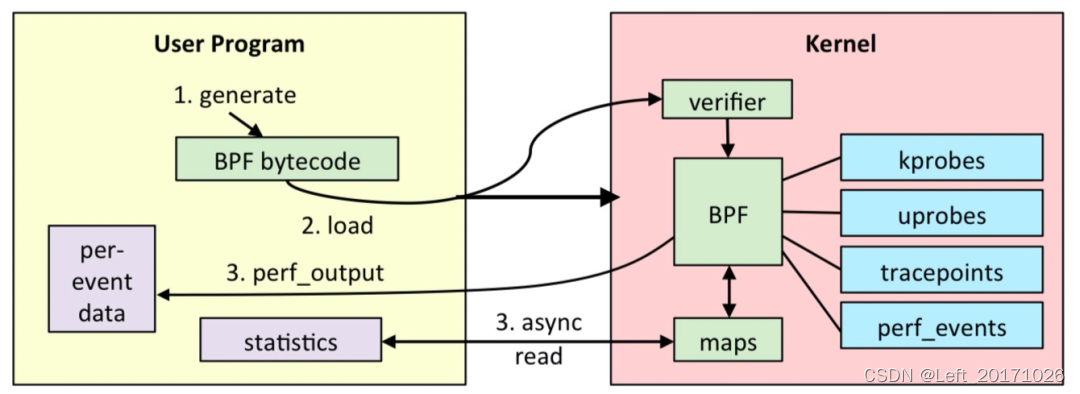
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载 BPF 字节码至内核,如需要也会负责读取内核回传的统计信息或者事件详情
- 内核中的 BPF 字节码负责在内核中执行特定事件,如需要也会将执行的结果通过 maps 或者 perf-event 事件发送至用户空间
其中用户空间程序与内核 BPF 字节码程序可以使用 map 结构实现双向通信,这为内核中运行的 BPF 字节码程序提供了更加灵活的控制
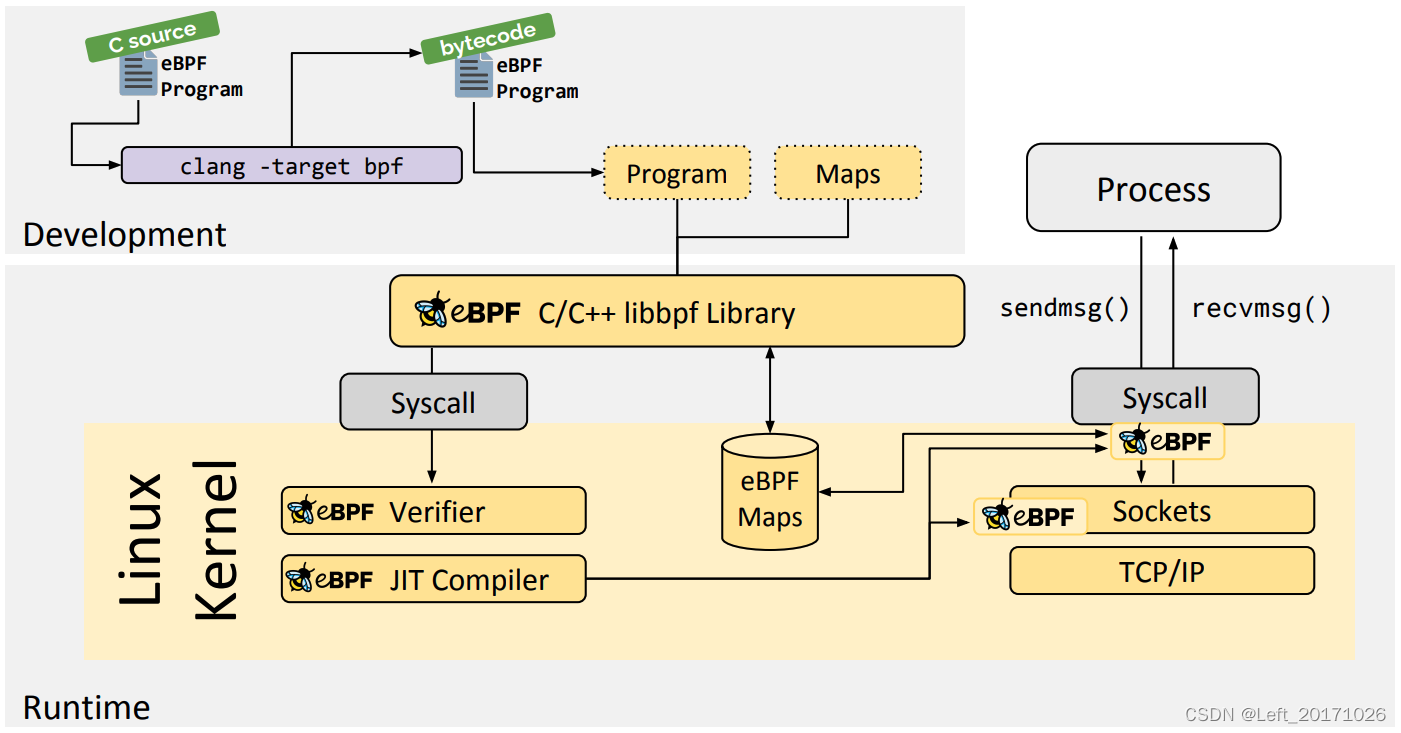
用户空间程序与内核中的 BPF 字节码交互的流程主要如下:
- 使用 C 语言开发一个 eBPF 程序;
- 使用 LLVM 或者 GCC 工具将程序编译成 BPF 字节码
- 使用加载程序 Loader 将字节码加载至内核
- 内核使用验证器(Verfier) 组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行
内核中运行的 BPF 字节码程序可以使用两种方式将数据回传至用户空间:
maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间;
perf-event 用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析。
eBPF 限制
eBPF 技术虽然强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也给予了诸多限制,当然随着技术的发展和演进,限制也在逐步放宽或者提供了对应的解决方案。
eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,函数支持列表也随着内核的演进在不断增加。
eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。
eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;参见 include/linux/filter.h[3],这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半。目前没有计划增加这个限制,解决方法是改用 bpf 映射存储,它实际上是无限的。
/* BPF program can access up to 512 bytes of stack space. */
#define MAX_BPF_STACK 512
eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令( BPF_COMPLEXITY_LIMIT_INSNS),参见:include/linux/bpf.h[4],对于无权限的BPF程序,仍然保留4096条限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。
#define BPF_COMPLEXITY_LIMIT_INSNS 1000000 /* yes. 1M insns */















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









