







并行编程模式概览
前面的5、6篇博文,都是和并行编程相关的基础知识,如果你一路看来,基本上也能够开始进行并行编程设计了,也可以和别人吹吹牛、聊聊天了。
但“欲穷千里目,更上一层楼”,前面的毕竟都是基础知识,拿来直接设计,虽然能够完成任务,但就像在茫茫大海中航行,没有灯塔,难免会走很多弯路、甚至绝路!
所以我们要在这些基础知识之上,学习一套系统的分析问题、设计方案、应用实现的理论来指导我们作出正确的、优秀的分析、设计,以及实现。并行编程模式就是这样一座指导我们进行并行编程设计和实现的灯塔。
当然,这个并行编程模式也是一个完整的体系,不是简单的几个模式堆杂在一起,所以我们要开始就把握住这个并行编程模式的体系的框架,高屋建瓴的从整体上对这套体系有一个清晰的了解,然后再开始深入的掌握每个部分。
首先,我们从整体上看一下并行编程模式的体系结构,如下图:
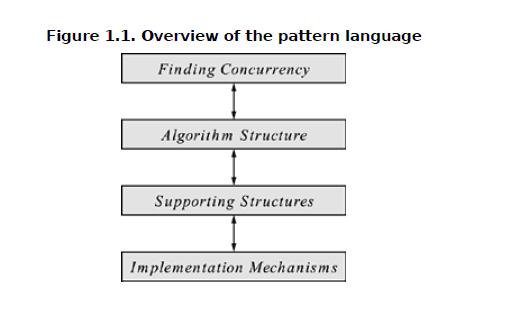
从图中可以看出,总共分为4大部分:Finding concurrency、Algorithm structure、Support Structure、Implementation Mechanisms。从英文本意来看比较难以理解,我仔细看了每章的介绍,按照如下方式翻译:并行性分析、算法结构、程序结构、实现结构。这几个部分实际上是按照设计的先后顺序进行分类的:首先要分析问题、然后再选择什么算法,再看程序如何设计,最后看具体实现。下面我们就逐一简单介绍这几部分。
1.1 并行性分析
顾名思义,这部分模式是用来分析并行性的,按照英文的字面意思就是“找到并行性”。
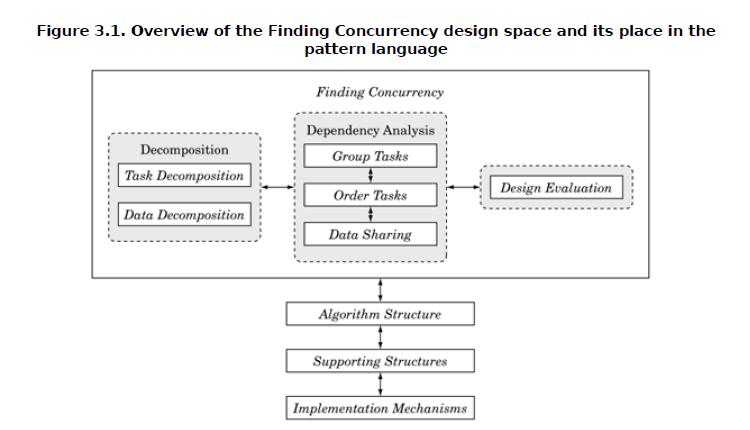
如下图,并行性分析又分为三大类:分解、依赖分析、设计评估,共6个模式。
1.2 算法结构
经过并行性分析后,并行相关的任务、数据、依赖都已经基本分析完毕了(之所以说是基本,是因为分析和设计是一个迭代的过程,不是标准的流水线作业),这时就要看看如何将这些任务、数据组织起来来解决实际的问题。也就是说并行性分析是一个“分”的过程,而算法结构是一个“合”的过程。
如下图:算法结构模式部分分为三类:按任务组织、按数据分解组织、按数据流组织,共6个模式。
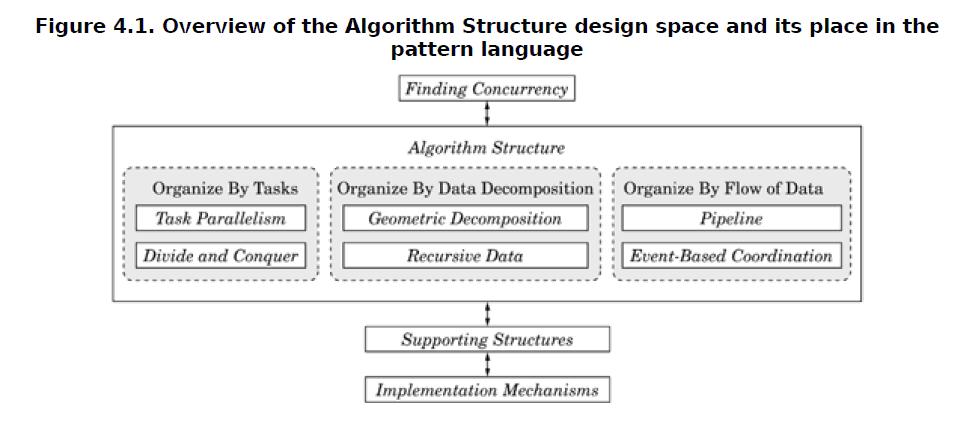
但细心的朋友可能就会问:在并行性分析之前就是一个已经“合”好的问题了,为什么这里还要再次合起来呢?
关键就在于:算法结构的“合”是针对已经分解好的任务、数据和依赖,而并行性分析前的“合”只是一个问题的初始混沌状态(有的书中叫做problem mud)。算法结构中的“合”动作是看并行性分析后的结果合起来是否能够解决并行性分析前“合”的问题,其实道理很简单:分解得再好,合起来不能解决分之前的问题,那也是错误的。
1.3 程序结构
按照英文原意翻译,这部分叫做“支撑结构”,很难理解,我仔细看了这类模式包含的几个子模式,发现其实都是关于进程/线程结构、数据结构的,而这些都是具体程序设计的时候需要考虑的,因此我觉得翻译成“程序结构”更加容易理解。
从下图可以看出,这类模式分为两类:Program Structure,这是关于如何组织进程或者线程的;Data structure,这是关于如何组织数据的。
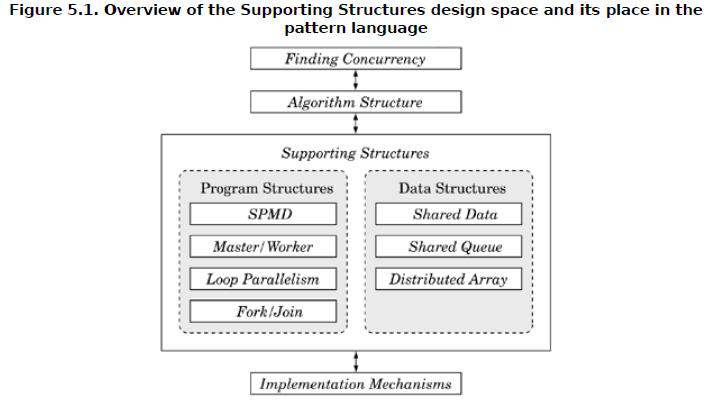
上一章的算法结构中也有“按照数据组织”,这一章也有“数据结构”,两者是什么区别或者关系呢?
区别就在于两个“数据”的地位不一样:算法结构中是按照数据来对任务进行“合”操作,不考虑对数据本身的管理(例如数据操作、数据互斥、数据同步),而程序结构中是考虑数据本身的管理,即如何保证数据满足多个任务的并行运行。
1.4 实现结构
实现结构作为并行编程模式有点“挂羊头卖狗肉”的意思,因为实际上这里面的内容都是和具体的语言或者平台相关的,作者在这部分主要讲了Java、OpenMP、MPI三种语言的实现方法,并不是什么模式(模式应该是语言无关的吧)。
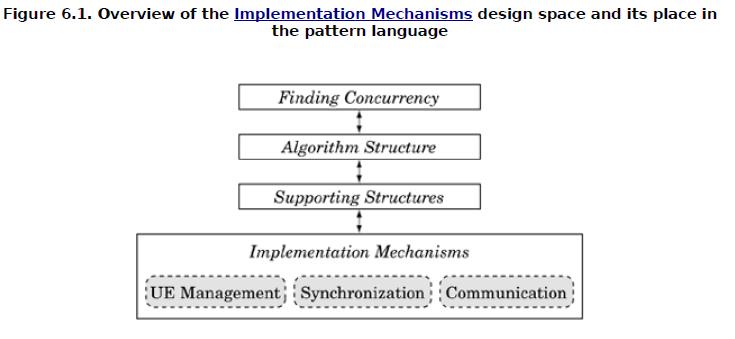
认真的朋友看到“UE Management”、“Synchronization”、“Communications”可能有似曾相识的感觉,因为我在前面5、6篇博文里面重点就是讲解了Windows和Linux的多进程/多线程实现机制、进程间同步、进程间通信,这不正好对应这里所谓的“UE Management”、“Synchronization”、“Communications”么?:)















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









