







从狭义上来看, Hashtable 可以是一种具体类型名称, 比如 .NET 中的 System.Collections.Hashtable 类, 或是 JAVA 中的 java.util.Hashtable 类. 从广义上来看, 她指的是一种数据结构, 即哈希表, 她牵涉了多种具体类型, 像 HashMap, 文章开头提到的 Dictionary 等等虽然称谓五花八门, 都属于哈希表的范畴. 下文中将出现的名词 Hashtable, 除非特别说明, 也是指广义上的哈希表.
哈希表的原始定义和基本原理各种数据结构教程上都有阐述. 简而言之, 哈希表之所以能够实现根据关键字 (典型的例子是一个字符串键值) 来获取记录, 是因为她在内部建立了记录存储位置 - 即内部数组中的索引号和关键字的一套对应关系 f, 因而在查找时, 只需根据这个映射关系 f 找到给定键值 K 对应的数 f(K), 就可直接从数组中取得目的数据 Hashtable[K] = Hashtable.InternalArray[f(K)], 而不必对数组进行遍历和比较. 这个对应关系 f 我们称为哈希函数.
哈希函数 f 的两个重要特点:
[1] 哈希函数可以自定义, 只要使得整数 f(K) 的范围不超出哈希表内部存储数组的上下界即可.
[2] K 的取法有任意种, 但 f(K) 只能固定在一个范围, 因此不同的关键字可能对应了相同的哈希值, 形成了冲突.
需要注意的是哈希函数的运算和冲突的处理都需要系统开销, 尤其后者代价不菲. 因此产生了两个关键问题: 如何设计函数 f 的算法, 以及如何处理冲突, 才能使得哈希表更加高效.
不同语言, 不同运行环境的解决方案都有所不同, 思路上甚至差别很大. 比如 .NET 的 System.Collections.Hashtable 和 Java 的 java.util.Hashtable 虽然称呼完全一样, 但内部算法是不尽相同的, 应此也产生了使用性能的差异.
这里我们选择几个常见的实例来深入分析:
[1] .NET 2.0, System.Collections.Hashtable
[2] .NET 2.0, System.Collections.Generic.Dictionary<K, V>
[3] Java, java.util.HashMap (java.util.Hashtable 的轻量级实现)
[4] PHP5, PHP 是弱类型语言, Hashtable 对编程者是透明的, 在后台运行时实现.
注: 以上 .NET 源代码来自 Reflector 反编译, Java 源代码参见 jdk, PHP 源代码参见 PHP sdk. 同时为便于说明, 下文采用了部分伪代码.
.NET 中的 System.Collecitons.Hashtable (以下简称 Hashtable) 是一种忠于传统的实现, 很有代表风格. 各类数据结构的教科书上一般就是采用类似的原理作为开篇教学. (当然书中的要简单, 原始得多, 离现实还有一定差距)
Hashtable 中的实际数据都存储在一个内部 Array 中 (当然和普通数组一样, 有固定容量, 上下标, 以数字索引存取), 当用户希望取得 Hashtable[K] 值的时候, Hashtable 进行如下处理:
[1] 为了保证 f(K) 的取值范围在 0 <= f(K) < Array.Length, 函数 f 的关键步骤是取模运算, 算得实际数据存储位置为 f(K) = HashOf(K) % Array.Length, 至于这个 HashOf(K) 怎么算出来的, 简单举例来说她可以取关键字的 ASCII 码根据一定规则运算得到.
[2] 如果发生多个 K 值的哈希值重复, 即 f(K1) = f(K2), 而 f(K1) 位置已经有数据占用了, Hashtable 采用的是 "开放定址法" 处理冲突, 具体行为是把 HashOf(K2) % Array.Length 改为 (HashOf(K2) + d(K2)) % Array.Length , 得出另外一个位置来存储关键字 K2 所对应的数据, d 是一个增量函数. 如果仍然冲突, 则再次进行增量, 依此循环直到找到一个 Array 中的空位为止. 将来查找 K2 的时候先搜索 HashOf(K2) 一档, 发现不是 K2, 那么增量 d(K2) 继续搜索, 直到找到为止. 连续冲突次数越多, 搜索次数也越多, 效率越低.
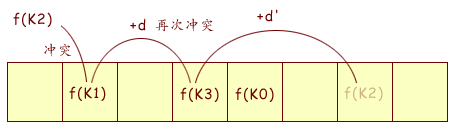
[3] 当插入数据量达到 Hashtable 容量上限时, 对内部 Array 进行扩容 (重新 new 一个更大的数组, 然后把数据 copy 过去), 不仅如此, 由于 Array.Length 发生了变化, 扩容后要对所有现存数据重新计算 f(K). 所以说扩容是个耗能比较惊人的内部操作. Hashtable 之所以写入效率仅为读取效率的 1/10 数量级, 频繁的扩容是一个因素.
f(K) 的取法是哈希表的关键所在, 从根本上决定了该哈希表的许多重要特征, 例如 .NET 中 System.Collections.Hashtable 的哈希函数 f 其算法决定了这样一些方面:
[1] 数组容量 Array.Length 越大, 冲突的机会越小. 由于 f(K) 的取值范围等于 Array.Length, 因此随着 Array.Length 的增长, f(K) 的值也更加多样性, 不容易重复.
[2] 数组容量 Array.Length 期望是一个 "比较大的质数", 这样 f(K) = HashOf(K) % Array.Length 取模运算之后得出的数冲突机会较小. 想象一个极端例子, 假设 Array.Length = 2, 则只要 HashOf(K) 是偶数, f(k) 都为 0. 所以说哈希表的实际容量一般都是有规律的, 和数组不一样, 不能任意设置.
[3] 随着插入的数据项逐渐增多, Hashtable 内部数组剩余的空位也越来越少, 下一次冲突的可能性也越来越多严重影响效率. 因此不能等到数组全部塞满后才进行扩容处理. 在 .NET 中, 当插入数据个数和数组容量之比为 0.72 时, 就开始扩容. 这个 0.72 称为装填因子 - Load Factor. 这是一个要求苛刻的数字, 某些时刻将装填因子增减 0.01, 可能你的 Hashtable 存取效率就提高或降低了 50%, 其原因是装填因子决定 Array.Length, Array.Length 影响 f(K) 的冲突几率, 进而影响了性能. 0.72 是 Microsoft 经过长期实验得出的一个比较平衡的值. (取什么值合适和 f(K) 的算法也有关, 0.72 不一定适合其他结构的哈希表)
[4] Hashtable 的初始容量 Array.Length 至少为 11, 再次扩容的容量至少为 "不小于 2 倍于当前容量的一个质数". 这里举一个例子, 方便大家看看 Hashtable 是多么浪费空间.
假设以默认方式初始化一个 Hashtable, 依次插入 8 个值, 由于 8 / 0.72 > 11, 因此 Hashtable 自动扩容, 新的容量为不小于 11 * 2 的质数, 即 23. 所以, 实际仅有 8 个人吃饭, 却不得不安排一桌 23 个座儿的酒席, 十分奢侈. 避免如此铺张的途径是在初始化 Hashtable 时用带参构造方式直接指定 capacity 为 17, 但即便这样仍浪费了 9 个空间.
有心的读者经过计算, 可能会问为什么不是指定初始容量为 13, 13 是质数啊, 13 * 0.72 > 8 啊. 确实理想情况是这样, 但实际上由于动态计算并判断一个数是否质数需要大量时间, 故 .NET Hashtable 中的 capacity 值是内部预设的一个数列, 只能为 3, 7, 11, 17, 23... 所以十分遗憾. (注: 只有当 Array.Length > 0x6DDA89 时动态计算扩容容量, 正常情况下我们不会存如此多的数据进去)
.NET 的 Hashtable 就是以这种方式来减少冲突, 以牺牲空间为代价换取读写速度. 假设你在实际开发中对内存空间要求很敏感, 譬如开发 ASP.NET 超大型 B/S 网站时, 就十分有必要检讨使用 Hashtable 的场景需求, 有的时候能否换个方式, 采取自定义 struct, 或者数组来高效实现呢?















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









