






转载注明出处!
《The Apache Modules Book:Application Development with Apache》Nick Kew
第一版 2007-05-17
翻译难免有错误,因此把英文原文贴上.有翻译错误请与我联系,非常谢谢!
版权所有,yacsha(wangcheng711@gmail.com)
http://blog.csdn.net/yacsha/
第2章 apache平台和结构(翻译)
Apache runs as a permanent background task: a daemon (UNIX) or service
(Windows). Start-up is a slow and expensive operation, so for an operational server,
it is usual for Apache to start at system boot and remain permanently up. Early versions
of Apache had documented support for an inetd mode (run from a generic
superserver for every incoming request), but this mode was never appropriate for
operational use.
apache作为常驻后台程序运行(windows下是services,unix下是deamon), Apache的启动过程是一个较慢且耗费资源的操作.作为一个可操作的服务程序,我们需要让它随系统启动,常驻系统之中.早期apache版本运行在inetd模式 (运行于超级服务器上,响应所有的连接请求), 但是这种模式已经不再应用于操作性的使用.
2.1 Overview
2.1 概要
The Apache HTTP Server comprises a relatively small core, together with a number
of modules (Figure 2-1). Modules may be compiled statically into the server or,
more commonly, held in a /modules/ or /libexec/ directory and loaded dynamically
at runtime. In addition, the server relies on the Apache Portable Runtime
(APR) libraries, which provide a cross-platform operating system layer and utilities,

FIGURE 2-1
Apache architecture
so that modules don’t have to rely on non-portable operating system calls. A special-
purpose module, the Multi-Processing Module (MPM), serves to optimize
Apache for the underlying operating system. The MPM should normally be the
only module to access the operating system other than through the APR.
apache http服务器由一个相对较小的内核和一系列模块组成.这些模块可以以静态方式编译到服务进程程序中,也可以以动态库的形式加载,动态模块一般存放在/modules/或者/libexec/目录.另外apache http服务程序需要依靠apr库(注…..)运行. apr库专门用来提供跨平台,
图 2-1
apache结构
因此模块的运行不需要依靠具体的平台.mpm(多重处理模式)模块是一个特别的模块,用来针对专一的平台来优化apache. mpm模块是唯一一个需要和操作系统交道的模块,其他模块应该通过apr库来完成自己的功能.
2.2 Two-Phase Operation
2.2 两个阶段
Apache operation proceeds in two phases: start-up and operational. System start-up
takes place as root, and includes parsing the configuration file(s), loading modules,
and initializing system resources such as log files, shared memory segments, and database
connections. For normal operation, Apache relinquishes its system privileges
and runs as an unprivileged user before accepting and processing connections from
clients over the network. This basic security measure helps to prevent a simple bug
in Apache (or a module or script) from becoming a devastating system vulnerability,
like those exploited by malware such as “Code Red” and “Nimda” in MS IIS.
apache的操作处理有两个阶段.初始化阶段和运行阶段.以root方式随系统启动,解析配置文件,加载模块,初始化一些系统资源,例如日志文件,共享内存段,数据库连接.对正常的操作,apache放弃自己特权用户级别,启动非特权用户用来接受用户的服务请求.这种基本安全方法用来阻止apache(或者模块,脚本)中一些简单错误而导致的系统级别的安全问题.像用malware对ms iis进行溢出攻击的”code red(红色代码)”和”Nimda(尼姆达)”病毒.
This two-stage operation has some implications for applications architecture. First,
anything that requires system privileges must be run at system start-up. Second, it is
good practice to run as much initialization as possible at start-up, so as to minimize
the processing required to service each request. Conversely, because so many slow
and expensive operations are concentrated in system start-up, it would be hugely
inefficient to try to run Apache from a generic server such as inetd or tcpserver.
这两个阶段的操作暗示着应用程序的结构,首先,任何需要系统权限的程序都必须在系统启动时候运行(译者注:这个好像有问题???不随系统启动就拿不到系统权限??).第二,在程序启动的时候进行所有的初始化,这是一个好方法.减少在接受请求的时候进行初始化.这些耗资源和拖慢速度的操作都在程序启动的时候完成, 相比apache以inetd或者tcpserver模式运行是有效率的.
One non-intuitive quirk of the architecture is that the configuration code is, in fact,
executed twice at start-up (although not at restart). The first time through checks
that the configuration is valid (at least to the point that Apache can successfully
start); the second pass is “live” and leads into the operational phase. Most modules
can ignore this behavior (standard use of APR pools ensures that it doesn’t cause a
resource leak), but it may have implications for some modules. For example, a module
that dynamically loads new code at start-up may want to do so just once and,
therefore, must use a technique such as setting and checking a static flag to ensure
that critical initialization takes place just once.
在启动的时候执行两次配置代码是一个没有直觉,奇怪的结构(不包括重新启动服务),第一次,检查配置是不是有效(最少能让apache启动),第二次是在启动服务的时候,就是我们上面说到的第二个阶段,大多数模块都能忽略这一阶段的初始化(注:apache会以非特权用户的方式启动服务进程),通过使用apr缓存池可以避免资源泄露,这些对一些模块有一些提示,例如,一个动态加载的模块只希望运行一次初始化代码,因此我们必须使用一种方法通过设置和检查全局的一个标志变量来确保关键变量只被初始化了一次.
2.2.1 Start-up Phase
2.2.1 初始化阶段
The purpose of Apache’s start-up phase is to read the configuration, load modules
and libraries, and initialize required resources. Each module may have its own
resources, and has the opportunity to initialize those resources. At start-up, Apache
runs as a single-process, single-thread program and has full system privileges.
这个阶段用来读取配置文件,加载模块,初始化需要的资源,每个模块可能有自己需要的资源,在这个时候初始化自己需要的资源.在初始化阶段, apache以一个单进程,单线程,完全控制系统的方式运行.
2.2.1.1 Configuration
2.2.1.1 配置
Apache’s main configuration file is normally called httpd.conf. However, this
nomenclature is just a convention, and third-party Apache distributions such as
those provided as .rpm or .deb packages may use a different naming scheme. In
addition, httpd.conf may be a single file, or it may be distributed over several files
using the Include directive to include different configuration files. Some distributions
have highly intricate configurations. For example, Debian GNU/Linux ships
an Apache configuration that relies heavily on familiarity with Debian, rather than
with Apache. It is not the purpose of this book to discuss the merits of different layouts,
so we’ll simply call this configuration file httpd.conf.
httpd.conf文件是apache的主要配置文件,术语规范,第三方apache组织,像提供rpm,deb包.可能使用一个不同命名表,另外httpd.conf文件可能是单一文件,也可能是多个文件.通过使用include指令来包含不同的配置文件.一些组织有非常难懂的配置,例如对Debian GNU/Linux的apache配置,需要对Debian非常熟悉.本书不是用来谈论这种设计的优缺点,因此我们仅仅简单的把这个配置文件叫做httpd.conf.
The httpd.conf configuration file is a plain text file and is parsed line-by-line at
server start-up. The contents of httpd.conf comprise directives, containers, and
comments. Blank lines and leading whitespace are also allowed, but will be ignored.
httpd.conf文件是一个纯文本文件,在程序初始化的时候被一行一行的解析,该文件由指令,容器,注释组成.空白行是允许的,不会对配置起任何影响.
Directives
指令
Most of the contents of httpd.conf are directives. A directive may have zero or
more arguments, separated by whitespace. Each directive determines its own syntax,
so different directives may permit different numbers of arguments, and different
argument types (e.g., string, numeric, enumerated, Boolean on/off, or filename). Each
directive is implemented by some module or the core, as described in Chapter 9.
httpd.conf文件中大多数内容是指令.一个指令可以没有参数,也可以有多个参数,参数之间用空格隔开.每一个指令有自己的语法格式,不同的指令允许不同的参数个数和参数类型(有字符串 数字 枚举 布尔 或者文件名).核心和一些模块有自己支持的指令,我们在第9章中详细讨论.
For example:
LoadModule foo_module modules/mod_foo.so
This directive is implemented by mod_so and tells it to load a module. The first
argument is the module name (string, alphanumeric). The second argument is a
filename, which may be absolute or relative to the server root.
DocumentRoot /usr/local/apache/htdocs
This directive is implemented by the core, and sets the directory that is the root of
the main document tree visible from the Web.
SetEnv hello ”Hello, World!”
This directive is implemented by mod_env and sets an environment variable. Note
that because the second argument contains a space, we must surround it with quotation
marks.
Choices On
This directive is implemented by mod_choices (Chapter 6) and activates that
module’s options.
例如:
LoadModule foo_module modules/mod_foo.so
这个指令由mod_so支持,用来加载一个模块.第一个参数是模块名(字符串,数字字符).第二个参数是文件名.可以是绝对路径也可以是相对路径.
DocumentRoot /usr/local/apache/htdocs
这个指令由核心模块支持,用来设置网页根目录.
SetEnv hello “Hello, World!”
这个指令由mod_env支持,用设置环境变量.注意,第二个参数包含空格,我们必须用双引号包含起来.
Choices On
这个指令由mod_choices(第6章)支持,用来激活模块的选项.
Containers
容器
A container is a special form of directive, characterized by a syntax that superficially
resembles markup, using angle brackets. Containers differ semantically from other
directives in that they comprise a start and an end on separate lines, and they affect
directives falling between the start and the end of the container. For example, the
<VirtualHost> container is implemented by the core and defines a virtual host:
<VirtualHost 10.31.2.139>
ServerName www.example.com
DocumentRoot /usr/www/example
ServerAdmin webmaster@example.com
CustomLog /var/log/www/example.log
</VirtualHost>
一个容器是一个特定集合的指令.通过一系列简单的尖括号来归类,容器在语义上和其他指令不同,指令的开始和结束分别独立占一行.有效的指令落在开始和结束的中间.例如由内核模块实现的<VirtualHost>指令.如以下指令
<VirtualHost 10.31.2.139>
ServerName www.example.com
DocumenRoot /usr/www/example
ServerAdmin webmaster@example.com
CustomLog /var/log/www/example.log
</VirtualHost>
The container provides a context for the directives within it. In this case, the directives
apply to requests to www.example.com, but not to requests to any other
names this server responds to. Containers can be nested unless a module explicitly
prevents it. Directives, including containers, may be context sensitive, so they are
valid only in some specified type of context.
容器提供作用域的功能,里面的指令只在该作用域内生效.在上面这个例子中,指令只对访问www.example.com域名时候有效.该容器可以被嵌套,除非明确的指示不能嵌套.所有用到的指令,包括容器都是在具体的上下文中生效.
Comments
注释
Any line whose first character is a hash is read as a comment.
# This line is a comment
A hash within a directive doesn’t in general make a comment, unless the module
implementing the directive explicitly supports it.
If a module is not loaded, directives that it implements are not recognized, and
Apache will stop with a syntax error when it encounters them. Therefore mod_so
must be statically linked to load other modules. This is pretty much essential whenever
you’re developing new modules, as without LoadModule you’d have to rebuild
the entire server every time you change your module!
任何一行以#号开头都被认为是注释.
# this line is a comment
一般行中的#不会被认为是注释,除非模块明确的支持该指令.
一个模块支持的指令在模块没有被加载的时候不会生效.apache在解析这个指令的时候会遇到语法错误.因此mod_so必须以静态的方式加载,这点非常重要的!当你开发一个新模块的时候,没有LoadModule的支持,在你修正你编写的模块的时候,必须重新编译整个服务器程序!
2.2.2 Operational Phase
2.2.2 运行阶段
At the end of the start-up phase, control passes to the Multi-Processing Module (see
Section 2.3). The MPM is responsible for managing Apache’s operation at a systems
level. It typically does so by maintaining a pool of worker processes and/or threads,
as appropriate to the operating system and other applicable constraints (such as
optimization for a particular usage scenario). The original process remains as “master,”
maintaining a pool of worker children. These workers are responsible for servicing
incoming connections, while the parent process deals with creating new
children, removing surplus ones as necessary, and communicating signals such as
“shut down” or “restart.”
在初始化阶段结束的时候,程序的控制转向多进程模块(mpm)(见2.3章节),mpm在系统级别管理apache的操作.根据当前系统来管理进程池或者线程池和一些应用限制(例如对特定情节的应用).启动进程作为控制者,管理一系列子工作例程.这些工作例程用来接受用户的请求.控制者用来创建新的子工作例程,移除多余的工作例程,通过信号指示来停止或者重启服务.
Because of the MPM architecture, it is not possible to describe the operational
phase in definite terms. Whereas the standard MPMs use worker children in some
manner, they are not constrained to work in only one way. Thus another MPM
could, in principle, implement an entirely different server architecture at the system
level.
由于mpm的结构,我们不能在确定的范围内描述运行阶段.尽管标准的mpm以工作例程的方式使用,但是没有被限制只能使用这一种方式使用mpm..原理上另外一个mpm能够在系统层上实现完全不同的服务器结构.
2.2.3 Shutdown
2.2.3 停止
There is no shutdown phase as such. Instead, anything that needs be done on shutdown
is registered as a cleanup, as described in Chapter 3. When Apache stops, all
registered cleanups are run.
这里没有停止阶段,但是有一些清除工作需要完成在服务停止的时候,在第3章中描述,当apache停止的时候,所有注册的清除操作都会被执行.
2.3 Multi-Processing Modules
2.3 多重处理模块
At the end of the start-up phase, after the configuration has been read, overall control
of Apache passes to a Multi-Processing Module. The MPM provides the interface
between the running Apache server and the underlying operating system. Its
primary role is to optimize Apache for each platform, while ensuring the server runs
efficiently and securely.
在初始化结束阶段,所有的配置也被解析后,apache的控制转到mpm控制模块,mpm提供apache服务程序和操作系统之间的接口,该模块的主要职责是优化apache适应当前的操作系统平台,确保apache能够足够安全和有效率.
As indicated by the name, the MPM is itself a module. But the MPM is uniquely
a systems-level module (so developing an MPM falls outside the scope of a book on
applications development). Also uniquely, every Apache instance must contain
exactly one MPM, which is selected at build-time.
通过名字我们能看出,mpm自身也是一个模块.但是mpm是一个唯一的系统层模块(因此开发mpm已经超出本书关于应用程序开发),每一个apche实例在编译的时候必须包含一个准确唯一的mpm模块.
2.3.1 Why MPMs?
2.3.1 为什么有多种mpm模块?
The old NCSA server, and Apache 1, grew up in a UNIX environment. It was a
multiprocess server, where each client would be serviced by one server instance. If
there were more concurrent clients than server processes, Apache would fork additional
server processes to deal with them. Under normal operation, Apache would
maintain a pool of available server processes to deal with incoming requests.
老版本的NCSA server和apache 1在unix环境下产生.是一个多进程服务器,一个服务例程服务一个请求.如果当前并发客户访问数量大于服务进程数,apache会产生相应的服务进程数来完成当前请求.在正常情况下,apache会维护一定数量的服务进程来处理用户的请求.
Whereas this scheme works well on UNIX-family1 systems, it is an inefficient solution
on platforms such as Windows, where forking a process is an expensive operation.
So making Apache truly cross-platform required another solution. The
approach adopted for Apache 2 is to turn the core processing into a pluggable module,
the MPM, which can be optimized for different environments. The MPM
architecture also allows different Apache models to coexist even within a single
operating system, thus providing users with options for different usages.
尽管在unix类(注1)系统下该调度方法能很好的工作,但是在windows下显得不够有效率.windows下产生一个进程是非常费时的过程.因此让apache在各个平台上都有效率,我们需要另外一些方法.被apache2采纳的方法是让内核能够处理以模块方式插入的mpm,能被优化适应不同的环境.mpm的结构也允许不同的apache模块在一个操作系统平台下共存,能够给用户提供各种使用用途.
1. Here and elsewhere in this book, terms such as “UNIX-family” imply both UNIX itself and other POSIX-centered operating systems such as Linux and MacOSX.
注1:在本书中提到的unix类,包括unix系统和其他posix操作系统,例如linux和macosx
In practice, only UNIX-family operating systems offer a useful2 choice: Other supported
platforms (Windows, Netware, OS/2, BeOS) have a single MPM optimized
for each platform. UNIX has two production-quality MPMs (Prefork and Worker)
available as standard, a third (Event) that is thought to be stable for non-SSL uses
in Apache 2.2, and several experimental options unsuitable for production use.
Third-party MPMs are also available.
在实际中,仅仅unix类操作系统提供了一个有用的选择:其他支持平台(Windows,Netware,OS/2,BeOS)只有一个单一的mpm优化.在unix平台上,apache2.2目前已经有两种产品化的,有效率的mpm方式(prefork和worker),第三种(event方式)被认为是稳定的除了不支持ssl,另外其他一些实验中的mpm方式不适合加入产品中.第三方mpm模块也可以使用.
2.3.2 The UNIX-Family MPMs
2.3.2 unix类的mpm模块
• The Prefork MPM is a nonthreaded model essentially similar to Apache 1.x.
It is a safe option in all cases, and for servers running non-thread-safe software
such as PHP, it is the only safe option. For some applications, including many
of those popular with Apache 1.3 (e.g., simple static pages, CGI scripts), this
MPM may be as good as anything.3
• The Worker MPM is a threaded model, whose advantages include lower
memory usage (important on busy servers) and much greater scalability than
that provided by Prefork in certain types of applications. We will discuss some
of these cases later when we introduce SQL database support and mod_dbd.
• Both of the stable MPMs suffer from a limitation that affects very busy servers.
Whereas HTTP Keepalive is necessary to reduce TCP connection and network
overhead, it ties up a server process or thread while the keepalive is active.
As a consequence, a very busy server may run out of available threads. The
Event MPM is a new model that deals with this problem by decoupling the
server thread from the connection. Cases where the Event MPM may prove
most useful are servers with extremely high hit rates but for which the server
processing is fast, so that the number of available threads is a critical resource
limitation. A busy server with the Worker MPM may sustain tens of thousands
of hits per second (as happens, for example, with popular news outlets at peak
times), but the Event MPM might help to handle high loads more easily. Note
that the Event MPM will not work with secure HTTP (HTTPS).
• There are also several experimental MPMs for UNIX that are not, at the time
of this book’s writing, under active development; they may or may not ever be
completed. The Perchild MPM promised a much-requested feature: It runs
servers for different virtual hosts under different user IDs. Several alternatives
offer similar features, including the third-party Metux4 and Peruser5 MPMs,
and (for Linux only) mod_ruid.6 For running external programs, other options
include fastcgi/mod_fcgid7 and suexec (CGI). The author does not have
personal knowledge of these third-party solutions and so cannot make recommendations
about them.
• prefork mpm和apache1.x版本中的mpm本质相似,没有线程.在所有情况下都很安全.对运行安全没有线程(non-thread-safe)模式软件,例如php,这是唯一的安全配置选项.对一些扩展程序,包括在apache1.3上非常流行的扩展程序(例如,简单静态文件,cgi脚本),这种mpm模式是最好的选择.
• worker mpm是一种线程模式,有以下优点,耗用内存低(对繁忙的服务很重要),在特定的服务类型上相比prefork有更好的测量性.我们稍后会讨论其中一些情况在我们介绍sql数据库支持和mod_dbd.
• 以上两种mpm方式的稳定性取决于服务器的繁忙程度.尽管http的keepalive能减少tcp连接和网络负载.但是keepalive和一个具体的服务进程或者线程绑定,结果在一个繁忙的机器上没有更多的资源来产生更多的进程或者线程来保持keepalive服务.event mpm是一种新方式,用来解决把服务进程从连接中分身出来.事实证明event mpm方式是最有用的,在有很高访问率,服务处理的速度之快,导致一个系统能产生最大线程数成为关键瓶颈.在一个以worker mpm方式工作的繁忙服务器上可能能承受每秒好几万的访问量(例如在大型新闻服务站点的高峰时候可能发生),但是event mpm可能帮助我们处理高负载更容易.注意event mpm不能在安全http(https)访问下工作.
• 这里也有一些针对unix实验中的的mpm方式,在本书编写过程中,有的在继续开发,有的已经停止开发了.有可能实现,也有可能不会被实现.perchild mpm方式承诺有很好的处理多请求的能力.以不用的用户id在不同的虚拟主机下运行.一些可选择的mpm也提供的相同的功能.包括第三方的Metux和Peruser mpm方式,还有mod_ruid(只支持linux),为了运行外部程序,可选择的有fastcgi/mod_fcgid和suexec(CGI).作者对第三方的解决方案没有相应的了解,不能做出相应的建议.
2. MPMs are not necessarily tied to an operating system (most systems have some kind of POSIX support
and might be able to use it to run Prefork, for instance). But if you try to build Apache with a “foreign”
MPM, you’re on your own!
3. This depends on the platform. On Linux versions without NPTL, Prefork is commonly reported to be as
fast as Worker. On Solaris, Worker is reported to be much faster than Prefork. Your mileage may vary.
………………………(注释没有翻译)
2.3.3 Working with MPMs and Operating Systems
2.3.3 mpm模块和操作系统协作
The one-sentence summary: MPMs are invisible to applications and should be ignored!
一句话总结:mpm方式对应用程序不可见,我们忽略它!
Applications developed for Apache should normally be MPM-agnostic. Given that
MPM internals are not part of the API, this is basically straightforward, provided
programmers observe basic rules of good practice (namely, write thread-safe, crossprocess-
safe, reentrant code), as briefly discussed in Chapter 4. This issue is closely
related to the broader question of developing platform-independent code. Indeed,
it is sometimes useful to regard the MPM, rather than the operating system, as the
applications platform.
apache的应用开发者不需要知道mpm的细节.mpm的内部不是api的一部分,简单易懂的提供在实际操作(线程安全,进程安全,代码重入)中的基本原理,这些将会在第4章中简单描述.非常接近在泛泛而谈开发平台无关代码的问题.事实上,在开发扩展程序的时候考虑mpm比考虑操作系统有时候更有好处.
Sometimes an application is naturally better suited to some MPMs than others. For
example, database-driven or load-balancing applications benefit substantially from
connection pooling (discussed later in this book) and therefore from a threaded
MPM. In contrast, forking a child process (the original CGI implementation or
mod_ext_filter) creates greater overhead in a threaded program and, therefore,
works best with the Prefork MPM. Nevertheless, an application should work even
when used with a suboptimal MPM, unless there are compelling reasons to limit it.
有时候扩展程序适应一些mpm比适应其他东西更好些.例如,数据驱动或者加载平衡程序得益于连接池(在本书稍后讨论),在thread mpm方式中.相比之下,产生子进程(原始的cgi实现或者mod_ext_filter)会产生巨大开销在一个基于线程的程序中.因此在prefork mpm方式下工作的更好. 除非有强迫性的原因在限制程序在工作在使用不理想的mpm方式下.
If you wish to run Apache on an operating system that is not yet supported, the
main task is to add support for your target platform to the APR, which provides the
operating system layer. A custom MPM may or may not be necessary, but is likely
to deliver better performance than an existing one. From the point of view of
Apache, this is a systems programming task, and hence it falls outside the scope of
an applications development book.
如果你希望让apache运行在现在还不支持的系统上,主要的任务是增加对平台的支持到apr库中.apr库用来提供操作系统层的支持.当前mpm可以需要也可以不需要.但是好像提供一个好性能的服务程序比仅仅能运行的服务程序要好很多,总观apache,这是一个系统界别的任务,它已经超出一本应用程序开发书籍的讲述范围.
4. http://www.metux.de/mpm/
5. http://www.telana.com/peruser.php
6. http://websupport.sk/~stanojr/projects/mod_ruid/
7. http://fastcgi.coremail.cn/
注释没有翻译
2.4 Basic Concepts and Structures
2.4 基本概念和数据结构
To work with Apache as a development platform, we need an overview of the basic
units of webserver operation and the core objects that represent them within Apache.
The most important are the server, the TCP connection, and the HTTP request. A
fourth basic Apache object, the process, is a unit of the operating system rather than
the application architecture. Each of these basic units is represented by a core data
structure defined in the header file httpd.h and, like other core objects we encounter
in applications development, is completely independent of the MPM in use.
想在apache平台之上做开发,我们需要对基本的web服务器的操作和apache内部的核心结构有大致的了解.最重要的是server, tcp 连接, http请求.相比应用程序的结构,第四个是apache基本对象是进程.操作系统的一个执行单元.每一个基本单元由一个核心数据结构表示.在httpd.h头文件中定义.在扩展程序的开发中,我们遇到的一些核心结构完全不受mpm的约束.
Before describing these core data structures, we need to introduce some further concepts
used throughout Apache and closely tied to the architecture:
• APR pools (apr_pool_t) are the core of resource management in Apache.
Whenever a resource is allocated dynamically, a cleanup is registered with a
pool, ensuring that system resources are freed when they are no longer
required. Pools tie resources to the lifetime of one of the core objects. We will
describe pools in depth in Chapter 3.
• Configuration records are used by each module to tie its own data to one of
the core objects. The core data structures include configuration vectors
(ap_conf_vector_t), with each module having its own entry in the vector.
They are used in two ways: to set and retrieve permanent configuration data,
and to store temporary data associated with a transient object. They are often
essential to avoid use of unsafe static or global data in a module, as discussed
in Chapters 4 and 9.
在描述这些核心结构之前,我们需要介绍贯穿在整个apache当中,而且和体系结构紧密关联的概念:
• apr pools(apr_pool_t)是apache中资源管理的核心.无论何时动态分配资源,对pool注册一个清除回调,当他们不再需要的时候确保系统资源能够被释放.pools绑定资源到一个内核对象的生命周期当中.我们会在第3章中深入讨论pools
• 配置记录被每一个模块使用,绑定自己的数据到一个内核数据当中,内核数据结构包括配置vectors(ap_conf_vector_t),在vectors中每一个模块有自己的入口,这里有两种使用方式,设置和获取全局的配置数据.保存临时数据到临时的对象中.在一个模块中应该尽量避免不安全的静态变量和全局变量.我们将在第4和第9章中讨论.
Having introduced pools and configuration records, we are now ready to look at the
Apache core objects. In order of importance to most modules, they are
• request_rec
• server_rec
• conn_rec
• process_rec
已经简单介绍完pools和配置数据,我们现在来解开apache核心结构.按照对大多数模块重要性的排列,它们是:
• request_rec
• server_rec
• conn_rec
• process_rec
The first two are by far the most commonly encountered in application development.
在应用程序开发中,到目前为止,前两种是经常遇到的.
2.4.1 request_rec
2.4.1 request_rec
A request_rec object is created whenever Apache accepts an HTTP request from
a client, and is destroyed as soon as Apache finishes processing the request. The
request_rec object is passed to every handler implemented by any module in the
course of processing a request (as discussed in Chapters 5 and 6). It holds all of the
internal data relevant to processing an HTTP request. It also includes a number of
fields used internally to maintain state and client information by Apache:
• A request pool, for management of objects having the lifetime of the request.
It is used to manage resources allocated while processing the request.
• A vector of configuration records for static request configuration (per-directory
data specified in httpd.conf or .htaccess).
• A vector of configuration records for transient data used in processing.
• Tables of HTTP input, output, and error headers.
• A table of Apache environment variables (the environment as seen in scripting
extensions such as SSI, CGI, mod_rewrite, and PHP), and a similar “notes”
table for request data that should not be seen by scripts.
• Pointers to all other relevant objects, including the connection, the server, and
any related request objects.
• Pointers to the input and output filter chains (discussed in Chapter 8).
• The URI requested, and the internal parsed representation of it, including the
handler (see Chapter 5) and filesystem mapping (see Chapter 6).
Here is the full definition, from httpd.h:
一个request_rec对象,在apache接受连接请求的时候创建.在处理完请求之后马上销毁该对象. request_rec对象被传递到位于处理请求链(在第5和6章中讨论)每一个模块中的处理例程中,这个对象保存所有涉及处理该请求的内部数据.也包括apache用来维护中间状态和客户端信息的一系列字段:
• 请求池,管理在处理请求周期中的对象.
• 配置记录vector,静态请求配置(在httpd.conf或者.htaccess中指定的目录访问权限)
• 在处理请求过程中临时的配置记录vector
• http输入头,输出头,错误信息头表
• apache环境变量表(像SSI,CGI,mod_rewrite,PHP脚本处理扩展中用到的环境变量),还有一个相似的记录请求数据的提示表,该表对脚本不可见.
• 指向其他相关对象的指针.包括connection,server和任何一个相关的请求对象.
• 指向输入输出过滤链(在第8章中讨论)
• URI请求和其中间解析形式.包括处理例程(见第5章)和文件系统映射(见第6章)
这是在httpd.h文件中的完整定义:
/** A structure that represents the current request */
struct request_rec {
/** The pool associated with the request */
apr_pool_t *pool;
/** The connection to the client */
conn_rec *connection;
/** The virtual host for this request */
server_rec *server;
/** Pointer to the redirected request if this is an external redirect */
request_rec *next;
/** Pointer to the previous request if this is an internal redirect */
request_rec *prev;
/** Pointer to the main request if this is a sub-request
* (see http_request.h) */
request_rec *main;
/* Info about the request itself... we begin with stuff that only
* protocol.c should ever touch...
*/
/** First line of request */
char *the_request;
/** HTTP/0.9, "simple” request (e.g., GET /foo/n w/no headers) */
int assbackwards;
/** A proxy request (calculated during post_read_request/translate_name)
* possible values PROXYREQ_NONE, PROXYREQ_PROXY, PROXYREQ_REVERSE,
* PROXYREQ_RESPONSE
*/
int proxyreq;
/** HEAD request, as opposed to GET */
int header_only;
/** Protocol string, as given to us, or HTTP/0.9 */
char *protocol;
/** Protocol version number of protocol; 1.1 = 1001 */
int proto_num;
/** Host, as set by full URI or Host: */
const char *hostname;
/** Time when the request started */
apr_time_t request_time;
/** Status line, if set by script */
const char *status_line;
/** Status line */
int status;
/* Request method, two ways; also, protocol, etc. Outside of protocol.c,
* look, but don’t touch.
*/
/** Request method (e.g., GET, HEAD, POST, etc.) */
const char *method;
/** M_GET, M_POST, etc. */
int method_number;
/**
* ‘allowed’ is a bit-vector of the allowed methods.
*
* A handler must ensure that the request method is one that
* it is capable of handling. Generally modules should DECLINE
* any request methods they do not handle. Prior to aborting the
* handler like this, the handler should set r->allowed to the list
* of methods that it is willing to handle. This bitvector is used
* to construct the "Allow:" header required for OPTIONS requests,
* and HTTP_METHOD_NOT_ALLOWED and HTTP_NOT_IMPLEMENTED status codes.
*
* Since the default_handler deals with OPTIONS, all modules can
* usually decline to deal with OPTIONS. TRACE is always allowed;
* modules don’t need to set it explicitly.
*
* Since the default_handler will always handle a GET, a
* module which does *not* implement GET should probably return
* HTTP_METHOD_NOT_ALLOWED. Unfortunately this means that a Script GET
* handler can’t be installed by mod_actions.
*/
apr_int64_t allowed;
/** Array of extension methods */
apr_array_header_t *allowed_xmethods;
/** List of allowed methods */
ap_method_list_t *allowed_methods;
/** byte count in stream is for body */
apr_off_t sent_bodyct;
/** body byte count, for easy access */
apr_off_t bytes_sent;
/** Last modified time of the requested resource */
apr_time_t mtime;
/* HTTP/1.1 connection-level features */
/**Sending chunked transfer-coding */
int chunked;
/** The Range: header */
const char *range;
/** The "real" content length */
apr_off_t clength;
/** Remaining bytes left to read from the request body */
apr_off_t remaining;
/** Number of bytes that have been read from the request body */
apr_off_t read_length;
/** Method for reading the request body
* (e.g., REQUEST_CHUNKED_ERROR, REQUEST_NO_BODY,
* REQUEST_CHUNKED_DECHUNK, etc.) */
int read_body;
/** reading chunked transfer-coding */
int read_chunked;
/** is client waiting for a 100 response? */
unsigned expecting_100;
/* MIME header environments, in and out. Also, an array containing
* environment variables to be passed to subprocesses, so people can
* write modules to add to that environment.
*
* The difference between headers_out and err_headers_out is that the
* latter are printed even on error, and persist across internal redirects
* (so the headers printed for ErrorDocument handlers will have them).
*
* The ‘notes’ apr_table_t is for notes from one module to another, with no
* other set purpose in mind...
*/
/** MIME header environment from the request */
apr_table_t *headers_in;
/** MIME header environment for the response */
apr_table_t *headers_out;
/** MIME header environment for the response, printed even on errors and
* persist across internal redirects */
apr_table_t *err_headers_out;
/** Array of environment variables to be used for subprocesses */
apr_table_t *subprocess_env;
/** Notes from one module to another */
apr_table_t *notes;
/* content_type, handler, content_encoding, and all content_languages
* MUST be lowercased strings. They may be pointers to static strings;
* they should not be modified in place.
*/
/** The content-type for the current request */
const char *content_type; /* Break these out -- we dispatch on ‘em */
/** The handler string that we use to call a handler function */
const char *handler; /* What we *really* dispatch on */
/** How to encode the data */
const char *content_encoding;
/** Array of strings representing the content languages */
apr_array_header_t *content_languages;
/** variant list validator (if negotiated) */
char *vlist_validator;
/** If an authentication check was made, this gets set to the user name. */
char *user;
/** If an authentication check was made, this gets set to the auth type. */
char *ap_auth_type;
/** This response cannot be cached */
int no_cache;
/** There is no local copy of this response */
int no_local_copy;
/* What object is being requested (either directly, or via include
* or content-negotiation mapping).
*/
/** The URI without any parsing performed */
char *unparsed_uri;
/** The path portion of the URI */
char *uri;
/** The filename on disk corresponding to this response */
char *filename;
/** The true filename, we canonicalize r->filename if these don’t match */
char *canonical_filename;
/** The PATH_INFO extracted from this request */
char *path_info;
/** The QUERY_ARGS extracted from this request */
char *args;
/** finfo.protection (st_mode) set to zero if no such file */
apr_finfo_t finfo;
/** A struct containing the components of URI */
apr_uri_t parsed_uri;
/**
* Flag for the handler to accept or reject path_info on
* the current request. All modules should respect the
* AP_REQ_ACCEPT_PATH_INFO and AP_REQ_REJECT_PATH_INFO
* values, while AP_REQ_DEFAULT_PATH_INFO indicates they
* may follow existing conventions. This is set to the
* user’s preference upon HOOK_VERY_FIRST of the fixups.
*/
int used_path_info;
/* Various other config info which may change with .htaccess files.
* These are config vectors, with one void* pointer for each module
* (the thing pointed to being the module’s business).
*/
/** Options set in config files, etc. */
struct ap_conf_vector_t *per_dir_config;
/** Notes on *this* request */
struct ap_conf_vector_t *request_config;
/**
* A linked list of the .htaccess configuration directives
* accessed by this request.
* N.B.: always add to the head of the list, _never_ to the end.
* That way, a sub-request’s list can (temporarily) point to a parent’s list
*/
const struct htaccess_result *htaccess;
/** A list of output filters to be used for this request */
struct ap_filter_t *output_filters;
/** A list of input filters to be used for this request */
struct ap_filter_t *input_filters;
/** A list of protocol level output filters to be used for this
* request */
struct ap_filter_t *proto_output_filters;
/** A list of protocol level input filters to be used for this
* request */
struct ap_filter_t *proto_input_filters;
/** A flag to determine if the eos bucket has been sent yet */
int eos_sent;
/* Things placed at the end of the record to avoid breaking binary
* compatibility. It would be nice to remember to reorder the entire
* record to improve 64-bit alignment the next time we need to break
* binary compatibility for some other reason.
*/
};
2.4.2 server_rec
2.4.2 server_rec
The server_rec defines a logical webserver. If virtual hosts are in use,8 each virtual
host has its own server_rec, defining it independently of the other hosts. The
server_rec is created at server start-up, and it never dies unless the entire httpd
is shut down. The server_rec does not have its own pool; instead, server resources
need to be allocated from the process pool, which is shared by all servers. It does
have a configuration vector as well as server resources including the server name and
definition, resources and limits, and logging information.
The server_rec is the second most important structure to programmers, after the
request_rec. It will feature prominently throughout our discussion of module
programming.
Here is the full definition, from httpd.h:
server_rec定义了一个逻辑web服务器结构,如果在使用虚拟主机,每一个虚拟主机都有自己的server_rec结构,并且和其他主机独立, server_rec在服务器初始化的时候创建,直到服务器关闭的时候被销毁. server_rec没有自己的缓冲池,相反,服务器资源需要从所有服务器共享的进程池中分配.有一个配置向量,也有包括服务器名字,定义,资源,限制,日志信息的服务器资源.
对程序员来讲,server_rec是第二重要的结构,在request_rec之后.在整个讨论模块编程的过程中, server_rec有着显著的重要作用.
下面是在httpd.h文件中的完整定义:
/** A structure to store information for each virtual server */
struct server_rec {
/** The process this server is running in */
process_rec *process;
/** The next server in the list */
server_rec *next;
/** The name of the server */
const char *defn_name;
/** The line of the config file that the server was defined on */
unsigned defn_line_number;
/* Contact information */
/** The admin’s contact information */
char *server_admin;
/** The server hostname */
char *server_hostname;
/** for redirects, etc. */
apr_port_t port;
/* Log files -- note that transfer log is now in the modules... */
/** The name of the error log */
char *error_fname;
/** A file descriptor that references the error log */
apr_file_t *error_log;
/** The log level for this server */
int loglevel;
/* Module-specific configuration for server, and defaults... */
/** true if this is the virtual server */
int is_virtual;
/** Config vector containing pointers to modules' per-server config
* structures. */
struct ap_conf_vector_t *module_config;
/** MIME type info, etc., before we start checking per-directory info */
struct ap_conf_vector_t *lookup_defaults;
/* Transaction handling */
/** I haven't got a clue */
server_addr_rec *addrs;
/** Timeout, as an apr interval, before we give up */
apr_interval_time_t timeout;
/** The apr interval we will wait for another request */
apr_interval_time_t keep_alive_timeout;
/** Maximum requests per connection */
int keep_alive_max;
/** Use persistent connections? */
int keep_alive;
/** Pathname for ServerPath */
const char *path;
/** Length of path */
int pathlen;
/** Normal names for ServerAlias servers */
apr_array_header_t *names;
/** Wildcarded names for ServerAlias servers */
apr_array_header_t *wild_names;
/** limit on size of the HTTP request line */
int limit_req_line;
/** limit on size of any request header field */
int limit_req_fieldsize;
/** limit on number of request header fields */
int limit_req_fields;
};
2.4.3 conn_rec
2.4.3 conn_rec
The conn_rec object is Apache’s internal representation of a TCP connection. It is
created when Apache accepts a connection from a client, and later it is destroyed
when the connection is closed. The usual reason for a connection to be made is to
serve one or more HTTP requests, so one or more request_rec structures will be
instantiated from each conn_rec. Most applications will focus on the request and
ignore the conn_rec, but protocol modules and connection-level filters will need to
use the conn_rec, and modules may sometimes use it in tasks such as optimizing
the use of resources over the lifetime of an HTTP Keepalive (persistent connection).
The conn_rec has no configuration information, but has a configuration vector for
transient data associated with a connection as well as a pool for connection
resources. It also has connection input and output filter chains, plus data describing
the TCP connection.
It is important to distinguish clearly between the request and the connection—the
former is always a subcomponent of the latter. Apache cleanly represents each as a
separate object, with one important exception, which we will deal with in discussing
connection filters in Chapter 8.
Here is the full definition from httpd.h:
conn_rec是apache内部用来表示tcp连接的对象,在apache接受客户连接请求的时候创建,在连接被关闭的时候,对象被销毁.在通常情况下,一个连接服务一个或者更多请求,因此一个或者更多request_rec被创建对应一个conn_rec.大多数应用程序重点放在请求上,忽略conn_rec,但是协议模块和连接层过滤器需要使用conn_rec,有时候模块在一些任务中使用它,例如,优化在一个http keepalive(持续性连接)生命周期中的资源使用.
conn_rec没有配置信息,但是有一个配置向量为连接的临时数据和连接资源池,也有连接输入输出过滤链,加上描述tcp连接的描述信息.
清晰的分清请求和连接是非常重要的.前者往往是后者的子集.apache明白的展示这两个作为独立的对象,除了一个重要的例外情况,我们在第8章讨论讨论连接过滤器的时候会涉及到这个情况.
下面是在httpd.h文件中的完整定义:
/** Structure to store things which are per connection */
struct conn_rec {
/** Pool associated with this connection */
apr_pool_t *pool;
/** Physical vhost this conn came in on */
server_rec *base_server;
/** used by http_vhost.c */
void *vhost_lookup_data;
/* Information about the connection itself */
/** local address */
apr_sockaddr_t *local_addr;
/** remote address */
apr_sockaddr_t *remote_addr;
/** Client's IP address */
char *remote_ip;
/** Client's DNS name, if known. NULL if DNS hasn't been checked;
* "" if it has and no address was found. N.B.: Only access this through
* get_remote_host() */
char *remote_host;
/** Only ever set if doing rfc1413 lookups. N.B.: Only access this through
* get_remote_logname() */
char *remote_logname;
/** Are we still talking? */
unsigned aborted:1;
/** Are we going to keep the connection alive for another request?
* @see ap_conn_keepalive_e */
ap_conn_keepalive_e keepalive;
/** Have we done double-reverse DNS? -1 yes/failure, 0 not yet,
* 1 yes/success */
signed int double_reverse:2;
/** How many times have we used it? */
int keepalives;
/** server IP address */
char *local_ip;
/** used for ap_get_server_name when UseCanonicalName is set to DNS
* (ignores setting of HostnameLookups) */
char *local_host;
/** ID of this connection; unique at any point in time */
long id;
/** Config vector containing pointers to connections per-server
* config structures */
struct ap_conf_vector_t *conn_config;
/** Notes on *this* connection: send note from one module to
* another. Must remain valid for all requests on this conn. */
apr_table_t *notes;
/** A list of input filters to be used for this connection */
struct ap_filter_t *input_filters;
/** A list of output filters to be used for this connection */
struct ap_filter_t *output_filters;
/** Handle to scoreboard information for this connection */
void *sbh;
/** The bucket allocator to use for all bucket/brigade creations */
struct apr_bucket_alloc_t *bucket_alloc;
/** The current state of this connection */
conn_state_t *cs;
/** Is there data pending in the input filters? */
int data_in_input_filters;
};
2.4.4 process_rec
2.4.4 process_rec
Unlike the other core objects discussed earlier, the process_rec is an operating
system object rather than a web architecture object. The only time applications
need concern themselves with it is when they are working with resources having the
lifetime of the server, when the process pool serves all of the server_rec objects
(and is accessed from a server_rec as s->process->pool). The definition
appears in httpd.h, but is not reproduced here.
不像先前讨论的核心结构, process_rec对象相比web结构对象更像操作系统对象.应用程序需要关注process_rec结构仅仅在当他们操作有着服务器生命周期的资源和在进程池服务所有的server_rec对象(在server_rec中通过s->process->pool访问)时候.结构定义在httpd.h文件中,我们这里不再重复列出.
2.5 Other Key API Components
2.5 其他关键API
The header file httpd.h that defines these core structures is but one of many API
header files that the applications developer will need to use. These fall into several
loosely bounded categories that can be identified by naming conventions:
• ap_ header files generally define low-level API elements and are usually
(though not always) accessed indirectly by inclusion in other headers.
• http_ header files define most of the key APIs likely to be of interest to application
developers. They are also exposed in scripting languages through modules
such as mod_perl and mod_python.
• util_ header files define API elements at a higher level than ap_, but are
rarely used directly by application modules. Two exceptions to that rule are
util_script.h and util_filter.h, which define scripting and filtering
APIs, respectively, and are commonly accessed by modules.
• mod_ header files define APIs implemented by modules that are optional.
Using these APIs may create dependencies. Best practice is discussed in
Chapter 10.
• apr_ header files define the APR APIs. The APR libraries are external but
essential to the webserver, and the APR is required (directly or indirectly) by
any nontrivial module. The APR is discussed in Chapter 3.
• Other header files generally define system-level APIs only.
• Third-party APIs may follow similar conventions (e.g., a mod_ header file) or
adopt their own.
应用程序开发者除了使用定义这些核心结构的httpd.h头文件,还使用许多API头文件.能够通过名字约定,把这些头文件宽松的分为几类.
• ap_ 头文件概括地定义了低级别的API元素,通常情况,间接地被在其他头文件中通过包含使用(使用的情况也不多).
• http_ 头文件定义了应用程序开发者感兴趣的大多数关键APIs. 这些API也被导出到脚本语言通过模块,例如mod_perl和mod_python模块.
• util_ 头文件定义的API元素比ap_ 头文件高一级,但是很少被应用程序模块直接使用. 有两个例外情况,定义脚本和过滤API的util_script.h和 util_filter.h文件各自被模块普遍地使用.
• mod_ 头文件定义被可选模块支持的APIs.使用这些APIs可能会产生依赖,在第10章讨论好的实践.
• apr_ 头文件定义了APR APIs. APR库对服务器来讲既是是外部的,又是基本的.对有实际功能的模块,APR库是必须的(直接地或间接地).在第3章讨论APR库.
• 其他头文件仅仅概括地定义了系统级别的APIs.
• 第三方APIs可能遵循相似的约定(例如, mod_ 头文件)或者采纳他们自己的约定.
As noted earlier, the primary APIs for application modules are the http_* header files.
• http_config.h—Defines the configuration API, including the configuration
data structures, the configuration vectors, any associated accessors, and,
in particular, the main APIs presented in Chapter 9. It also defines the module
data structure itself and associated accessors, and the handler (content generator)
hook. It is required by most modules.
• http_connection.h—Defines the (small) TCP connection API, including
connection-level hooks. Most modules will access the connection through the
conn_rec object, so this API is seldom required by application modules.
• http_core.h—Defines miscellaneous APIs exported by the Apache core,
such as accessor functions for the request_rec object. It includes APIs
exported for particular modules, such as to support mod_perl’s configuration
sections. This header file is rarely required by application modules.
• http_log.h—Defines the error logging API and piped logs. Modules will
need it for the error reporting functions and associated macros.
• http_main.h—Defines APIs for server start-up. It is unlikely to be of interest
to modules.
• http_protocol.h—Contains high-level functional APIs for performing a
number of important operations, including all normal I/O to the client, and
for dealing with aspects of the HTTP protocol such as generating the correct
response headers. It also exports request processing hooks that fall outside the
scope of http_request. Many modules will require this header file—for
example, content generators (unless you use only the lower-level APIs) and
authentication modules.
• http_request.h—Defines the main APIs discussed in Chapter 6. It exports
most of the request processing hooks, and the subrequest and internal redirect
APIs. It is required by some, but not all, modules.
• http_vhost.h—Contains APIs for managing virtual hosts. It is rarely needed
by modules except those concerned with virtual host configuration.
• httpd.h—Contains Apache’s core API, which is required by (probably) all
modules. It defines a lot of system constants, some of them derived from local
build parameters, and various APIs such as HTTP status codes and methods.
Most importantly, it defines the core objects mentioned earlier in this chapter.
在前面提到,应用模块开发的主要APIs是http_* 头文件.
• http_config.h——定义配置API,包括配置数据结构,配置向量及相应的存取器和特别在第9章的主要APIs.也定义了自己的模块数据结构及相应的存取器,处理器(内容产生器)拦截,大多数模块都需要这个文件.
• http_connection.h——定义(小)TCP连接,包括连接级的拦截,大多数模块访问连接状态通过conn_rec对象.因此应用程序模块很少需要这个文件的API.
• http_core.h——定义了被apache核心导出的各种混杂的APIs,例如对request_rec对象进行存取的功能函数,也包括为特定模块导出的APIs,例如支持mod_perl模块的配置.这个头文件很少被应用程序模块需要.
• http_log.h——定义错误日志API和管道日志.模块需要它的错误报告函数及相应的宏.
• http_main.h——定义服务器初始化的APIs.模块不可能需要该文件.
• http_protocol.h——包含高级别的功能APIs,完成执行一系列的重要操作,包括所有正常的到客户的I/O请求和填充HTTP协议的各个字段以产生正确的相应头信息.它也导出超出http_request作用域的请求拦截处理.许多模块需要这个头文件——例如,内容产生器(除非你使用低级别的APIs)和认证模块.
• http_request.h——定义的主要API会在第6章中讨论,它导出了大多数请求处理拦截,子请求和内部跳转APIs.它不是被所有需要,只被一部分模块需要.
• http_vhost.h——包含API管理虚拟主机,它很少被模块需要,除了关心虚拟主机配置的模块.
• httpd.h——包含apache核心API,所有模块都需要这个文件(大概).定义了大量的系统常量,一些从本地编译参数中派生出来,和各种各样的APIs,例如HTTP状态码和HTTP请求方式.最重要的,它定义了在本章早些段落中的提到的核心对象.
Other important API headers we will encounter include the following files:
• util_filter.h—The filter API, required by all filter modules (Chapter 8)
• ap_provider.h—The provider API (Chapter 10)
• mod_dbd.h—The DBD framework (Chapters 10 and 11)
其他我们将会遇到的重要API头文件:
• util_filter.h——过滤API,所有过滤模块都需要(第8章)
• ap_provider.h——provider API(第10章)
• mod_dbd.h——DBD框架(第10章和第11章)
Other API headers likely to be of interest to application developers include the following
files:
• util_ldap.h—The LDAP API
• util_script.h—A scripting environment that originally supported CGI,
but is also used by other modules that use CGI environment variables (e.g.,
mod_rewrite, mod_perl, mod_php) or that generate responses using CGI
rules (e.g., mod_asis)
其他可能对应用程序开发者感兴趣的API头文件:
• util_ldap.h——LDAP API
• util_script.h——最初用来支持CGI的脚本环境,但是也被其他使用CGI环境变量的模块(例如,mod_rewrite,mod_perl,mod_php)或者用CGI规则产生响应信息的模块(mod_asis)使用.
2.6 Apache Configuration Basics
2.6 Apache配置基础
Apache configuration is mostly determined at start-up, when the server reads
httpd.conf (and any included files). Configuration data, including resources
derived from them by a module (e.g., by opening a file), are stored on each module’s
configuration records.
Apache的主要配置在服务器初始化和读取httpd.conf(和任何一个被包含的文件) 的时候确定.配置数据,包括从一个模块中继承的的资源(例如打开一个文件),这些被存在每一个模块的配置记录上.
Each module has two configuration records, either or both of which may be null
(unused):
• The per-server configuration is stored directly on the server_rec, so there is
one instance per virtual host. The scope of per-server directives is controlled
by <VirtualHost> containers in httpd.conf, but other containers such as
<Location>, <Directory>, and <Files> will be ignored.
• The per-directory configuration is stored indirectly and is available to modules
via the request_rec object in the course of processing a request. It is the
opposite of per-server configuration: Its scope is defined by containers such as
<Location>, <Directory>, and <Files>.
每一个模块有两个配置记录,其中一个或者两个都是空(没有被使用):
• 每一服务器的配置被直接存在server_rec,因此一个虚拟主机一个实例.服务器的指令作用域被httpd.conf文件中的<VirtualHost>容器控制.但是其他的容器指令,例如, <Location>, <Directory>,和 <Files>会被忽略.
• 每个目录的配置被间接存储的,在处理请求的过程中通过request_rec对象被模块访问到.这个是和每一服务器的配置是相反的:它的作用域在容器指令定义范围内,例如<Location>, <Directory>, and <Files>.
To implement a configuration directive, a module must supply a function that will
recognize the directive and set a field in one of the configuration records at system
start-up time. After start-up, the configuration is set and should not be changed. In
particular, the configuration records should generally be treated as read-only while
processing requests (or connections). Changing configuration data during request
processing violates thread safety (requiring use of programming techniques such as
locking) and runs a high risk of introducing other bugs due to the increased complexity.
Apache provides a separate configuration record on each conn_rec and
request_rec for transient data.
Chapter 9 describes working with configuration records and data.
实现一个配置指令,模块必须提供一个识别指令的函数,并且在初始化阶段设置一个配置集合的一个字段.在初始化之后,配置被设置完,不应该被改变.在特殊情况下,配置集合一般应该被对待为只读,在处理请求(或者连接)时候.在处理请求过程中改变配置数据是违反线程安全的(需要使用编程技巧,例如锁),并且加大产生其他bug的风险,最终导致系统的复杂性.Apache为每一个conn_rec和request_rec临时数据提供了一个独立配置集合.
第9章描述配置集合和数据
2.7 Request Processing in Apache
2.7 Apache的请求处理过程
Most, though by no means all, modules are concerned with some aspect of processing
an HTTP request. But there is rarely, if ever, a reason for a module to concern
itself with every aspect of HTTP—that is the business of the httpd. The
advantage of a modular approach is that a module can easily focus on a particular
task but ignore aspects of HTTP that are not relevant to it.
大多数模块,尽管不是所有的,会关心处理请求的某些过程.但是几乎没有模块会关心处理的全部过程,如果有,可能是因为商业需要.模块化的好处是一个模块能容易专心处理他的特定任务,而可以忽略和它不相关的一些HTTP请求过程.
2.7.1 Content Generation
2.7.1 内容生成
The simplest possible formulation of a webserver is a program that listens for
HTTP requests and returns a response when it receives one (Figure 2-2). In
Apache, this job is fundamentally the business of a content generator, the core of
the webserver.
用尽可能简单的语言来描述web服务器,是监听,接受一个HTTP请求并给于回应的程序(图2-2).在Apache中,这个工作由web服务器的有着基础功能的内容生成器核心完成.

FIGURE 2-2
Minimal webserver
Exactly one content generator must be run for every HTTP request. Any module
may register content generators, normally by defining a function referenced by a
handler that can be configured using the SetHandler or AddHandler directives in
httpd.conf. The default generator, which is used when no specific generator is
defined by any module, simply returns a file, mapped directly from the request to
the filesystem. Modules that implement content generators are sometimes known
as “content generator” or “handler” modules.
准备地说,对每一个HTTP请求,必须有一个内容处理器运行. 通过定义被处理器(handler)引用的函数这种正常方法,任何模块都可以注册为内容生成器,我们能在httpd.conf文件中用SetHandler或者AddHandler指令配置这个处理器(handler).在没有任何一个模块指定生成器的时候,默认生成器会被使用,简单的返回一个文件,直接把请求映射到文件系统上.实现内容生成器的模块有时被称着”内容生成器”或者”处理器”模块
2.7.2 Request Processing Phases
2.7.2 请求处理阶段
In principle, a content generator can handle all the functions of a webserver. For
example, a CGI program gets the request and produces the response, and it can take
full control of what happens between them. Like other webservers, Apache splits the
request into different phases. For example, it checks whether the user is authorized
to do something before the content generator does that thing.
原则上,内容生成器能完成web服务器的所有功能.例如,一个CGI程序获取请求然后给出响应,这个过程能被完全控制.像其它web服务器,Apache划分请求为不同的几个阶段.例如,在内容生成器开始做事之前,检查用户的活动是否被授权.
Several request phases precede the content generator (Figure 2-3). These serve to
examine and perhaps manipulate the request headers, and to determine what to do
with the request. For example:
• The request URL will be matched against the configuration, to determine
which content generator should be used.
• The request URL will normally be mapped to the filesystem. The mapping
may be to a static file, a CGI script, or whatever else the content generator
may use.
• If content negotiation is enabled, mod_negotiation will find the version of
the resource that best matches the browser’s preference. For example, the
Apache manual pages are served in the language requested by the browser.
• Access and authentication modules will enforce the server’s access rules, and
determine whether the user is permitted what has been requested.
• mod_alias or mod_rewrite may change the effective URL in the request.
一些请求阶段在内容生成器之前(如图2-3),这些用来检查,或许修改请求头部信息,来决定接下的操作,例如:
• 根据当前请求URL检查配置,来决定使用哪一个内容生成器.
• 当前请求URL将被映射到文件系统上,被映射的可能是一个静态文件,一个CGI脚本,或者其他的内容生成器.
• 如果内容选择是开启的,. mod_negotiation模块会找出最适合浏览器配置的资源版本.例如,apache的帮助文档根据浏览器来选择相应的语言版本.
• 访问和授权模块会加强服务器的访问规则,决定用户的请求是否允许.
• mod_alias 或者mod_rewrite模块可能会改变请求中的URL.
There is also a request logging phase, which comes after the content generator has
sent a reply to the browser.
在内容生成器发送应答信息给浏览器之后的阶段是日志阶段.
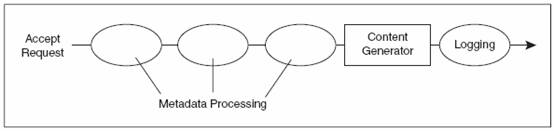
FIGURE 2-3
Request processing in Apache
2.7.2.1 Nonstandard Request Processing
2.7.2.1 非标准的请求处理过程
Request processing may sometimes be diverted from the standard processing axis
described here, for a variety of reasons:
• A module may divert processing into a new request or error document at any
point before the response has been sent (Chapter 6).
• A module may define additional phases and enable other modules to hook
their own processing in (Chapter 10).
• There is a quick_handler hook that bypasses normal processing, used by
mod_cache (not discussed in this book).
在这儿描述的请求处理过程有时候可能会从标准处理过程中转移,因为各种各样的原因.
• 在响应发送之前,某个模块可能会转移处理过程到一个新的请求或者报错页面在任何时候(第6章)
• 某个模块可能会定义附加的处理过程和允许其他模块来拦截他们的处理过程(第10章)
• 快速处理拦截,绕过正常处理过程.被mod_cache使用(不在本书讨论)
2.7.3 Processing Hooks
2.7.2 处理拦截
The mechanism by which a module can influence or take charge of some aspect of
processing in Apache is through a sequence of hooks. The usual hooks for processing
a request in Apache 2.0 are described next.
通过一系列的拦截方法,模块能够影响或者接管apache处理过程中的一些细节.这种在Apache2.0中常用的拦截处理在下面描述:
post_read_request—This is the first hook available to modules in normal
request processing. It is available to modules that need to hook very early into processing
a request.
post_read_request—在正常处理请求过程中,这是第一个对模块有效的拦截机会.对需要在处理过程中拦截非常早的模块也有效.
translate_name—Apache maps the request URL to the filesystem. A module can
insert a hook here to substitute its own logic—for example, mod_alias.
translate_name—Apache映射请求URL到文件系统.模块能在这里插入一个拦截来替换自己的逻辑—例如,mod_alias
map_to_storage—Since the URL has been mapped to the filesystem, we are now
in a position to apply per-directory configuration (<Directory> and <Files>
sections and their variants, including any relevant .htaccess files if enabled). This
hook enables Apache to determine the configuration options that apply to this
request. It applies normal configuration directives for all active modules, so few modules
should ever need to apply hooks here. The only standard module to do so is
mod_proxy.
map_to_storage—在URL已经被映射到文件系统之后,我们现在有机会应用每一目录的配置(<Directory>和<Files>节和他们的信息, 在.htaccess文件允许的情况下,也包括其文件的内容).这个拦截能够让Apache应用对这次请求的配置选项.它为所有活动的模块应用了正常的配置指令,很少有模块需要在这里拦截,仅仅有一个mod_proxy标准模块在这里拦截了.
header_parser—This hook inspects the request headers. It is rarely used, as modules
can perform that task at any point in the request processing, and they usually
do so within the context of another hook. mod_setenvif is a standard module that
uses a header_parser to set internal environment variables according to the
request headers.
header_parser—这个拦截检查请求头部信息.这个拦截很少使用,因为模块能够在处理请求过程的任何一个阶段,在其它拦截的环境中完成这个任务.标准模块mod_setenvif使用header_parser根据请求信息头来设置内部的环境变量.
access_checker—Apache checks whether access to the requested resource is permitted
according to the server configuration (httpd.conf). A module can add to
or replace Apache’s standard logic, which implements the Allow/Deny From directives
in mod_access (httpd 1.x and 2.0) or mod_authz_host (httpd 2.2).
access_checker—根据服务器的配置(httpd.conf),Apache检查请求的资源是否被允许.模块能够增加或者替换Apache的标准逻辑,在mod_access (httpd 1.x and 2.0)或者mod_authz_host (httpd 2.2)模块中根据指令实现允许或者拒绝访问.
check_user_id—If any authentication method is in use, Apache will apply the
relevant authentication and set the username field r->user. A module may implement
an authentication method with this hook.
check_user_id—如果任何一个认证方法正在使用,Apache会去使用相关的认证和设置用户名字字段r->user.模块能够通过这个拦截实现认证.
auth_checker—This hook checks whether the requested operation is permitted
to the authenticated user.
auth_checker—这个拦截用来检查认证过的用户的请求是不是被允许.
type_checker—This hook applies rules related to the MIME type (where applicable)
of the requested resource, and determines the content handler to use (if not
already set). Standard modules implementing this hook include mod_negotiation
(selection of a resource based on HTTP content negotiation) and mod_mime (setting
the MIME type and handler information according to standard configuration
directives and conventions such as filename “extensions”).
type_checker—这个拦截给请求的MIME类型资源应用规则.决定使用内容处理程序(如果还没有设置).实现这个拦截的标准模块包括mod_negotiation(根据HTTP内容选择来选择资源)和mod_mime(设置MIME类型和根据标准配置指令和文件扩展名来处理信息)
fixups—This general-purpose hook enables modules to run any necessary processing
after the preceding hooks but before the content generator. Like
post_read_request, it is something of a catch-all, and is one of the most commonly
used hooks.
fixups—这个通用拦截能够让模块在前面所列拦截之后但是在内容生成器之前运行任何需要的处理.像post_read_request,是非常重要的抓住所有处理过程,也是一个最常用的拦截.
handler—This is the content generator hook. It is responsible for sending an
appropriate response to the client. If there are input data, the handler is also responsible
for reading them. Unlike the other hooks, where zero or many functions may
be involved in processing a request, every request is processed by exactly one handler.
handler—这是一个内容生成器拦截.负责给客户发送恰当的响应.如果这里有输入数据,处理器也负责读取他们.不像其它的拦截,没有或者有大量函数被调用在处理请求过程中,每一个请求准确的被一个处理器处理.
log_transaction—This hook logs the transaction after the response has been
returned to the client. A module may modify or replace Apache’s standard logging.
log_transaction—这个拦截在响应客户之后记录传输信息.模块能够修改或者替换Apache的标准日志方式.
A module may hook its own handlers into any of these processing phases. The module
provides a callback function and hooks it in, and Apache calls the function during
the appropriate processing phase. Modules that concern themselves with the
phases before content generation are sometimes known as metadata modules; they
are described in detail in Chapter 6. Modules that deal with logging are known as
logging modules. In addition to using the standard hooks, modules may define further
processing hooks, as described in Chapter 10.
模块能够加入自己的拦截处理过程在任何处理阶段.模块提供一个回调函数挂接上去,Apache在适当的处理阶段调用这个函数.在内容生成器拦截阶段之前只用考虑自身的模块被称为元(metadata)模块,我们在第6章中描述.处理日志的模块被称为日志模块.除此之外使用标准拦截的,模块可以定义更进一步的处理拦截,在第10章中描述.
2.7.4 The Data Axis and Filters
2.7.2 数据轴向和过滤
What we have described so far is essentially similar to the architecture of every general-
purpose webserver. There are, of course, differences in the details, but the
request processing (metadata → generator → logger) phases are common.
The major innovation in Apache 2, which transforms it from a “mere” webserver
(like Apache 1.3 and others) into a powerful applications platform, is the filter
chain. The filter chain can be represented as a data axis, orthogonal to the request processing
axis (Figure 2-4). The request data may be processed by input filters
before reaching the content generator, and the response may be processed by output
filters before being sent to the client. Filters enable a far cleaner and more efficient
implementation of data processing than was possible in the past, as well as
separating content generation from its transformation and aggregation.
我们到目前为止的描述系统结构在本质上和普遍的web服务器是一样的.当然在细节上有一些不同,但是请求过程阶段(metadata → generator → logger)是通用的. Apache2把仅仅的web服务器(像Apache1.3和其它的)变成了一个强大的应用平台,其中的主要创新是提供了一个过滤链.过滤链能够由数据轴和正交的请求处理过程轴描绘出来(图2-4).请求数据在到内容生成器之前能被输入过滤器处理,响应数据在被发送到客户之前可以被输出过滤器处理.过滤器是非常伶俐的和有效的实现数据处理,相比在过去可能的情况下,也独立了内容产生从转换和聚合中.
2.7.4.1 Handler or Filter?
2.7.4.1 处理器或过滤器?
Many applications can be implemented as either a handler or a filter. Sometimes it
may be clear that one of these solutions is appropriate and the other would be nonsensical,
but between these extremes lies a gray area. How does one decide whether
to write a handler or a filter?
许多扩展能够以处理器或者过滤器实现.有时候这是非常清楚,其中只有一种方法是恰当的,其它都显得没有意义,但是在这两个极端中存在一个灰色地带.应该如何决定是编写一个处理器还是过滤器了?
When making this decision, there are several questions to consider:
• Feasibility: Can it be made to work in both cases? If not, there’s an instant
decision.
• Utility: Is the functionality it provides more useful in one case than the other?
Filters are often far more useful than handlers, because they can be reused with
different content generators and chained both with generators and other filters.
But every request has to be processed by some handler, even if it does
nothing!
• Complexity: Is one version substantially more complex than the other? Will it
take more time and effort to develop, and/or run more slowly? Filter modules
are usually more complex than the equivalent handler, because a handler is in
full control of its data and can read or write at will, whereas a filter has to
implement a callback that may be called several times with partial data, which
it must treat as unstructured chunks. We will discuss this issue in detail in
Chapter 8.
当做这个决定的时候,我们有几个问题需要考虑:
• 可行性:在这两种情况下都能工作吗?如果不能,我们就有选择了.
• 有效性:是否其中一种方式提供的功能比另外一种要更有用?通常,过滤器要比处理器更有用,因为它能被不同的内容生成器重用,能和内容生成器和其它的过滤器链接在一起.但是每一个请求必须被一些处理器处理,甚至不用做什么事情!
• 复杂性:其中一个比另一个更显得复杂?这个会花去大量时间和精力去开发,或者运行的更慢?在同等功能下,过滤模块常常是比处理器更复杂,因为处理器在完全控制自己的数据,能按自己的意愿进行读写,与此同时过滤器不得不去实现一个回调函数,会被调用几次,只拥有部分的数据,这些数据必须被处理为一整块数据,我们在第8章中详细讨论这个.
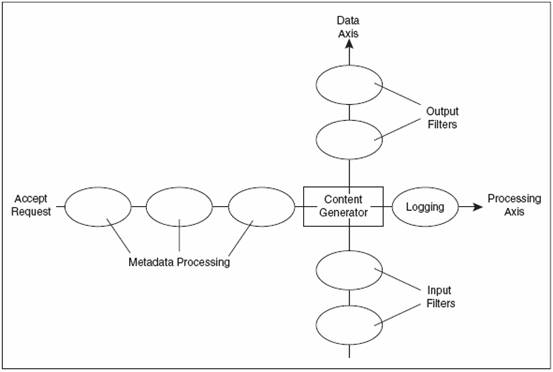
FIGURE 2-4
Apache 2 introduces a new data axis enabling a new range of powerful applications
For example, Apache 1.3 users can do an XSLT transformation by building it into
handlers, such as CGI or PHP. Alternatively, they can use an XSLT module, but this
is very slow and cumbersome (this author tried an XSLT module for Apache 1.3,
but found it many hundreds of times slower than running XSLT in a CGI script
operating on temporary files). Running XSLT in a handler works, but loses modularity
and reusability. Any nontrivial application that needs it has to reinvent that
wheel, using whatever libraries are available for the programming or scripting language
used and often resorting to ugly hacks such as temporary files.
例如,Apache1.3用户能够做XSLT转换,通过以handler方式编译,例如CGI或者PHP.可选的,我们能使用XSLT模块,但是非常慢和笨重(这个作者已经为Apache1.3实验XSLT模块,但是发现在操作临时文件时要比以CGI脚本方式运行XSLT慢很多).以处理器的方式能很好的运行XSLT,但是丢掉了模块和重用性.任何一个需要这个功能的实用程序不得不重新构造,使用任何对编程可用的库或者使用脚本语言,
Apache 2, by contrast, allows us to run XSLT in a filter. Content handlers requiring
XSLT can simply output the XML as is, and leave the transformation to
Apache. The first XSLT module for Apache 2, written by Phillip Dunkel and
released while Apache 2.0 was still in beta testing, was initially incomplete, but
already worked far better than XSLT in Apache 1.3. It is now further improved, and
is one of a choice of XSLT modules. This book’s author developed another XSLT
module.
相比,Apache2允许我们以过滤器的方式运行XSLT.内容处理器需要XSLT能简单的输出XML格式,把转换留给Apache.在Apache2.0还处于测试阶段的时候,第一个Apache2的XSLT模块是由Phillip Dunkel编写和发布,在开始的时候还不怎么完善,但是已经比Apache 1.3下的XSLT好很多了.现在更进一步的提高了,是我们可选的一个XSLT模块.本书的作者开发了另一个XSLT模块.
More generally, if a module has both data inputs and outputs, and if it may be used
in more than one application, then it is a strong candidate for implementation as a
filter.
更普遍的,如果一个模块有输入和输出数据,可以被多个程序使用,那么强烈建议作为一个过滤器来实现.
2.7.4.2 Content Generator Examples
2.7.4.2 内容产生器例子
• The default handler sends a file from the local disk under the DocumentRoot.
Although a filter could do that, there’s nothing to be gained.
• CGI, the generic API for server-side programming, is a handler. Because CGI
scripts expect the central position in the webserver architecture, it has to be a
handler. However, a somewhat similar framework for external filters is also
provided by mod_ext_filter.
• The Apache proxy is a handler that fetches contents from a back-end server.
• Any form-processing application will normally be implemented as a handler—
particularly those that accept POST data, or other operations that can alter the
state of the server itself. Likewise, applications that generate a report from any
back end are usually implemented as handlers. However, when the handler is
based on HTML or XML pages with embedded programming elements, it can
usefully be implemented as a filter.
• 默认处理器从本地硬盘DocumentRoot目录发送文件,尽管过滤器能够完成这个功能,但是这样做没什么好处.
• CGI,服务端编程通用API,是一个处理器.因为CGI脚本期待web服务器结构的重要位置,而不得不是一个处理器.但是,一个有点相似的外部过滤器框架也由mod_ext_filter提供.
• Apache代理是一个处理器,用来从后端的服务器获取内容.
• 任何一个表单处理程序必须是处理器—一特别是接受POST数据,或者其他能改变服务器自身状态的操作.同样的,从客户端产生报告数据的程序常常需要是以处理器形式实现.但是当处理器是基于有着嵌入编程元素的HTML或者XML页面的时候,作为过滤器来实现是非常有用的.
2.7.4.3 Filter Examples
2.7.4.3 过滤器例子
• mod_include implements server-side includes, a simple scripting language
embedded in pages. It is implemented as a filter, so it can post-process content
from any content generator, as discussed earlier with reference to XSLT.
• mod_include模块实现服务端的包含,嵌入页面的一个简单脚本语言.作为过滤器实现,因此它能够从任何一个内容生成器中post-process内容,在前面关于XSLT时候讨论了.
• mod_ssl implements secure transport as a connection-level filter, thereby
enabling all normal processing in the server to work with unencrypted data.
This represents a major advance over Apache 1.x, where secure transport was
complex and required a lot of work to combine it with other applications.
• mod_ssl模块作为一个连接层的过滤器实现安全传输,因此允许在服务端的所有对加密数据的正常操作.相比Apache1.x,这是一个主要的优点,安全传输是十分复杂,而且需要很多工作来和其他程序的兼容.
• Markup parsing modules are used to post-process and transform XML or
HTML in more sophisticated ways, from simple link rewriting9 through XSLT
and Xinclude processing,10 to a complete API for markup filtering,11 to a security
filter that blocks attempts to attack vulnerable applications such as PHP
scripts.12 Examples will be introduced in Chapter 8.
• Markup parsing模块是被用来post-process和转换XML或者更多变化的HTML,从通过XSLT简单连接重写和包括处理,到完成API, markup过滤,阻止试图攻击程序漏洞的安全过滤例如PHP脚本.在第8章介绍例子.
• Image processing can take place in a filter. This author developed a custom
proxy for a developer of mobile phone browsers. Because the browser tells the
proxy its capabilities, images can be reduced to fit within the screen space and,
where appropriate, translated to gray scale, thereby reducing the volume of
data sent and accelerating browsing over slow connections.
• 图片处理是一个过滤器,这个作者为手机浏览器开发者开发了自定义代理.因为浏览器告诉代理器它的参数,图片能被缩减适合屏幕空间,适当的转换灰度值,因此减少发送数据量和加速在低带宽的浏览速度.
• Form-processing modules need to decode data sent from a web browser. Input
filter modules, such as mod_form and mod_upload,13 spare applications from
reinventing that wheel.
• 表单处理模块需要解码从web浏览器发来的数据.输入过滤器,例如mod_form和mod_upload为应用程序节省重新完成这个功能.
• Data compression and decompression are implemented in mod_deflate.
The filter architecture allows this module to be much simpler than mod_gzip
(an Apache 1.3 compression module) and to dispense with any use of temporary
files.
• 数据压缩和解压缩由mod_deflate实现.过滤器的结构允许这个模块比mod_gzip(Apache1.3 的压缩模块)更简单,无需任何临时文件.
2.7.5 Order of Processing
2.7.5 处理过程顺序
Before moving on to discuss how a module hooks itself into any of the stages of
processing a request/data, we should pause to clear up a matter that often causes
confusion—namely, the order of processing.
在开始讨论模块怎么在处理请求过程的任何一个阶段进行拦截之前,我们需要暂停下来阐明一个让我们迷惑的问题,也就是处理过程的顺序.
9. http://apache.webthing.com/mod_proxy_html/
10. http://www.outoforder.cc/projects/apache/mod_transform
11. http://apache.webthing.com/xmlns.html
12. http://modsecurity.org/
13. http://apache.webthing.com/
The request processing axis is straightforward, with phases happening strictly in
order. But confusion arises in the data axis. For maximum efficiency, this axis is
pipelined, so the content generator and filters do not run in a deterministic order.
For example, you cannot in general set something in an input filter and expect it to
apply in the generator or output filters.
请求处理轴是容易理解的,各个阶段有着严格的发生次序.但是数据轴很迷惑.为了最高的效率,这个轴是通过管道传递的,因此内容生成器和过滤器不是运行在一个确定的次序.例如,你不能一般性的在输入过滤器上设置一些东西,而希望它也应用在内容生成器或者输出过滤器上.
The order of processing centers on the content generator, which is responsible for
pulling data from the input filter stack and pushing data onto the output filters
(where applicable, in both cases). When a generator or filter needs to set something
affecting the request as a whole, it must do so before passing any data down the chain
(generator and output filters) or before returning data to the caller (input filters).
处理过程的次序集中在内容生成器上,内容生成器负责从输入过滤器堆栈中取出数据和给输出过滤器输出数据(where applicable, in both cases).当内容生成器或者过滤器需要设置一些东西影响请求的全部过程,必须在传递数据给数据过滤链(内容生成器和输出过滤器)或者在返回数据给调用者(输入过滤器)之前完成设置.
2.7.6 Processing Hooks
2.7.6 处理过程拦截
Now that we have an overview of request processing in Apache, we can show how
a module hooks into it to play a part.
现在我们已经对Apache的请求处理过程有一个大体上的了解了,我们能够展示让一个模块参与其中的拦截了.
The Apache module structure declares several (optional) data and function members:
Apache模块数据结构声明了几个可选的数据段和函数成员:
module AP_MODULE_DECLARE_DATA my_module = {
STANDARD20_MODULE_STUFF, /* macro to ensure version consistency */
my_dir_conf, /* create per-directory configuration record */
my_dir_merge, /* merge per-directory configuration records */
my_server_conf, /* create per-server configuration record */
my_server_merge, /* merge per-server configuration records */
my_cmds, /* configuration directives */
my_hooks /* register modules functions with the core */
};
The configuration directives are presented as an array; the remaining module entries
are functions. The relevant function for the module to create request processing
hooks is the final member:
配置指令是一个数组, 模块余下结构部分是函数.模块结构里面的最后一个函数用来创建请求过程处理的拦截:
static void my_hooks(apr_pool_t *pool) {
/* create request processing hooks as required */
}
Which hooks we need to create here depend on which part or parts of the request
our module is interested in. For example, a module that implements a content generator
(handler) will need a handler hook, looking something like this:
我们需要创建什么拦截根据请求处理过程的部分或者我们感兴趣的处理部分.例如实现内容生成器(handler)的模块需要一个处理器拦截,像下面这样:
ap_hook_handler(my_handler, NULL, NULL, APR_HOOK_MIDDLE) ;
Now my_handler will be called when a request reaches the content generation
phase. Hooks for other request phases are similar.
现在my_handler会被调用在一个请求到达内容生成器阶段.拦截其他请求阶段是类似的.
The following prototype applies to a handler for any of these phases:
下面这个是这些阶段的拦截处理器的函数原型:
static int my_handler(request_rec *r) {
/* do something with the request */
}
Details and implementation of this prototype are discussed in Chapters 5 and 6.
这个原型的详情和实现在第5章和第6章中讨论.
2.8 Summary
2.8 总结
This basic introduction to the Apache platform and architecture sets the scene for
the following chapters. We have now looked at the following aspects of Apache:
• The Apache architecture, and its relationship to the operating system
• The roles of the principal components: MPMs, APR, and modules
• The separation of tasks into initialization and operation
• The fundamental Apache objects and (briefly) the API header files
• Configuration basics
• The request processing cycle
• The data axis and filter architecture
Nothing in this general overview is specific to C programming, so Chapter 2
should be equally relevant to scripting languages. Together with the next two chapters
(on the APR and programming techniques, respectively), it provides the essential
basis for understanding the core information and advanced topics covered in
Chapters 5–11. In those chapters, the concepts introduced here are examined
in more detail, and demonstrated in the context of developing real applications.
对Apache平台和结构的基础介绍是为下面的章节做准备.我们已经了解了Apache的以下特征:
• Apache的结构及其和操作系统的关系.
• MPMs,APR和模块这些主要组件的任务..
• 服务的启动被分为初始化和运行.
• Apache的基础对象和简要的API头文件.
• 基本配置概念.
• 请求过程处理周期.
• 数据流向轴和过滤结构.
在这个概括的谈论中没有涉及到C语言编程,因此第2章应该等同于和脚本语言相关.和下面两章结构起来(APR和编程技巧)提供了基本的概念用来理解核心和第5-11章谈到的高级技巧.在这些章节中,这些概念在这里描述的详细些,示范了开发一个实用程序的环境.
第2章完!!!希望在以后的修改中更加完善.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









