







数据一致性
对于redis的数据一致性问题我们是有两种模式需要讨论的
读写模式:客户端删改数据时,同时对redis和数据库都进行相同操作并且要保证原子性。
这种模式又分为同步直写和异步写回,同步直写是客户端修改数据,修改redis同时修改数据库需要开启事务保证原子性。异步写回是客户端修改数据修改redis数据不同步修改数据库,等待redis数据淘汰之后刷脏页的方式写入数据库,这种情况有可能在redis意外宕机导致数据不一致。
所以在读写模式还是需要选择同步直写,保证了原子性我们也需要保证执行成功,所以我们可以加入消息队列,处理异常之后我们需要重试,重试多次后还失败在返回异常。
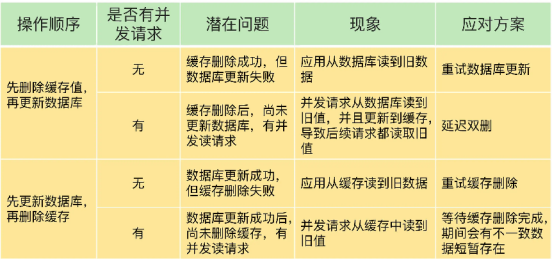
只读模式:客户端删改数据,直接删除redis数据,然后更新数据库,等待请求redis数据缺失后,再将数据库中的数据写入到Redis中。
只读模式会出现两种异常场景:
先删除缓存,在更新数据库
线程 A 删除缓存值后,还没有来得及更新数据库(比如说有网络延迟),线程 B 就开始读取数据了,那么这个时候,线程 B 会发现缓存缺失,就只能去数据库读取。
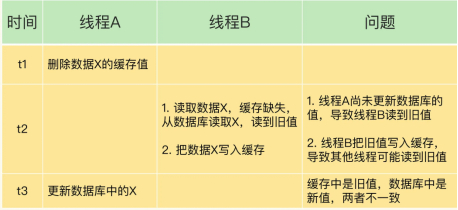
所以我们可以实行延迟双删方案:先删除缓存,在更新数据库,等待一段时间(保证B线程结束之后),再删除一次缓存。
先更新数据库,再删除缓存
线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,那么此时,线程 B 查询缓存时,发现缓存命中,就会直接从缓存中读取旧值。这种事在并发相对不高的情况,后面的线程就能取到对的值。

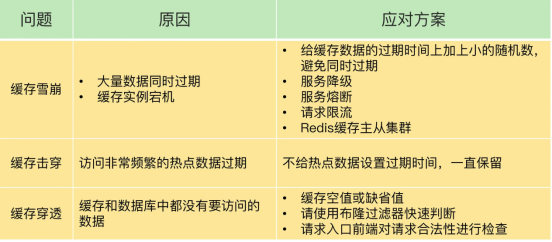
缓存雪崩、击穿、穿透
正对缓存穿透我们也有布隆过滤器:由一个初值都为0 的 bit 数组和 N 个哈希函数组成,可以用来快速判断某个数据是否存在。
布隆过滤器实际运行逻辑,当一个数据进来我们首先通过N个哈希函数进行处理,得到N个哈希值,然后每个哈希值都对bit数组进行取模,然后得到N个数,在对应的位置标记为1。等到下次查询的时候就对这个数组的对应位置取值,只要有一个为0,那么这个数据就是不存在的,不需要进行数据库查询。

数据值X,用3个哈希函数对X处理计算,然后对数组取模分别得到1、3、7,然后对这三个位置赋值。等待查询redis没有命中的时候就需要查询布隆过滤器,有一个位置为0,就不进行数据库查询。
解决方案:
(1)针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群;
(2)针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间;
(3)针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。















 1573
1573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









