






一、实验目的
(1) 熟悉网页浏览器开发工具的使用;
(2) 掌握动态网页加载过程;
(3) 掌握 post 请求参数设置;
(4) 掌握基本的反反爬技术;
(5) 能够根据问题需求,指定网络爬虫方案,并编码实现。
(6) 具备撰写项目实验报告的能力。
二、实验内容
网页来自:
https://kns.cnki.net/kns8/AdvSearch?id=11&dbcode=CFLQ&searchtype=gradeS earch&ishistory=1
内容:
关于《混合动力汽车》主题的173篇学术期刊
任务:
(1)爬取多页的文章列表数据,包括:
文章标题,文章链接,作者,刊名,发表时间,被引,下载
(2)根据文件链接,进入文章详情页
爬取:摘要、关键词,专辑等。
(3)数据分析
以下任务任选一个完成:
1) 按月统计每月文章发表量,制作图表;
2) 基于文章的摘要(或题目)制作词云图,查看主要关键词
三、实验设计及实现
目录
(1)项目描述
来自中国知网的关于关于《混合动力汽车》主题的173篇学术期刊,可用于研究相关领域的学术问题,了解该类学士期刊的关键字和内容。
(2)项目分析
该网页的请求方法为POST,获取时还要给定不同的表单数据,网页目录中包含了整个网页的预览效果,该网页数据储存XHR中的GetGridTableHtml,本实验主要对其中的数据进行爬取和分析。
-
爬取方案制定和实现
1)构建网络请求函数

2、3)数据提取和解析并构建数据处理函数
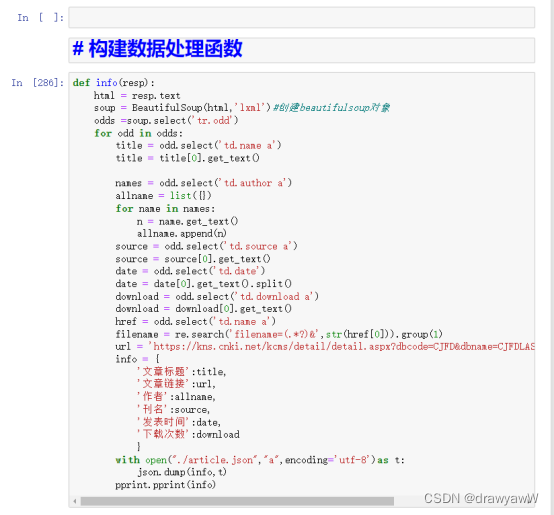
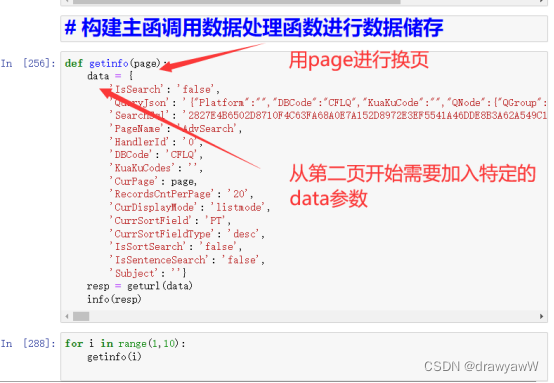
4)构建主函调用数据处理函数进行数据储存
5)爬虫实现(源代码)
- import requests
- import json
- import re
- import pprint
- import jieba
- from wordcloud import WordCloud
- import numpy as np
- from PIL import Image
- from bs4 import BeautifulSoup
- import matplotlib.pyplot as plt
- def geturl(data):
- url = 'https://kns.cnki.net/kns8/Brief/GetGridTableHtml'
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52',
- 'X-Requested-With': 'XMLHttpRequest',
- 'Referer': 'https://kns.cnki.net/kns8/AdvSearch?dbcode=CFLQ'
- }
- resp = requests.post(url,data=data,headers=headers)
- return resp
- def info(resp):
- html = resp.text
- soup = BeautifulSoup(html,'lxml')#创建beautifulsoup对象
- odds =soup.select('tr.odd')
- for odd in odds:
- title = odd.select('td.name a')
- title = title[0].get_text()
- names = odd.select('td.author a')
- allname = list({})
- for name in names:
- n = name.get_text()
- allname.append(n)
- source = odd.select('td.source a')
- source = source[0].get_text()
- date = odd.select('td.date')
- date = date[0].get_text().split()
- download = odd.select('td.download a')
- download = download[0].get_text()
- href = odd.select('td.name a')
- filename = re.search('filename=(.*?)&',str(href[0])).group(1)
- url = 'https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2022&filename={}'.format(filename)
- info = {
- '文章标题':title,
- '文章链接':url,
- '作者':allname,
- '刊名':source,
- '发表时间':date,
- '下载次数':download
- }
- with open("./article.json","a",encoding='utf-8')as t:
- json.dump(info,t)
- pprint.pprint(info)
- def getinfo(page):
- data = {
- 'IsSearch': 'false',
- 'QueryJson': '{"Platform":"","DBCode":"CFLQ","KuaKuCode":"","QNode":{"QGroup":[{"Key":"Subject","Title":"","Logic":4,"Items":[],"ChildItems":[{"Key":"input[data-tipid=gradetxt-1]","Title":"主题","Logic":0,"Items":[{"Key":"","Title":"混合动力汽车","Logic":1,"Name":"SU","Operate":"%=","Value":"混合动力汽车","ExtendType":1,"ExtendValue":"中英文对照","Value2":""}],"ChildItems":[]}]},{"Key":"ControlGroup","Title":"","Logic":1,"Items":[],"ChildItems":[{"Key":".tit-startend-yearbox","Title":"","Logic":1,"Items":[{"Key":".tit-startend-yearbox","Title":"出版年度","Logic":1,"Name":"YE","Operate":"","Value":"2020","ExtendType":2,"ExtendValue":"","Value2":"2022","BlurType":""}],"ChildItems":[]},{"Key":".extend-tit-checklist","Title":"","Logic":1,"Items":[{"Key":0,"Title":"SCI","Logic":2,"Name":"SI","Operate":"=","Value":"Y","ExtendType":14,"ExtendValue":"","Value2":"","BlurType":""},{"Key":0,"Title":"EI","Logic":2,"Name":"EI","Operate":"=","Value":"Y","ExtendType":14,"ExtendValue":"","Value2":"","BlurType":""},{"Key":0,"Title":"北大核心","Logic":2,"Name":"HX","Operate":"=","Value":"Y","ExtendType":14,"ExtendValue":"","Value2":"","BlurType":""},{"Key":0,"Title":"CSSCI","Logic":2,"Name":"CSI","Operate":"=","Value":"Y","ExtendType":14,"ExtendValue":"","Value2":"","BlurType":""},{"Key":0,"Title":"CSCD","Logic":2,"Name":"CSD","Operate":"=","Value":"Y","ExtendType":14,"ExtendValue":"","Value2":"","BlurType":""}],"ChildItems":[]}]}]}}',
- 'SearchSql': '2827E4B6502D8710F4C63FA68A0E7A152D8972E3EF5541A46DDE8B3A62A549C1B093F0A10875FEBDE5B17F4F918A6F10CAA2EA622595552DEE59C9627930D8AA16C4AEE03761E9763755CFB4AB484B0A8B7EF2B8C90286C2DEC78CD0E3AE2DB9B3BE203F0BDCAD4BCDFF877136D437E9DCE523BB91848194E9042A1EF42639481893C32BC15EB49F8DBA6D88E0BE298A81A2A10E0803C3F010CB7FA11AA1A188E6726B6A7F4FD1C636081BE13C709F99462180D1BA1B79C9098ADE36A48F3CCE2B1B78B0A17F7A5C77FADBBE119FDF3E7C8AFB383F33B5F6EB3B6B6C6D79B830FD7B151288283EE5D974D96297962072C0D40233CCAFEE9C6498694742FE2D80FCAAA0FABC4D63452A8EC9796C58C80333763B655C7C0320539DF1A90468E26D37D70D269AAAAFF3E3B04C1DC5D26B485836840CD0CB5372BB7336EEC13900D63CE4340AFB729888F8A144ABD212A6B34FAAFA6D1E5439D516FFED876EB0F8D68C613D561024DD68F2009006DB8FA215E521048042041D8E8A3E69F019137BBC029BC474CA02BDA146F1C234D135725FF5EA178CDA3AB8304742D417E95D79A47D1C1378F6B9586ED9ED0B1A886633E6C5630DEB57C5B253290AD78041CE70B4847BFA299012FF1020413DF186908A51BD59D66C9AF8AC95C68D9EFAAF3F7C0268D662FA2BB9F17B0D6E8A9488F27C79CDF23D4DC15A1F5A2E7AC8B86FDE619C10C36805FBCF1917510D091DBF76C7B90D92A761A28EE3050C5AB5D2B5675CF86D03EB70EB6CC3E8FFB685A4390394C71475B56BF1E3AD45BBC2AC45221795D0A9FF733A6A5E31D73407BD10E50267DE6655D6B04D1980ED447E96806489766D94950E346F296415EA9CD72F1D9A4DDC1690D3A5B43DCD14B732E89F3F04E48378BEF7C8B7397C57B7873B4232AC29E77A5E6790397DEBE1C498C1980F9F13F26E4FC31951A5A6ED9FE2EE80608F09A778F806CC129FE113B4CFCB500FF324C2B13617573945F8D9AA92C544E03CC2B9234726757135F53D7EBB12F4E4BC5C6D7702793B23E37598B7070F2267CB166547FE45E445A881134FE00D9D3E3D5C041F973D6FE3D83635BB70B21E0F6D804F47A772FCEE5A8C9298497BFC8EDF97B1707A975F8E148740DF3F7648E92E132D5BA61EF1AB103305C3E3E008DF2E9398D0D47047570CEE576EA09B0AEAE55B15F6456221327031D6880BDBA6432A488A801D65350DB5C40D0E087753851488F646EA3AC2C82300495D93BB13AE3D72235FC788FC2C681200C065F0FB310F9BF781764774C6CF8B929A6BA9B38DBAC5583E655604E0B5B707AD8A3AD21EBFDC8D1D806AD456359A60D2FFF23692314BF03BF3E4174DC177C33A8CD5B41716D6A452C5567BC395F59D24A6AFBBC29CC876250E5BE7C3F03E6E8A0A87B782F575CCD2AF49B568D2F63BAA26BD0DB1058FD6B8C72E09C5ABBBCB053FA128BDFB318EFCC4745B32CCA69872E0D62C8DC7D392BB8590B2488A0A82EC1AE36973FE211804E3EF24770CE8D5A62869D2C280B6A9580DC15E3955895E3711C8EED8C3EC5AC5DBFEE92B1D579D3924CD88D8059F9BAA9AC2F0D3613C78D402CC182C2ABDAFEA0AD8DAE883B3DF8D11ECE705EF37CE6516DC7AFBEC7F164549A41C69CF6EEE8983739DFEB8E22E5D9DEAE15B3C2946EED0970C7A499705036EF348993E1B0D',
- 'PageName': 'AdvSearch',
- 'HandlerId': '0',
- 'DBCode': 'CFLQ',
- 'KuaKuCodes': '',
- 'CurPage': page,
- 'RecordsCntPerPage': '20',
- 'CurDisplayMode': 'listmode',
- 'CurrSortField': 'PT',
- 'CurrSortFieldType': 'desc',
- 'IsSortSearch': 'false',
- 'IsSentenceSearch': 'false',
- 'Subject': ''}
- resp = geturl(data)
- info(resp)
- for i in range(1,10):
- getinfo(i)
(6)运行结果

json文件也成功写入
![]()

任务二
1)构建网络请求函数
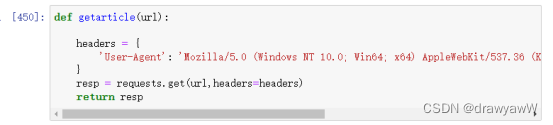
2、3)数据提取和解析并构建数据处理函数
4)获取任务一保存的文章链接URL

5)构建主函调用数据处理函数对URL进行数据储存

6)爬虫实现(源代码)
- # 从保存的数据中获取文章链接
- def getarticle(url):
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52'
- }
- resp = requests.get(url,headers=headers)
- return resp
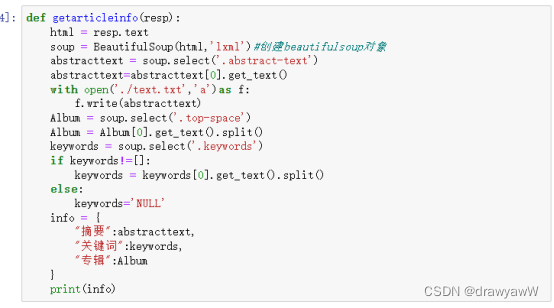
- def getarticleinfo(resp):
- html = resp.text
- soup = BeautifulSoup(html,'lxml')#创建beautifulsoup对象
- abstracttext = soup.select('.abstract-text')
- abstracttext=abstracttext[0].get_text()
- with open('./text.txt','a')as f:
- f.write(abstracttext)
- Album = soup.select('.top-space')
- Album = Album[0].get_text().split()
- keywords = soup.select('.keywords')
- if keywords!=[]:
- keywords = keywords[0].get_text().split()
- else:
- keywords='NULL'
- info = {
- "摘要":abstracttext,
- "关键词":keywords,
- "专辑":Album
- }
- print(info)
- file = open('./article.json','r',encoding='utf-8')
- data = file.readline()
- urls = re.findall('u63a5": (.*?),',data)
- for i in urls:
- i=i.strip('"')
- url = i
- resp = getarticle(url)
- getarticleinfo(resp)
(7)运行结果


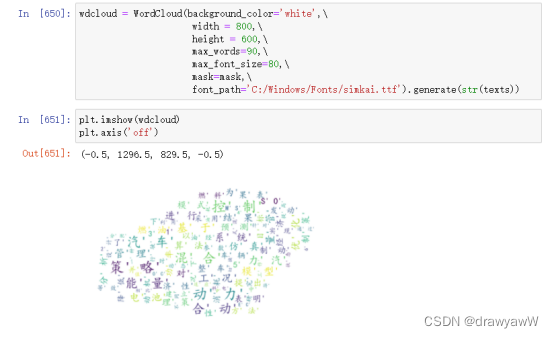
任务三
1)获取词云背景和文本信息

2)对文本信息进行处理

3、4)生成词云
四、总结与反思
(1)完成该实验用到的知识点
- 网页请求(requests.get、requests.post)
- post 请求参数设置;(需要提交表单数据)
- 数据解析(BeautifulSoup 、select方法)
- 文件写入(json)
- 分词处理(jieba)、停用词处理
- 图片读取(Image.open)
- 词云生成(WordCloud)
(2)收获
通过完成该实验,我了解了动态网页的加载方式和POST网络请求的方法,更熟练地掌握了数据解析中css解析器调用select方法进行数据解析的方式,学会了如何从动态网页爬取信息保存为文本和图片,了解了动态网页使用POST网络请求爬取的方法,巩固了理论课程所学的知识。
(3)遇到的问题和不足
- 读取写入的文件(json格式)时出现错误,通过逐行读取(readlines()) 解决了该问题
- 生成词云时,没有文字显示,通过设定字体样式(font_path)解决
- 没有非常清晰的思路,编程速度偏慢,应当提升编程速度
- 格式也需要尽可能规范,多给代码添加一些注释方面阅读,也方便对程 序的修改和完善















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









