






原创文章,请勿转载!
仅供学习使用!需要源码联系博主(需要为知识付费)
一、说明
采集的数据字段:
电影名称、导演、上映日期、评论、评价、国家、电影类型
可视化图:
饼状图、柱状图二、主要部分代码
1.获取列表页的详情页id
url = await self.base_url_queue.get()
self.base_url_queue.task_done()
async with session.get(url, headers=self.random_ua(url)) as response:
text = await response.text()
tree = etree.HTML(text)
li_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li') # 获取到当前页的所有url长度
for li in range(1, len(li_list) + 1):
href = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{li}]/div/div[2]/div[1]/a/@href')[
0] # 获取详情页的url地址
await self.detail_url_queue.put(href)2.获取详情页数据
item['title'] = tree.xpath("//span[@property='v:itemreviewed']/text()")[0] # 电影名称
item['director'] = tree.xpath("//a[@rel='v:directedBy']/text()")[0] # 导演
item['date'] = '/'.join(tree.xpath("//span[@property='v:initialReleaseDate']/text()")) # 上映日期
item['comment-content'] = tree.xpath("//p[@class=' comment-content']/span[@class='short']/text()") # 评论
item['comment-count'] = tree.xpath("//span[@property='v:votes']/text()")[0] # 评价
item['country'] = tree.xpath('//span[text()="制片国家/地区:"]/following-sibling::text()[1]')[
0].strip() # 国家
item['movie-type'] = '/'.join(tree.xpath('//span[@property="v:genre"]/text()')) # 电影类型三、结果

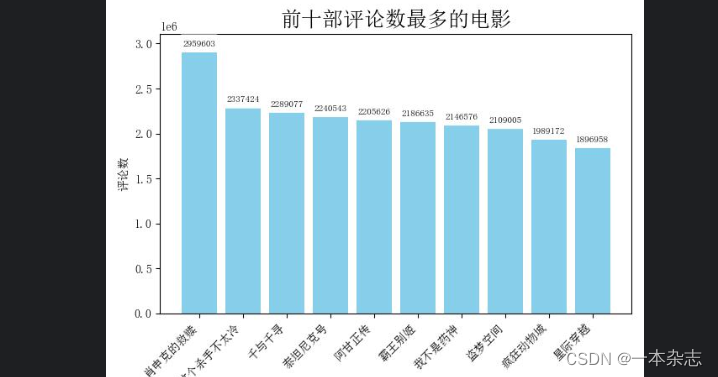
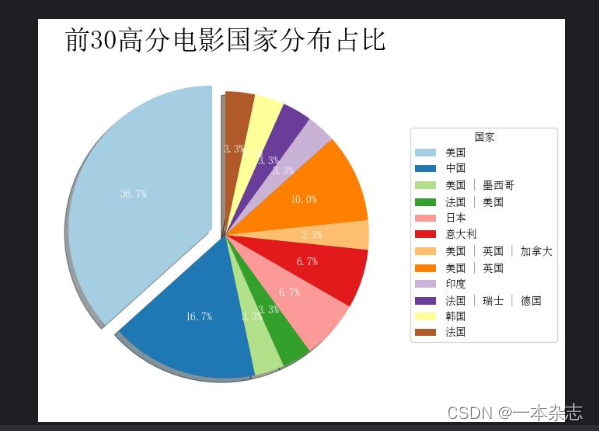
学习交流QQ:450297392















 5172
5172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









