







Android 平台对内存敏感,所以需要在代码中对数据结构进行一定程度的优化,下面比较常用的几种Map实现
HashMap
Java中比较常用的Map实现类,但是对内存的利用率并不是很高,HashMap使用的是HashTable 中的拉链结构(数组+链表头)
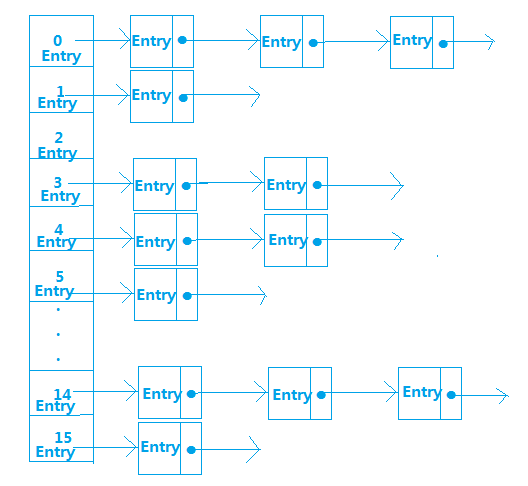
Entry是Map的实体类,内部的数据结构如下
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;HashMap是如何计算元素的位置的?
HashMap通过计算元素的key的hash值得到该元素的位置
从中我们得知Entry存储的内容有key、value、hash值、和next下一个Entry,那么,这些Entry数据是按什么规则进行存储的呢?就是通过计算元素key的hash值,然后对HashMap中数组长度取余得到该元素存储的位置,计算公式为hash(key)%len,比如:假设hash(14)=14,hash(30)=30,hash(46)=46,我们分别对len取余,得到
hash(14)%16=14,hash(30)%16=14,hash(46)%16=14,所以key为14、30、46的这三个元素存储在数组下标为14的位置,如:
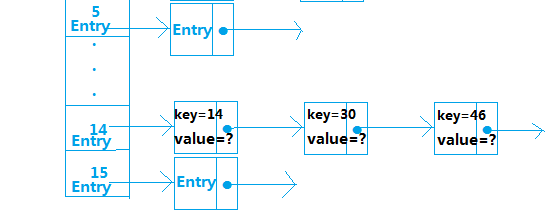
HashMap是使用链地址法处理的冲突,其他处理方法如下
* 开放地址法
* 再哈希法
* 链地址法
* 建立公共溢出区
当不断put数据时,HashMap会以两倍的速度进行扩容,在此过程中也要不断进行Hash运算,对内存的消耗巨大;
int newCapacity = oldCapacity * 2; // 数量数 > 容量 * 加载因子(0.75)就会进行扩容SparseArray 稀疏矩阵
SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),
它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,
它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间,我们从源码中可以看到key和value分别是用数组表示:
private int[] mKeys; // 直接使用int[] 避免自动装箱
private Object[] mValues;SparseArray的put()
/**
* Adds a mapping from the specified key to the specified value,
* replacing the previous mapping from the specified key if there
* was one.
*/
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}Android中提供的二分查找
// This is Arrays.binarySearch(), but doesn't do any argument validation.
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // value found
}
}
return ~lo; // value not present
}也就是在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。
而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
SparseArray特有方法
在此之外,SparseArray还提供了两个特有方法,更方便数据的查询:
获取对应的key:
public int keyAt(int index)
获取对应的value:
public E valueAt(int index)
SparseArray的应用场景
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。
数据量不大,最好在千级以内
key必须为int类型,这中情况下的HashMap可以用SparseArray代替:
ArrayMap
ArrayMap是一个key,value映射的数据结构,它设计上更多的是考虑内存的优化,内部是使用两个数组进行数据存储,一个数组记录key的hash值,另外一个数组记录Value值,它和SparseArray一样,也会对key使用二分法进行从小到大排序,在添加、删除、查找数据的时候都是先使用二分查找法得到相应的index,然后通过index来进行添加、查找、删除等操作,所以,应用场景和SparseArray的一样,如果在数据量比较大的情况下,那么它的性能将退化至少50%。
它使用两个数组来存储数据——一个整型数组存储键的哈希值,另一个对象数组存储键/值对。这样既能避免为每个存入 map 中的键创建额外的对象,还能试图更积极地控制这些数组的长度的增加(因为增加长度只需拷贝数组中的键,而不是重新构建一个哈希表)
需要注意的是,ArraryMap 并不适用于可能含有大量条目的数据类型。它通常比 HashMap 要慢,因为在查找时需要进行二分查找,增加或删除时,需要在数组中插入或删除键。对于一个最多含有几百条目的容器来说,它们的性能差异并不巨大,相差不到 50%。
同样有两个特殊的方法
public K keyAt(int index)
public V valueAt(int index)ArrayMap应用场景
数据量不大,最好在千级以内
数据结构类型为Map类型
注意 Api19以下需要导入support包
import android.support.v4.util.ArrayMap;
总结
如果key的类型已经确定为int类型,那么使用SparseArray,因为它避免了自动装箱的过程,如果key为long类型,它还提供了一个LongSparseArray来确保key为long类型时的使用
如果key类型为其它的类型,则使用ArrayMap















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









