







 本文详细介绍了如何从零开始使用C++实现BP神经网络,包括前向传播和反向传播过程,以及训练和测试阶段。通过实例解析了常见错误和解决方法,并提供了C++代码实现。
本文详细介绍了如何从零开始使用C++实现BP神经网络,包括前向传播和反向传播过程,以及训练和测试阶段。通过实例解析了常见错误和解决方法,并提供了C++代码实现。
BP(backward propogation)神经网络
简单理解,神经网络就是一种高端的拟合技术。教程也非常多,但实际上个人觉得看看斯坦福的相关学习资料就足够,并且国内都有比较好的翻译:- 人工神经网络概论,直接翻译与斯坦福教程:《神经网络 - Ufldl》
- BP原理,直接翻译与斯坦福教程:《反向传导算法 - Ufldl》
- 网上公开课笔记:《Andrew Ng Machine Learning 专题【Neural Networks】下》
三篇文章,详细的数学推导已经在里面,不赘述了。下面记录我在实现过程中碰到的一些总结与错误.
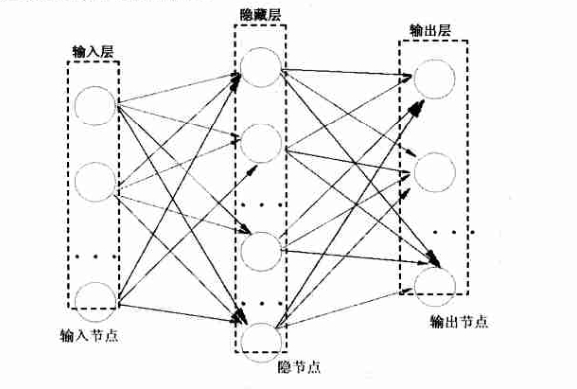
神经网络的过程
- 简单说,就是我有一堆已知的输入向量(每个向量可能有多维),每次读取一个向量(可能会有多维度),每个特征维度成为上图的输入层中一个输入节点。
- 每个维度的数值,将自己的一部分按照权值分配送给隐藏层。写程序时第一次的权值怎么办呢?其实(-1,1)随机化(绝不是0~1随机化)就好了,后续会逐渐修正。
- 这样隐含层每个节点同样有了自己的数值,同样道理,乘以权值再经过激活函数(根据需求选择,分类问题一般是 sigmoid 函数,数值拟合一般是 purelin 函数,也有特殊函数),最后传给输出节点。每个输出节点的每个值对应输出向量的一个特征维度
至此,我们完成了一次 forward pass 过程,方向是:输入层 ⇒ 输出层。
- 熟悉神经网络的同学肯定知道,神经网络使用时有“训练”、“测试”两部分。我们现在考虑训练过程。每次 forward pass 过程之后,输出层的值与真实值之间,存在一个差,这个差记为 δ 。 此时我们根据公式,将误差作为参数传给隐藏层节点。
- 这些误差有什么用呢?还记得我们各个层之间的随机化的权值么?就是用来修正这个权值的。同理,修改输入层与隐藏层之间的权值,我们的视角到达输入层。
至此,我们完成了一次 backward pass 过程,方向是:输入层 ⇐ 输出层。
第一个样本的一套做完了,即 forward pass + backward pass。
接下来呢?再做第二个样本的一套,并把误差与上一个样本误差相加;第三个样本的一套,加误差;……第N个样本的一套,加误差。等到所有样本都过了一遍,看误差和是否小于阈值(根据实际情况自由设定)时。如果不小于则进行下一整套样本,即:- 清零误差;第一个样本,加误差;第二个样本,加误差;……第N个样本,加误差。误差和是否小于阈值……
- 误差和达到阈值,妥了,不训练了
此时输入一个测试样本,将各个特征维度的数值输入到输入层节点,一次 forward pass,得到的输出值就是我们的预测值。
易错点
既然这么通俗易懂,为什么实现中会出现错误呢?下面说说几个遇到的错误:- 输入节点,究竟是每个样本的特征维度一个节点?还是每个样本一个节点?以为每个样本对应一个输出节点,是错误的。答案是每个特征一个输入节点;
- bias 必不可少!bias 是一个数值偏移量,不受上一层神经元的影响,在每个神经元汇总上一层的信息之后,都需要进行偏移之后再作为激活函数的输入。开头教程中有说明,这是为什么呢?举个例子,如果我们学习 XOR 问题,2个输入节点是0、0,如果没有 bias 所有隐含层节点都是同一个值,产生对称失效问题;
- 神经网络有多少隐含层、每个隐含层多少神经元、学习效率,都是需要调试的。没有确解,但要保证每次循环中,样本的误差和呈下降趋势
最后,是我自己的C++实现代码:
- BP神经网络的头文件:
#pragma once
#include <iostream>
#include <cmath>
#include <vector>
#include <stdlib.h>
#include <time.h>
using namespace std;
#define innode 2 //输入结点数
#define hidenode 4 //隐含结点数
#define hidelayer 1 //隐含层数
#define outnode 1 //输出结点数
#define learningRate 0.9//学习速率,alpha
// --- -1~1 随机数产生器 ---
inline double get_11Random() // -1 ~ 1
{
return ((2.0*(double)rand()/RAND_MAX) - 1);
}
// --- sigmoid 函数 ---
inline double sigmoid(double x)
{
double ans = 1 / (1+exp(-x));
return ans;
}
// --- 输入层节点。包含以下分量:---
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









