







文章目录
真题
如何判断一棵树是不是二叉排序树?
1,思路:
对二叉树执行中序遍历,如果是二叉排序树则遍历的顺序是递增序列。只要出现逆序则就可以判断不是二叉排序树。
2,代码
int predt=INF//INF为比序列所有元素都小的值
int judBST(BTNode *bt)
{
int b1,b2;
if(bt==NULL)//树为空则不结束
return 1;
else{
b1=judBST(bt->lchild);//遍历左子树,接受左子树情况
if(b1==0||predt > bt->data)//左子树中已经逆序了或者本层逆序
return 0;//返回0,不是二叉排序树
predt=bt->data;//读取本层根节点
b2=judBST(bt->rchild);//遍历右子树,接受右子树情况
return b2;//返回右子树的情况
}
}
3,效率
时间复杂度:排序树中每个元素都要被遍历进行对比,则为O(n)
空间复杂度:取决于递归深度(递归栈中最多塞入的函数数量),也就是二叉树的高度,为O(logn)
选择题
1,二分查找法的时间复杂度
从二叉树的角度看:二分查找就是从根节点出发沿着某一条路径查找。其中最大查找次数就是查到最下层节点,也就是等于树的高度。

假设树高h,有n个节点。对于第h层,最少只有最左边一个节点——第一层到上一层节点数+1;最多就是层满到最右边节点——为第一层到本层节点数。
易知,从第一层开始到第h层节点数为
2
h
−
1
2^{h}-1
2h−1
则
2
h
−
1
<
=
n
<
=
2
h
−
1
2^{h-1}<=n<=2^{h}-1
2h−1<=n<=2h−1
l
o
g
n
+
1
<
=
h
<
=
l
o
g
n
+
1
log^{n+1}<=h<=log^{n}+1
logn+1<=h<=logn+1
左边为本层节点数最多的时候,那么本层其他节点数都小于这个值,由此向上取整。
右边为本层节点数最小的时候,那么本层其他节点数都大于这个值,由此向下取整。
二分查找的查找次数不会比二叉树层高还多,由此查找次数<= l o g n + 1 log^{n}+1 logn+1;为O(logn)级别
2,理解m阶B树
m阶B树非根节点最多有m个分叉,m-1个节点
B树可以为空,根节点可以左右子树都为空
为了保证树不太高,每个节点的分叉应该保证在⌈m/2⌉以上。最多为m个分叉。节点则是在⌈m/2⌉-1到m-1个。
3,平方探查
d+ 1 2 1^{2} 12 d- 1 2 1^{2} 12 d+ 2 2 2^{2} 22 d- 2 2 2^{2} 22…
4,HASH()函数的目的
保证元素等概率,均匀地落在表格中。以便减少冲突的情况。
5,手算折半查找
起始下标+终点下标,除以2,然后向下取整
得到中间下标
对中间下标,要么-1查找左子表,要么+1查找右子表
6,平衡因子
平衡因子可能为负数,因为是左子树高度减右子树高度。范围在[-1,1]
7,平衡二叉树每层所需最少节点
H0=0 H1=1 H2=2 … Hn=Hn-1 + Hn-1 + 1; n为层数
通过通项公式可以求得构建n层平衡二叉树所需的最少节点数量。
如H5=12 H6=20 则15个节点最多只能构建5层的平衡二叉树;进一步,对这个二叉树遍历最多就是树的层数,即只需要5次。
而最少遍历次数是叶节点所在的最低层数。需要画图确定。
可以通过遍历次数排除掉序列数量不对的选项。且查找对比的最后一个应该是要查找的元素(假设元素在树中)
综合题
1,二叉排序树T前序序列中关键字依次插入空的二叉树排序树T1,T1与T是否相同。
前序序列是按“根左右”,顺序遍历。第一个节点一定是根,然后以根节点为界,其后元素中小于根节点的一组元素为左子树节点,大于根节点的一组元素为右子树节点。首先插入的第一个节点为根节点,然后依次递归的插入左子树节点和右子树节点,得到的树和原来的一样。
2,有序表与无序表查找长度
1,查找失败,有序表遇到第一个大于key的元素即可结束扫描(n+1)/2。无序表要从头到尾扫描n+1。
2,查找成功,表中有多个相同值元素,要求全部找出。
有序表中值相同的元素都是相邻,只需继续扫描,遇到值不相同的元素即可停止。小于n+1
无序表值相同元素随机分布,要全部扫描表。n+1
3,哈希表
填装因子
装填因子:a=n/m 其中n 为关键字个数,m为表长。装填因子是哈希表装满程度的标记因子。值越大,填入表中的数据元素越多,产生冲突的可能性越大。
由填装因子求得表长:
假设填装因子a,元素n,则表长=n/a向上取整。(理解为:表没有装满也算一格)
构造Hash函数——除留取余法
H(key) = key mod p
p是小于等于表长的最大素数,选择素数可以最大程度减少冲突
计算ASL

1,查找成功
实际就是统计每个元素被查找到的次数,由于采用了队列链表的形式,队列第一个元素找一次即可找到,第二个元素找两次即可。最后除以元素个数,就是平均查找长度。
ASL=(6+4*2+3+4)/12=1.75
2,查找不成功
不成功则是要考虑Hash函数使用的表长(如除留取余法的p),统计每个表格查找几次才会失败,最后除以表长计算平均值。如果表中没有元素,查找次数为0;如果有n个元素,则查找n次失败。
ASL=(4+2+2+1+2+1)/13=0.923
4,线性探测法

利用线性探测法解决冲突,如H(1)与H(14)冲突,因此向后探测一位到表2。

1,查找成功
在计算ASL时应该考虑向后探测的情况,如查找14只需要1次,而查找27需要4次(含向后探测的3次)。

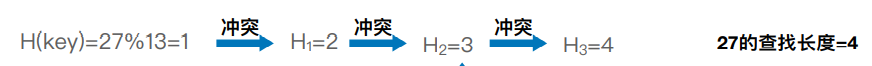

2,查找失败
从Hash函数确定的位置向后找直到遇到空位置,并且空位置比较也算一次。


越早遇到空位置,越早确定失败


如果该元素不存在,则最好的是落在L0,对比一次即可。最坏的是落在L1,对比13次。而且受Hash限制只可能在0-12处对比,只需考虑Hash函数映射的表格。

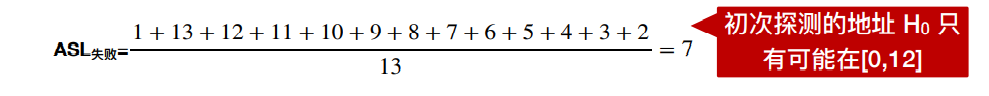
5,B树最少节点数
第一层只有一个节点,第二层两个节点。以后每次都是多k个分支,也就是多乘k。且节点数与关键字数要区分开。

6,平衡二叉树
1,节点的顺序
平衡二叉树就是二叉排序树左右子树高之差不能超过1,排序的意义就是从小到大或者从大到小排序;按从小到大来,则节点的顺序就是左中右。
下图中顺序就是7 8 9 10 11 13 14

2,确定第k个节点位置
①思路
在二叉排序树中添加一个lsize数据,保存该节点左子树高度+1。实际上lsize就是以该节点为根的子树中该节点次序。
如果该节点是根节点,或者是父节点的左孩子,则lsize代表整体的次序。
如果该节点是是父节点的右孩子,则lsize代表相对的次序,需要加上父节点的次序才为整体的次序。
对于第k个元素,从根节点开始查找,如果向左子树查找,则不改变k
如果向右子树查找,k要减去父节点的lsize,变为相对的次序值。
②代码
typedef struct BTNode{
int data;
int lsize;
struct BTNode *lchild;
struct BTNode *rchild;
}BTNode;
BTNode * search(BTNode *t,int k)
{
if(t==NULL||k<1)
return NULL;
if(t->lsize==k)
return T
if(t->lsize>k)
return search(t->lchild,k);
else
return search(t->rchild,k-t->lsize);
}
7,插入(创建)平衡二叉树
在平衡二叉树的存储结构中,添加一个count,记录相同节点数量。在此基础上实现插入新节点。
在递归中,传入的参数树T->rchild或者T->lchild,这样在遍历到底层时,实际为底层的空孩子节点T,已经被父节点指向了,对其进行插入时无需关注父节点。(用非递归实现需要记录父节点)
# include<stdio.h>
#include <malloc.h>
typedef struct Tree {//存储结构
int key;
int count;//存储重复数据
Tree* lchild;
Tree* rchild;
}Tree;
void insert(Tree*& T, int n) {//插入元素
if (T != NULL) {
if (n > T->key) insert(T->rchild, n);
else if (n < T->key) insert(T->lchild, n);
else {
T->count++;
return;
}
}
else {
T = (Tree*)malloc(sizeof(Tree));
T->key = n;
T->count = 1;
T->lchild = T->rchild = NULL;
return;
}
}
非递归实现,需要增加一个记录父节点的指针,并且该指针要在主函数定义。
void Insert(Tree*& T,Tree *&pr, int n) {//插入新节点
Tree* p = T;//代替T作为遍历对象
while (p != NULL) {//p遍历到底,pr为其父节点;或者t本身就为空
if (p->key != n) {//按排序规则向下遍历
pr = p;
if (n < p->key) p = p->lchild;
else p = p->rchild;
}
else {
p->count++;
return;
}
}
Tree* s = (Tree*)malloc(sizeof(Tree));
s->key = n;
s->count = 1;
s->lchild = s->rchild = NULL;
if (pr == NULL) s = T;//t本身就是空,直接替换指针指向
else if (n < pr->key) pr->lchild = s;//pr与新节点比较大小,决定插入左右孩子位置。
else pr->rchild = s;//pr改变指向在函数结束后也不会被销毁
}
1,malloc函数会开辟一个新空间,然后s指针会从指向t的孩子节点变为指向新空间。函数结束后s被销毁,t不变化。


2,若是s指向t所指的空间,然后修改值,则t变化。

3,递归中,自始至终都是T指针在改变,即使函数结束也不会被销毁。从而实现了值的修改。

函数内t的值修改。


回到主函数这种修改仍然保留。


8,给定序列中关键字不同,判断此序列是否是二叉排序树的查找序列
1,思路
对于二叉排序树的查找序列,就是对一个关键字进行查处,产生的序列。
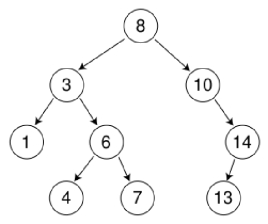
如查找7,产生的序列就是8 3 6 7
查找关键字X,沿顺序查找,只可能顺着左子树或者右子树向下逐层查找,则前后节点一定是父子节点关系。且查找的值会在X周围波动,不断逼近X(小于X的会递增,大于X的会递减,直到最后达到X)。
那么对于给定值X,按顺序遍历序列(相当于用x进行一次查找),小于x存在s1,大于x存在s2(具体实现就是,节点i与节点i+1对比,i>i+1,x大于节点i,向右子树查找,则i存在s2,i<i+1,x小于节点i,向左子树查找,则i存在s1)。
如果是查找序列,s1单调递增,s2单调递减;s1中元素除最后一个等于X,其余的均小于X,s2中均大于x。满足以上条件,则为查找序列。
2,代码
#include<stdio.h>
#include<malloc.h>
#define maxsize 10
typedef struct
{
int elem[maxsize];//查找序列数组
int len;//序列内元素个数
}sequence;
void reduce(sequence& s, sequence& s1, sequence& s2)
{
int i = 0, j = 0, k = 0;
do
{
while (i + 1 < s.len && s.elem[i] < s.elem[i + 1])
s1.elem[j++] = s.elem[i++];
while (i + 1 < s.len && s.elem[i] > s.elem[i + 1])
s2.elem[k++] = s.elem[i++];
} while (i + 1 < s.len);
s1.len = j;
s2.len = k;
}
int judge(sequence& s1, sequence& s2, int x)
{
int i, flag;
flag = 1;
i = 0;
//判断s1是否满足条件,单调递增,s1的元素值小于x
while (flag && i + 1 < s1.len)
{
//An-1>An,单调递减,记录退出
if (s1.elem[i] > s1.elem[i + 1] || s1.elem[i] > x)
flag = 0;
else
++i;
}
//判断s2是否满足条件,单调递减,s2的元素值大于x
while (flag && i + 1 < s2.len)
{
//An-1<An,单调递增,记录退出
if (s2.elem[i] < s2.elem[i + 1] || s2.elem[i] < x)
flag = 0;
else
++i;
}
return flag;
}
int issearch(sequence& s, sequence& s1, sequence& s2, int x)
{
reduce(s, s1, s2);
return judge(s1, s2, x);
}
int main()
{
sequence s, s1, s2;
int A[] = { 20, 30, 90, 80, 40, 50, 70, 60 };
for (int i = 0; i < 8; ++i)
{
s.elem[i] = A[i];
}
s.len = 8;
printf("%d", issearch(s, s1, s2, 60));
return 0;
}
9,折半查找比较次数
对于一个元素,查找失败的次数,最多就是折半查找树的高度。

10,树的阶
题干说,B树的阶为5.但是实际最少节点的情况只有两个分支。如下图:

1,如果题干只说了阶为5,那么分支数可以不为5,满足最低数目即可。因为阶是人为规定的,只是当前状态没有达到5个分支。
2,如果是画出了一个树,那么依据图中的分支数确定阶。
11,计算散列表的平均查找长度
1,成功,根据Hash()函数计算每个元素,一次找到就1,冲突就计算比较次数。计算所有的元素情况。
2,不成功,对0-6表格计算,因为不管什么元素输入Hash()都只映射到0-6。遇到空格就确认失败。如元素映射到表0,查找到表2,找3次失败。

12,带概率的查找
对n个元素集合,每个元素都带有一个查找到的概率。
1,如果是顺序结构存储元素,按照概率大小降序排列。采用顺序查找进行。
2,如果是链式存储,要么按照单链表,按概率降序排列,顺序查找。要么构建二叉排序树,按照左小右大构造。且对于字母,也要按照字母顺序区分大小,否则打乱就无法查找。
















 3570
3570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











