







4 管理区Zone
为了应对NUMA模型,系统把内存划分为多个Node已经可以解决不同cpu访问不同Node之间的速度差异问题,那为什么还将内存再次划分呢?原因是计算机组成的硬件中也存在访问内存的诸多限制,为了统一的处理这些限制问题,将内存通过地址大小所在的范围划分为Zone
- ISA总线的DMA(直接内存存储)处理器有一个严格的限制 : 他们只能对RAM的前16MB进行寻址
- 在具有大容量RAM的现代32位计算机中(最大4G), CPU不能直接访问所有的物理地址, 因为线性地址空间太小, 内核不可能直接映射所有物理内存到线性地址空间
每个管理区由一个struct zone_t 描述。zone_structs 由于跟踪诸如页面使用情况统计数,空闲区域信息和锁信息等。
Zone类型定义:
//kernel/include/linux/mmzone.h
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390, powerpc <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};| 名称 | 说明 |
| ZONE_DMA/ZONE_DMA32 | 标记DMA的内存域 |
| ZONE_NORMAL | 标记可直接映射到内存段的普通内存域 |
| ZONE_HIGHMEM | 标记了超出内核虚拟地址空间的物理内存段,该段内存不能被内核直接映射 |
| ZONE_MOVABLE | 引入ZONE_MOVABLE主要是为了优化内存迁移的场景,通过划分Movable以及Non-Movable的内存管理区,仅允许可迁移的页面在Movable的区域申请内存,从而保证当需要申请一块连续的大内存块可以通过迁移页面的方式实现(虚拟内存域, 在防止物理内存碎片的机制中会使用到该内存区域) |
| ZONE_DEVICE | 为支持热拔插而分配的Non-Volatile-Memory非易失性内存 (非易失性:一般指掉电后,数据是否保存) |
可以通过如下命令获得系统Zone信息
cat /proc/zoneinfo |grep Node
Node 0, zone DMA32
Node 0, zone Normal
Node 0, zone Movable
Node 1, zone DMA32
Node 1, zone Normal
Node 1, zone Movable
Node 2, zone DMA32
Node 2, zone Normal
Node 2, zone Movable
Node 3, zone DMA32
Node 3, zone Normal
Node 3, zone Movable
4.1 Zone Water(管理区极值)
- 当系统中的可用内存很少时,守护进程kswapd被唤醒开始释放页面,如果内存压力很大,进程会同步地释放内存,有时候这种情况被引用为direct-reclaim路径。
- 影响页面换出行为的参数与FreeBSD[McK96]和Solaris[MM01]中所用的参数类似。
每个管理区都有3个极值:page_low,page_min和page_high,这些极值用于跟踪一个管理区承受了多大的压力。
- pages_min 的页面数量在内存初始化阶段由函数free_area_init_core()计算出来,并且是基于页面的管理区大小的一个比率:计算初始化为ZoneSizeInPages/128,它所能区的最小值为20页,最大值可能是255页
每个极值在表示内存不足时的行为都互不相同:
- pages_low: 在空闲页面数达到 pages_low 时,伙伴分配器就会唤醒kswapd释放页面。
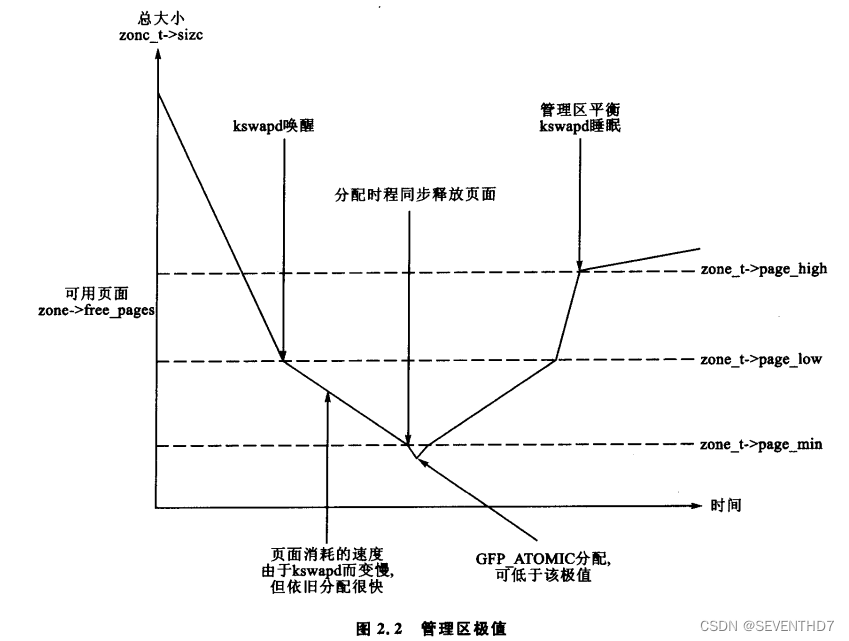
- pages_low的默认值是pages_min的两倍
当达到pages_min时,分配器会以同步方式启动kswapd(kswapd 和 分配器同步运行),有时候这种情况被引用为direct-reclaim路径。
pages_high:kswapd 被唤醒后开始释放页面,在page_high个页面被释放以前,是不会认为该管理区已经平衡,只有达到整个极值后,kswapd就再次睡眠
这个3个极值用于决定守护进程或页面换出进程释放页面的频繁程度。
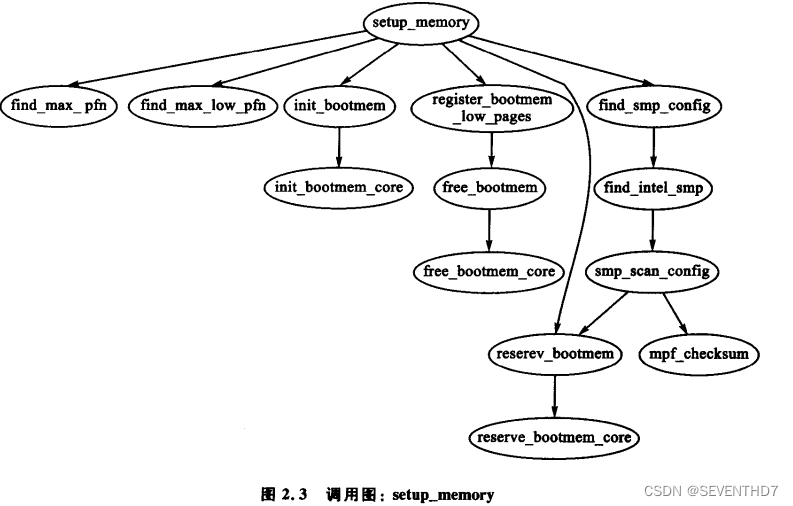
4.2 计算管理区大小
每个管理区大小是在setup_memory()中计算出来的,如图:
4.2.1 PFN 页帧号
PFN是在物理内存映射中以页为计量单位的一种偏移
计算管理区的大小:
函数:
find_max_pfn()
find_max_low_pfn()
量:
min_low_pfn:内核镜像加载到内存末尾位置(_end)后的第一个可用页帧
max_low_pfn:ZONE_NORMAL管理区尾帧,能被内核直接访问的低内存区最大页帧号
max_pfn:总共的物理页帧
4.2.3 管理区等待队列列表
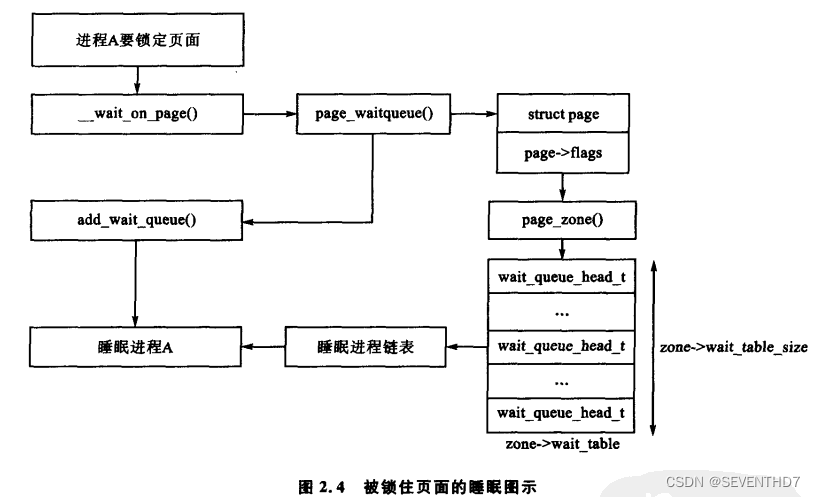
当页面需要进行I/O操作时,比如页面换入或者页面换出,I/O必须被锁住以防止访问的不一致.使用这些页面的进程必须在I/O能访问前,通过调用wait_on_page()被添加到一个等待队列中。当IO完成后,页面通过UnlockPage解锁,然后等待队列上的每个进程都被唤醒。
理论上,每个页面都应有一个等待队列,但是系统这样会花费大量的内存存放如此多分散的队列。
wait_table_size 等待队列hash表大小:calculated by wait table size() and is stored in zone t→wait table size
For smaller tables, the size of the table is the minimum power of 2 required to store NoPages / PAGES PER WAITQUEUE
number of queues
对于最小表, 表大小: 2的最小次幂 能存放 NoPages / PAGES PER WAITQUEUE 个队列
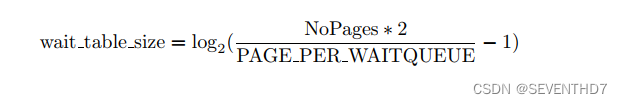
struct zone {
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
}
| 字段 | 描述 |
|---|---|
| wait_table | 待一个page释放的等待队列哈希表。它会被wait_on_page(),unlock_page()函数使用. 用哈希表,而不用一个等待队列的原因,防止进程长期等待资源 |
| wait_table_hash_nr_entries | 哈希表中的等待队列的数量 |
| wait_table_bits | 等待队列散列表数组大小, wait_table_size == (1 << wait_table_bits) |
4.2.3.1 惊群效应(tundering herd)
管理区中只有一个等待队列是有可能,但这意味着等待该管理区中的任何一个页面的所有进程在页面解锁后,都将被唤醒,这就会引起惊群效应
Linux的解决办法,用一个hash表管理等待队列,储存在zone_t->wait_table中,在发生哈希冲突时,虽然进程也有可能无缘无故被唤醒,但冲突不会再发生得如此频繁
2.3 管理区初始化
在kernel page table通过paging_init()函数完全建立起z来以后,zone被初始化。可预见的,不同的体系结构执行zone初始化任务肯定也是不一样的,但它们的目的却是相同的:确定什么参数需要传递给free_area_init()(对于UMA体系结构)或者free_area_init_node()(对于NUMA体系结构)。UMA,只需要zones_size 这个参数。完整的参数列表参照一下:
nid is the NodeID that is the logical identifier of the node whose zones are being
initialized
zone holes is an array containing the total size of memory holes in the zones
核心函数 free_area_init_core() 负责将相关的信息填充每个zone_t,并且负责为node分配mem_map 数组。关于ZONES里那些页是空闲的信息不是在这里决定的,这些信息在boot 内存分配器退出之前是不明的。
4.4 初始化 mem_map
mem_map 在系统启动期间是以两种方式中的种创建的。
- 对于NUMA系统,全局变量mem_map 被看作一个虚拟数组,从PAGE_OFFSET开始。free_area_init_node() 用于系统中的每个活动的node初始化,分配部分mem_map数组。
- UMA中,free_area_init()用contig_page_data 表示node,用全局mem_map数组表示当前node的局部(本地)mem_map。
调用关系见图2.5:
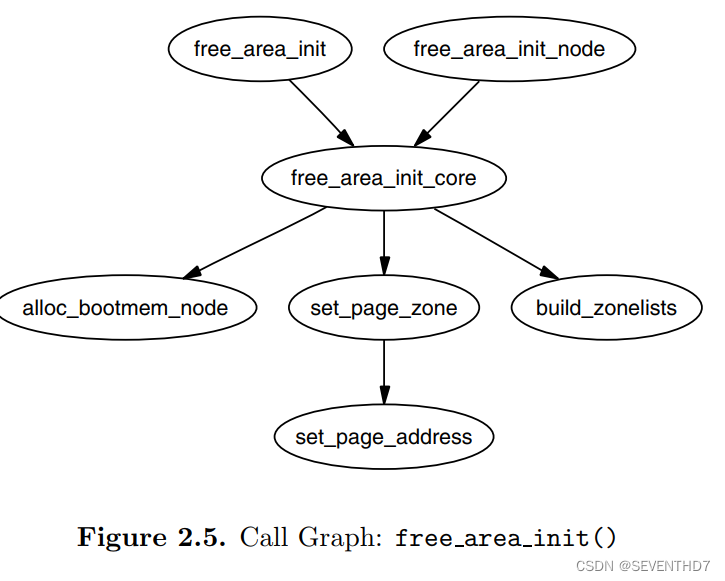
在node初始化中, 核心函数 free_area_init_core() 分配了一个局部 lmem_map 变量。boot内存分配器调用alloc_bootmem_node()分配好了这个数组变量。
- 对于UMA架构,lmem_map 以一种新的方式分配的内存作为全局mem_map,与NUMA对比,两种变量只有细微的差别。
NUMA 架构在自己的内存节点为lmem_map分配内存。全局变量mem_map不会明确地分配空间,而是被看作一个虚拟数组被放置在PAGE_OFFSET处。mem_map本地映射地址保存在pg_data_t->node_mem_map中,存在于虚拟的mem_map中的某处。对于node中的zone(管理区)来说,在虚拟的mem_map中zone的mem_map保存在zone_t->zone_mem_map.余下的代码把mem_map当作了真实的数组,是因为只有当中有效的区域被nodes使用。
struct zone {
/* Read-mostly fields *//* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM *//* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endifint initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];/* zone flags, see below */
unsigned long flags;/* Primarily protects free_area */
spinlock_t lock;/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endifbool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
| watermark | 每个zone在系统启动时,会计算出3个水位值,分别为WMARK_MIN, WMARK_LOW, WMARK_HIGH水位,这在页面分配器和kswapd页面回收中会用到。当该zone可用内存小于WMARK_LOW时,会触发oom回收内存。 |
| lowmem_reserve | zone中预留的内存 |
| zong_pgdat | 指向内存节点 |
| pageset | 用于维护Per-CPU上的一系列页面,以减少自旋锁的争用 |
| pageblock_flags | 页面迁移类型数据内存指针 |
| zone_start_pfn | zone中开始物理页面的页帧号 |
| managed_pages | zone中被伙伴系统管理的页面数量 |
| spanned_pages | zone包含的页面数量 |
| present_pages | zone里实际管理的页面数量,对一些体系结构来说,其值和spanned_pages相等 |
| free_area | 管理空间区域的数组,包含管理链表等 |
| lock | 并行访问时用于对zone保护的自旋锁 |
| vm_stat | zone计数 |















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









