







基于用户的协同过滤算法也被称为最近邻协同过滤或KNN (K.Nearest-Neighbor,K最近邻算法)。其核心思想就是,首先根据相似度计算出目标用户的邻居集合,然后用邻居用户评分的加权组合来为目标用户作推荐。
通常这些算法都可以总结成三步:
- 首先,使用用户已有的评分来计算用户之间的相似度;
- 然后,选择与目标用户相似度最高的K个用户,通常把这些用户称为邻居;
- 最后,通过对邻居用户的评分的加权平均来预测目标用户的评分。为了方便说明,我们把系统中用户的集合记为U。物品的集合记为I,用户u,v∈U,物品i,j∈I, 是用户对物品的评分,而用户u和v之间的相似度记为 ,用一个m×n的矩阵来表示所个用户对玎个物品的评分情况。
Pearson相关系数将两个用户共同评分的n个项目看做一组向量,计算两个用户在这n个项目上评分的相关性,减去用户平均评分是基于用户评分尺度的考量,公式如下:
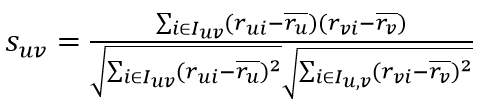
其中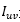
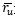
余弦相似度则是把用户的评分(包括所有项目,未评过分的项目分数则为0)看作是一个向量,通过计算两个向量夹角的余弦来衡量用户之间的相似性,其定义如公式如下:
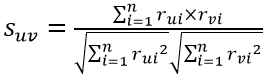
得到用户相似度后,接下来的工作就是对近邻用户下载过的应用进行评分预测,公式如下:
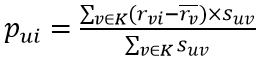
其中得到的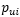
Python代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









