









学习内存管理时一直有个疑问:内核虚拟地址空间中有一部分是线性映射用的,在内核初始化时会把物理内存映射到这个线性区域,既然映射已经建立完成了,那是不是就把物理内存全都占用了,用户空间是否就不能申请这些内存了?
后来宋宝华老师给出了解释:被映射和被占用完全是两码事。
下面就结合代码,谈谈我最这个解释的理解,以及自己碰到的疑问。
我最大的疑问是,在实际项目中,我看到的线性映射区并没有对所有的物理内存进行映射,而只有很小一部分进行了映射。这个结论是从ramdump中获取到的。
先列下项目中的虚拟地址空间布局:
[ 0.000000] Virtual kernel memory layout:
[ 0.000000] modules : 0xffffff8000000000 - 0xffffff8008000000 ( 128 MB)
[ 0.000000] vmalloc : 0xffffff8008000000 - 0xffffffbebfff0000 ( 250 GB)
[ 0.000000] .text : 0xffffff8008080000 - 0xffffff8009010000 ( 15936 KB)
[ 0.000000] .rodata : 0xffffff8009100000 - 0xffffff8009900000 ( 8192 KB)
[ 0.000000] .init : 0xffffff8009900000 - 0xffffff8009ac0000 ( 1792 KB)
[ 0.000000] .data : 0xffffff8009ac0000 - 0xffffff8009cfb200 ( 2285 KB)
[ 0.000000] .bss : 0xffffff8009cfb200 - 0xffffff800aa823a8 ( 13853 KB)
[ 0.000000] fixed : 0xffffffbefe7fb000 - 0xffffffbefec00000 ( 4116 KB)
[ 0.000000] PCI I/O : 0xffffffbefee00000 - 0xffffffbeffe00000 ( 16 MB)
[ 0.000000] vmemmap : 0xffffffbf00000000 - 0xffffffc000000000 ( 4 GB maximum)
[ 0.000000] 0xffffffbf00400000 - 0xffffffbf04000000 ( 60 MB actual)
[ 0.000000] memory : 0xffffffc010000000 - 0xffffffc100000000 ( 3840 MB)
我这是kernel 4.9版本,arm64的CPU,4GB RAM的配置:
DDRCS0.BIN 10000000–7fffffff
DDRCS1.BIN 80000000–ffffffff
所以,我的线性映射区虚拟地址范围是0xffffffc010000000 - 0xffffffc100000000
对应物理地址范围是0x10000000 - 0x100000000
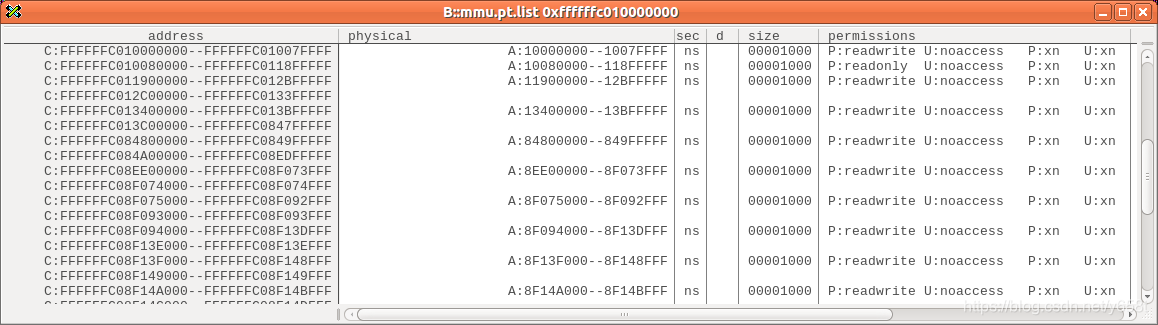 从图中可以看出,在线性映射区中只有小部分是有效映射,这是为什么?这就和之前的说法有矛盾:之前说已经全部做好映射了,可是这里却只有一小部分。
从图中可以看出,在线性映射区中只有小部分是有效映射,这是为什么?这就和之前的说法有矛盾:之前说已经全部做好映射了,可是这里却只有一小部分。
疑问抛出来,下面是我的一些分析。
通过查询页表的信息,来看看到底有没有做映射,没准是trace32的问题呢。
我选了两个地址,一个有映射,一个没有:
0xFFFFFFC011900000 --> 0x11900000
0xFFFFFFC012C00000 --> null
下面是简单的映射表的查找:
ffffff800aa86000 A swapper_pg_dir
1000000008=0x800
0100011008=0x460
100000000*8=0x800
d.dump 0xffffff800aa86000+0x800 -> 0xF23E7003 最后12bit清零,同时减去0x80000000得到0x723E7000
hexdump -C -s 0x723E7000+0x460 -n 8 DDRCS1.BIN -->0xf23e5003 最后12bit清零,同时减去0x80000000得到0x723e5000
hexdump -C -s 0x723e5000+0x800 -n 8 DDRCS1.BIN -->e80000 11900f13 ->0x11900000
这与trace32显示的结果是匹配上的,确实映射到了物理地址0x11900000
下面是0xFFFFFFC012C00000的映射过程
1000000008=0x800
0100101108=0x4B0
000000000*8=0x0
d.dump 0xffffff800aa86000+0x800 -> 0xF23E7003 最后12bit清零,同时减去0x80000000得到0x723E7000
hexdump -C -s 0x723E7000+0x4b0 -n 8 DDRCS1.BIN ->f23db003 最后12bit清零,同时减去0x80000000得到723db000
hexdump -C -s 0x723db000+0x0 -n 8 DDRCS1.BIN ->e80000 12c00f12 ->0x12c00000
貌似也映射到了预期的0x12c00000地址。
查了下armv8文档中关于MMU的介绍,发现这个最后的pte其实是无效的,因为它的最后一个bit是0
 从这里可以看到,若最后一个bit为0,则代表为Invalid。
从这里可以看到,若最后一个bit为0,则代表为Invalid。
查了下内核代码,确实有相关定义:
#define PTE_VALID (_AT(pteval_t, 1) << 0)
因此,我的结论是:映射已经执行完成了,因为相关的页表都是有效的,但是映射完成后做了特殊处理,使之无效了。
根据PTE_VALID这个线索查下去,发现在free page时会将其置为无效,在alloc page时会置为有效:
__free_pages
__free_pages_ok
free_pages_prepare
kernel_map_pages(page, 1 << order, 0);//此处的0代表无效
get_page_from_freelist
prep_new_page
post_alloc_hook
kernel_map_pages(page, 1 << order, 1);//此处的1代表有效
所以,我推测是在内核初始化阶段映射的工作确实做了,但是初始化完成,由memblock转到buddy system去管理内存时,会把memory中非reserved的内存释放,转给buddy,那里会调用free page,因此就会把没有分配的内存的pte置为无效。在后续申请内存时,只需要再置为有效就可以,不需要再做映射操作了。这就是我对自己疑问的解释。
在这个过程中,我注意到了一个配置:CONFIG_DEBUG_PAGEALLOC=y
我的项目中,配置为y。
看它的描述,和前面的分析基本一致:会把线性映射区未使用的空间unmap掉,在申请page时再完成map。
config DEBUG_PAGEALLOC
bool "Debug page memory allocations"
---help---
Unmap pages from the kernel linear mapping after free_pages().
Depending on runtime enablement, this results in a small or large
slowdown, but helps to find certain types of memory corruption.
For architectures which don't enable ARCH_SUPPORTS_DEBUG_PAGEALLOC,
fill the pages with poison patterns after free_pages() and verify
the patterns before alloc_pages(). Additionally,
this option cannot be enabled in combination with hibernation as
that would result in incorrect warnings of memory corruption after
a resume because free pages are not saved to the suspend image.
By default this option will have a small overhead, e.g. by not
allowing the kernel mapping to be backed by large pages on some
architectures. Even bigger overhead comes when the debugging is
enabled by DEBUG_PAGEALLOC_ENABLE_DEFAULT or the debug_pagealloc
command line parameter.
既然如此,把它关闭会怎样?
看DEBUG_PAGEALLOC_ENABLE_DEFAULT相关注释可知,这个功能可以动态关闭。不过我采用的还是直接关闭CONFIG_DEBUG_PAGEALLOC。之后获取到的ramdump是这样的。
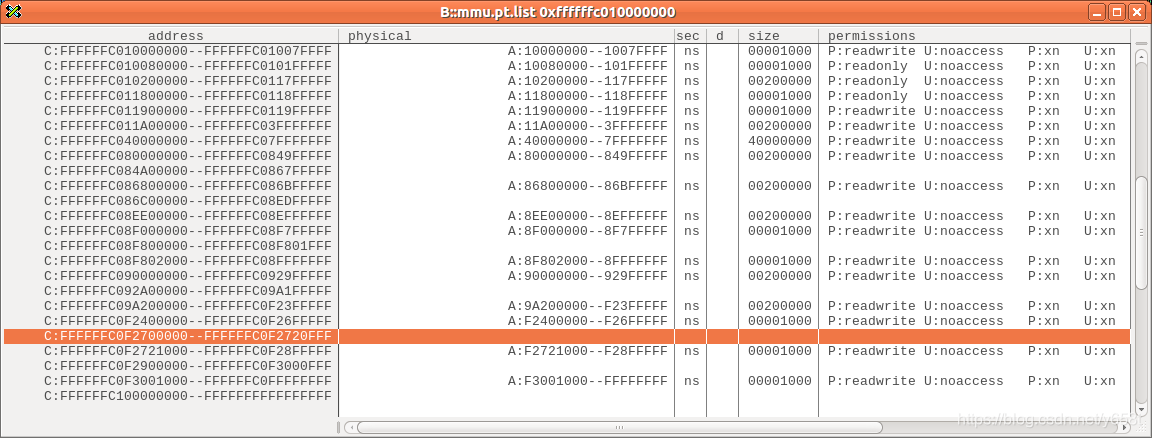 恩,这次好多了,但是还是有6块区域并没有映射。
恩,这次好多了,但是还是有6块区域并没有映射。
针对这个疑问,我只能解释一部分:其中有3块区域我可以解释清楚,另外3块就不知道是为什么了。
android:/sys/kernel/debug/memblock # cat memory
0: 0x0000000010000000..0x00000000849fffff
1: 0x0000000086800000..0x0000000086bfffff
2: 0x000000008ee00000..0x00000000929fffff
3: 0x000000009a200000..0x00000000ffffffff
从/sys/kernel/debug/memblock/memory文件可知,这个项目申请了3块预留区域,这些预留预期在map时是不会映射。
剩下那3块,我不知该如何解释。暂时遗留吧。
最后看看相关代码
///kernel/msm-4.9/arch/arm64/mm/mmu.c
void __init paging_init(void)
{
phys_addr_t pgd_phys = early_pgtable_alloc();
pgd_t *pgd = pgd_set_fixmap(pgd_phys);
// 这里完成kernel的重新映射,区别于之前开启MMU时__create_page_tables创建的section映射,这里更细了
map_kernel(pgd);
// 这里完成线性映射
map_mem(pgd);
// 以前一直没看懂这里到底想干啥,今天终于知道了。开启MMU时已经为kernel镜像创建过映射,那时使用的是位于内核bss段之后的空间来存储页表,我的配置是CONFIG_ARM64_VA_BITS=39,4K page,所以这里只有2个page空间,使用的是section map。那时也不区分代码段,数据段,反正能建立映射访问就可以了,现在就不一样了,memblock已经OK,dtb也访问完成,可以使用动态申请内存???,于是就要重新映射。映射包括把kernel的代码和数据映射到vmalloc区域,同时完成线性区域的映射。但是,做这些操作时不能动之前__create_page_tables创建的页表,否则代码可能就无法执行了。所以,函数一开始就通过fixmap申请了一个临时page作为内核页表的基地址,然后在这上面完成其它页表的建立,最后通过一个copy动作把内容copy到swapper_pg_dir中:当前的ttbr1保存的是swapper_pg_dir;由于pgd_phys的映射已经完成,所以使用pgd_phys,这样就可以随意操作swapper_pg_dir;然后把pgd_phys的内容copy到swapper_pg_dir中;然后还是使用swapper_pg_dir作为ttbr1的内容。如此一来,以前bss段之后的2个page,只有第一个还有用,后面那个就可以free了。
// ffffff800aa86000 A swapper_pg_dir
// ffffff800aa88000 A tramp_pg_dir
cpu_replace_ttbr1(__va(pgd_phys));
memcpy(swapper_pg_dir, pgd, PAGE_SIZE);
cpu_replace_ttbr1(lm_alias(swapper_pg_dir));
pgd_clear_fixmap();
memblock_free(pgd_phys, PAGE_SIZE);
memblock_free(__pa_symbol(swapper_pg_dir) + PAGE_SIZE,
SWAPPER_DIR_SIZE - PAGE_SIZE);
}
static void __init map_mem(pgd_t *pgd)
{
struct memblock_region *reg;
//从这个for循环看,reserved-memory节点下compatible = "removed-dma-pool",且有no-map的,是不会在memblock.memory中出现,因此也就不会被映射,至于下面的memblock_is_nomap,貌似都是true吧。要注意的是,这里并不关注是否在memblock.reserve中出现不影响,都会做映射,只是后续memblock交给buddy时,reserve中的会被保留,不会调用free page,因此其映射也会保留
/* map all the memory banks */
for_each_memblock(memory, reg) {
phys_addr_t start = reg->base;
phys_addr_t end = start + reg->size;
if (start >= end)
break;
if (memblock_is_nomap(reg))
continue;
__map_memblock(pgd, start, end);
}
}
在做线性映射时,虚拟地址是怎么获取的?因为我们已知的是物理地址空间。虚拟地址就是通过下面这个宏来计算的。
对于我的4G RAM配置而言,此处的PHYS_OFFSET为0,因此这个物理到虚拟的映射关系非常简单,就是物理地址加上PAGE_OFFSET,也就是0xffffffc000000000。
以前一直觉得奇怪,对于内核而言,在vmalloc区域和线性区域,都有虚拟地址空间指向kernel镜像所在的物理地址空间,那物理地址转换为虚拟地址岂不是应该有两种可能的结果。实际确实是,不过,这里的__phys_to_virt返回的只是线性区域的虚拟地址而已。还有一个宏__phys_to_kimg正是用来返回vmalloc区域的虚拟地址的,这个后面再仔细看看。
#define __phys_to_virt(x) ((unsigned long)((x) - PHYS_OFFSET) | PAGE_OFFSET)
#define PHYS_OFFSET ({ VM_BUG_ON(memstart_addr & 1); memstart_addr; })
#define __phys_to_kimg(x) ((unsigned long)((x) + kimage_voffset))















 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









