






协同过滤推荐算法
基本思想:
根据用户的历史行为数据的挖掘发现用户的兴趣爱好,基于不同的兴趣爱好对用户进行划分并推荐兴趣相似的物品给用户。

协同过滤推荐算法包含:
1.1基于记忆的推荐算法(基于领域的推荐)
1.1.1 基于用户的推荐算法
1.1.2 基于物品的推荐算法
1.2基于模型的推荐:借助分类 线性回归 聚类 机器学习
1.2.1 基于图模型的推荐
1.2.2 基于朴素贝叶斯的推荐算法
1.2.3 基于矩阵分解的推荐算法(MF)
-
基于用户的协同过滤推荐算法
UserCF,思想其实比较简单,当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的,而用户A没有听说过的物品推荐给A。
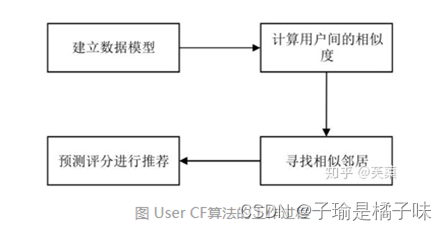
- UserCF算法主要包括两个步骤:
1、找到和目标用户兴趣相似的用户集合
2、找到这个集合中的用户喜欢的, 且目标用户没有听说过的物品推荐给目标用户。

1.建立“用户→用户”的索引
- 对于每个用户,索引他最相似的k个用户
- 给定任意用户ID,可以快速找到他最相似的k个用户

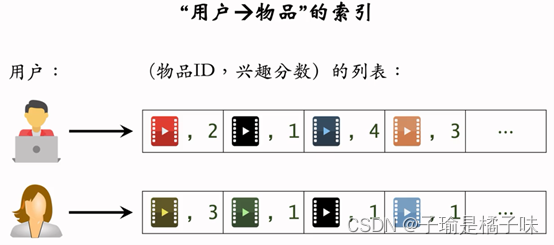
2.建立“用户→物品”的索引
- 记录每个用户最近点击、交互过的物品ID。
- 给定任意用户ID,可以找到他近期感兴趣的物品列表。
UserCF的python实现过程为:

import random
import math
from operator import itemgetter
# 基于用户的协同过滤推荐算法实现
class UserBasedCF():
# 初始化相关参数
def __init__(self):
# 找到与目标用户兴趣相似的20个用户,为其推荐10部电影
self.n_sim_user = 20
self.n_rec_movie = 10
# 将数据集划分为训练集和测试集
self.trainSet = {}
self.testSet = {}
# 用户相似度矩阵
self.user_sim_matrix = {}
self.movie_count = 0
print('Similar user number = %d' % self.n_sim_user)
print('Recommneded movie number = %d' % self.n_rec_movie)
# 1. 读文件得到“用户-电影”数据
def get_dataset(self, filename, pivot=0.75):
trainSet_len = 0
testSet_len = 0
print("1.读文件得到用户-电影数据")
for line in self.load_file(filename):
user, movie, rating, timestamp = line.split('::')
if random.random() < pivot:
self.trainSet.setdefault(user, {})
self.trainSet[user][movie] = rating
trainSet_len += 1
else:
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
print('Split trainingSet and testSet success!')
print('训练集:TrainSet = %s' % trainSet_len)
print('测试集:TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load dataset %s success!' % filename)
# 2. 计算用户之间的相似度
def calc_user_sim(self):
print("2. 计算用户之间的相似度 ")
#2.1 构建“电影-用户”倒排索引
print('2.1构建电影-用户倒排表: Building movie-user table ...')
movie_user = {}
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in movie_user:
movie_user[movie] = set()
movie_user[movie].add(user)
print('电影-用户倒排表建立成功: Build movie-user table success!')
self.movie_count = len(movie_user)
print('Total movie number = %d' % self.movie_count)
# 2.2 构建用户相关联的电影矩阵
print('2.2 建立用户相关联的电影矩阵 Build user co-rated movies matrix ...')
for movie, users in movie_user.items():
for u in users:
for v in users:
if u == v:
continue
self.user_sim_matrix.setdefault(u, {})
self.user_sim_matrix[u].setdefault(v, 0)
self.user_sim_matrix[u][v] += 1
print('Build user co-rated movies matrix success!')
# 2.3 计算用户的相似性
print('2.3 计算用户之间的相似度 : Calculating user similarity matrix ...')
for u, related_users in self.user_sim_matrix.items():
for v, count in related_users.items():
self.user_sim_matrix[u][v] = count / math.sqrt(len(self.trainSet[u]) * len(self.trainSet[v]))
print('Calculate user similarity matrix success!')
# 针对目标用户U,找到其最相似的K个用户,产生N个推荐
def recommend(self, user):
K = self.n_sim_user
N = self.n_rec_movie
rank = {}
watched_movies = self.trainSet[user]
# v=similar user, wuv=similar factor
for v, wuv in sorted(self.user_sim_matrix[user].items(), key=itemgetter(1), reverse=True)[0:K]:
for movie in self.trainSet[v]:
if movie in watched_movies:
continue
rank.setdefault(movie, 0)
rank[movie] += wuv
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
# 3. 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print("3.进行评价: Evaluation start ...")
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user, in enumerate(self.trainSet):
test_movies = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_movies)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
if __name__ == '__main__':
rating_file = '../ml-1m/ratings.dat'
userCF = UserBasedCF()
userCF.get_dataset(rating_file) # 1.读文件得到“用户-电影”数据
userCF.calc_user_sim() # 2. 计算用户之间的相似度
userCF.evaluate() # 3.产生推荐并通过准确率、召回率和覆盖率进行评估
















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











