






 文章讲述了作者在安装并启动Hadoop伪集群后,遇到无法从浏览器访问的问题。经过尝试关闭防火墙和检查端口占用,最终通过将文件端口号改为10000解决了问题。
文章讲述了作者在安装并启动Hadoop伪集群后,遇到无法从浏览器访问的问题。经过尝试关闭防火墙和检查端口占用,最终通过将文件端口号改为10000解决了问题。
根据网上的资料进行安装hadoop的伪集群
都安装成功,并且启动也成功了,如下图所示:
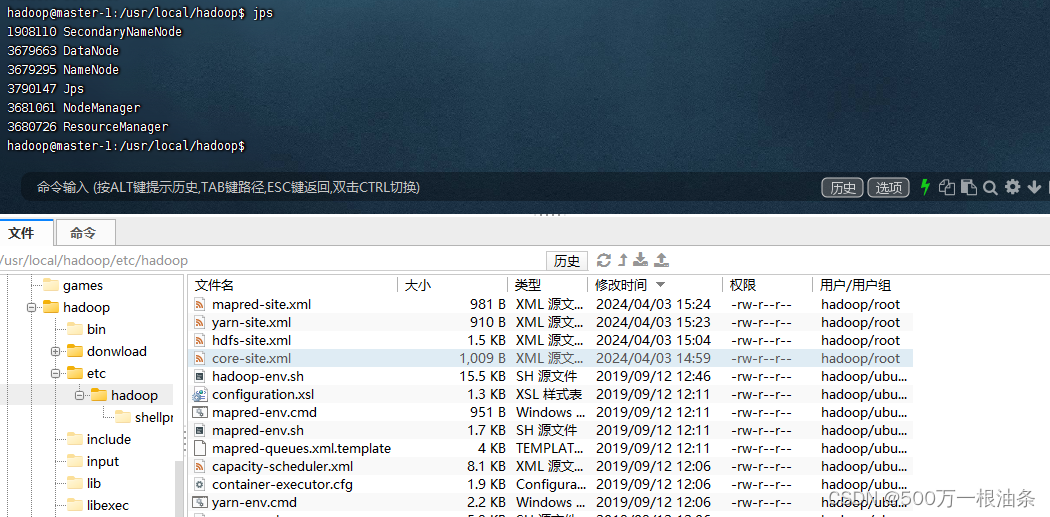
2、但是在浏览器上确是怎么也访问不了,
解决思路,
2.1、根据网上的一些文章处理解决是关闭防火墙,
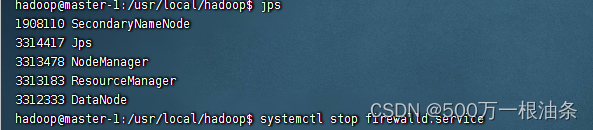
2.1.1、我根据操作步骤执行了,还是不行
2.2、开始怀疑是不是端口占用导致的
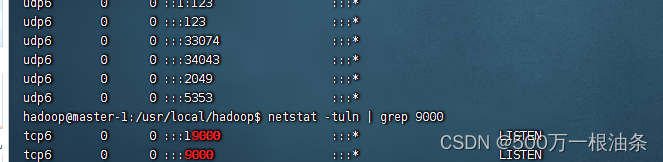

思考...........................................................处理...............................................................
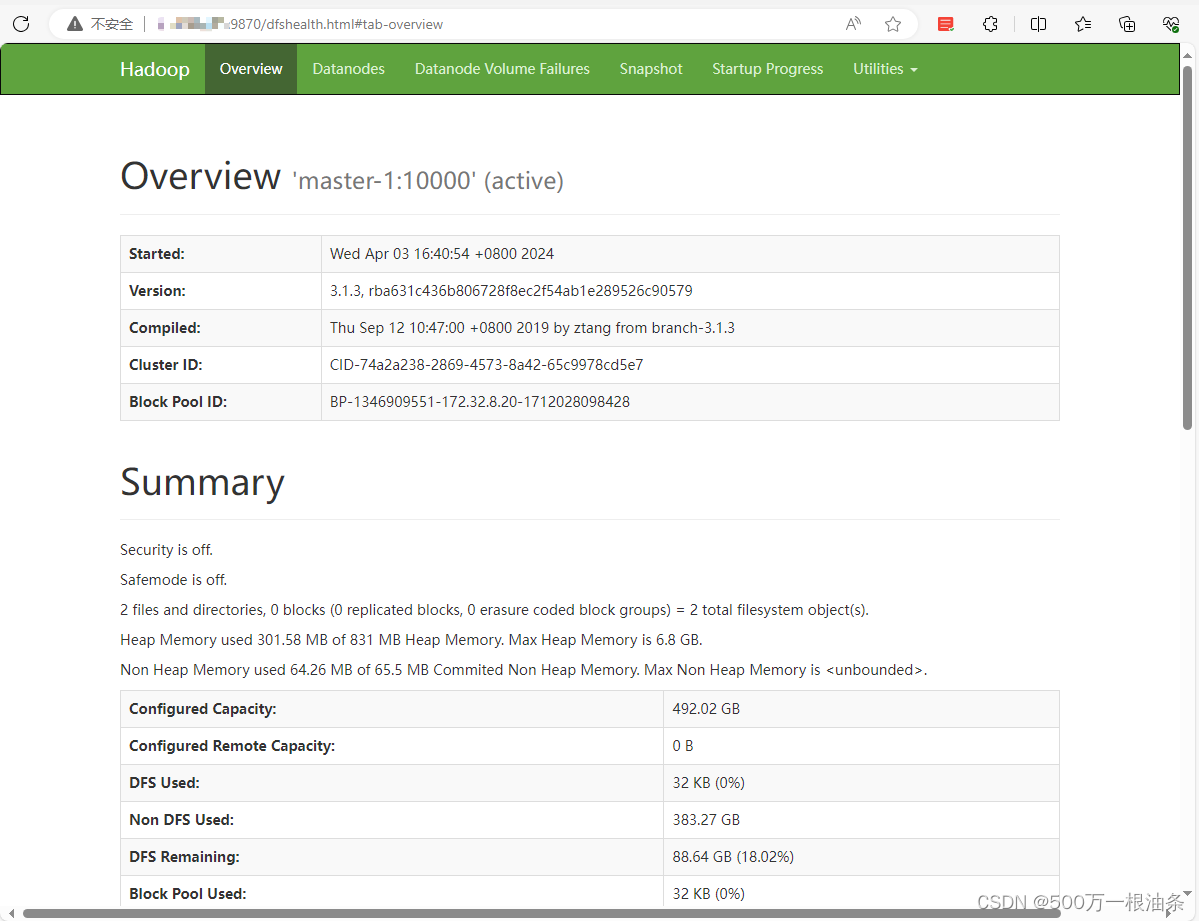
最后我把文件的端口号改成10000,
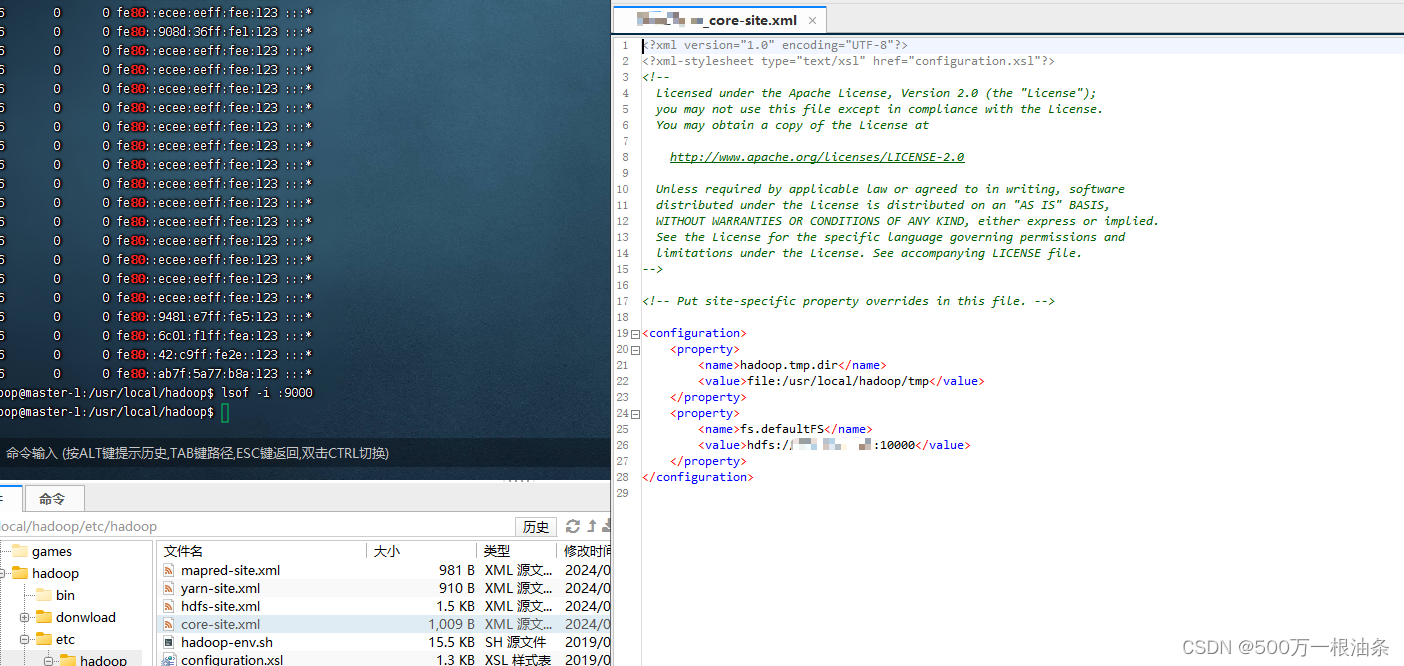
终于可以了:
















 8483
8483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









