









Python在设计上坚持了清晰划一的风格,这使得Python成为一门易读、易维护,并且被大量用户所欢迎的、用途广泛的语言。学习Python也有一段时间了,接下来做一下简单的爬虫程序,用来获取一些网页上的数据:
网页图:
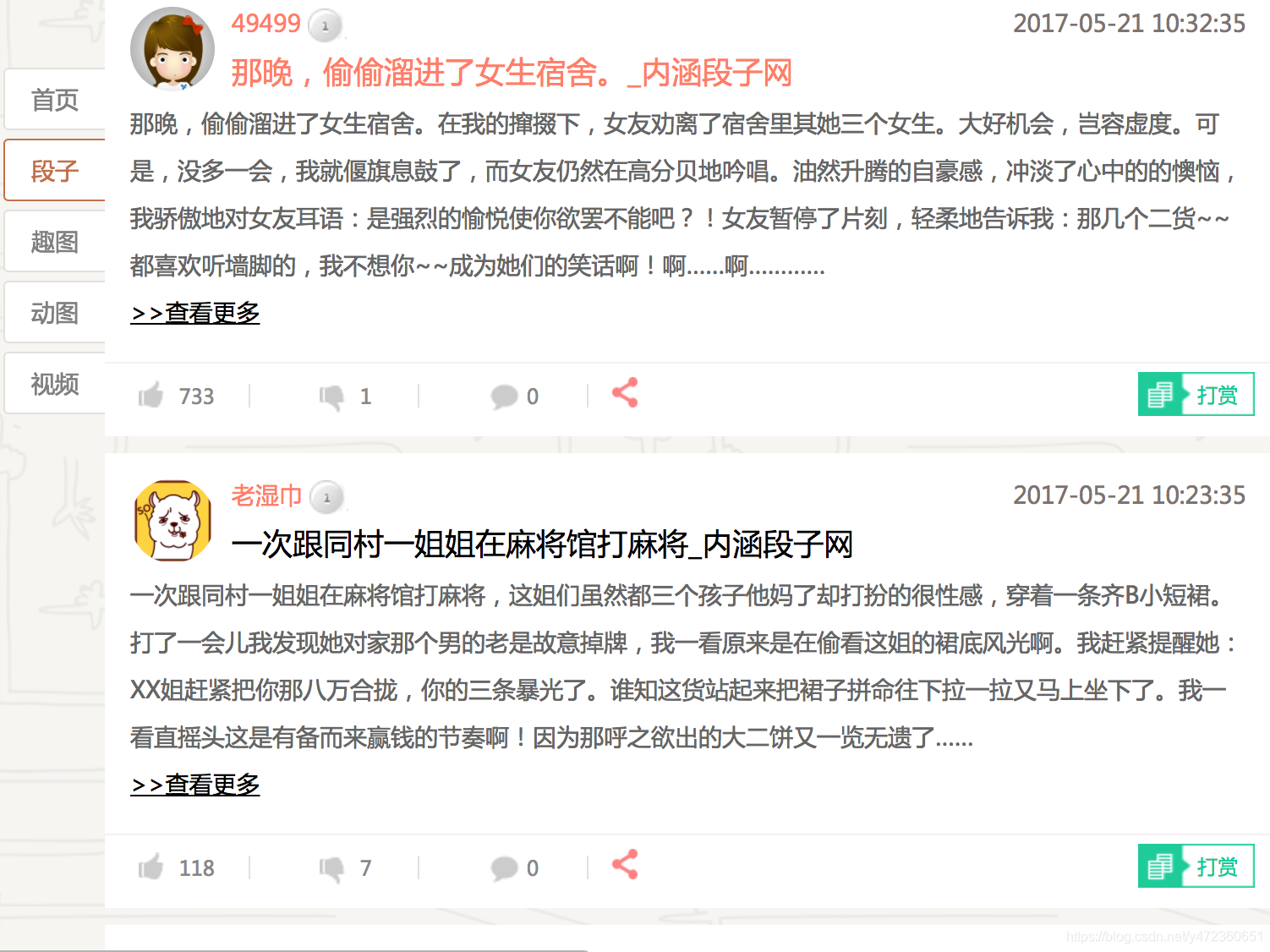
爬取的数据:

实现代码:
#coding=utf-8
import urllib.request
import re
class Reptile(object):
def start(self):
# 爬取页面总数
pageCount = 10
# 页码
i = 1
while i <= pageCount:
url = "http://www.neihan.net/text_%d.html"%i
send_headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"}
f = urllib.request.Request(url,headers=send_headers)
r = urllib.request.urlopen(f)
# 读取并转码
html = r.read().decode("utf-8")
print("开始爬取第%d页"%i)
self.doInfo(html)
print("爬取完毕")
i+=1
def doInfo(self, html):
str_ = str(html)
pattern = re.compile(r'<dd class="content"(.*?)(<br/>|</dd>)', re.S)
list = pattern.findall(str_)
for temp in list:
self.writeToFile(temp[0])
def writeToFile(self,content):
file = open("test.txt","a",encoding="utf-8")
file.write(content)
file.write("\n\n")
file.close()
if __name__ == "__main__":
reptile = Reptile()
reptile.start()
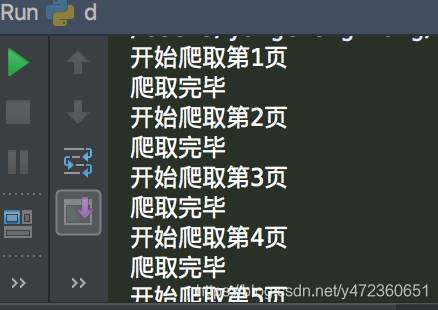
输出结果:














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









