







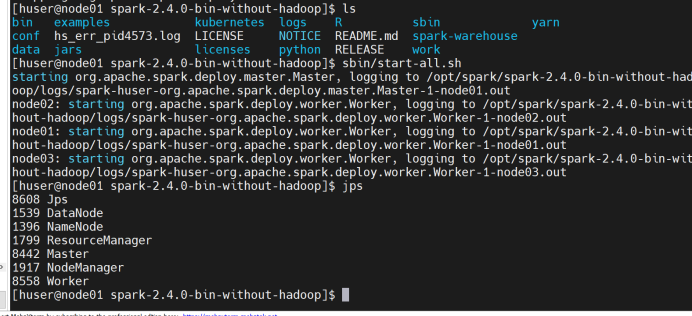
一.实验环境:
(1)Hadoop已安装

启动Hadoop集群进行测试
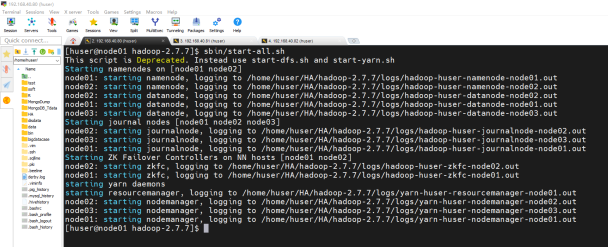
(2)Hbase已安装

启动Hbase集群进行测试
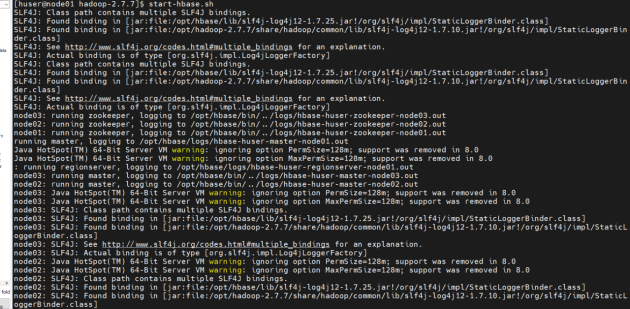
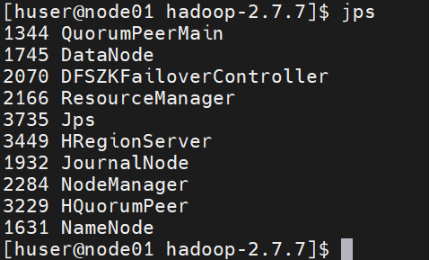
查看节点进程数
(3)Sqoop已安装

(4)MySQL已安装
(5)Hive已安装

(6)Spark已安装
二.解决方案及思路
(1)数据预处理
通过查看CoffeeChain.csv数据集介绍,并且实际考察数据集,发现其中并无脏数据,但是有冗余列Number of Records(销售记录),并且只有这一个冗余列,为了最大化效率,我直接在excel中手动删除该冗余列。
其读取路径为:HDFS路径
“/big_work/CoffeeChain.csv”。
(2)读取数据
读取CSV文件,并将其转换为DataFrame
val filePath = "/big_work/Coffee_Chain.csv"
val df = spark.read.options(
Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true")
).csv(filePath)
filePath:指定CSV文件的路径。
spark.read.options(…):读取CSV文件,指定选项包括:
- “inferSchema” -> “true”:自动推断数据类型。
- “delimiter” ->“,”:指定CSV文件的分隔符为逗号。
- “header” ->“true”:指定CSV文件第一行是列名。
- csv(filePath):读取CSV文件并返回一个DataFrame。
(3)创建临时视图
df.createOrReplaceTempView("coffee")
- createOrReplaceTempView("coffee"):将DataFrame df
注册为临时表,表名为"coffee",以便后续使用SQL语句进行查询。
(4)执行查询
1)查看咖啡销售量排名。
val b = spark.sql("select product,sum(Marketing) as number from coffee group by product order by number desc")
2)观察咖啡销售量的分布情况
查询咖啡销售量和state的关系:
val b = spark.sql("select market,state,sum(Marketing) as number from coffee group by state,market order by number desc")
查询咖啡销售量和market销售关系:
val b = spark.sql("select market,sum(Marketing) as number from coffee group by market order by number desc")
查询咖啡的平均利润和售价:
val b = spark.sql("select product,avg(`Coffee Sales`),avg(profit) as avg_profit from coffee group by product order by avg_profit desc")
查询咖啡的平均利润和售价和销售量的关系:
val b = spark.sql("select a.product,avg(`Coffee Sales`),avg(profit) as avg_profit , b.number from coffee as a, (select product,sum(Marketing) as number from coffee group by product) as b where a.product == b.product group by a.product,b.number order by b.number desc ")
查询咖啡的平均利润、销售量与其他成本的关系:
val b = spark.sql("select a.product, avg(profit) as avg_profit , b.number , avg(a.`Total Expenses`) as other_cost from coffee as a, (select product,sum(Marketing) as number from coffee group by product) as b where a.product == b.product group by a.product,b.number order by b.number desc ")
查询咖啡属性与平均售价、平均利润、销售量与其他成本的关系:
val b = spark.sql("select a.type,avg(a.`Coffee Sales`) as avg_sales, avg(profit) as avg_profit , sum(b.number) as total_sales , avg(a.`Total Expenses`) as other_cost from coffee as a, (select product,sum(Marketing) as number from coffee group by product) as b where a.product == b.product group by a.type order by total_sales desc ")
查询市场规模、市场地域与销售量的关系:
val b = spark.sql("select Market,`Market Size`, sum(`Coffee Sales`) as total_sales from coffee group by Market,`Market Size` order by total_sales desc ")
(5)结果保存
1)查看咖啡销售量排名。
b.write.option("header",true).csv("/big_work/Coffee/sell_num.csv")
2)观察咖啡销售量的分布情况
查询咖啡销售量和state的关系:
b.write.option("header",true).csv("/big_work/Coffee/state_sell_num.csv")
查询咖啡销售量和market销售关系:
b.write.option("header",true).csv("/big_work/Coffee/market_sell_num.csv")
查询咖啡的平均利润和售价:
b.write.option("header",true).csv("/big_work/Coffee/coffee_avg_sell_price_and_profit.csv")
查询咖啡的平均利润和售价和销售量的关系:
b.write.option("header",true).csv("/big_work/Coffee/coffee_avg_price_profit_relation_sell_num.csv")
查询咖啡的平均利润、销售量与其他成本的关系:
b.write.option("header",true).csv("/big_work/Coffee/coffee_relation_price_ _sellnum_othercost.csv")
查询咖啡属性与平均售价、平均利润、销售量与其他成本的关系:
b.write.option("header",true).csv("/big_work/Coffee/coffee_relation_type_price_ _sellnum_profit_othercost.csv")
查询市场规模、市场地域与销售量的关系:
b.write.option("header",true).csv("/big_work/Coffee/coffee_relation_market_marketsize_total_sales.csv")
(6)数据可视化
数据可视化采用的是Python的Flask框架和Echarts结合,Flask框架内置的jinja语言可以定时向主节点的MySQL服务发送请求来获取最新数据。因此Flask和Echarts结合可以满足数据实时更新的需求。
1)网址路由部分
@app.route('/big_index')
def big_index():
sum_Selling_Profit=Utial.get_sum_Selling_Profit_data()
# print(sum_Selling_Profit)
selling_TOP10=Utial.get_sellingTOP10_data()
# print(selling_TOP10)
daily_new_KF_cases=Utial.get_daily_new_KF_data()
# print(daily_new_KF_cases)
daily_new_profit=Utial.get_daily_new_profit_data()
# print(daily_new_profit)
profit_rate=Utial.get_profit_rate_data()
# print(profit_rate)
get_profit_TOP5_data=Utial.get_profit_TOP5_data()
# print(get_profit_TOP5_data)
Inventory_no5=Utial.get_Inventory_no5_data()
# print(Inventory_no5)
county_Selling=Utial.get_county_Selling_data()
# print(county_Selling)
return render_template('big_index.html',
sum_Selling_Profit=sum_Selling_Profit,
selling_TOP10=selling_TOP10,
daily_new_KF_cases=daily_new_KF_cases,
daily_new_profit=daily_new_profit,
profit_rate=profit_rate,
get_profit_TOP5_data=get_profit_TOP5_data,
Inventory_no5=Inventory_no5,
county_Selling=county_Selling
)
2)数据处理部分
def get_selling_data():
datalist = []
# 1、连接数据库
conn = pymysql.connect(host="192.168.40.80", port=3306, user='hive', password="hive", charset='utf8',db='Coffee')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 2、发送指令
sql = '''SELECT CoffeeChain.State AS State,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales,SUM(CoffeeChain.Marketing) AS Marketing
FROM CoffeeChain
GROUP BY CoffeeChain.State
ORDER BY Marketing DESC;
'''
cursor.execute(sql)
data = cursor.fetchall()
for item in data:
datalist.append(item)
# 3、关闭
cursor.close()
conn.close()
# print(datalist)
return datalist
3)Jinja处理部分
{% for foo in county_Selling %}
{name: '{{ foo.State }}', value:{{ foo.CoffeeSales }} },
{% endfor %}
4)Echars图表部分
<script>
var myChart=echarts.init(document.querySelector
('.column .pie2 .chart'));
var option = {
color: ['#006cff', '#60cda0', '#ed8884', '#ff9f7f', '#0096ff', '#9fe6b8', '#32c5e9', '#1d9dff'],
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c} ({d}%)'
},
legend: {
// 距离底部为0%
bottom: "0%",
// 小图标的宽度和高度
itemWidth: 10,
itemHeight: 10,
// 修改图例组件的文字为 12px
textStyle: {
color: "rgba(255,255,255,.5)",
fontSize: "12"
}
},
series: [
{
name: '地区分布',
type: 'pie',
// 饼形图大小
radius: ["10%", "60%"],
// 饼形图位置
center: ['50%', '40%'],
roseType: 'radius',
// 图形的文字标签 修改文字大小
label:{
fontsize:10
},
// 链接和图形和文字的线条
labelLine: {
// length修改链接图形的线条
length:6,
// length2修改不连接图形的线条
length2: 8
},
itemStyle: {
borderRadius: 5
},
data: [
{% for foo in Inventory_no5 %}
{ value: {{ foo.Inventory }}, name: '{{ foo.State }}' },
{% endfor %}
]
}
]
};
myChart.setOption(option);
// 4、让图表跟随屏幕自动地去适应
window.addEventListener('resize',function (){
myChart.resize();
})
</script>
5)SQL数据分析部分
-- 1、美国每个州每日的累计销售量——>双柱状图
SELECT DATE(CoffeeChain.Ddate) AS date,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales,SUM(CoffeeChain.Marketing) AS Marketing
FROM CoffeeChain
GROUP BY CoffeeChain.Ddate
ORDER BY date ASC;
SELECT CoffeeChain.State AS State,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales,SUM(CoffeeChain.Marketing) AS Marketing
FROM CoffeeChain
GROUP BY CoffeeChain.State
ORDER BY Marketing DESC;
-- 2、美国每日的咖啡新增销售量
SELECT t.date,(CoffeeSales1-CoffeeSales2) AS daily_Sales
FROM(
SELECT a.date,a.CoffeeSales CoffeeSales1,b.CoffeeSales CoffeeSales2
FROM (SELECT DATE(CoffeeChain.Ddate) AS date,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales
FROM CoffeeChain
GROUP BY CoffeeChain.Ddate
ORDER BY Ddate ASC) a JOIN
(SELECT DATE(CoffeeChain.Ddate) AS date,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales
FROM CoffeeChain
GROUP BY CoffeeChain.Ddate
ORDER BY Ddate ASC) b ON a.date=b.date+1
) t
ORDER BY t.date ASC;
-- 3、美国每日的新增咖啡盈利
SELECT t.date,(Profit1-Profit2) AS daily_Profit
FROM(
SELECT a.date,a.Profit Profit1,b.Profit Profit2
FROM (SELECT DATE(CoffeeChain.Ddate) AS date,SUM(CoffeeChain.Profit) AS Profit
FROM CoffeeChain
GROUP BY CoffeeChain.Ddate
ORDER BY Ddate ASC) a JOIN
(SELECT DATE(CoffeeChain.Ddate) AS date,SUM(CoffeeChain.Profit) AS Profit
FROM CoffeeChain
GROUP BY CoffeeChain.Ddate
ORDER BY Ddate ASC) b ON a.date=b.date+1
) t
ORDER BY t.date ASC;
-- 4、美国累计销售量排前10的州
SELECT disease_action.county,SUM(cases) AS cases
FROM disease_action
GROUP BY disease_action.county
ORDER BY SUM(cases) DESC LIMIT 10;
SELECT CoffeeChain.State AS State,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales,SUM(CoffeeChain.Marketing) AS Marketing
FROM CoffeeChain
GROUP BY CoffeeChain.State
ORDER BY CoffeeSales DESC LIMIT 10;
-- 5、美国累计销售咖啡量前10的州
SELECT CoffeeChain.State AS State,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales
FROM CoffeeChain
GROUP BY CoffeeChain.State
ORDER BY CoffeeSales DESC LIMIT 10;
-- 6、美国累计获得利润前5的州
SELECT CoffeeChain.State AS State,SUM(CoffeeChain.Profit) AS Profit
FROM CoffeeChain
GROUP BY CoffeeChain.State
ORDER BY Profit DESC LIMIT 5;
-- 7、美国库存剩余最多的前5的州
SELECT CoffeeChain.State AS State,SUM(CoffeeChain.Inventory) AS Inventory
FROM CoffeeChain
GROUP BY CoffeeChain.State
ORDER BY Inventory DESC LIMIT 5;
-- 8、美国累计实际销售量与累计实际盈利
SELECT SUM(CoffeeChain.CoffeeSales) AS CoffeeSales,SUM(CoffeeChain.Profit) AS Profit
FROM CoffeeChain;
-- 9、该咖啡店的盈利率
SELECT ROUND((SUM(CoffeeChain.Profit)/SUM(CoffeeChain.Cogs+CoffeeChain.TotalExpenses)),3) AS Moneyrate,ROUND((SUM(CoffeeChain.Profit)/SUM(CoffeeChain.CoffeeSales)),3) AS sellingrate
FROM CoffeeChain;
-- 10、咖啡连锁店每个州的销售量
SELECT CoffeeChain.State AS State,SUM(CoffeeChain.CoffeeSales) AS CoffeeSales
FROM CoffeeChain
GROUP BY CoffeeChain.State;
SELECT CoffeeChain.State
FROM CoffeeChain;
三.大作业实现流程
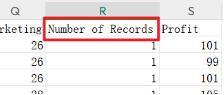
(1)数据预处理
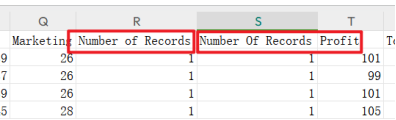
手动删除一列Number of Records
(2)数据分析
1)查看咖啡销售量排名。
创建临时表格用于SQL查询
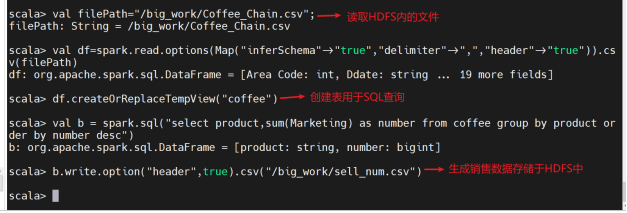
查看生成的数据是否成功存于HDFS内
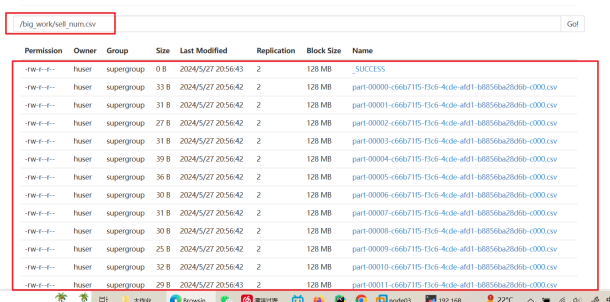
查看生成的表格数据
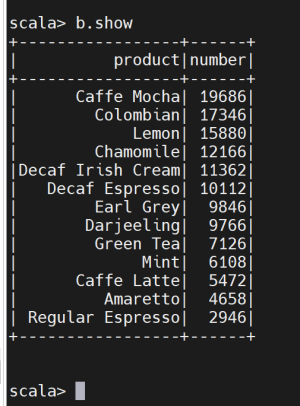
通过排名确定销售量高的咖啡品种,决策者可以重点关注高销售量产品,优化供应链,确保库存充足;对于销售量低的品种,可以考虑调整营销策略或逐步淘汰。
2)观察咖啡销售量的分布情况
1、查询咖啡销售量和state的关系:
创建临时表格用于SQL查询
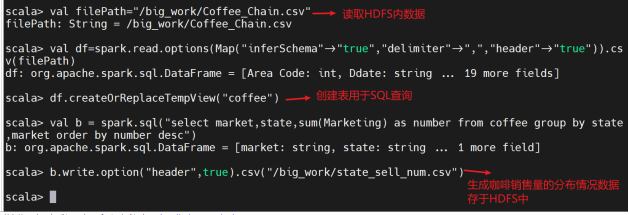
查看生成的数据是否成功存于HDFS内
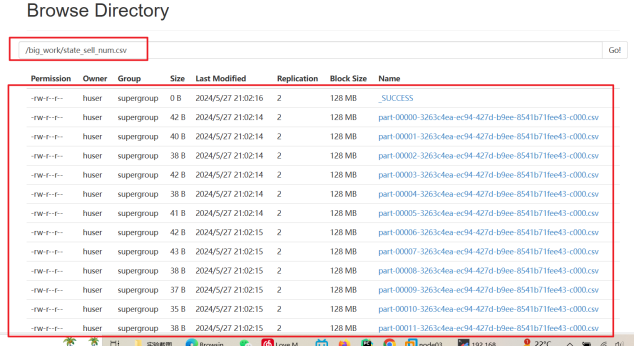
查看生成的表格数据
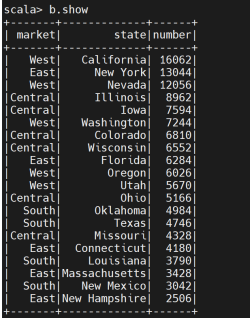
分析不同州的销售数据,决策者可以发现区域差异,并采取有针对性的区域营销策略。例如,在销售量较低的州增加广告投放或开展促销活动,在销售量较高的州维持现有策略或进一步增强供应链。
2、查询咖啡销售量和market销售关系:
创建临时表格用于SQL查询
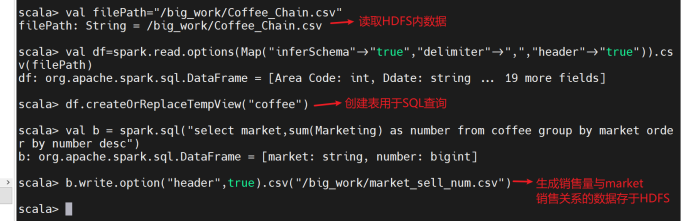
查看生成的数据是否成功存于HDFS内
查看生成的表格数据
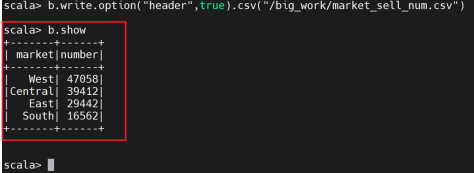
通过分析不同市场的销售情况,可以识别出潜力市场和饱和市场。在潜力市场加大市场投入,提高品牌知名度;在饱和市场维持或优化现有市场策略。
3、查询咖啡的平均利润和售价:
创建临时表格用于SQL查询
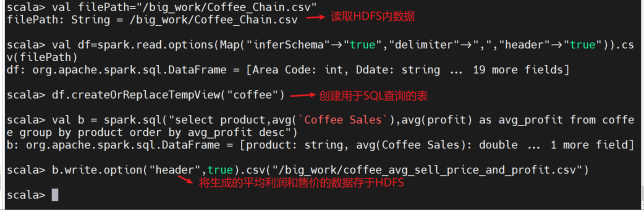
查看生成的数据是否成功存于HDFS内
查看生成的表格数据
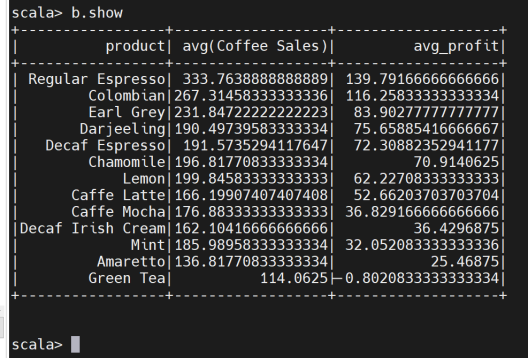
计算平均利润和售价的关系,有助于决策者确定最佳定价策略。如果售价过低导致利润偏低,可以考虑适当提价;如果售价过高影响销售量,则应考虑降价促销以提升销量。
4、查询咖啡的平均利润和售价和销售量的关系:
创建临时表格用于SQL查询
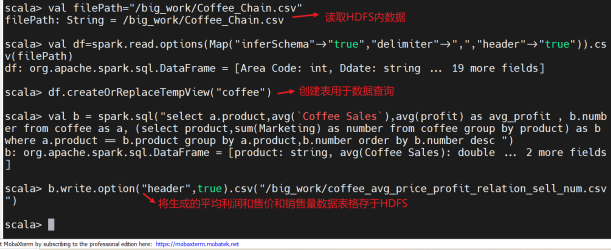
查看生成的数据是否成功存于HDFS内
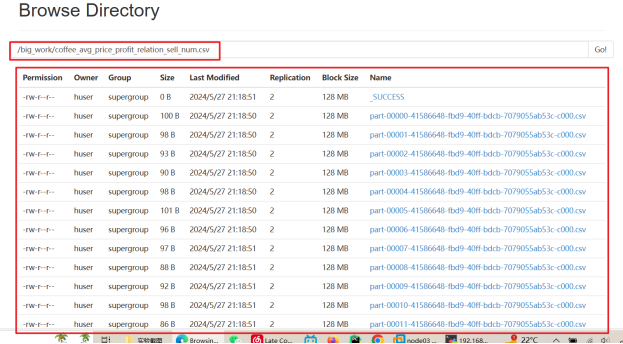
查看生成的表格数据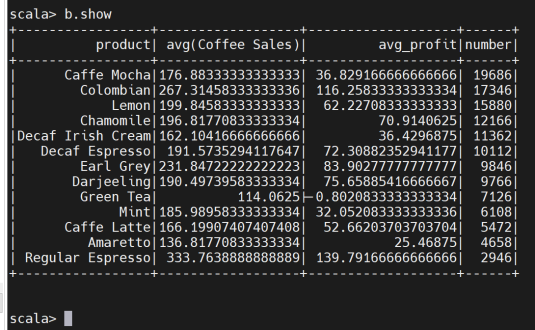
分析利润、售价与销售量的关系,有助于找出利润最大化的定价策略。决策者可以根据数据调整售价,以在保证利润的前提下,最大化销售量。
5、查询咖啡的平均利润、销售量与其他成本的关系:
创建临时表格用于SQL查询
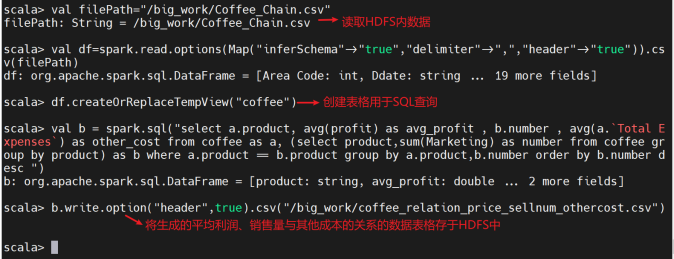
查看生成的数据是否成功存于HDFS内
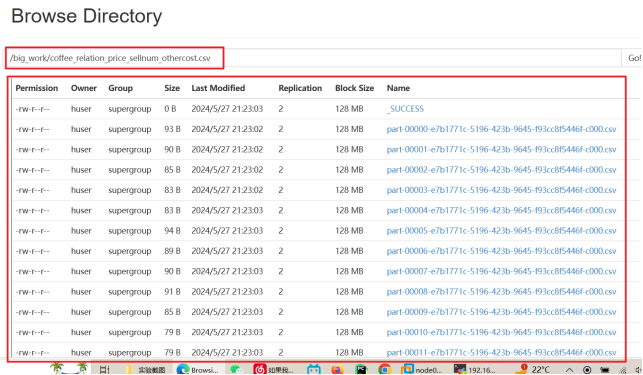
查看生成的表格数据
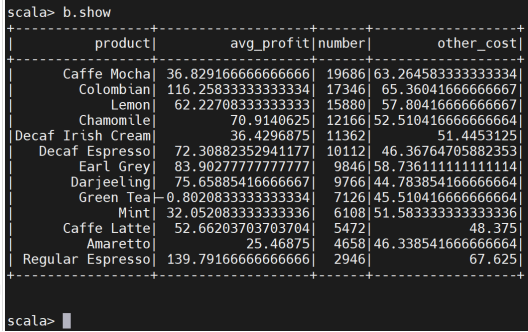
了解平均利润、销售量与成本的关系,决策者可以识别出高成本低利润的产品,优化成本结构或重新评估产品线,以提高整体盈利能力。
6、查询咖啡属性与平均售价、平均利润、销售量与其他成本的关系:
创建临时表格用于SQL查询
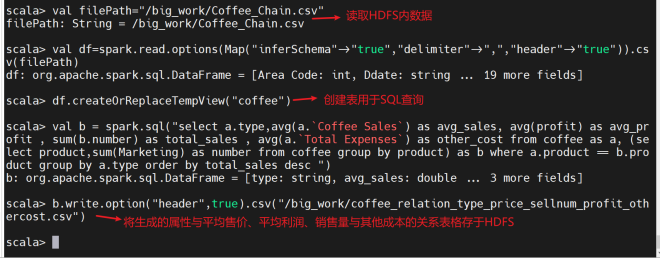
查看生成的数据是否成功存于HDFS内
查看生成的表格数据
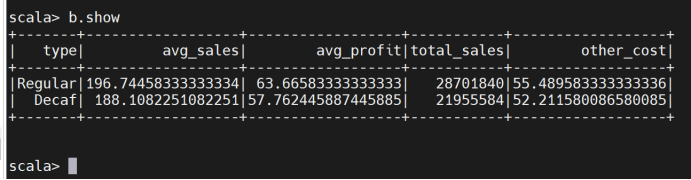
通过分析咖啡的属性(如品牌、口味、包装等)与各项财务指标的关系,决策者可以优化产品组合,推出更受市场欢迎的产品,同时控制成本,提高整体利润。
7、查询市场规模、市场地域与销售量的关系:
创建临时表格用于SQL查询
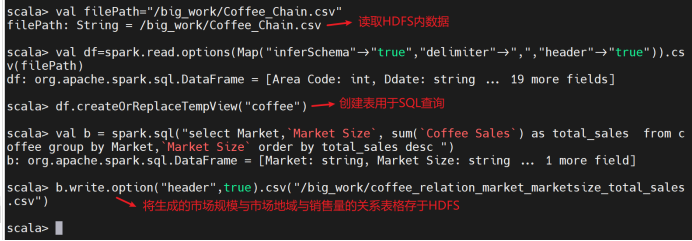
查看生成的数据是否成功存于HDFS内

查看生成的表格数据
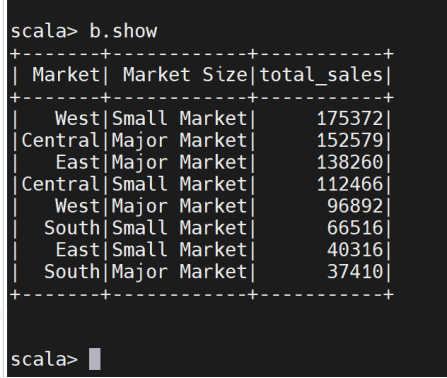
分析市场规模和地域对销售量的影响,有助于决策者制定扩展策略。在市场规模大的地区投入更多资源,扩大市场份额;在市场规模小的地区,探索新的增长机会或优化资源配置。
(3)数据可视化
数据可视化采用的是Python的Flask框架和Echarts结合,Flask框架内置的jinja语言可以定时向主节点的MySQL服务发送请求来获取最新数据。因此Flask和Echarts结合可以满足数据实时更新的需求。
数据可视化前提准备
1)数据预处理
去除CSV的标题行
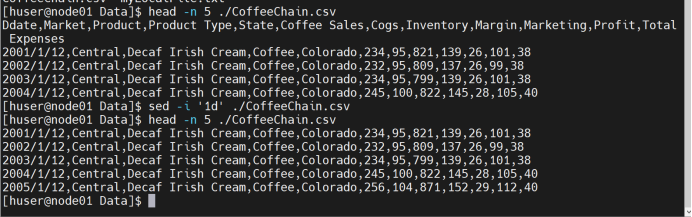
编写Coffee.sh预处理文件
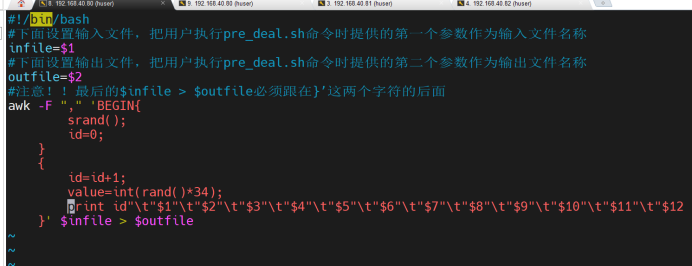
运行Shell文件进行数据预处理
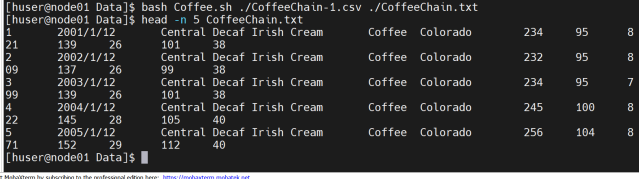
上传预处理后的数据文件至HDFS
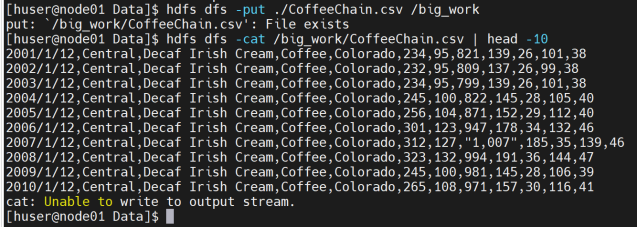
2)Hive数据准备
创建Coffee数据库
创建CoffeeChain表并从HDFS导入数据

查看数据是否导入成功
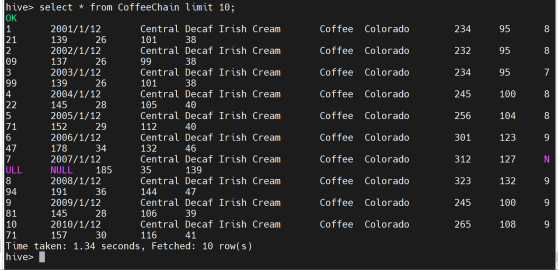
3)Sqoop到数据至MySQL
Mysql中建立Coffee数据库
MySQL中建CoffeeChain表

Sqoop将数据从Hive导入MySQL
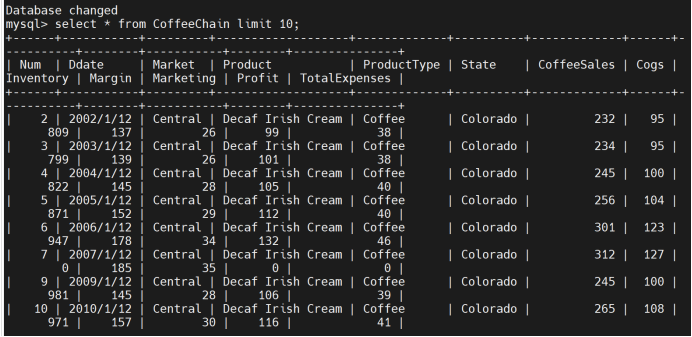
查看MySQL表格是否导入成功
数据可视化图表展示
1)每州累计咖啡销售量-柱状图
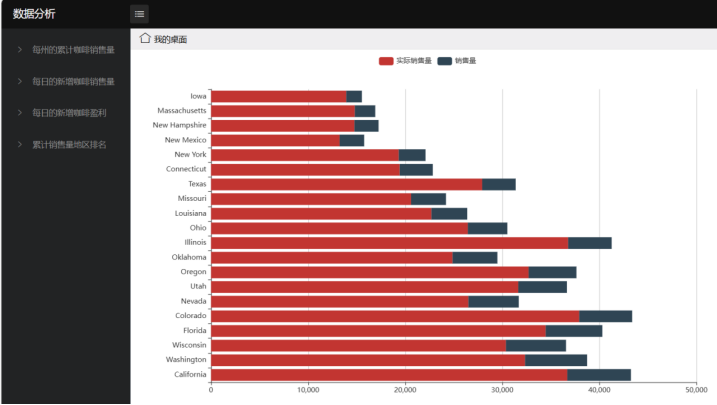
由此可以发现,比较有钱的城市(加利福尼亚和纽约)最喜欢喝咖啡。
2)每日的新增咖啡销售量-折线图
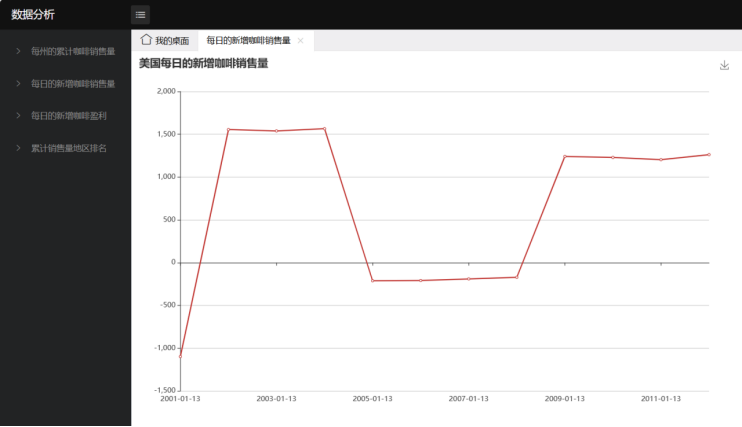
由此可以发现咖啡店的销售量的增减趋势是不确定,应与其它数据分析结合判断是什么原因导致。
3)每日的新增咖啡盈利-折线图
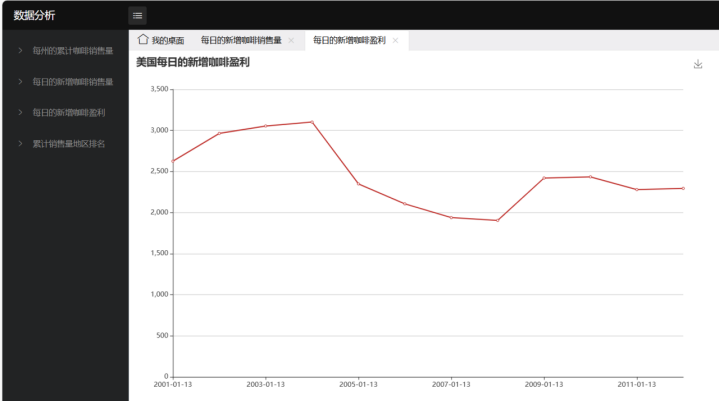
由已知的数据可知咖啡店的盈利利润大幅度上是呈现递减趋势,应结合其他数据分析判断是什么原因导致。
4)累计销售量地区排名-柱状图
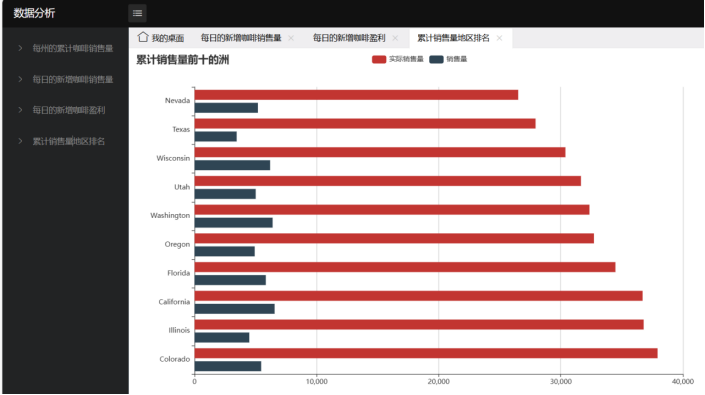
由此可以看出经济能力较好的州咖啡的销售与盈利能力都更强。
5)连锁咖啡店大屏展示
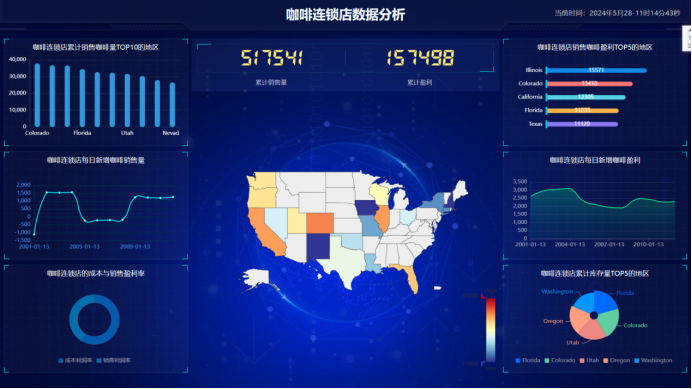
左一:咖啡连锁店累计销售咖啡量TOP10的地区-柱状图
由此可得比较有钱的城市(加利福尼亚和纽约等)销售咖啡能力更强。
左二:咖啡连锁店每日新增咖啡的销售量-折线图
由已知数据可得销售量的增减趋势是不一致的,结合右三图可得是由库存量库存过多导致,应将多余库存转换至重点销售地区来减少库存。
左三:咖啡连锁店的成本与销售盈利率-饼状图
由此可得成本盈利率要大于销售盈利率,表明企业在成本控制和生产效率方面表现较好,但在销售定价或市场竞争方面存在一定的压力,导致销售毛利率相对较低。可以结合同领域内销售较好的企业,调整定价。
右一:咖啡连锁店销售咖啡盈利TOP5的地区-条状图
由此可以的赚钱最多的五个州,可以根据覆盖范围再多设立1-2个咖啡店赚取更多的钱。
右二:咖啡连锁店每日新增咖啡盈利-折线图
由此可得大体上呈现下降趋势,结合左三可得应调整销售价格,增加毛利率。
右三:咖啡连锁店累计库存量TOP5的地区-饼状图
由此可得库存量最多的5个州,因此可降低这几个地区的库存提供,以减少亏损。
中间:各州的连锁咖啡店的销售额(由于该咖啡连锁店没有做到美国每个州都有连锁店。因此,只有部分有连锁店的店有数据)
由数据分析图可得,咖啡店覆盖范围仍有待提高,决策者可根据一个咖啡店的覆盖范围在未开售的州进行开设,以增加销售量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









