






文章目录
linux 基本结构

Linux和核心就是kernel(内核),他负责整个系统的运行和对硬件的调度。将用户对系统的调用和各类硬件的调用都统一和封装。应用只要和kernel沟通,让kernel和各类硬件去交流,我们应用开发技术人员就不需要管他就好了。
虚拟文件系统VFS

VFS(Virtual Filesystem Switch):内核既管内存,又管磁盘IO。
作为LINUX内核来说,它在内存中构建了一个虚拟文件系统VFS,不同于windows上的物理文件系统结构,C盘代表的就是物理的C盘分区,D盘就是D盘的物理分区,
VFS 虚拟文件系统本质就是一颗目录树,每个目录可以映射代表不同的物理设备,可以挂载
为什么要有VFS?
因为VFS相当于一个中间的解耦层,下层的存储源的存储形式可能是各不相同的,可能是来自不同的硬件设备,需要将这些包成一个统一的对外接口暴露给上层应用使用。使上层的应用程序能够使用通用的接口访问不同文件系统、不同的设备。
pagecache
在VFS中,每一个文件都有一个inode id作为唯一标识,一个文件首先要被内核读到内存中,然后开启一个pagecache(默认4K)作为这个文件在内存中的缓存,这样的话如果多个应用都需要这同一个文件,只需要来内存中命中这一份文件,而不需要多次读取,后续对文件的操作都将是基于内存中缓存的操作,将会变得非常快。
inode:
可以看该博客进行细节了解:http://www.ruanyifeng.com/blog/2011/12/inode.html
感谢阮一峰大神(_)
inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础。
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。每个inode节点的大小,一般是128字节或256字节。
困扰我多年的疑问: 一个inode指向的一个固定的block区域,一个文件我看只有一个inode,那为什么有的文件1M,有的1G,这个怎么玩?????/(ㄒoㄒ)/~~
答疑:一个文件对应的在系统中的inode这个解答是没错,但是其实他是一个层次型的inode结构。一个文件存储的结构其实是一个树状的,我们对外的inode其实就是这个树的根的inode。
保存一个大文件时结构是这样的
inode–>[block:下一层的inode_list,数据]–>[block:下一层的inode_list,数据]
如下图的结构

Inode 文件在硬盘中的存储对应的block的索引节点。
文件打开的时候系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据,读到pagecache页缓存中。
两个程序如果打开的是统一文件,共享的是同一个pagecache 4k。
如果后续我们对pagecache进行了修改,会产生脏数据,这时候需要使用flush刷新到磁盘中去。
dirty
pagecache作为文件的缓存,当被进行修改了的时候,实际是对这个缓存内容的修改,此时就会标记成dirty
“脏”这个标识是内核对于上层打开的文件的一个统一的管理,并不是针对某一个文件。内核会根据自己的设定,把数据输入到磁盘中去。如果你在5秒钟内产生了3.8G数据,又恰好没有触发内核的写磁盘操作,这时候突然断电会导致你这些数数据的丢失。
如果两个线程同时修改同一块数据,会加锁。
Redis的持久化,也是受操作系统内核这种机制的约束。
flush
被标记为dirty,意味着这个缓存的文件是发生了变化的,也就是需要将变化同步更新到磁盘的真实文件中,所以会有一个flush的操作,但flush的触发时机也是分为很多种,每一种的成本也不同:
1、例如:可以修改一次缓存文件,就通过内核刷写更新一次内容到磁盘文件中(响应快,但效率最差)
2、考虑到dirty的文件并不是只针对某一个文件的, 而是内核中会存在许多dirty的文件,因此可以当内核中的dirty达到一定比例,内核进行刷写(存在中间数据丢失风险,效率较高)
3、可以周期性的进行刷洗内核中的dirty的文件。(存在中间数据丢失风险,效率较高)
FD(文件描述符)
内核是利用文件描述符来访问文件。文件描述符是非负整数。
打开现存文件或新建文件时,内核会返回一个文件描述符。
读写文件也需要使用文件描述符来指定待读写的文件。
但是文件描述符这个概念是只有在Linux和unix才有。
每一个进程在内核中,都对应有一个“打开文件”数组,存放指向文件对象的指针,而 fd 是这个数组的下标。
我们对文件进行操作时,系统调用,将fd传入内核,内核通过fd找到文件,对文件进行操作。
在linux中,一个进程默认可以打开的文件数为1024个,fd的范围为0~1023。可以通过设置,改变最大值。
在Linux下有一句话是一切皆文件,文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开.
文件的内存中的pagecache,就意味着多个应用有可能都共享使用一份缓存内容,那么各自的例如对文件的不同位置的读取,就涉及到一个seek偏移量可能是各不相同的,而这些包起来对外来看就统一用FD来表示。
通过df -h可以看到当前VFS的整个结构

计算机引导的时候,先挂载了3分区,又挂载了1分区。新的挂载覆盖了原有的boot目录

这个结构就是首先挂载了来自/dev/sda3的一个/的根目录,然后发现还有一个单独从/dev/sda1挂载的/boot目录,而实际上/下面也应该有一个/boot目录,但这个新挂载的/boot目录会覆盖原本/中的/boot目录。
这里看到的实际上就是来自 /dev/sda1的/boot

那如果把这个挂载的/boot去掉呢?

发现挂载结构少了/boot,确实卸载掉了/boot:

此时再去/下查看,发现/boot还在,这个/boot就是/原本的/boot,只不过里边是空的:

此时重新再挂载上刚才卸载的/boot,发现再次查看/boot,内容又回来了:

但这个过程我们可以发现,对于程序而言,这个文件目录树结构非常的稳定,不会随着挂载的变动,目录发生什么变化
并且这之中其实是有一个映射的过程,通过这个过程,我们可以想到,日后如果某个文件夹例如/abc的大小不满足需要,完全可以接入一块新的比较大的外接设备,然后把旧数据迁移过去,然后将外接设备挂载到/abc,也就是覆盖掉原来的/abc,这样就完成了一个无结构修改的静默扩容操作了。
LINUX中的一切皆文件
在冯诺依曼体系结构下,计算器,控制器就相当于我们的CPU,主存储器就相当于我们的内存, 而输入输出设备也就是一切的IO设备。而这一切,在linux之中,全都是用文件进行表示。
磁盘文件、摄像头、打印机,都被看做是文件,基于文件的这种抽象,就可以应用到IO流了。
那么如何区分这些不同的文件?我们引入文件类型:

-:普通文件
可执行,图片,文本
-rwxr-xr-x. 1 root root 764088 4月 5 2012 vi
d:目录
dr-xr-xr-x. 2 root root 4096 6月 12 2019 bin
l:链接
软链接,硬链接。
无论是硬链接还是软连接,如果修改任意一方,另外一个文件也会看到这个变化。
硬链接

一个文件的硬链接下的各个文件与源文件共享inodeid,可以通过stat xx文件查看,并且会在文件本身标识着引用数Links,当删除源文件时,对其他的硬链接文件没有影响。

软链接


一个文件的软链接下的各个文件inodeid是不同的。当删除源文件时,软链接的文件也会无法使用。

如果删除原有的msb.txt,则xxoo.txt找不到链接了,会标红报错

b:块设备
读取的内容位置可以来回漂移。
例如:硬盘
证明一切皆文件
用dd命令生成一个空的mydisk.img文件

dd if=/dev/zero of=mydisk.img bs=1048576 count=100
输入是/dev/zero(空),输出是mydisk.img,一个块的大小是1048576(1M),一共有100个块组成,最后生成的就是100M的被0填充的文件
挂载到虚拟的环回设备上,挂载之后进行格式化

losetup /dev/loop0 mydisk.img
让环卫接口设备/dev/loop0挂载刚刚生成的文件mydisk.img 也就是/dev/loop0不再指向一个物理地址,而是指向了新生成的这个文件
mke2fs /dev/loop0
格式化成ext2的文件格式。
到现在为止,我们已经成功挂载到了一块虚拟环卫设备,那能不能也类似的让linux中的某个虚拟文件路径映射到这个虚拟设备上? 就类似于上面/boot的效果。
把新的loop0挂载到原来的/mnt/ooxx目录中去

指定挂载的文件格式为ext2,把它(/dev/loop0)挂载到 /mnt/xxoo/的虚拟路径上
现在/mnt/ooxx是空的

我们希望用子目录模仿根目录里面的目录结构,以及程序的摆放位置。
1、找到bash所在位置,拷贝过来

2、将bash需要动态链接的文件,也拷贝过来

将根目录切换到当前目录,并将当前目录下的bin下的bash启动

在当前bash中输出“hello mashibing”,重定向到根目录下的abc,txt文件中

可以看到abc.txt被输出到新的根目录下。
那么Docker呢?也是这个原理吗?
这个实验不同于Docker,Docker更加复杂,它不只是文件系统的命名空间的一个子域。
Docker复用的是物理机的内核,Docker里面跑的是进程,先有镜像,有了img镜像之后,才有container容器的概念。
源于整个虚拟文件系统的支撑。
文件描述符

1、lsof命令
lsof是list open files的简称,它的作用主要是列出系统中打开的文件,基本上linux系统中所有的对象都可以看作文件,lsof可以查看用户和进程操作了哪些文件,也可以查看系统中网络的使用情况,以及设备的信息。

创建一个文件描述符8,用来读取ooxx.txt
NODE列:表示Inode号
如果lsof加上-o参数的话,会显示一列OFFSET,表示当前读文件位置的指针
<
表示的是输入重定向的意思,就是把<后面跟的文件取代键盘作为新的输入设备
>
由于左侧没有内容,因此将file清空
执行 cat file1 > file2,则将文件1的内容覆盖掉文件2的。因此">"左侧可以使用其它命令组合并将输出当做右侧文件的输入
file1 >> file2
用于覆盖,将左侧文件内容追加到右侧文件中

使用read读文件:

新开了一个bash标签页,用一个新的文件描述符6,去读取ooxx.txt
证明两个进程读取文件时,不会相互影响:

我们可以得出这个结论,内核为每一个进程各自维护了一套数据,包括fd文件描述符。
fd维护了一些关于文件的偏移、Inode号,以及元数据信息等。
这些内容看起来和Java没什么关系,但是在使用Java进行文件IO时,关系到每种不同的写法的成本。所以还是很重要的~
s:socket (底层类型,不能直接看到)
用文件描述符8,指向一个socket连接


关于/proc目录
与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件
/proc/$$ 是当前bash的文件
$BASHPID是当前bash的pid
/proc/$$/fd是当前程序的所有的文件描述符, 也可以使用lsof -op $$看见当前进程的文件描述符的细节,包括偏移量、指针等等。
关于 0标准输入 1标准输出
<表示输入
>表示输出
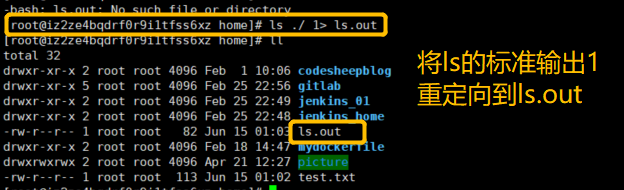
ls 命令的标准输出
ls ./ 1> ls.out 将 ls的标准输出1重定向到 ls.out
cat 命令的标准输入、标准输出
cat 0< test.txt 1> cat.out 将 cat 的标准输入重定向为 test.txt , 将其标准输出重定向为 cat.out

read命令的标准输入、标准输出

重定向操作符< >的对接
让两个流写到不同的文件中去:

让两个流写到相同的文件中去:

管道命令 |
head 默认读前 10 行
head -3 读前 3 行
tail 默认读后 10 行
tail -3 读后 3 行
head -8 test.txt | tail -1 通过管道,让左面的输出流入右面的输入,实现仅输出第 8 行
进程之间的父子关系
当前所在的bash的进程id号

在当前bash中新开一个bash,打印新开的bash的进程id号

使用pstree查看进程关系

使用exit,又回到了11053

关于变量
父进程定义的变量x,不能在子进程取到,除非使用export
这也是为什么在/etc/profile/配环境变量的时候,要添加export的原因

关于代码块、管道开启的子进程
在一个花括号中,所有的指令在同一个进程中执行。
bash是解释执行的,如果看到管道,会将管道左侧的命令独立开启一个子进程,管道右侧的命令独立开启一个子进程,用管道进行对接。而进程的隔离级别很高,所以在新开启的进程中对变量a的修改,不会影响父进程a的值。
$$ 的优先级高于 |,$BASHPID 的优先级低于 |

看一下进程号,可以发现管道两侧开启的是独立的子进程

实际上,我们进行的是如下管道操作:
p:pipeline(底层类型,不能直接看到)

上面代码管道符左右都会各自启动一个子进程去执行花括号里的内容,而我们知道管道符的作用是将管道符左边的输出作为右边的输入,那它是如何实现的呢?此时看下它们的文件描述符
下面这个图可以看到,管道左侧的进程和右侧的进程通过管道被对接起来
可以看到左侧子进程(4512)的输出到pipe管道文件描述符上,而右侧子进程(4513)的输入也为同一个pipe管道文件描述符上,这样就完成了管道符的功能

我们也可以使用
lsof -op 4512
lsof -op 4513
这两个命令,看到两个子进程中正在开启的管道。
两者指向的都是一个inodeid 39968的pipe,并且一个是写,一个是读

c:字符设备
只能向后读取,不能自由读取前后偏移量的数据,可能会有一些编解码约束,不能被切割的字符数据
键盘,socket
tty显示终端机连接标准输入设备的文件名称
crw--w---- 1 root tty 4, 32 7月 23 22:37 tty32
eventpoll
内核提供给epoll的内存区域。
因为redis就是基于epoll实现连接的,启动redis,然后看redis的文件描述符可以看到:
lrwx------ 1 root root 64 7月 23 22:37 5 -> [eventpoll]















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









