







说明
- 本文章重在理解Seq2Seq模型和相关代码使用,没有深入研究模型使用相关的实践,请具有动手能力的开发者,深入学习研究后动手实践。
- 由于本人非NLP领域的专业研究人员,如果文章中存在错漏,请在评论区或私信及时之处,感谢您的指导!
1. Seq2Seq模型概述
1.1 什么是Seq2Seq模型?
- 在自然语言处理(NLP)领域,Seq2Seq(Sequence-to-Sequence)模型是一种强大的框架,专门用于处理输入和输出都是序列的任务。自从2014年由Google的研究团队提出以来,Seq2Seq模型已经彻底改变了机器翻译、文本摘要、对话系统等多个NLP领域。
- Seq2Seq模型是一种端到端的深度学习框架,专门设计用于将一个序列(如句子)转换为另一个序列。它的核心思想是接受可变长度的输入序列,并生成可变长度的输出序列,这两个序列的长度可以不同。
1.2 典型应用场景
- Seq2Seq模型在以下任务中表现出色:机器翻译(如英译中)、文本摘要(长文本→短摘要)、对话系统(用户输入→系统回复)、语音识别(音频序列→文字)、代码生成(自然语言描述→程序代码)
1.3 基本架构组成
传统的Seq2Seq模型由三部分组成:
- 编码器(Encoder): 处理输入序列,将其压缩为固定长度的上下文向量(context vector)。
- 上下文向量: 编码输入序列信息的固定维度表示。
- 解码器(Decoder): 基于上下文向量生成输出序列。
2. Seq2Seq模型的核心原理
2.1 编码器-解码器架构
编码器工作流程
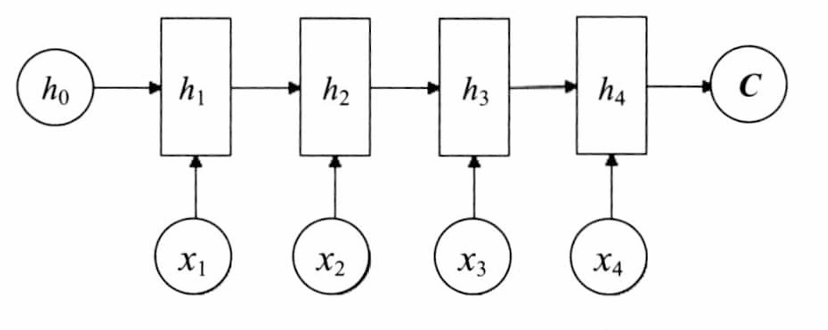
- 接收输入序列的每个元素(如单词)
- 逐步更新内部隐藏状态
- 在处理完整个输入序列后,最终隐藏状态作为整个序列的表示(上下文向量)
解码器工作流程
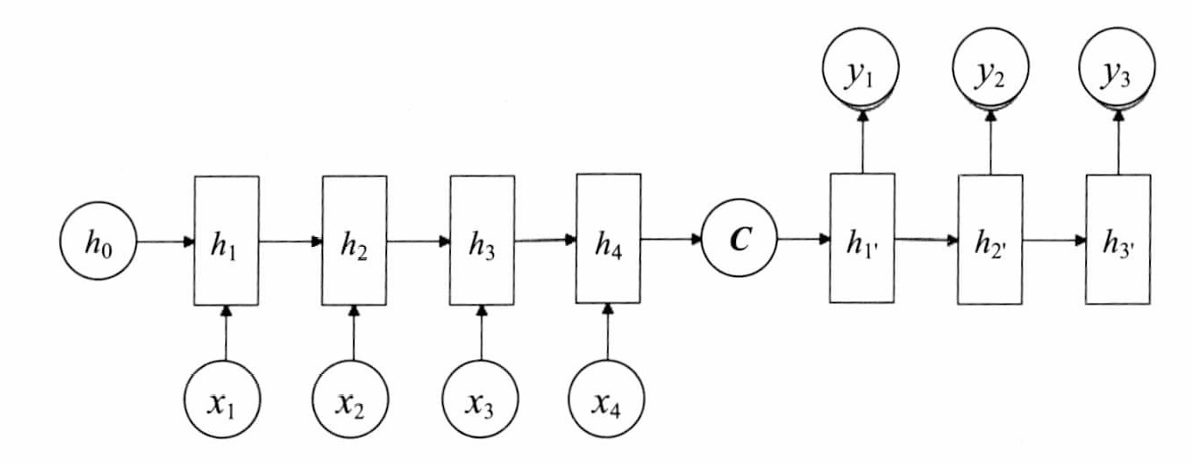
- 以编码器生成的上下文向量为初始状态
- 逐步生成输出序列的元素
- 每个步骤使用前一个时间步的输出作为当前输入(自回归生成)
2.2 循环神经网络(RNN)的基础
- 早期Seq2Seq模型主要基于RNN及其变体(LSTM、GRU):
# 简化的RNN结构示例
class RNNCell:
def __init__(self, input_size, hidden_size):
self.Wxh = random_matrix(input_size, hidden_size) # 输入到隐藏层权重
self.Whh = random_matrix(hidden_size, hidden_size) # 隐藏层到隐藏层权重
self.bh = zeros(hidden_size) # 隐藏层偏置
def forward(self, x, h_prev):
h_next = tanh(self.Wxh @ x + self.Whh @ h_prev + self.bh)
return h_next
RNN的局限性:
- 梯度消失/爆炸问题
- 难以捕捉长距离依赖关系
- 上下文向量成为信息瓶颈
2.3 注意力机制的引入
- 注意力机制(Attention Mechanism)解决了传统Seq2Seq模型的关键限制:
- 核心思想:解码器在生成每个输出时,可以"关注"输入序列的不同部分,而不是仅依赖单一的上下文向量
- 工作原理:
- 计算编码器所有隐藏状态的加权和
- 权重由解码器当前状态和编码器各状态共同决定
- 优势:
- 缓解信息瓶颈问题
- 提供更好的长序列处理能力
- 模型可解释性增强(可通过注意力权重了解模型关注点)
2.4 Transformer架构的革新
- 2017年提出的Transformer模型彻底改变了Seq2Seq的实现方式:
- 自注意力(Self-Attention)机制:序列中每个位置都可以直接关注所有位置
- 多头注意力(Multi-Head Attention):并行多个注意力机制,捕捉不同子空间的信息
- 位置编码(Positional Encoding):注入序列顺序信息
- 完全基于注意力:摒弃了RNN的循环结构
Transformer的优势:
- 更强的长距离依赖建模能力
- 更高的并行计算效率
- 在许多基准测试中达到state-of-the-art性能
3. Seq2Seq模型的实现细节
3.1 基于RNN的Seq2Seq实现
3.1.1 编码器实现示例(PyTorch)
import torch
import torch.nn as nn
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output, hidden = self.gru(embedded, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)
3.1.2 解码器实现示例
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)
3.2 注意力机制实现
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)
3.3 Transformer实现关键组件
3.3.1 多头注意力实现
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
assert d_model % num_heads == 0
self.depth = d_model // num_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.transpose(1, 2)
def forward(self, q, k, v, mask):
batch_size = q.size(0)
q = self.wq(q)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = scaled_attention.transpose(1, 2).contiguous()
concat_attention = scaled_attention.view(batch_size, -1, self.d_model)
output = self.dense(concat_attention)
return output, attention_weights
3.3.2 Transformer编码器层
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = nn.LayerNorm(d_model)
self.layernorm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(rate)
self.dropout2 = nn.Dropout(rate)
def forward(self, x, mask):
attn_output, _ = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output)
out2 = self.layernorm2(out1 + ffn_output)
return out2
4. Seq2Seq模型的训练技巧
4.1 教师强制(Teacher Forcing)
教师强制是一种训练技术,在解码器训练时使用真实目标输出作为下一个输入,而不是使用解码器自己的预测输出。
- 优点:加速模型收敛,提高训练稳定性
- 缺点:可能导致推理时性能下降(暴露偏差问题)
# 教师强制示例
for t in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
# 使用教师强制
use_teacher_forcing = random.random() < teacher_forcing_ratio
if use_teacher_forcing:
decoder_input = target_tensor[t] # 使用真实目标作为下一个输入
else:
decoder_input = decoder_output.topk(1)[1] # 使用模型预测作为下一个输入
4.2 集束搜索(Beam Search)
集束搜索是一种启发式搜索算法,在解码时保留多个最有可能的候选序列,而不是仅保留单个最优假设。
实现步骤:
- 保持k个最有可能的候选序列(称为beam width)
- 在每个时间步,扩展所有可能的候选
- 从k*V个候选中选择top-k(V是词汇表大小)
- 重复直到达到最大长度或结束符号
def beam_search_decoder(model, input_seq, beam_width=5, max_len=50):
# 初始化
beams = [([], 0, model.init_hidden())] # (序列, 分数, 隐藏状态)
for _ in range(max_len):
candidates = []
for seq, score, hidden in beams:
if seq and seq[-1] == EOS_token: # 已生成结束符
candidates.append((seq, score, hidden))
continue
# 获取下一个token预测
output, hidden = model(input_seq, hidden)
topk_scores, topk_ids = output.topk(beam_width)
for i in range(beam_width):
new_seq = seq + [topk_ids[i].item()]
new_score = score + topk_scores[i].item()
candidates.append((new_seq, new_score, hidden))
# 选择top-k候选
candidates.sort(key=lambda x: x[1], reverse=True)
beams = candidates[:beam_width]
return beams[0][0] # 返回分数最高的序列
4.3 其他重要技巧
- 标签平滑(Label Smoothing):防止模型对预测结果过于自信
- 学习率调度(Learning Rate Scheduling):如warmup策略
- 梯度裁剪(Gradient Clipping):防止梯度爆炸
- 批量归一化(Batch Normalization):加速训练
- 残差连接(Residual Connections):缓解深层网络梯度消失问题
5. 实际应用案例
5.1 机器翻译
- 以英译中为例:
# 使用HuggingFace Transformers库实现
from transformers import pipeline
translator = pipeline("translation_en_to_zh", model="Helsinki-NLP/opus-mt-en-zh")
result = translator("Hello world, this is a Seq2Seq model tutorial.", max_length=40)
print(result[0]['translation_text'])
5.2 文本摘要
# 使用预训练的文本摘要模型
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
article = """
Seq2Seq models have revolutionized many NLP tasks since their introduction.
This article provides a comprehensive overview of Seq2Seq architecture...
"""
summary = summarizer(article, max_length=130, min_length=30, do_sample=False)
print(summary[0]['summary_text'])
5.3 对话系统
# 简单的对话生成
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
def chat(input_text):
new_user_input_ids = tokenizer.encode(input_text + tokenizer.eos_token, return_tensors='pt')
bot_input_ids = new_user_input_ids
chat_history_ids = model.generate(
bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
return tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)
print(chat("What do you think about Seq2Seq models?"))
6. 评估与优化
6.1 常用评估指标
- BLEU (Bilingual Evaluation Understudy):用于机器翻译、比较机器输出与人工参考翻译的n-gram重叠
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation):、用于文本摘要、计算召回率导向的n-gram重叠
- METEOR:考虑同义词和词形变化的更复杂指标
- Perplexity:语言模型评估指标、反映模型对测试数据的"惊讶程度"
6.2 模型优化方向
- 架构优化:深层网络设计、注意力机制变体、混合架构(CNN+Attention等)
- 数据优化:数据增强(回译、随机插入/删除等)、领域适应
- 数据清洗
- 训练策略优化:课程学习(Curriculum Learning)、对抗训练、多任务学习
总结
- Seq2Seq模型作为序列转换任务的基础框架,已经发展出多种强大的变体和实现方式。从最初的RNN-based架构到现在的Transformer模型,Seq2Seq技术不断演进,推动着NLP领域的进步。理解这些模型的原理和实现细节,对于在实际项目中应用和优化它们至关重要。随着研究的深入,我们期待看到更多创新的Seq2Seq架构和应用场景出现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









