







字符串的取代
将字符串的一部分换成其他的字符串的这种操作称为"取代"。Ruby有sub与gsub这两个方法用来做取代的操作,这两个方法的差异在于sub方法是取代最先找到的地方,而gsub方法会取代所有找到的地方。
关于sub方法与gsub方法,请参见"14.6.1 sub方法与gsub方法"一节的介绍。另外,sub方法与gsub方法还有破坏性的版本sub!方法与gsub!方法,同样在该节进行介绍。
http://book.51cto.com/art/200902/111862.htm
12.8.1 查找字符串
http://book.51cto.com 2009-02-26 15:57 博硕文化/柯志杰 电子工业出版社 我要评论(0)
- 摘要:《Ruby Programming:向Ruby之父学程序设计》第12章字符串(String)类,本章将要为大家介绍String类的处理。本节为您讲述的是查找字符串。
- 标签:字符串 Ruby 程序设计 向Ruby之父学程序设计
12.8 字符串的查找与取代
一般操作字符串的时候,经常会有"搜寻"或"取代"的需求。Ruby可以很容易地进行字符串查找。
12.8.1 查找字符串
想要检查字符串里是否包含特定的字符串,可以使用index方法或rindex方法。
index方法会从字符串的左边开始查找是否包含实参所指定的字符串,而rindex方法则会从右边开始查找。rindex的"r"是"right(右边)"的意思。
str = "sumomomomomomomomonouchi"
p str.index("momo") #=> 2
p str.rindex("momo") #=> 14
index方法与rindex方法在找到字符串的时候,会返回找到处的位置,找不到时则会返回nil。
另外,单纯地想要检查是否包含时,也可以使用include?方法。
str = "sumomomomomomomomonouchi"
p str.include?("momo") #=> true
若想检查字符串是否包含特定样式时,则需要使用正则表达式。关于样式查找,详见"第14章 正则表达式(Regexp)类"。
另外,有时候不只是想要查找字符串,还想对找到的字符串做某些处理。这时Ruby语言往往可以使用迭代器简单完成,请参考"第20章 迭代器"。
关于换行
换行符是表示文字行返回的特殊记号。前面的12.6节中的专栏"文字编码"一文中已经说到,在计算机中,一般情况下,文字中使用编码的做法是行不通的,使用换行符的做法跟使用编码的做法一样行不通。然而,换行符处理的困难之处主要还在于:不同的OS,换行符也不尽相同。
对一些典型的OS的换行符总结如下。在这里,"LF"(Line Feed)的编码为"0X0a","CR"(Carriage Return)的编码为"0X0d"。

在Ruby中,换行符号为"LF",并在IO#gets方法等实际情况中作为预设行的分隔符。当然,对于Mac OS 9以前标准的文本来说,在Ruby中就会出现"无法识别换行"的问题。
在gets方法中,对可识别的换行符的变更,相对应的方法的有关详情,还请参照17.5节的论述。
查询是否含有样式(Pattern)
如果只要查询字符串中是否包含样式的时候,可以使用=~运算符(Regexp#=~)
#是否包含有空格符或者Tab?
p(/[ \t]/ =~ "a c") #=> 1
p(/[ \t]/ =~ "abc") #=> nil
查询样式第一次出现的字节位置
如果想要知道指定样式第一次出现的字节位置的话,可以使用String#index
p "xxxabcabcabcxxx".index(/abc/) #=> 3
p "xxxabcabcabcxxx".index(".") #=> nil
p "xxx.........xxx".index(".") #=> 3
查询样式最后出现的字节位置
如果想要知道指定样式最后一次出现的字节位置的话,可以使用String#rindex。
p "xxxabcabcabcxxx".rindex(/abc/) #=> 9
p "xxxabcabcabcxxx".rindex(".") #=> nil
p "xxx.........xxx".rindex(".") #=> 11
取得匹配的详细信息
使用Regexp#match的话,可以取得关于匹配的详细信息(MatchData对象)。我们可以由此对象中取得关于匹配部分的开头、结尾的字节位置,以及匹配部分的字符串等各种信息。String#match也可以取得与Regexp#match同样的结果。
m = /abc/.match("xxxabcabcabcxxx")
p m.begin(0) #=> 3
p m.end(0) #=> 6
p m[0] #=> "abc"
p m.post_match #=> "abcabcxxx"
m = "xxxabcabcabcxxx".match(/abc/)
p m.begin(0) #=> 3
p m.end(0) #=> 6
p m[0] #=> "abc"
p m.post_match #=> "abcabcxxx"
在一个字符串中匹配所有的候选
到目前为止介绍的方法都只能匹配到在字符串中数个可匹配的开头(或者结尾)部分的其中一个,不过实际上我们也可以让程序去匹配所有符合的部分。这就要使用String#scan方法。
#匹配所有注音符号
str = "ㄅ\n aad ㄆㄇ e\ne ㄈ0\n0a ㄍ\n ii ㄚ\n"
str.scan(/[ㄅ-ㄜ]+/){|s|
puts s
}
#=> ㄅ
#=> ㄆㄇ
#=> ㄈ
#=> ㄍ
#=> ㄚ
String#scan在正则表达式中加入“( )”的话,则会改变其动作,请读者要注意。
只处理包含有样式的行
在一个字符串中包含多行的时候,若要重复处理包含样式的行,则可以使用String#grep(Enumerable#grep)。
#只处理包含有“快”或“乐”的行
str = "快\n aad好吃 e\ne 乐 0\n0a 哈\n ii 好\n"
str.grep([快乐]){|line|
p line
}
#=> "快\n"
#=> "e 乐 0\n"
也就是说,下面两个方式是一样的。
str.gerp(re){|line|
各行的处理
}
str.each{
if re =~ line
各行的处理
end
}
说明:Ruby1.6版中String#scan的参数在两个以上字符串的情况下,会变换为Regexp对象之后进行查找,而在Ruby1.8版之后就会直接以该字符串来进行搜索。因此在有Meta字符(“.”及“*”等)的情况下,其运作会有所不同。要避开这个规格的问题,只要一直都使用正则表达式的参数就可以解决。
String#match在Ruby1.8版之后才被定义。
在处理多字节字符串的时候,一定要实现设置$KCODE。在这项技巧下,我们假设的环境是设置$KCODE="UTF8"(-Ku)后,再进行加载、执行。
Ruby中,内置很多对字符串操作的方法,下面我们看看最主要的一些方法
连接字符串

可以对字符串做乘法

字符串比较

我们知道字符串其实存储的是数字,对字符串进行比较其实就是比较ASCII值
用?求字符的ASCII值

数字代表的字符

将需要替换的表达式的放入#{..}
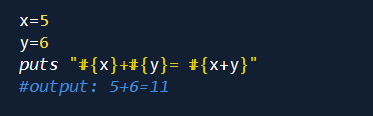
字符串也可以插入字符串变量

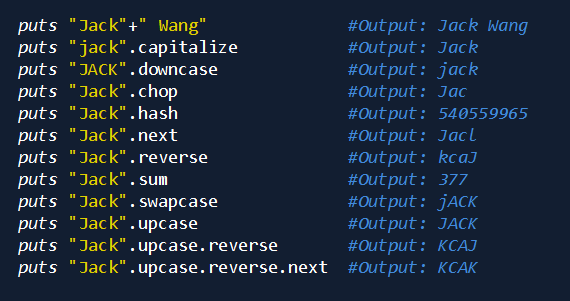
字符串常用方法

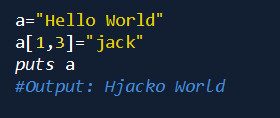
替换字符串的某一范围内的值
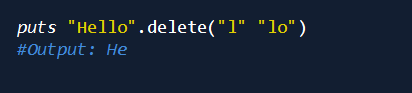
删除字符
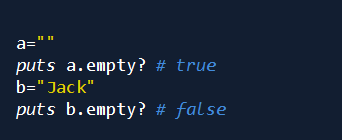
判断空
以replace来替换字符串中所有与pattern相匹配的部分

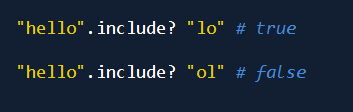
判断包含指定的字符串
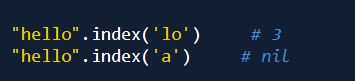
按照从左到右的顺序搜索子字符串,并返回搜索到的子字符串的左侧位置. 若没有搜索到则返回nil
用replace来替换首次匹配pattern的部分

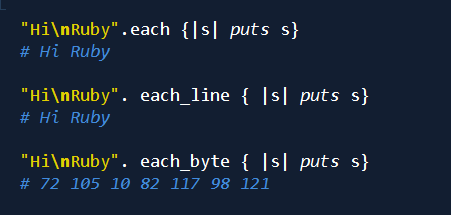
对字符串中的各行进行迭代操作,对字符串中的各个字节进行迭代操作
拆分字符串

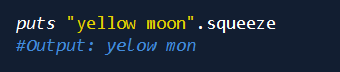
压缩重复的字符串
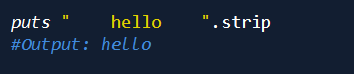
删除头部和尾部的所有空白字符。空白字符是指" "t"r"n"f"v"
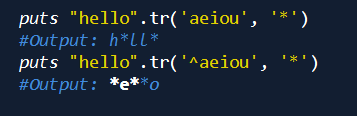
若字符串中包含search字符串中的字符时,就将其替换为replace字符串中相应的字符


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}