






进程、系统性能
内核功能:进程管理、文件系统、网络功能、内存管理、驱动程序、安全功能等
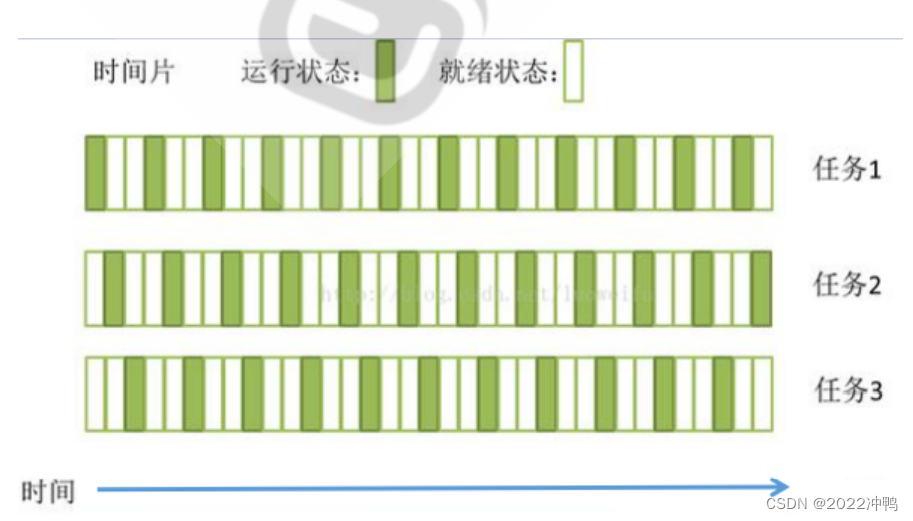
把CPU资源分成时间片,对任务进行调度
守护进程:随着计算机开机、关机而存在的进程
- 进程和内存管理
1.1、什么是进程
process: 运行中的程序的一个副本,是被载入内存的一个指令集合,是资源分配的单位
1)进程ID(Process ID,PID)号码被用来标记各个进程
2)UID、GID、和SELinux语境决定对文件系统的存取和访问权限
3)通常从执行进程的用户来继承
4)存在生命周期

进程创建:
init:第一个进程
进程:都由其父进程创建,父子关系,CoW:copy on write,子进程写数据之后,会单独分配一个进程编号
fork(), clone()
父进程与子进程使用同一个id编号,除非子进程状态发生改变
协程:它与开发块有关,在线程中一个独立的语句块,相互之间控制由程序完成
tips:如何查看某个进程在磁盘的位置?
ll /proc/PID/exe,以sshd为例

fd 文件描述符,系统会分配一个数字来表示打开的文件描述符
查看进程中的线程:
cat /proc/PID/status |grep -i threads
1.2、进程结构
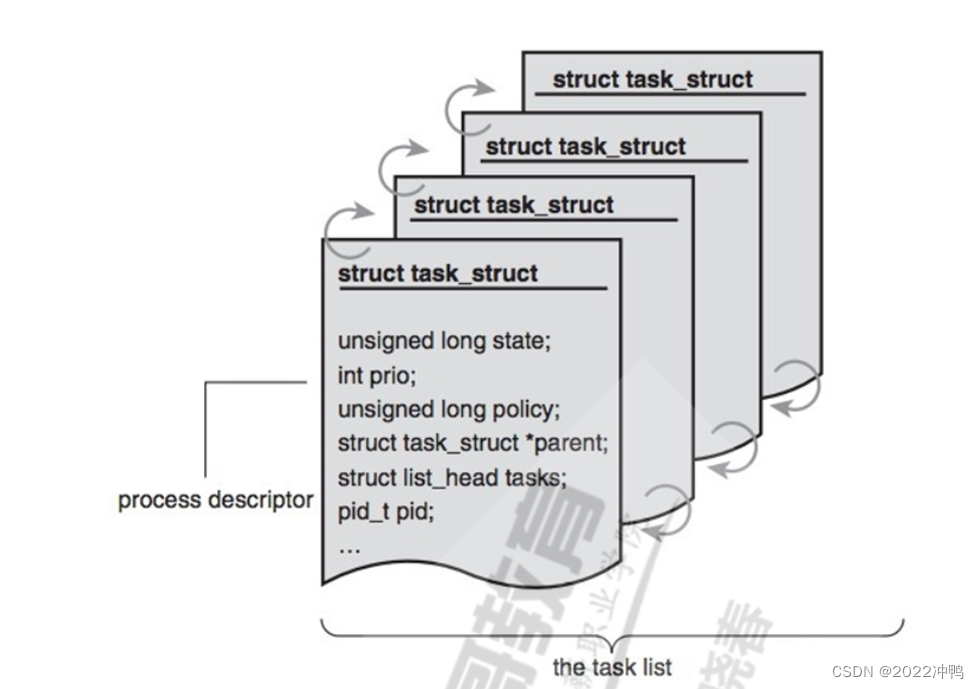
内核把进程存放在叫做任务队列(task list)的双向循环链表中
链表中的每一项都是类型为task_struct,称为进程控制块(Processing Control Block),PCB中包含
一个具体进程的所有信息
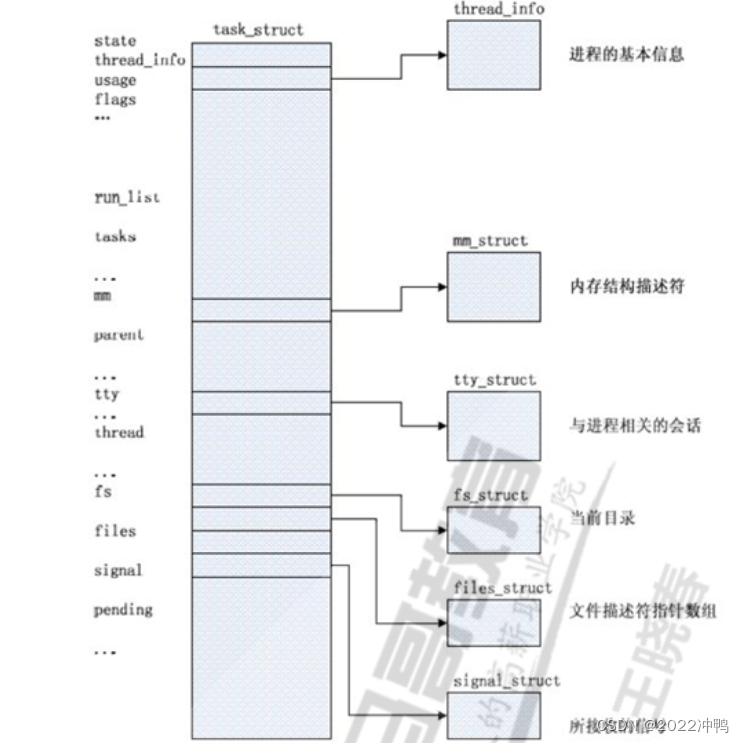
进程控制块PCB包含信息:
进程id、用户id和组id
程序计数器
进程的状态(有就绪、运行、阻塞)
进程切换时需要保存和恢复的CPU寄存器的值
描述虚拟地址空间的信息
描述控制终端的信息
当前工作目录
文件描述符表,包含很多指向file结构体的指针
进程可以使用的资源上限(ulimit –a命令可以查看)
输入输出状态:配置进程使用I/O设备
1.3、进程相关概念
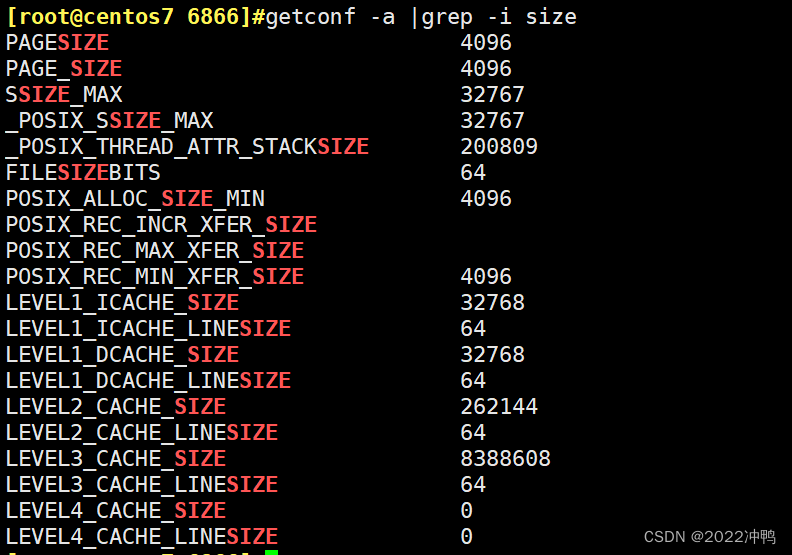
Page Frame: 页框,用存储页面数据,存储Page 4k
getconf -a |grep -i size
1.3.1、物理地址空间和线性地址空间
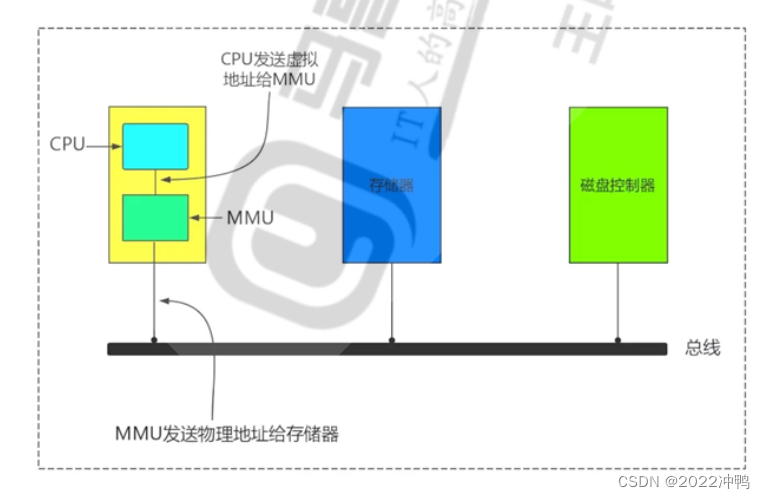
MMU:Memory Management Unit 负责转换线性和物理地址,是数据CPU部件每个应用程序使用的内存其实是虚拟内存,假设有程序proc1,在物理上的内存地址是X-Y,程序proc2,在物理上的内存地址是M-N,且物理内存地址并不一定是连续的,而proc1在虚拟内存中会以为操作系统将所有内存分配给自身。MMU的作用就是转换线程和物理地址
TLB:Translation Lookaside Buffer 翻译后备缓冲器 (加快物理内存和虚拟内存的转换)
用于保存虚拟地址和物理地址映射关系的缓存
LRU:Least Recently Used 近期最少使用算法,释放内存
1.3.2、用户和内核空间
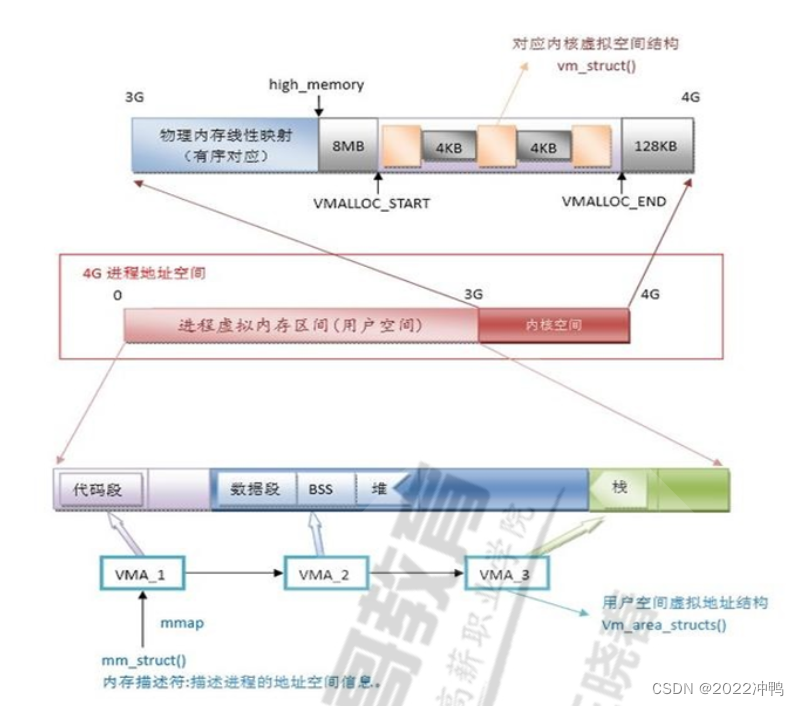
1.3.3、进程使用内存问题
内存泄漏:Memory Leak
指程序中用malloc或new申请了一块内存,但是没有用free或delete将内存释放,导致这块内存一直处
于占用状态
内存溢出:Memory Overflow
指程序申请了10M的空间,但是在这个空间写入10M以上字节的数据,就是溢出
内存不足:OOM
OOM 即 Out Of Memory,“内存用完了”,在情况在java程序中比较常见。系统会选一个进程将之杀死,
在日志messages中看到类似下面的提示
Jul 10 10:20:30 kernel: Out of memory: Kill process 9527 (java) score 88 or sacrifice child
当JVM因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,就会抛出这个
error,因为这个问题已经严重到不足以被应用处理)。
原因:
给应用分配内存太少:比如虚拟机本身可使用的内存(一般通过启动时的VM参数指定)太少。
应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
使用的解决办法:
- 限制java进程的max heap,并且降低java程序的worker数量,从而降低内存使用
- 给系统增加swap空间
设置内核参数(不推荐),不允许内存申请过量:
echo 2 > /proc/sys/vm/overcommit_memory
echo 80 > /proc/sys/vm/overcommit_ratio
echo 2 > /proc/sys/vm/panic_on_oom
说明:
Linux默认是允许memory overcommit的,只要你来申请内存我就给你,寄希望于进程实际上用不到那
么多内存,但万一用到那么多了呢?Linux设计了一个OOM killer机制挑选一个进程出来杀死,以腾出
部分内存,如果还不够就继续。也可通过设置内核参数 vm.panic_on_oom 使得发生OOM时自动重启
系统。这都是有风险的机制,重启有可能造成业务中断,杀死进程也有可能导致业务中断。所以Linux
2.6之后允许通过内核参数 vm.overcommit_memory 禁止memory overcommit。
vm.panic_on_oom 决定系统出现oom的时候,要做的操作。接受的三种取值如下:
0 - 默认值,当出现oom的时候,触发oom killer
1 - 程序在有cpuset、memory policy、memcg的约束情况下的OOM,可以考虑不panic,而是启动OOM
killer。其它情况触发 kernel panic,即系统直接重启
2 - 当出现oom,直接触发kernel panic,即系统直接重启
vm.overcommit_memory 接受三种取值:
0 – Heuristic overcommit handling. 这是缺省值,它允许overcommit,但过于明目张胆的
overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存。Heuristic的意思是“试
探式的”,内核利用某种算法猜测你的内存申请是否合理,它认为不合理就会拒绝overcommit。
1 – Always overcommit. 允许overcommit,对内存申请来者不拒。内核执行无内存过量使用处理。使
用这个设置会增大内存超载的可能性,但也可以增强大量使用内存任务的性能。
2 – Don’t overcommit. 禁止overcommit。 内存拒绝等于或者大于总可用 swap 大小以及
overcommit_ratio 指定的物理 RAM 比例的内存请求。如果您希望减小内存过度使用的风险,这个设置就
是最好的。
Heuristic overcommit算法:
单次申请的内存大小不能超过以下值,否则本次申请就会失败。
free memory + free swap + pagecache的大小 + SLAB
vm.overcommit_memory=2 禁止overcommit,那么怎样才算是overcommit呢?
kernel设有一个阈值,申请的内存总数超过这个阈值就算overcommit,在/proc/meminfo中可以看到
这个阈值的大小:
[root@centos7 ~]#grep -i commit /proc/meminfo
CommitLimit: 5125912 kB
Committed_AS: 4176204 kB
CommitLimit 就是overcommit的阈值,申请的内存总数超过CommitLimit的话就算是overcommit。
此值通过内核参数vm.overcommit_ratio或vm.overcommit_kbytes间接设置的,公式如下:
CommitLimit = (Physical RAM * vm.overcommit_ratio / 100) + Swap
vm.overcommit_ratio 是内核参数,缺省值是50,表示物理内存的50%。如果你不想使用比率,也可以
直接指定内存的字节数大小,通过另一个内核参数 vm.overcommit_kbytes 即可;
如果使用了huge pages,那么需要从物理内存中减去,公式变成:
commitLimit = ([total RAM] – [total huge TLB RAM]) * vm.overcommit_ratio / 100 +
swap
/proc/meminfo中的 Committed_AS 表示所有进程已经申请的内存总大小,(注意是已经申请的,不
是已经分配的),如果 Committed_AS 超过 CommitLimit 就表示发生了 overcommit,超出越多表示
overcommit 越严重。Committed_AS 的含义换一种说法就是,如果要绝对保证不发生OOM (out of
memory) 需要多少物理内存。
1.4、进程状态
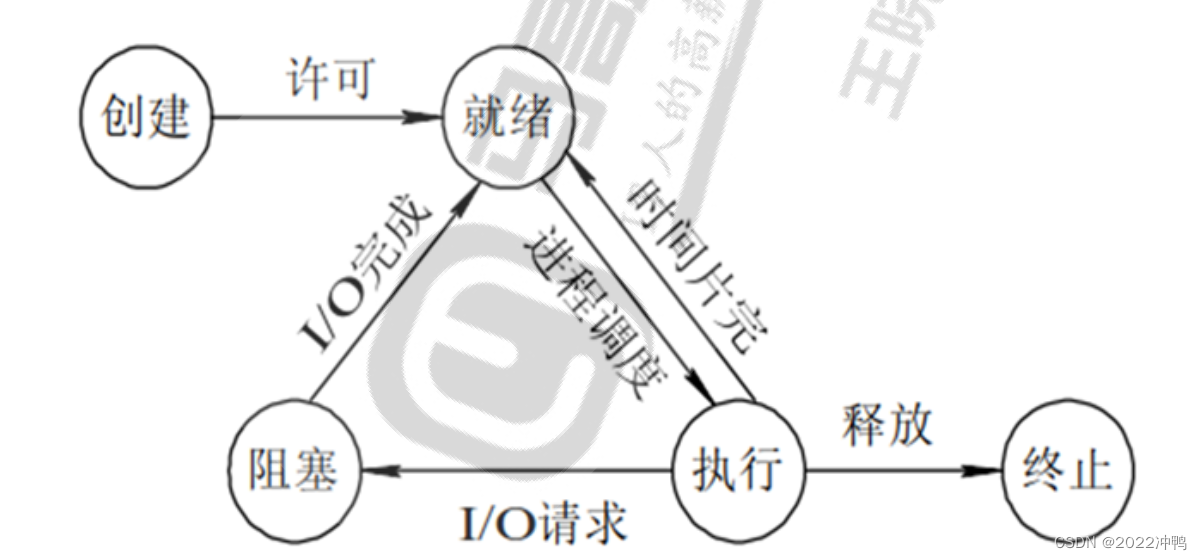
进程的基本状态介绍:
创建状态:进程在创建时需要申请一个空白PCB(process control block进程控制块),向其中填写
控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调
度运行,把此时进程所处状态称为创建状态
就绪状态:进程已准备好,已分配到所需资源,只要分配到CPU就能够立即运行
执行状态:进程处于就绪状态被调度后,进程进入执行状态
阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用
终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
状态之间转换六种情况
运行——>就绪:1,主要是进程占用CPU的时间过长,而系统分配给该进程占用CPU的时间是有限的;2,在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行时,该进程就被迫让出CPU,
该进程便由执行状态转变为就绪状态
就绪——>运行:运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配CPU
运行——>阻塞:正在执行的进程因发生某等待事件而无法执行,则进程由执行状态变为阻塞状态,如发生了I/O请求
阻塞——>就绪:进程所等待的事件已经发生,就进入就绪队列
以下两种状态是不可能发生的:
阻塞——>运行:即使给阻塞进程分配CPU,也无法执行,操作系统在进行调度时不会从阻塞队列进行
挑选,而是从就绪队列中选取
就绪——>阻塞:就绪态根本就没有执行,谈不上进入阻塞态
进程更多的状态:
运行态:running
就绪态:ready
睡眠态:分为两种,可中断:interruptable,不可中断:uninterruptable
停止态:stopped,暂停于内存,但不会被调度,除非手动启动
僵死态:zombie,僵尸态,结束进程,父进程结束前,子进程不关闭,杀死父进程可以关闭僵死
态的子进程
例子:
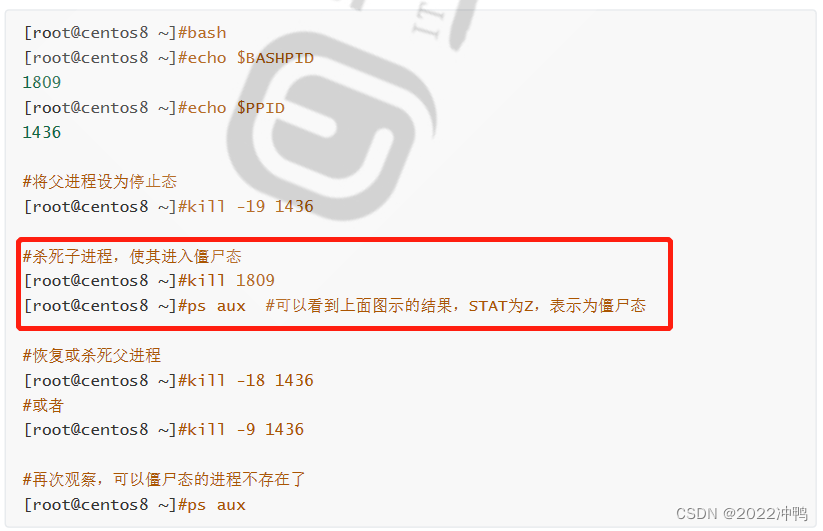
杀死父进程,没有进程管理子进程,则会进入僵尸态,STAT 为Z,表示僵尸态
1.5、LRU 算法
LRU:Least Recently Used 近期最少使用算法(喜新厌旧),释放内存
将使用平率最少的使用算法,释放内存。
1.6、IPC 进程间通信
IPC: Inter Process Communication
文件类型:普通文件、软连接文件、套接字文件、管道文件(p)、目录文件(d)、字符文件(c)、块文件(b)
创建管道文件:mkfifo /data/test.fifo
实现进程间通信IPC,一对一的通信,一方写,另一方读
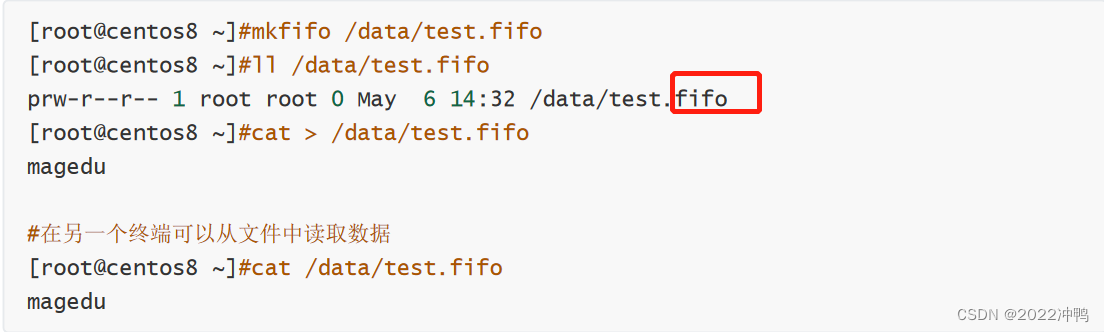
同一主机:

不同主机:socket=IP和端口号

RPC 远程主机调用,一台主机发起任务,另一台接受到信号处理任务,任务结束后发送最终结果
1.7、进程优先级
Linux2.6内核将任务优先级进行划分,实时优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(100-139)
0-99 实时进程
100-139 非实时进程
Centos优先级

进程优先级:
系统优先级:数字越小,优先级越高
0-139(CentOS 4,5),各有140个运行队列和过期队列
0-98,99(CentOS 6)
实时优先级: 99-0 值最大优先级最高
nice值:-20到19,对应系统优先级100-139或99
Big O:时间(空间)复杂度,用时(空间)和规模的关系
O(1), O(logn), O(n)线性, O(n^2)抛物线, O(2^n)
1.8、进程分类
操作系统分类
协作式多任务:早期 windows 系统使用,即一个任务得到了 CPU 时间,除非它自己放弃使用
CPU ,否则将完全霸占 CPU ,所以任务之间需要协作——使用一段时间的 CPU ,主动放弃使用
抢占式多任务:Linux内核,CPU的总控制权在操作系统手中,操作系统会轮流询问每一个任务是
否需要使用 CPU ,需要使用的话就让它用,不过在一定时间后,操作系统会剥夺当前任务的 CPU
使用权,把它排在询问队列的最后,再去询问下一个任务
进程类型:
守护进程: daemon,在系统引导过程中启动的进程,和终端无关进程
前台进程:跟终端相关,通过终端启动的进程
注意:两者可相互转化
按进程资源使用的分类:
CPU-Bound:CPU密集型,非交互
IO-Bound:IO密集型,交互
1.9、IO调度算法
NOOP
NOOP算法的全写为No Operation。该算法实现了最简单的FIFO队列,所有IO请求大致按照先来
后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,
并不是完完全全按照先进先出的规则满足IO请求。NOOP假定I/O请求由驱动程序或者设备做了优
化或者重排了顺序(就像一个智能控制器完成的工作那样)。在有些SAN环境下,这个选择可能是最
好选择。Noop 对于 IO 不那么操心,对所有的 IO请求都用 FIFO 队列形式处理,默认认为 IO 不会
存在性能问题。这也使得 CPU 也不用那么操心。当然,对于复杂一点的应用类型,使用这个调度
器,用户自己就会非常操心
Deadline scheduler
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。deadline 算法保证对于既定的 IO 请
求以最小的延迟时间,除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提
供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队
列内的IO请求优先级要比CFQ队列中的高,,而读FIFO队列的优先级又比写FIFO队列的优先级
高。优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
Anticipatory scheduler
CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做
优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。
ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms 的等待时间窗口。如果在这
6ms内OS收到了相邻位置的读IO请求,就可以立即满足 Anticipatory scheduler(as) 曾经一度
是 Linux 2.6 Kernel 的 IO scheduler 。Anticipatory 的中文含义是”预料的, 预想的”, 这个词的确揭
示了这个算法的特点,简单的说,有个 IO 发生的时候,如果又有进程请求 IO 操作,则将产生一
个默认的 6 毫秒猜测时间,猜测下一个 进程请求 IO 是要干什么的。这对于随即读取会造成比较大
的延时,对数据库应用很糟糕,而对于 Web Server 等则会表现的不错。这个算法也可以简单理解
为面向低速磁盘的,因为那个”猜测”实际上的目的是为了减少磁头移动时间。
CFQ
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不
是按照先来后到的顺序来进行响应。 在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时
间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在
CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能
被满足,可能会出现饿死的情况。
Completely Fair Queuing (cfq, 完全公平队列) 在 2.6.18 取代了 Anticipatory scheduler 成为
Linux Kernel 默认的 IO scheduler 。cfq 对每个进程维护一个 IO 队列,各个进程发来的 IO 请求
会被 cfq 以轮循方式处理。也就是对每一个 IO 请求都是公平的。这使得 cfq 很适合离散读的应用
实现CPU绑定
taskset –help
taskset 查询或设置进程(线程)绑定CPU(亲和性)
Linux:taskset 查询或设置进程(线程)绑定CPU(亲和性)_test1280的博客-CSDN博客_taskset 线程
- 进程管理和性能相关工具
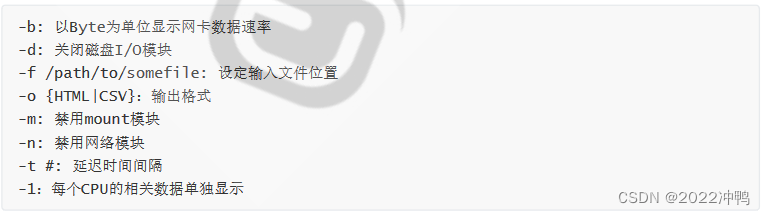
Linux系统状态的查看及管理工具:pstree, ps, pidof, pgrep, top, htop, glance, pmap, vmstat, dstat,
kill, pkill, job, bg, fg, nohup
2.1 进程树 pstree
pstree -p查看进程以及对应的线程 { } 代表线程
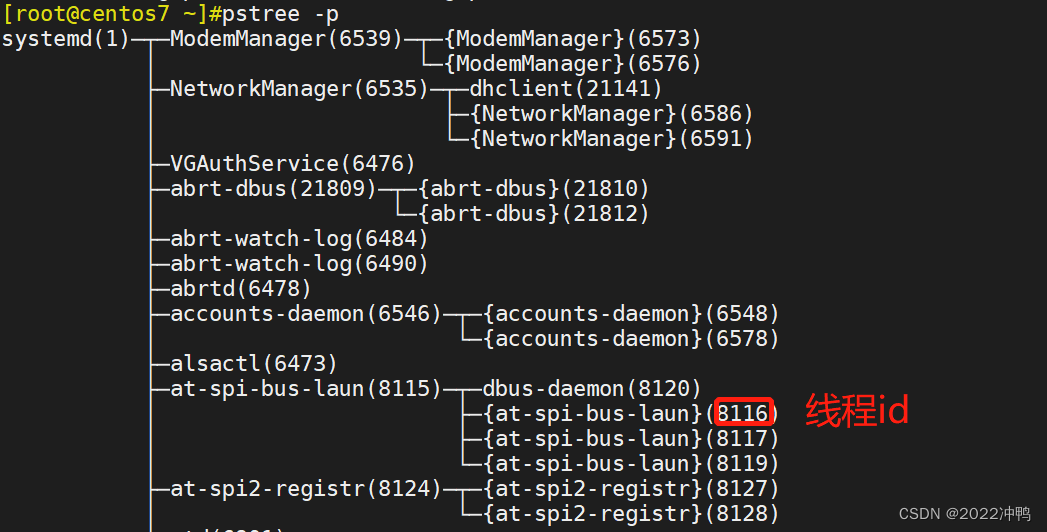
打开某个进程里面的线程:top -H -p 8116
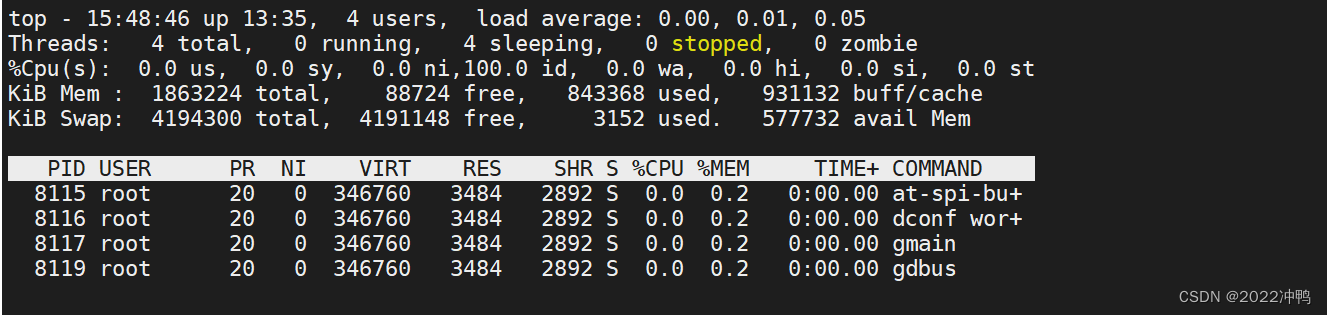
2.2 进程信息 ps
ps 即process state,可以进程当前状态的快照,默认显示当前终端中的进程,Linux系统各进程的相关,信息均保存在/proc/PID目录下的各文件中。
ps格式
![]()
支持三种选项:
UNIX选项 如: -A -e
BSD选项 如: a
GNU选项 如: --help
常用选项:

ps 输出属性
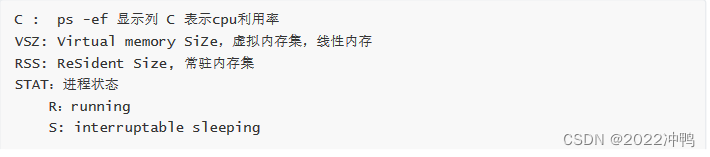

例子:
ps axo pid,cmd,psr,ni,pri,rtprio
常用组合:
aux
-ef
-eFH
-eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,comm
axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
典型用法:


单位为K

查找占用最多的内存和CPU的前10个进程
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem |head
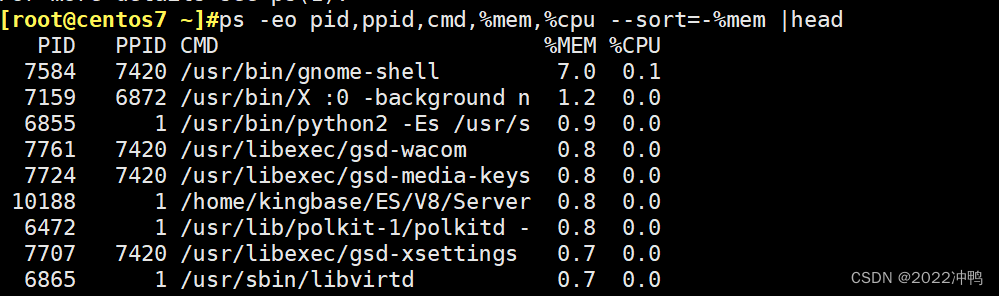
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%cpu |head

w 查看终端执行哪个进程

pgrep -t pts/1

2.3、查看进程信息prtstat
可以显示进程信息,来自于psmisc包
格式:
prtstat [options] PID …
选项:
-r raw 格式显示
2.4、设置和调整进程优先级
进程优先级调整
静态优先级:100-139
进程默认启动时的nice值为0,优先级为120
只有根用户才能降低nice值(提高优先性)
nice命令
以指定的优先级来启动进程
nice [OPTION] [COMMAND [ARG]...]
-n, --adjustment=N add integer N to the niceness (default 10)
renice命令
可以调整正在执行中的进程的优先级
renice [-n] priority pid...
查看进程优先级:
ps axo pid,comm,ni
2.5、搜索进程
按条件搜索进程
ps 选项 | grep 'pattern' 灵活
pgrep 按预定义的模式
/sbin/pidof 按确切的程序名称查看pid
pgrep 命令格式
pgrep [options] patter
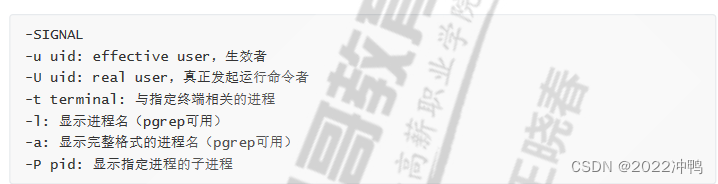
常用选项
-u uid: effective user,生效者
-U uid: real user,真正发起运行命令者
-t terminal: 与指定终端相关的进程
-l: 显示进程名
-a: 显示完整格式的进程名
-P pid: 显示指定进程的子进程
pidof:用于查找指定名称的进程的进程号id号
pidof kingbase
10196 10195 10194 10193 10192 10191 10189 10188
pidof (选项)(参数)
选项
-s:仅返回一个进程号;
-c:仅显示具有相同“root”目录的进程;
-x:显示由脚本开启的进程;
-o:指定不显示的进程ID。
参数
进程名称:指定要查找的进程名称
2.6、负载查询 uptime
/proc/uptime 包括两个值,单位:秒(s)
系统启动时长
空闲进程的总时长(按总的CPU核数计算,不是单个CPU时长)
[root@centos7 ~]#cat /proc/uptime
11633.53 10672.56
系统cpu空闲率=系统启动时长*CPU核数/空闲进程总时长

负载数指的是总核数统计时间内,0.05个进程在运行队列中
uptime 和 w 显示以下内容
当前时间
系统已启动的时间
当前上线人数
系统平均负载(1、5、15分钟的平均负载,一般不会超过1,实际使用经验,超过5时建议警报)
系统平均负载: 指在特定时间间隔内运行队列中的平均进程数,通常每个CPU内核的当前活动进程数不大
于3,那么系统的性能良好。如果每个CPU内核的任务数大于5,那么此主机的性能有严重问题。可以使用uptime来确定是服务器还是网络出了问题。例如如果网络应用程序运行,运行uptime来了解系统负载是否很高。如果负载不高,这个问题很有可能是由于网络引起的而非服务器。
如果linux主机是1个单核CPU,当Load Average 为6的时候说明机器已经被充分使用。
如果是多核CPU,则还要将结果除以核数。例如4核时,某个最近一分钟的负载值为3.73,则意味着有3.73个进程在运行队列中,这些进程可被调度至4核中的任一一个核上运行,假如最近1分钟的负载值为1.6,表示这一分钟每核cpu都空闲(1-1.6/4)*100%=60%
需要注意的是,可运行的(就绪态,即就绪队列的长度)、正在运行的(运行态)和不可中断睡眠(如I/O等待)的进程都会计算到负载中。现在负载高、CPU空闲,说明当前正在执行的任务基本不消耗CPU资源,大量的负载进程都处于不可中断睡眠状态,这意味着有大量进程在·I/O等待中。
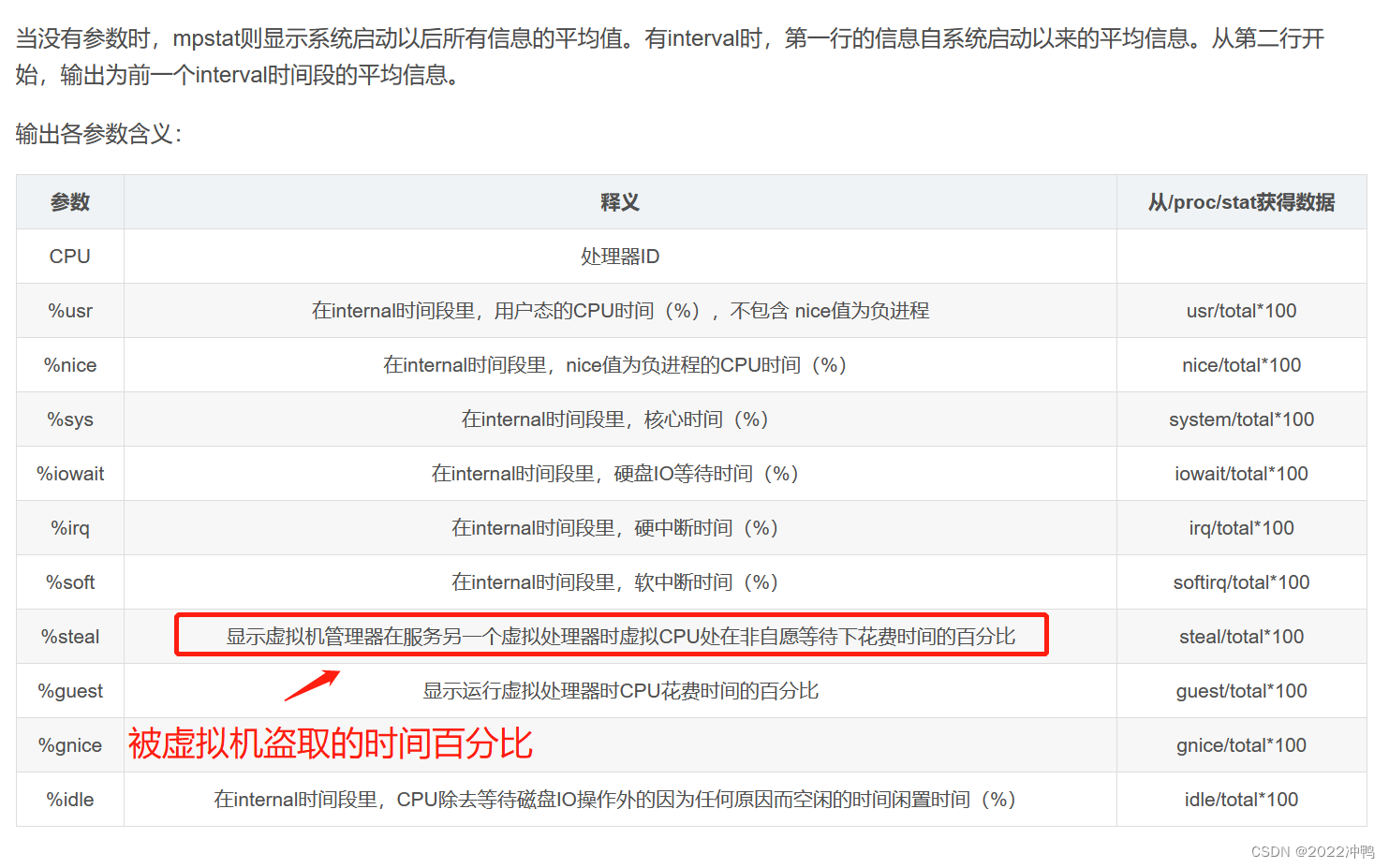
2.7、显示CPU相关统计 mpstat
此命令需要安装sysstat,yum install sysstat
mpstat默认为静态结果

mpstat N M N 时间间隔 M频率
输出参数含义
2.8、查看进程实时状态 top
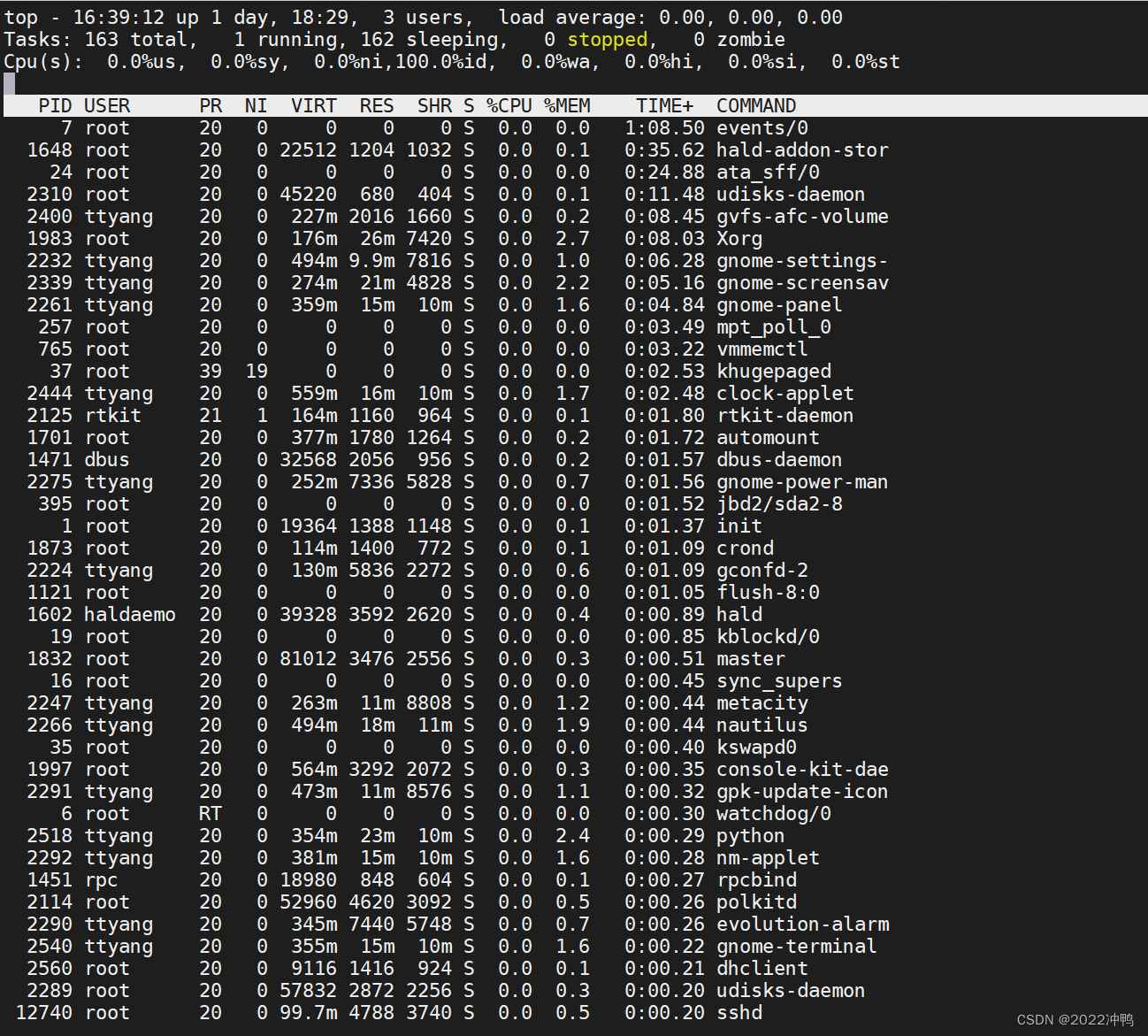
top命令详解

us 用户,应用程序均在此安装,期望此值数目大
sy 操作系统内核占比
ni nice 用户优先级调整
id 空闲空间
wa 操作系统等待
hi 硬中断
si 软中断(模式切换)
st 盗取时间片 steal ,丢失的时间点
中断 :打断cpu 执行
- 默认使用top命令以cpu占比从高到低排序,按P键
- T 按照时间排序
- M 按照内存占比排序
- T 累计占据CPU时长,TIME+
%MEM 不断增大,会出现内存泄露
l 键隐藏uptime
首部信息提示:
uptime信息:l命令
task及cpu信息:t命令
cpu分别显示:1(数字),适用于多核cpu
memory信息:m命令
退出命令:q
修改刷新时间间隔:s
终止指定进程:k
保存文件:W
top选项:
-d #指定刷新时间间隔,默认为3秒
-b #全部显示所有进程
-H 线程模式
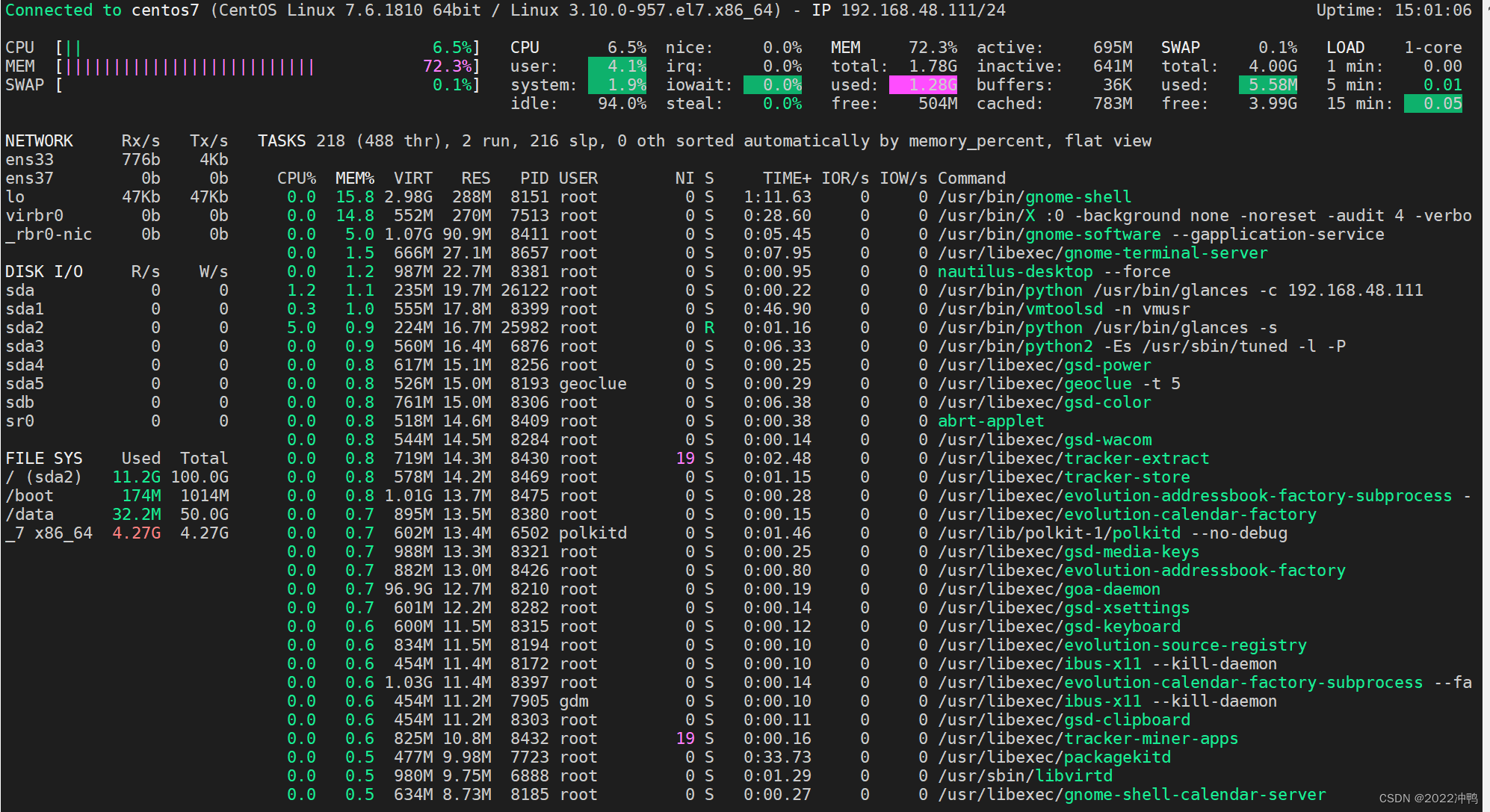
2.9、htop :增强版的TOP命令,来自EPEL源,比top功能更强,界面显示多样性。进入界面以后,默认为nano形式,最下面有相对应的操作说明。

选项:
-d #: 指定延迟时间;
-u UserName: 仅显示指定用户的进程
-s COLUME: 以指定字段进行排序
子命令:
s:跟踪选定进程的系统调用
l:显示选定进程打开的文件列表
a:将选定的进程绑定至某指定CPU核心
t:显示进程树
2.10、free内存空间
free 可以显示内存空间使用状态
格式:
free [OPTION]
常用选项:
-b 以字节为单位
-m 以MB为单位
-g 以GB为单位
-h 易读格式
-o 不显示-/+buffers/cache行
-t 显示RAM + swap的总和
-s n 刷新间隔为n秒
-c n 刷新n次后即退出
centos6 中free 命令查看
buffers 与写数据有关,修改完数据,将数据按照一定的次序写入缓冲区中
cached 与读数据有关,将数据放入缓存中,下次直接从缓存中提取
二者均能够提高效率

free -h 选择合适的单位,-g 以G为单位 -M 以MB为单位

centos7 中显示

清理缓存的方法如下,但是不建议清理缓存,因为缓存本身就是为了提高访问效率:
[root@centos6 ~]# echo 3 > /proc/sys/vm/drop_caches
2.11、进程对应的内存映射pmap
pmap pid或者另一种实现 cat /proc/PID/maps
pmap PID
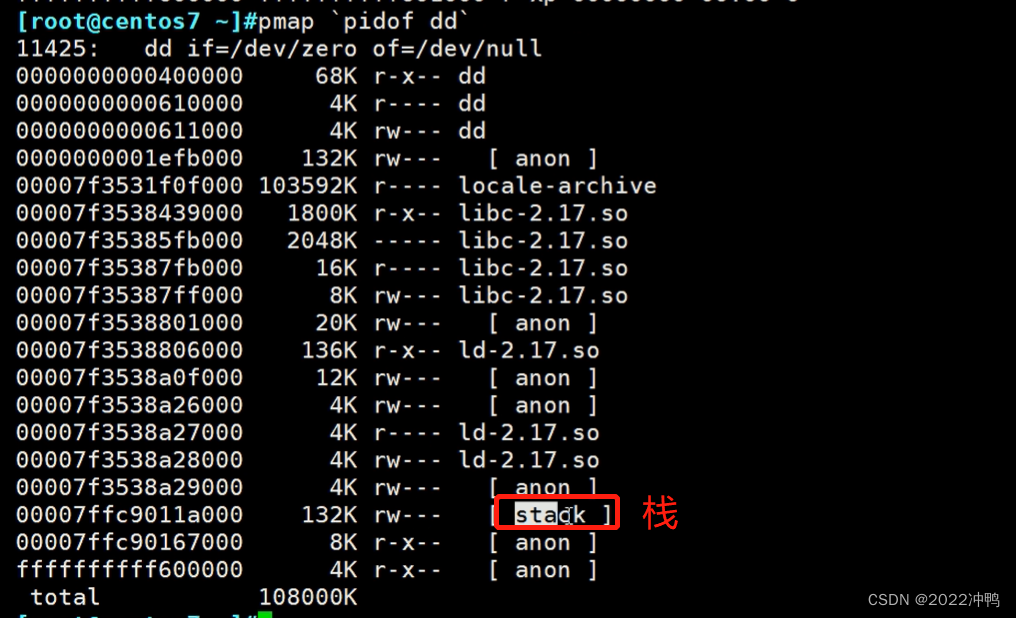
anon 匿名内存空间
heap 堆,数据量大,分散的块
stack 栈
查看系统调用 strace command,需要安装yum install strace -y
查看库调用 ltrace command,需要安装yum install ltrace -y
查看某个命令调用的系统库
strace /bin/cat
查看系统调用的函数库
ltrace /bin/cat /etc/passwd
2.12、虚拟内存信息vmstat 工具

以下的I/O均是以内存为参照物
打印显示项说明:
vmstat命令:虚拟内存信息
vmstat [options] [delay [count]]
vmstat 2 5
procs:
r:可运行(正运行或等待运行)进程的个数,和核心数有关
b:处于不可中断睡眠态的进程个数(被阻塞的队列的长度)
memory:
swpd: 交换内存的使用总量
free:空闲物理内存总量
buffer:用于buffer的内存总量
cache:用于cache的内存总量
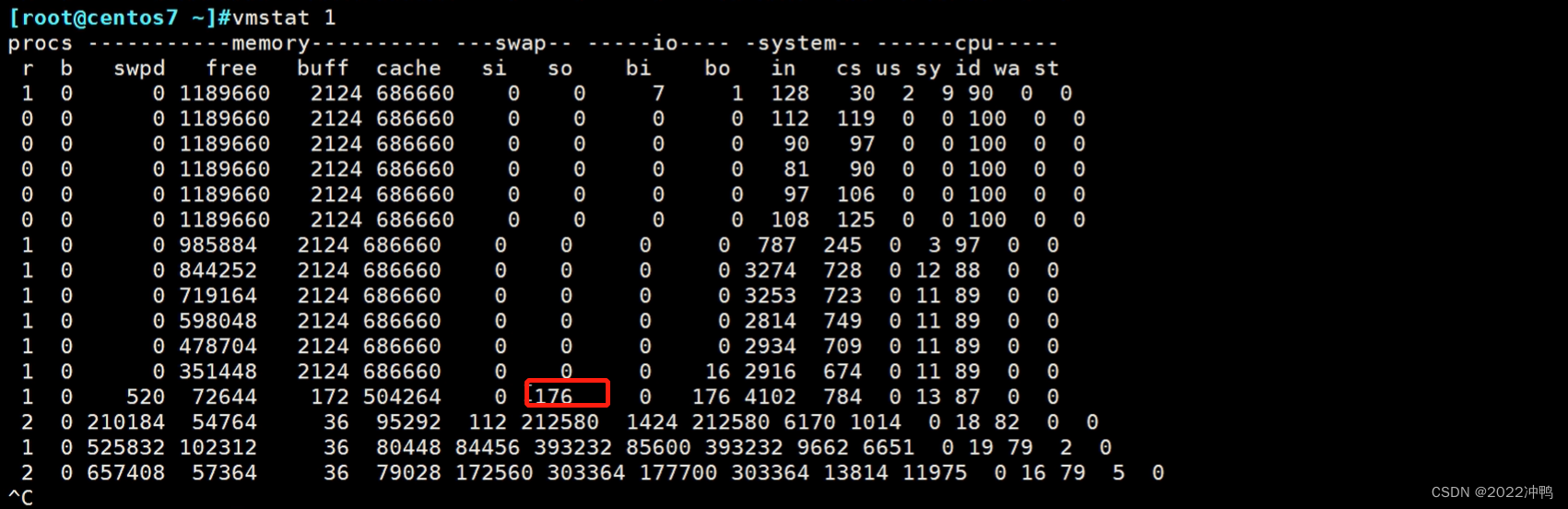
io:
bi:从块设备读入数据到系统的速率(kb/s)
bo: 保存数据至块设备的速率
cpu:
us:Time spent running non-kernel code
sy: Time spent running kernel code
id: Time spent idle. Linux 2.5.41前,包括IO-wait time.
wa: Time spent waiting for IO. 2.5.41前,包括in idle.
st: Time stolen from a virtual machine. 2.6.11前, unknown.
system:
in: interrupts 中断速率,包括时钟
cs: context switch 进程切换速率
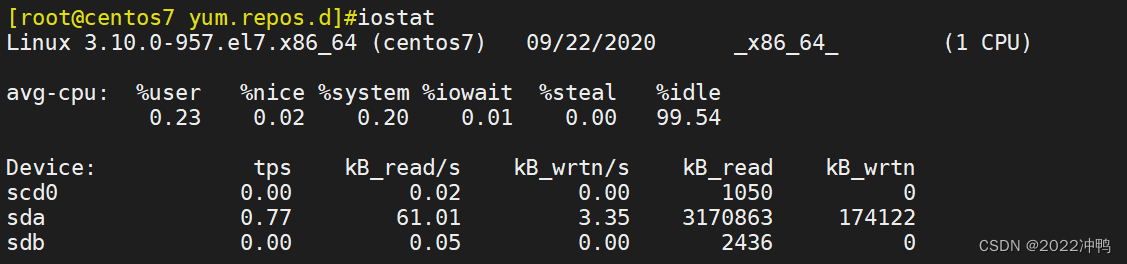
2.13、统计CPU和设备IO信息iostat
此工具由sysstat包提供
2.14、系统资源统计 dstat
dstat由pcp-system-tools包提供,用于代替 vmstat,iostat功能
格式:
dstat [-afv] [options..] [delay [count]]
常用选项
-c 显示cpu相关信息
-C #,#,...,total
-d 显示disk相关信息
-D total,sda,sdb,...
-g 显示page相关统计数据
-m 显示memory相关统计数据
-n 显示network相关统计数据
-p 显示process相关统计数据
-r 显示io请求相关的统计数据
-s 显示swapped相关的统计数据
--tcp
--udp
--unix
--raw
--socket
--ipc
--top-cpu:显示最占用CPU的进程
--top-io: 显示最占用io的进程
--top-mem: 显示最占用内存的进程
--top-latency: 显示延迟最大的进程
例子:
dstat 1 6
2.15、监视磁盘I/O iotop
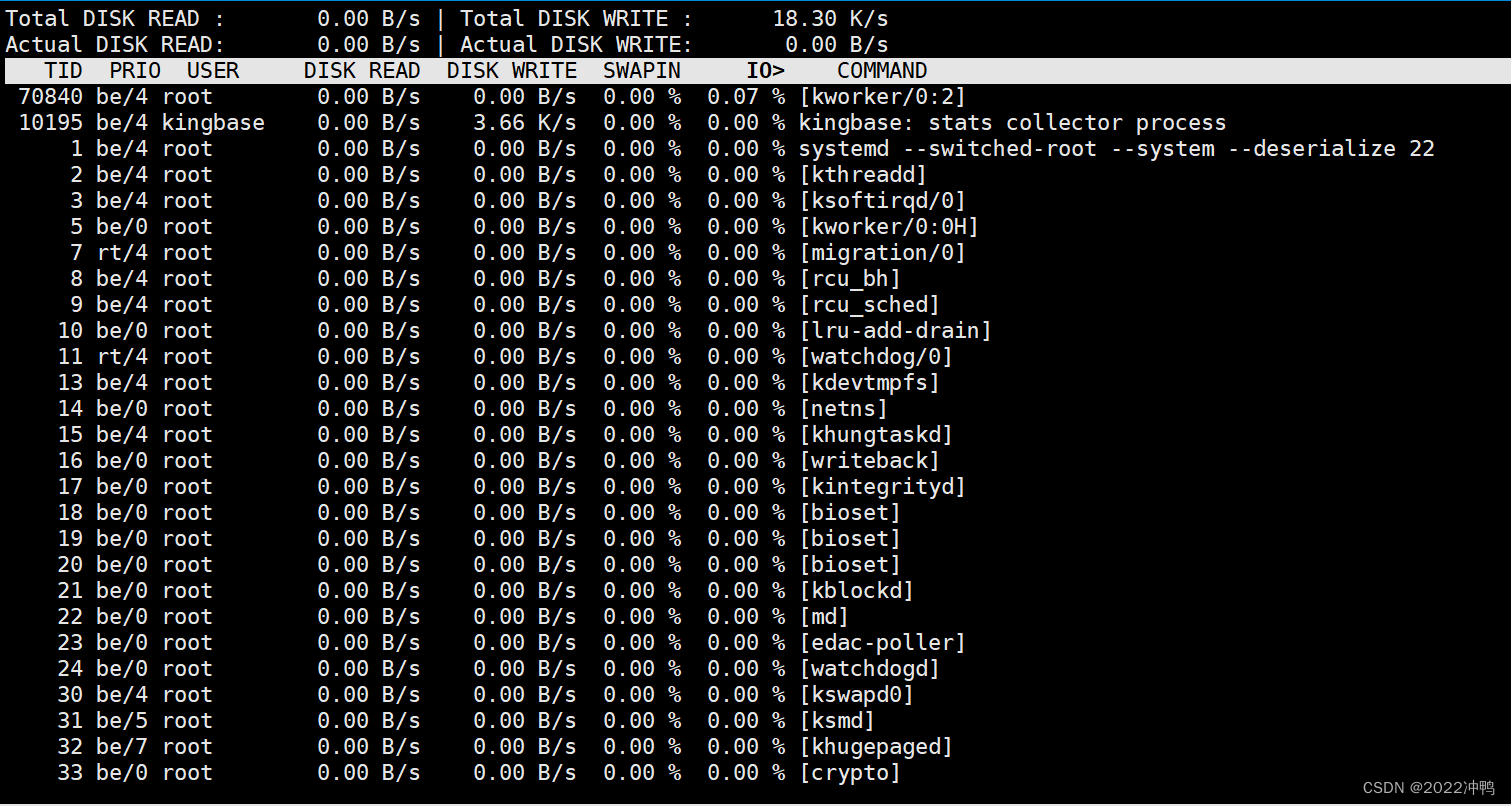
iotop命令是一个用来监视磁盘I/O使用状况的top类工具iotop具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息,可查看每个进程是如何使用IO
iotop输出
第一行:Read和Write速率总计
第二行:实际的Read和Write速率
第三行:参数如下:

iotop常用参数
-o, --only只显示正在产生I/O的进程或线程,除了传参,可以在运行过程中按o生效
-b, --batch非交互模式,一般用来记录日志
-n NUM, --iter=NUM设置监测的次数,默认无限。在非交互模式下很有用
-d SEC, --delay=SEC设置每次监测的间隔,默认1秒,接受非整形数据例如1.1
-p PID, --pid=PID指定监测的进程/线程
-u USER, --user=USER指定监测某个用户产生的I/O
-P, --processes仅显示进程,默认iotop显示所有线程
-a, --accumulated显示累积的I/O,而不是带宽
-k, --kilobytes使用kB单位,而不是对人友好的单位。在非交互模式下,脚本编程有用
iotop常用参数和快捷键
-t, --time 加上时间戳,非交互非模式
-q, --quiet 禁止头几行,非交互模式,有三种指定方式
-q 只在第一次监测时显示列名
-qq 永远不显示列名
-qqq 永远不显示I/O汇合
交互按键
left和right方向键:改变排序
r:反向排序
o:切换至选项--only
p:切换至--processes选项
a:切换至--accumulated选项
q:退出
i:改变线程的优先级
显示网络带宽使用情况iftop(通过EPEL源安装)
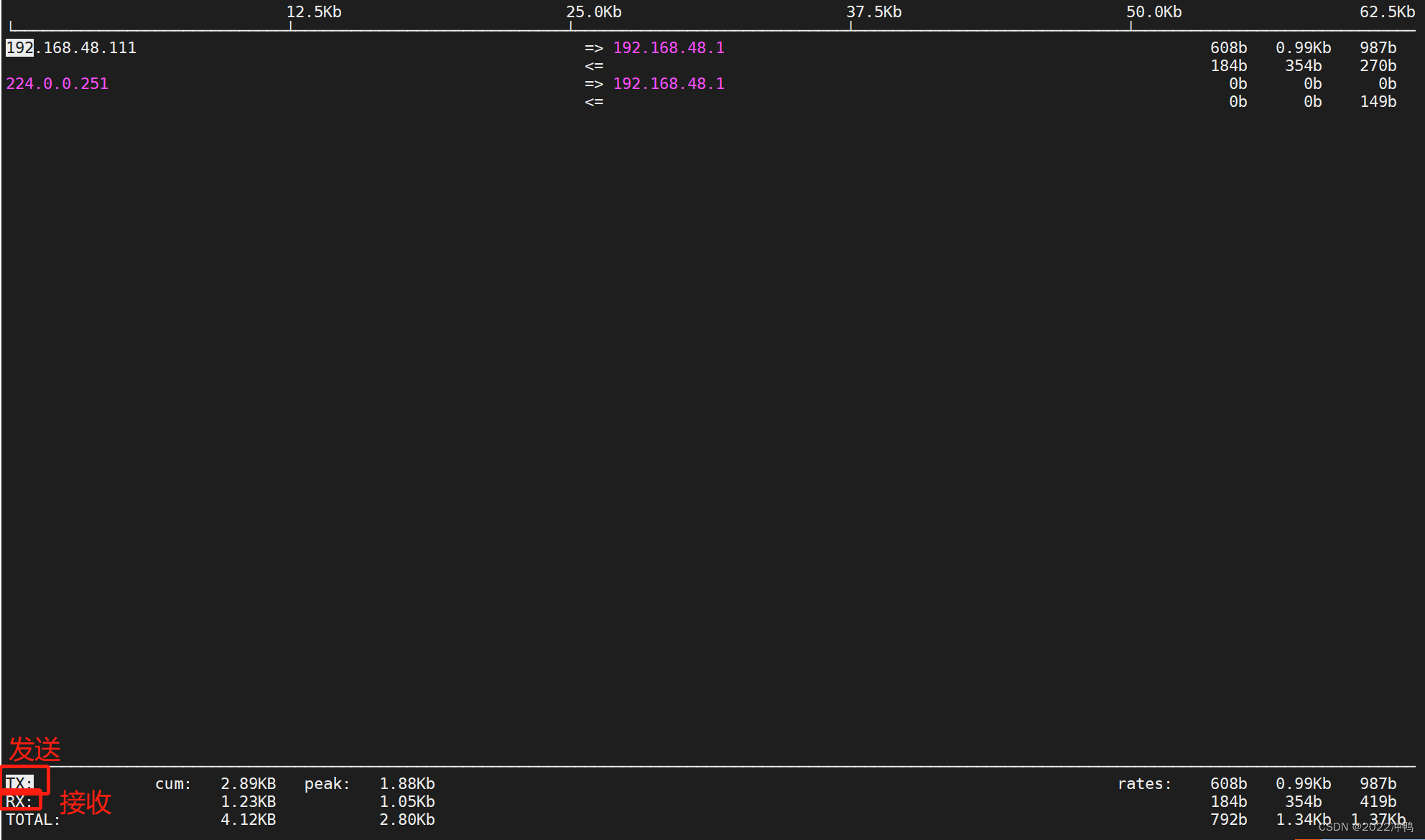
2.16、查看网络实时吞吐量nload(epel安装)
nload 是一个实时监控网络流量和带宽使用情况,以数值和动态图展示进出的流量情况

界面操作
上下方向键、左右方向键、enter键或者tab键都就可以切换查看多个网卡的流量情况
按 F2 显示选项窗口
按 q 或者 Ctrl+C 退出 nload
例子:

2.17、综合监控工具glances(EPEL源安装,CentOS 8 目前没有提供)
glances [-bdehmnrsvyz1] [-B bind] [-c server] [-C conffile] [-p port] [-P
password] [--password] [-t refresh] [-f file] [-o output]
内建命令:
a Sort processes automatically l Show/hide logs
c Sort processes by CPU% b Bytes or bits for network I/O
m Sort processes by MEM% w Delete warning logs
p Sort processes by name x Delete warning and critical logs
i Sort processes by I/O rate 1 Global CPU or per-CPU stats
d Show/hide disk I/O stats h Show/hide this help screen
f Show/hide file system stats t View network I/O as combination
n Show/hide network stats u View cumulative network I/O
s Show/hide sensors stats q Quit (Esc and Ctrl-C also work)
y Show/hide hddtemp stats
常用选项:
C/S模式下运行glances命令
服务器模式:
glances -s -B IPADDR
IPADDR: 指明监听的本机哪个地址
客户端模式:
glances -c IPADDR
IPADDR:要连入的服务器端地址
例子:
server端
glances -s

client端
glances -c 192.168.48.111
2.18、查看进程打开文件 lsof
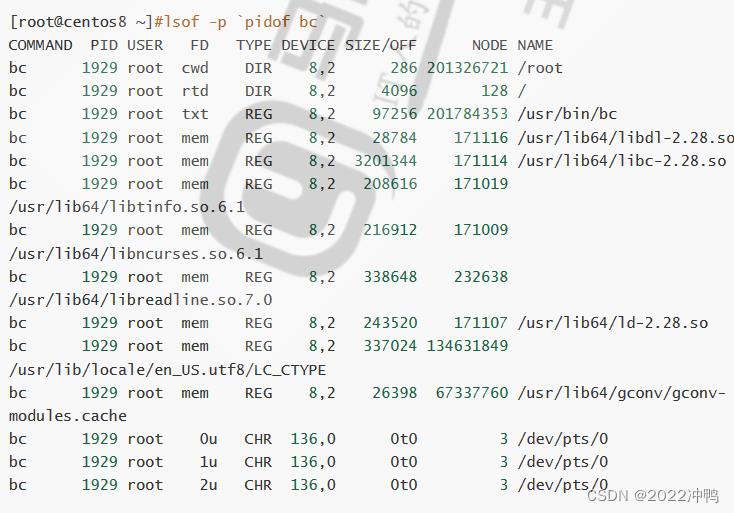
lsof:list open files,查看当前系统文件的工具。在linux环境下,一切皆文件,用户通过文件不仅可以
访问常规数据,还可以访问网络连接和硬件如传输控制协议 (TCP) 和用户数据报协议 (UDP)套接字等,
系统在后台都为该应用程序分配了一个文件描述符
命令选项:
-a:列出打开文件存在的进程
-c<进程名>:列出指定进程所打开的文件
-g:列出GID号进程详情
-d<文件号>:列出占用该文件号的进程
+d<目录>:列出目录下被打开的文件
+D<目录>:递归列出目录下被打开的文件
-n<目录>:列出使用NFS的文件
-i<条件>:列出符合条件的进程(4、6、协议、:端口、 @ip )
-p<进程号>:列出指定进程号所打开的文件
-u:列出UID号进程详情
-h:显示帮助信息
-v:显示版本信息。
-n: 不反向解析网络名字
例子:
#查看由登陆用户启动而非系统启动的进程
lsof /dev/pts/1
#指定进程号,可以查看该进程打开的文件
lsof -p 952
#查看指定程序打开的文件
lsof -c httpd
[root@centos8 ~]#lsof -c b

实际解决问题的例子:
利用 lsof 恢复正在使用中的误删除的文件
lsof |grep /var/log/messages
rm -f /var/log/messages
lsof |grep /var/log/messages
cat /proc/653/fd/6
cat /proc/653/fd/6 > /var/log/messages
2.19、CentOS 8 新特性 cockpit
Cockpit 是CentOS 8 取入的新特性,是一个基于 Web 界面的应用,它提供了对系统的图形化管理
监控系统活动(CPU、内存、磁盘 IO 和网络流量)
查看系统日志条目
查看磁盘分区的容量
查看网络活动(发送和接收)
查看用户帐户
检查系统服务的状态
提取已安装应用的信息
查看和安装可用更新(如果以 root 身份登录)并在需要时重新启动系统
打开并使用终端窗口
例子:
安装 cockpit,dnf install cocpit,systemctl enable --now cockpit.socket
打开浏览器,访问以下地址:
https://centos8主机:9090
2.20、信号发送 kill
kill:内部命令,可用来向进程发送控制信号,以实现对进程管理,每个信号对应一个数字,信号名称以SIG开头(可省略),不区分大小写
显示当前系统可用信号:
kill -l
trap -l
查看帮助:man 7 signal
常用信号:

指定信号的方法 :
信号的数字标识:1, 2, 9
信号完整名称:SIGHUP,sighup
信号的简写名称:HUP,hup
向进程发送信号:
按PID
kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... or kill -l [sigspec]
例子:

按照名称:killall 来自于psmisc包
常用选项:
例子:
查看某个服务的HUP信号
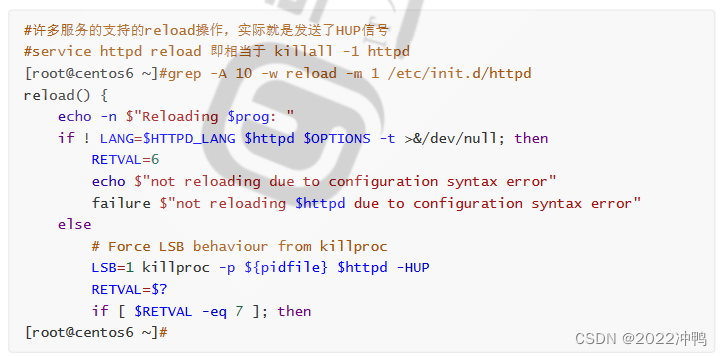
killall -0 服务名称 检测服务是否正常,并不是很严谨,有可能为僵尸态,但此脚本本身诊断却为正常

2.21、作业管理
Linux的作业控制
前台作业:通过终端启动,且启动后一直占据终端
后台作业:可通过终端启动,但启动后即转入后台运行(释放终端)
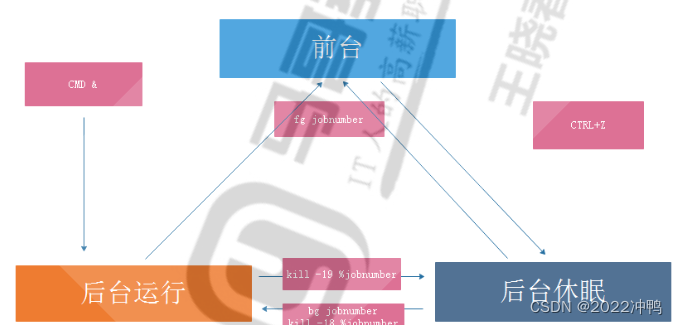
让作业运行于后台
运行中的作业: Ctrl+z
尚未启动的作业: COMMAND &
后台作业虽然被送往后台运行,但其依然与终端相关;退出终端,将关闭后台作业。如果希望送往后台后,剥离与终端的关系
nohup COMMAND &>/dev/null &
screen;COMMAND
tmux;COMMAND
jobs 查看当前窗口进程的作业编号、进程状态
作业控制:
fg [[%]JOB_NUM]:把指定的后台作业调回前台
bg [[%]JOB_NUM]:让送往后台的作业在后台继续运行
kill [%JOB_NUM]: 终止指定的作业
command & 放入后台且执行,关闭终端,进程也会消失
ctrl+z 前台运行切换到后台停止
fg 作业编号 将后台进程放入前台进程
bg 作业编号 将前台休眠进程切换到后台运行进程
killall -18 服务名称 后台停止切换到后台运行
killall -19 服务名称 后台运行切换到后台停止
如何将前台进程切换在后台?
ctrl+z, 此时命令状态变为停止状态(T)
如果需要将进程放在后台且为运行状态,需发送18信号,kill -18 pid,或者是作业编号,例如kill -18 %1
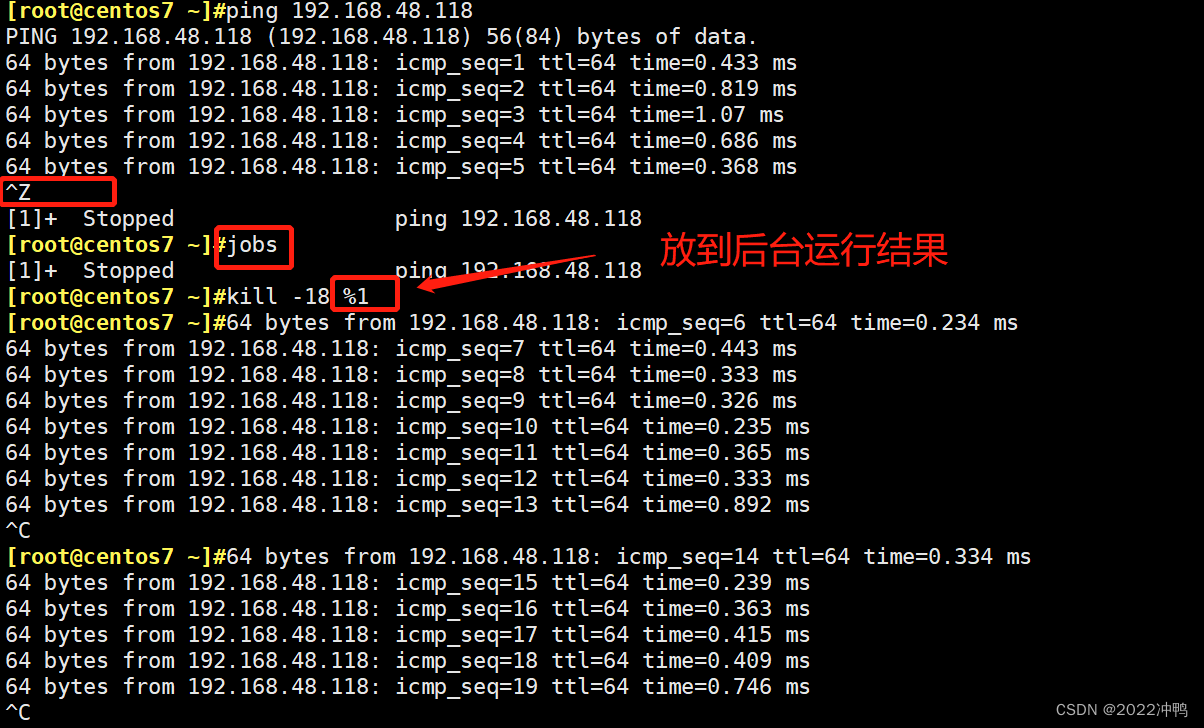
如何将后台命令改为前台进行?
fg + 作业编号
2、22、并行运行
利用后台执行,实现并行功能,即同时运行多个进程,提高效率
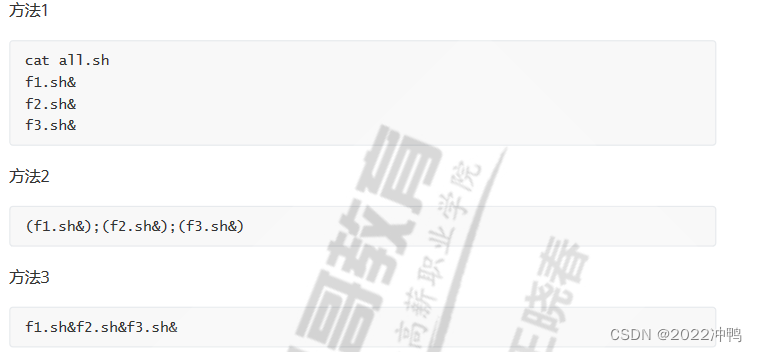
- 多组命令实现并行

- 检测主机状态
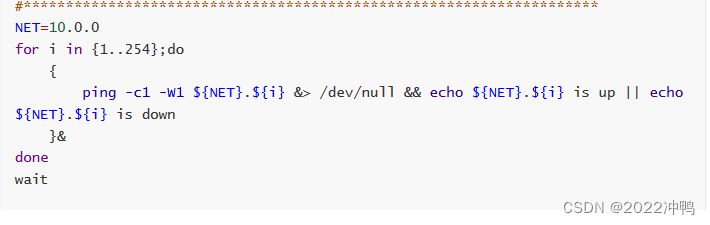
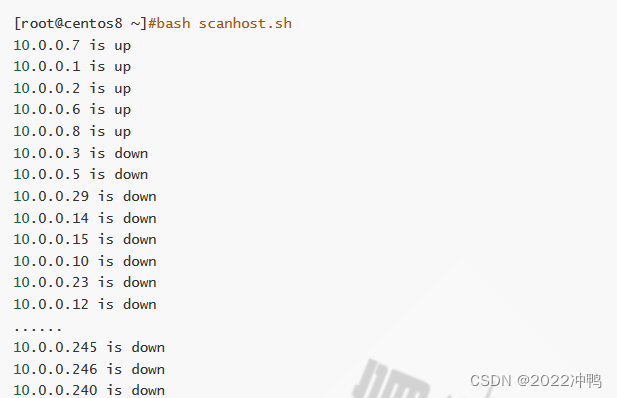
init 3 关闭图形界面
init5 开启图形界面















 811
811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









