






先来一张测试结果截图:
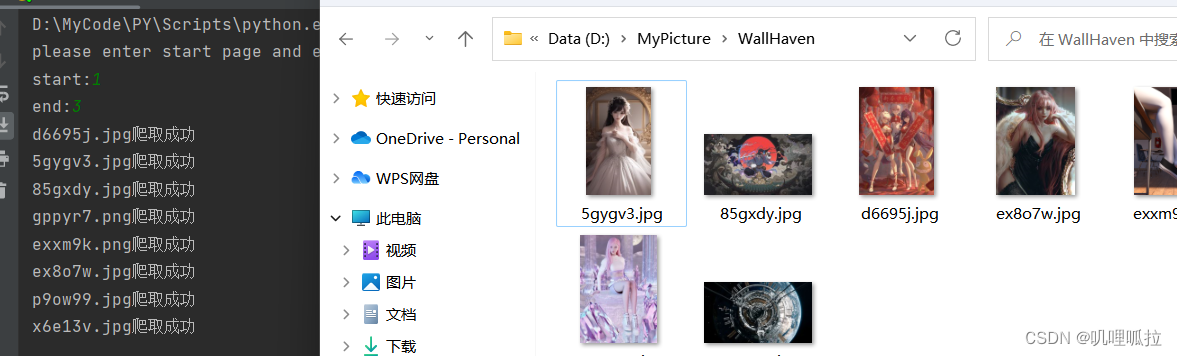
这里使用的是requests和xpath
先安装所需要的requests和lxml包,这个就不多说了
然后开始书写代码,关键的内容在代码中都有注释,这里只是简单介绍流程
由于要爬取的是很多页的,所以设置一个起始页和终止页,对主函数进行循环调用
if __name__ == "__main__": #程序主入口 用于输入需要爬取的起始页和终止页
print("please enter start page and end page:")
start = int(input("start:"))
end = int(input("end:"))
for i in range(start, end + 1): #循环执行main函数
main(i)
print('completed')然后就是主函数,主要存储一些关键信息(网址、头等等)和调用各个函数
def main(i):
#wallhaven排行榜网址
url = 'https://wallhaven.cc/toplist?page='+str(i)
#用于伪装的headers信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
li_list=get_li_list(url,headers) #调用get_li_list函数用于获取每个缩略图所在的li标签
for li in li_list: #对每个li标签再次进行操作 提取href属性值(即缩略图网址)
href=li.xpath('./figure/a/@href')[0]
src=get_src(href,headers) #在href所在的网址中提取出原图的src地址
save(src,headers) #保存图片
模拟浏览器对网页发出请求,获得响应,解析网页并返回tree
def get_etree(url,headers):
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
text = response.text
tree = etree.HTML(text)
return tree #返回解析后的tree提取关键标签和网址(此处用的是xpath,我个人觉得比较方便)
def get_li_list(url,headers):
tree = get_etree(url,headers) #获得解析后的tree
return tree.xpath('//*[@id="thumbs"]/section/ul/li') #返回提取出的的li标签
def get_src(href,headers):
tree = get_etree(href,headers)
return tree.xpath('/html/body/main/section/div[1]/img/@src')[0] #提取src最后就是保存图片,保存位置可随意愿自行修改
def save(src,headers):
response=requests.get(url=src,headers=headers)
img=response.content #图片存储为二进制格式
name=src.split('-')[1] #从src中切出独特的图片序列用做图片名称
path = 'D:\\MyPicture\\WallHaven\\' + name #存储地址可自行修改
with open(path, 'wb') as p:
p.write(img)
print(name + '爬取成功')完整代码:
import requests
from lxml import etree
#这里选取的是网站是wallhaven
def get_etree(url,headers):
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
text = response.text
tree = etree.HTML(text)
return tree #返回解析后的tree
def get_li_list(url,headers):
tree = get_etree(url,headers) #获得解析后的tree
return tree.xpath('//*[@id="thumbs"]/section/ul/li') #返回提取出的的li标签
def get_src(href,headers):
tree = get_etree(href,headers)
return tree.xpath('/html/body/main/section/div[1]/img/@src')[0] #提取src
def save(src,headers):
response=requests.get(url=src,headers=headers)
img=response.content #图片存储为二进制格式
name=src.split('-')[1] #从src中切出独特的图片序列用做图片名称
path = 'D:\\MyPicture\\WallHaven\\' + name #存储地址可自行修改
with open(path, 'wb') as p:
p.write(img)
print(name + '爬取成功')
'''限制级的图片需要账号信息,比较简单的方式就是添加cookies属性,可自行修改'''
def main(i):
#wallhaven排行榜网址
url = 'https://wallhaven.cc/toplist?page='+str(i)
#用于伪装的headers信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
li_list=get_li_list(url,headers) #调用get_li_list函数用于获取每个缩略图所在的li标签
for li in li_list: #对每个li标签再次进行操作 提取href属性值(即缩略图网址)
href=li.xpath('./figure/a/@href')[0]
src=get_src(href,headers) #在href所在的网址中提取出原图的src地址
save(src,headers) #保存图片
if __name__ == "__main__": #程序主入口 用于输入需要爬取的起始页和终止页
print("please enter start page and end page:")
start = int(input("start:"))
end = int(input("end:"))
for i in range(start, end + 1): #循环执行main函数
main(i)
print('completed')
内容仅供参考
















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











